pytorch YoLOV3 源码解析 train.py
train.py
总体分为三部分(不算import 库)
初始的一些设定 + train函数 + main函数
源码地址:
https://github.com/ultralytics/yolov3
一 .import 相关
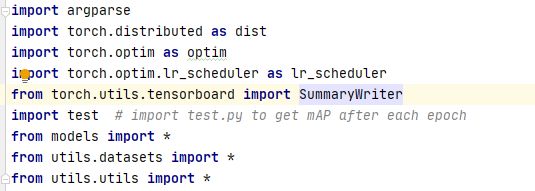
torch.distributed 分布式训练
torch.optim.lr_scheduler 学习率衰减
二.初始设定
1使用混合精度训练

2预训练权重路径
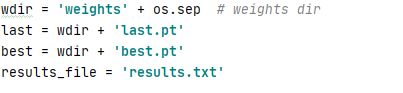
Python可跨平台使用,但win和linux 的路径分隔符是不同的(斜杠)。
这里的os.sep会根据你所处的平台,自动采用相应的分隔符号。
results.txt 记录loss
3获取本地的超参数文件并解析
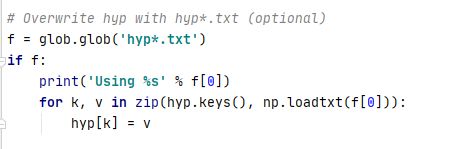
使用glob.glob来获取文件
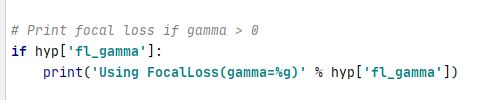
4是否使用focal loss
三.main函数:
1参数的设定(之后涉及会说明)
这里是程序的默认参数
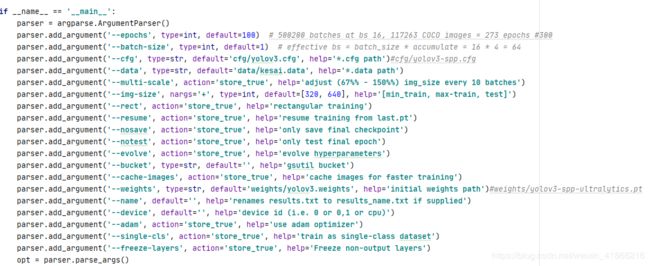
关于parser.add_argument的action=‘store_true’ 的解释是如果命令行执行程序时 设定对应的参数 那么这个参数的布尔值会变为True。
以这个为例:
parser.add_argument(’–nosave’, action=‘store_true’, help=‘only save final checkpoint’)
如果执行
train.py nosave
那么
opt.nosave 布尔值为True 一般涉及if判断 即 if opt.nosave :
2

p1 预训练权重的选择 如果设定了opt.resume就使用上次保存的权重 即命名带last.pt。else使用opt.weights路径下的权重
p2 一些check操作
check_git_status()函数 check一些版本 和 进程相关的内容。
p3 原本opt.img_size 设定的是一个img最大值和最小值 这里再添加一个test中img的size
p4 程序运行device的设定
如果opt.device 设定为GPU就使用混合精度计算。
设定GPU一般用数字id表示 0表示在第一个GPU上执行程序
3

if not:如果为False 就使用之前预设好的超参数进行训练 train(hyp)是进行正常的训练
之前设定的hyp是超参数搜索之后的超参数值。
使用opt.evolve判断是否使用超参数搜索的参数来训练
else:
以# Evolve hyperparameters (optional)方式来训练
以下暂略
四.train normal:
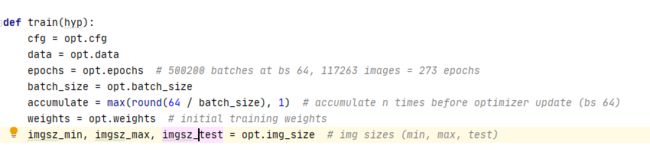
初始的一些设定
accumulate是用于判断模型是否进行更新参数

这个32是指模型的32前向传播会进行32倍的下采样率
也就是指32下采样后的featmap 的一个像素点 表示原图 32像素点的特征信息。详见原理
判断imgsz_min 是否可以整除32,刚好整除就不会出现 featmap 大小32.5 取整 为32 导致的信息损失。
assert函数 是判断后面是否出现异常。
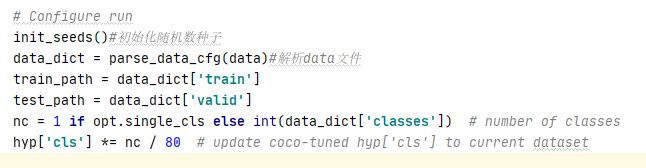
解析运行程序时所对应的data文件
我感觉如果是训练自己的数据集 这个80要修改成对应的类别数,不知道是否是这样的。

移除之前保存的图片
初始化模型
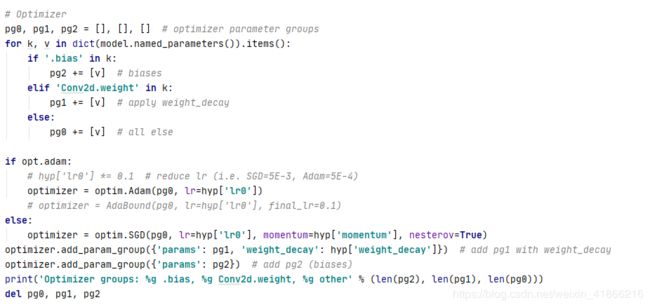
attempt_download 用来获取权重 weights 是之前的opt.weights
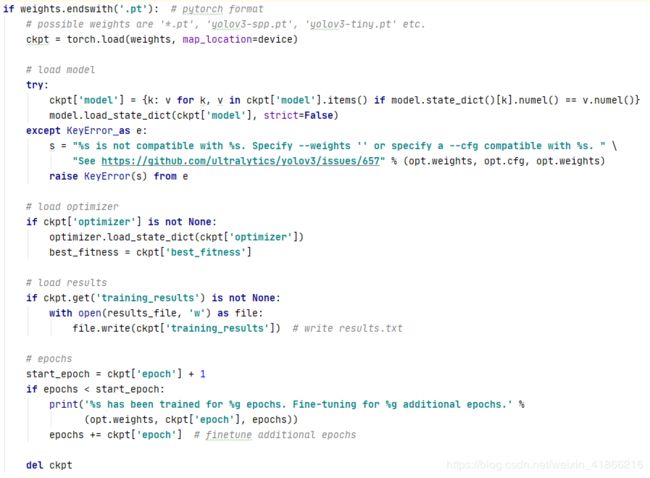
if 权重文件是以pt结尾 也就是使用pytorch state_dict方式保存的形式。
这个pt文件包含四个部分(有的部分可能为空,就是写入的时候没有写入)
ckpt[weights]模型权重参数,ckpt[optimizer]优化器的参数,
ckpt[training_results]是这个权重文件中之前保存的结果 如果有就把里面的值写入我们这个程序的result.txt文件
ckpt[epoch] 这个权重文件中训练的epoch
def ckpt 释放一些内存

如果模型是YOLOV3 源码相关的格式保存的就用这种方式加载,比如我跑的预训练权重文件就叫
YOLOV3.weights

这段函数的含义就是是否进行freeze_layers操作,字面意思就是冻结一些层的权重参数,不去训练这些层,而是训练一些特定的层。这里训练yolo层 和 yolo层之后的一层。其他的层冻结操作。

关于混合精度训练的设定

学习率
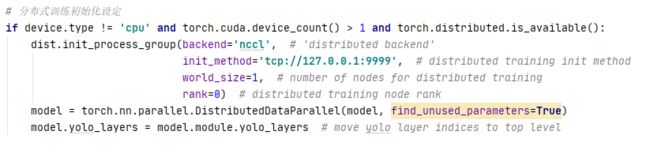
分布式训练设定
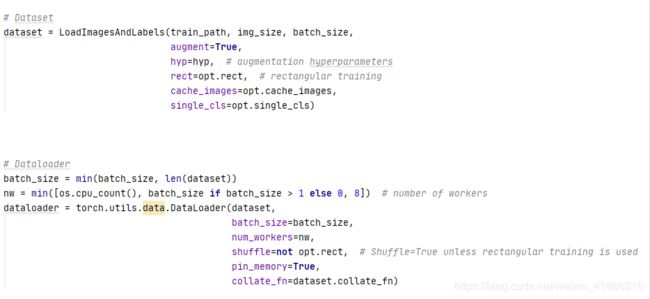
初始化Dataset和Dataloader 用于训练
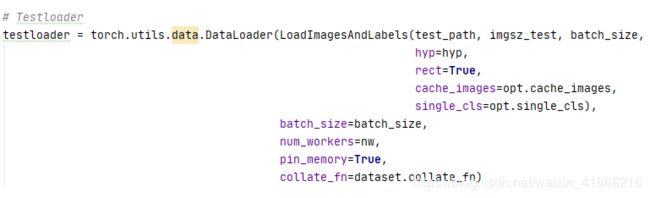
初始化Testloader 用于test
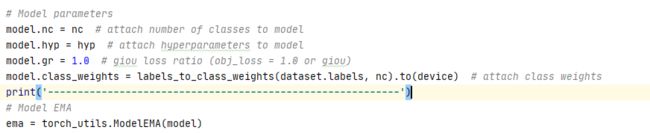
模型的参数设定
nc模型的类别数
hyp超参数
GIoU
gr 是涉及到giou的权重系数
原本使用iou来判别回归损失的时候有自身的缺点。1如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重合度)。同时因为loss=0,没有梯度回传,无法进行学习训练。2不能判别两个标定框的重合程度。
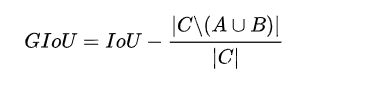
c是指A和B的最小封闭形状。
GIoU公式 是指IoU 减去 ( |c中不包含A和B的区域| :|c的区域|)
这个公式可以表示两个标定框的重合程度。在IoU为0的时候也不会对更新参数有不好的影响。
EMA指数加权平均操作
也叫滑动平均值

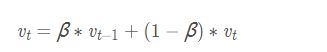
计算公式 β×之前时刻数值 + (1-β)×此时的数字
当β越大时,滑动平均得到的值越和v的历史值相关
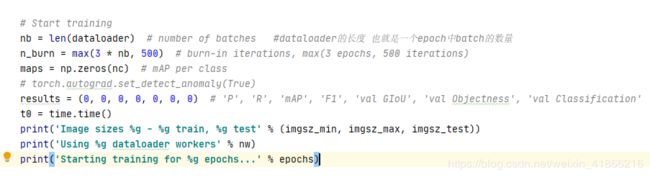
训练
一次迭代为一个周期
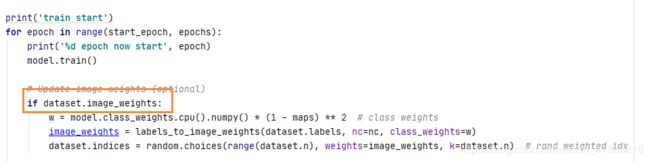
这里是判断是否要更改权重 这里没有使用。
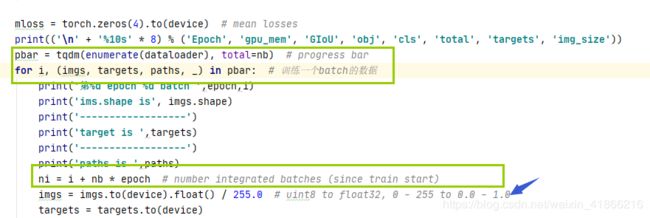
把迭代dataloader的操作 使用tqdm 来封装 迭代的时候会显示进度条
ni是总体上已迭代的batch数
归一化操作
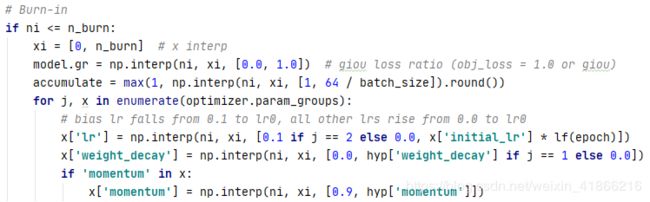
n_burn 是之前设定的参数
用于是否进行x interp操作
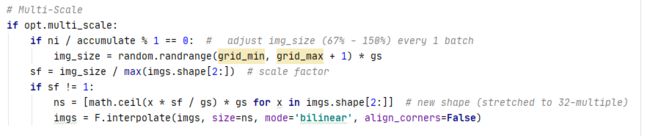
opt.multi_scale 是上面求得的,判断是否对图片进行随机缩放
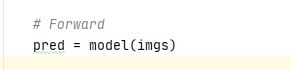
前向传播的到模型的预测值

计算loss
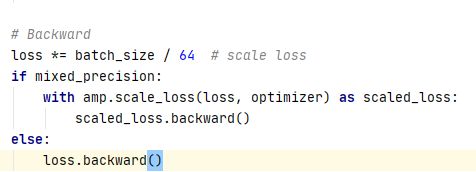
backward

accumulate 之前设定的值 判断是否更新参数

把mloss,mem 等信息set到进度条显示中
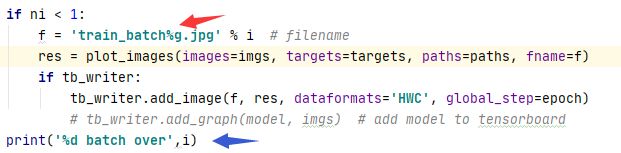
ni = 0 时 也就是第一个batch 会保存一张带有模型预测信息的图片
到此迭代完一个batch
迭代完整体的dataloader时,也就是是一个epoch:
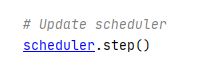



记录最好的 results

保存最好的模型权重 并释放ckpt
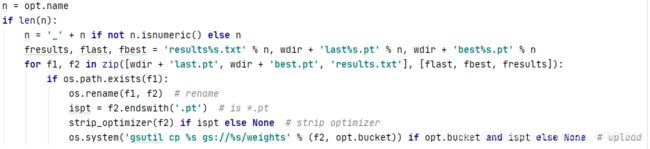
opt.name = ’ ’ 为空
len(opt.name) = 0
if 0 相当于 if False 不执行

时间不够 有的地方不具体 之后补充 欢迎留言
涉及的论文:
https://arxiv.org/pdf/1812.01187.pdf
https://arxiv.org/pdf/1812.01187.pdf
网站:
论文相关博客:
https://zhuanlan.zhihu.com/p/51870052
https://blog.csdn.net/diligent_321/article/details/87885418
超参数搜索
https://www.cnblogs.com/pprp/p/12432549.html
round()函数
https://blog.csdn.net/lly1122334/article/details/80596026
math.fmod()
https://blog.csdn.net/sunline_wanghj/article/details/79490986
check out()
https://www.cnblogs.com/hubavyn/p/8467329.html
GIoU
https://zhuanlan.zhihu.com/p/57992040
https://zhuanlan.zhihu.com/p/94799295
EMA:
https://blog.csdn.net/mikelkl/article/details/85227053
https://www.jianshu.com/p/f99f982ad370
分布式训练:
https://blog.csdn.net/m0_38008956/article/details/86559432?utm_source=blogxgwz4