模型量化-更小更快更强
原视频地址:https://www.bilibili.com/video/BV19J411R7t2?t=4678
官方长文:https://www.sohu.com/a/361341209_610522
整理的时候发现的官方长文。
Outlines

Fixed-point and Floating-point Numbers
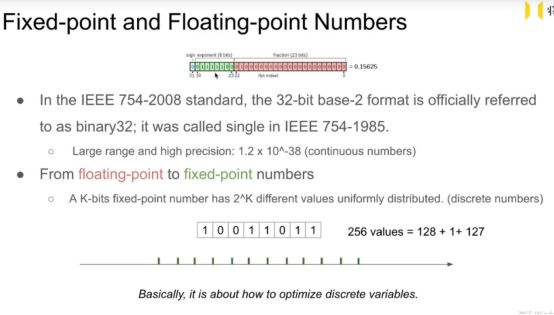
假如使用8bit 的离散量化方式 只能表示256个数 128负 0 127正数

模型压缩常见的方式
1矩阵分解:
把100*100 的矩阵分解成100*2 和 2*100 的两个矩阵。可以达到减少内存的损耗,但是并不能起到加速的作用。 而且改变了特征的形状,放行->矩形 计算过程中可能会出错。
这种方式早期使用,现在用的比较少。
2剪枝(普遍使用的方法)
方式一:非结构化剪枝 把网络一些连接参数置为0 把参数矩阵变为稀疏的。如果在CUDA上运行,或者GPU上运行,很难看到性能的提升,还有可能会下降,性能这里指的是计算速度和延迟。
方式二:结构化剪枝
指把网络的channel整个拿掉,相当于把网络进行一个瘦身。这种方式简单直观,可以起到提升性能的作用。优势来源于内存,模型体积变小了,网络内存读取花费时间少了自然速度提高了。
值得注意的是这种方式,剪枝占比和性能提升并不是完全对应的。
即:网络剪枝比:0.5 性能并不会对应等价提升。
3AutoML
使用神经网络来自动搜索来实现网络的剪枝
为什么要使用量化
模型的量化不光起到模型压缩从而减少内存损耗的作用,更主要的是可以起到加速的效果。
2个32bit float 的计算 时间是远远大于 2个4bit 定点数的时间。
量化本质上讲也是硬件友好化的,硬件上面是一些0和1的位操作,而量化就是实现减少我们使用的bit数。
一个好的量化包括 model performance (acc 和 FN score 等), model efficiency(性能速度),hardware practicality(在硬件上面是否可以实现)。
量化存在的问题
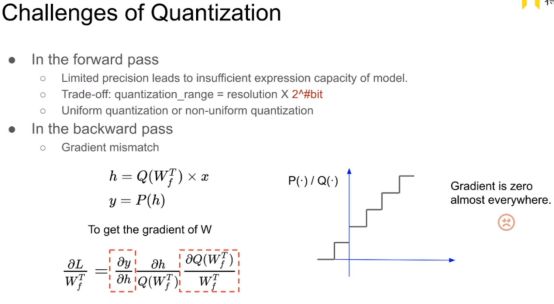
Forward 部分
1量化把连续的数值变为离散的数值。
假如量化为2bit。我们有一个100维的向量那么它每一个数只有4个选择。这个向量也只有4^100次方个表示方式,这样可能会带来网络表达能力的下降。
2Teade-off:量化的范围,最大的数 - 最小的数
Resolution(分辨率):小格子的长度
量化的级别 2^bit
量化精度与量化范围之间的抉择

3均匀量化还是非均匀量化
一个硬件友好
一个硬件不友好但是自由度高 效果更好
Backward 部分
离散变量的求导是很麻烦的。
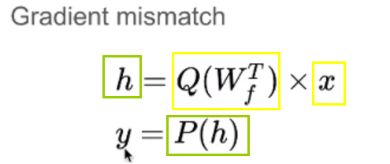
这里表示的 x 是上一层量化后的入 假如是4bit 形式, Q函数实现的是对这一层所有的权重实现的量化, 量化后的权重也是4bit 形式。 之后得到的activation 是h 它可能不是4bit形式,可能会是16bit形式, 之后使用P函数把h 量化为4 bit形式。
Backward 时要计算w的梯度来更新w。
根据链式求导法则:
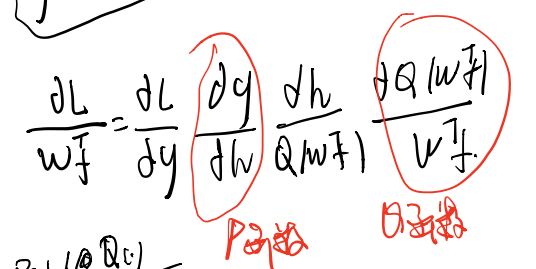
这里的P函数和Q函数的梯度都是为0的 这导致w的梯度为0,模型不能更新。

怎么解决
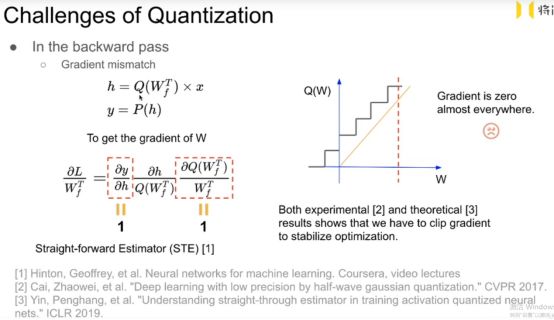
强行认为P函数和Q函数的梯度是为0的。
相当于假设 我们在forward的时候 使用了量化,而backward时没有使用量化。
相当于在forward时候 我们使用的是阶梯函数 , 而 backward时使用的是 y = x。
方法叫:
至少网络可以训练动了。但是loss跳动非常大,训练极其不稳定。
这里相当于假设量化前激活值的梯度等于量化后激活值的梯度。
量化前的参数和量化后的参数的梯度也是一样的。
这样的假设叫gradmismatch
我们得到的是量化之后的梯度,我们用来更新量化之前的参数。这里存在不匹配性。
使用STE的时候还要额外进行clip grad操作。
怎么解决这些问题
主要有3种方式

第一种:量化之前改变参数的分布
第二种:大部分论文集中处理这一部分。这部分主要是研究怎么把连续的权重数值划分为离散的权重数值,对应的就是量化函数, 本质是一个分段函数。 梯度几乎都是为0。
第三种:对量化之后的数值做一些处理,目前相关paper较少。
假如量化的值是[-1, 0, 1]把这些数值乘以不同的系数来改变值 比如0.5.
量化存在问题1的解决
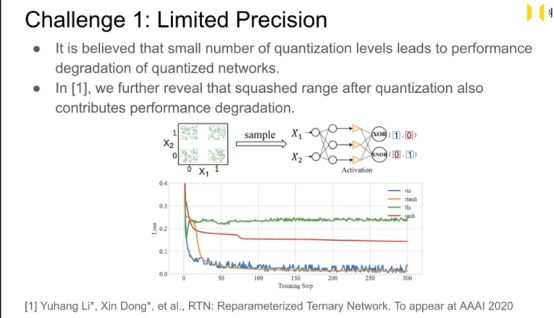
Quantization levels太少了 -> 模型的表达能力很差 -> 模型性能很差。
量化后模型的效果差的原因还有可存在Activation 的取值上面,比如量化前Activation的取值是(-5,+5)量化后的取值是(-1,+1)。
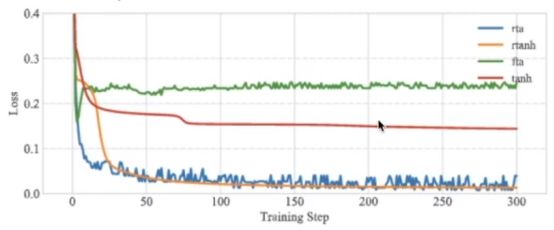
绿色量化后的激活函数:这里使用的是三值量化 即量化到 -1 0 +1 效果最差。
红色Tanh 函数,有压缩功能的激活函数,但是由于本身弊端比较多,被Relu取代。
Tanh 函数表达范围(-1, +1)
蓝色 对三值量化之后的范围进行一些人为的调整 加上系数和偏置
模型的表达能力提高,效果有了改善,但有一些抖动。
橙色tanh函数:根据论文对tanh函数进行改造 效果最好。
再参数化

在实际中bit数往往是固定的,数值选取受限于2^k个。
这里是在quantization range 的角度进行优化。
我们对Activation和Weight 进行一些变换,我们没有在Weight设置偏置项是避免引入一些额外的计算量。
这里的α,γ,β,都是网络自适应训练的,训练后每层的α,γ,β值也是不同的。
这种方式α,γ,β相关的计算也是很高效的,不必担心影响速度。
我们网络在部署的时候由于权重Weights 是固定的 可以把这些 部署到硬件上面。
论文中发现最好的稀疏程度在60%左右,而不是Relu对应的50%。
当然网络太稀疏会使模型的性能变差。
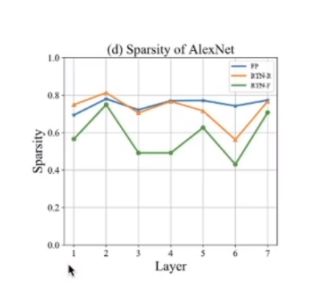
绿色:原本三值 蓝色:人为调整参数 来量化 橙色 :这里的优化方式 可以看到和人为调整还是吻合的。
效果:

这里TTQ 是一种非均匀三值量化。
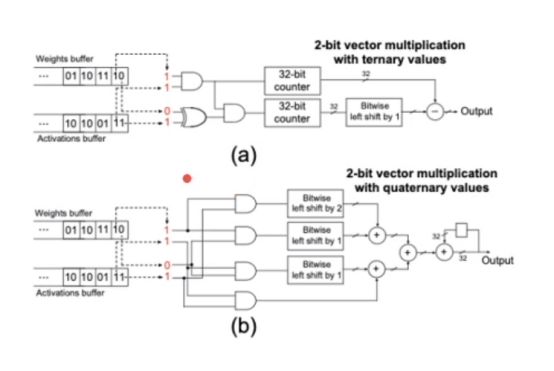
一般三值网络都是使用2 bit 来存储的,浪费了一位。
这里通过特殊的电路设计来优化了计算速度。避免了使用32 bit counter。
量化存在问题二
如何选择量化范围和量化精度
![]()
上面解释过这个问题。
下面的部分是指量化函数把连续的参数离散化的阈值的选取堆网络精度的影响。
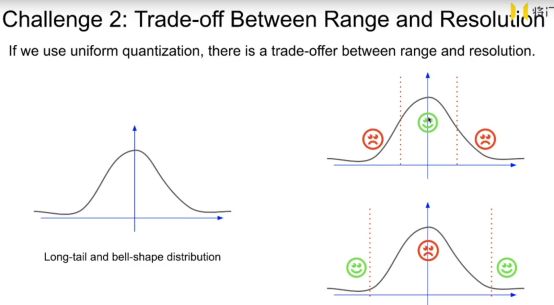
参数的分布

长尾效应:处于边缘的一些值的绝对值数值都很大
数据分布的形状是一个钟形形状。

第一种划分方式:阈值选取离参数分布集中的区域近,这种方式可以合理的离散化中间集中分布的参数。但是处于边界,数值较大的参数被划分到较小的阈值上,这些绝对值数值大的参数对网络是有一些影响的,这样划分对这些数值是不合理的,也会影响网络的精度。
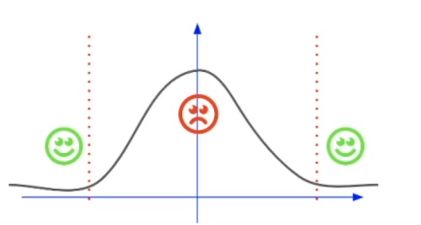
第二种划分方式:与之前划分方式相反,这种方式侧重考虑了边界数值较大的参数,可以合理划分边界参数。但是却忽略了中间的参数,中间参数虽数值较小,但是占比多,这种方式显然也是不合理的。
解决办法 通过训练来使loss 自适应的选择 cliping threshold

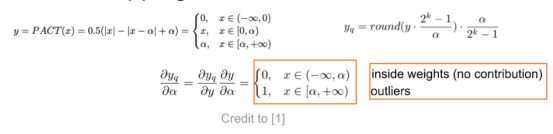
第一种方式是来使用α来作为阈值。
这种方式有有一个问题:只有处在外部的参数的梯度不为0,只有外部的参数才能起到优化cliping threshold的作用,内部的参数梯度为0,不能对优化起到作用。

第二种方法统一的考虑到了内部参数和外部参数。也就是全局的参数。
量化存在问题三
均匀量化还是非均匀量化

可以看到这个分布是不均匀分布,那么我们使用均匀量化方法来量化非均匀分布显然是不合理的。但实际还是使用均匀量化 硬件友好。
能不能找一个非均匀量化函数,且在硬件上非常高效呢。
这个地方表述不好就直接截取的官方文档

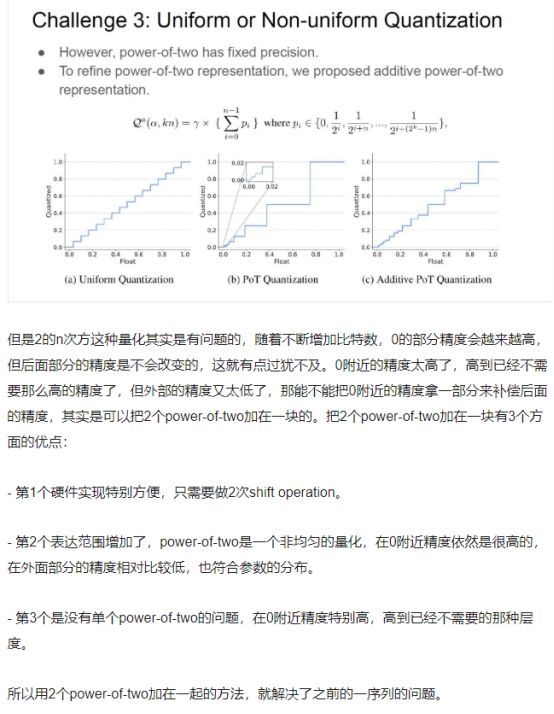
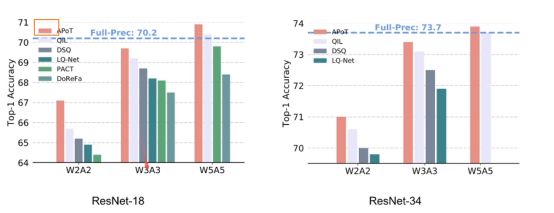
超过了全精度网络
两次power of two 加载一块不用做乘法了,都是shift operation
我们能剪枝量化之后的网络吗?
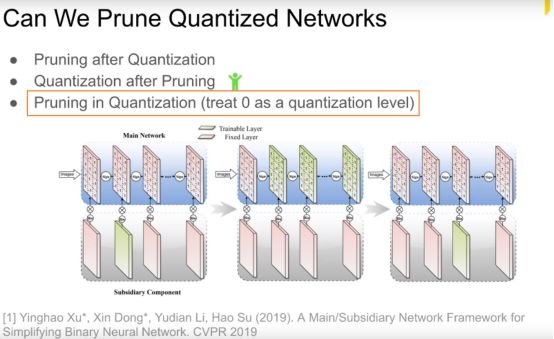
剪枝和量化同步操作是考虑到这两种方式的共同点,相当于把更多的数量化的0的位置。
是一个新的方向。
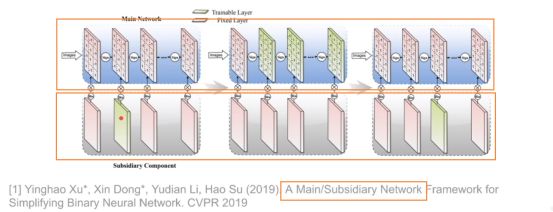
一个二值网络 分为两部分 上面为主网络 下面为副网络 表示上面的对应的网络 的通道是否被取消1 保留 0 有去掉的操作。
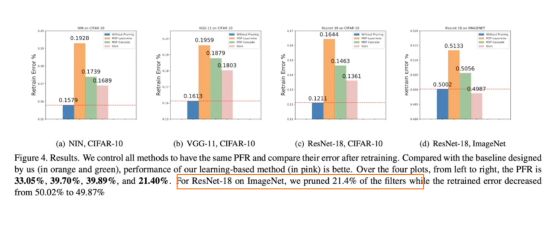
性能有些提升,说明二值网络也存在一些冗余性的。
有什么方式可以补足量化/剪枝对模型带来的精度的下降。
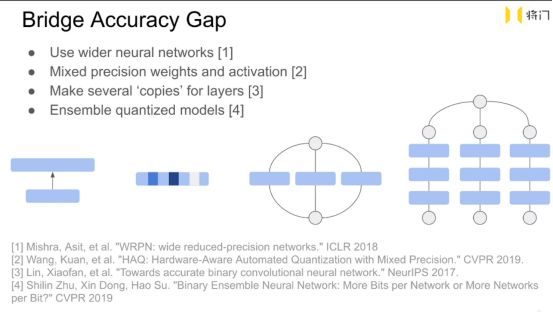
1 加宽网络 性价比高 好实现
2 对不同重要性的参数在量化的时候 赋予不同的bit 但是这可能带来一些计算的问题
3 同样的一层 三种不同量化方式 后结合 (but 为开源 需自己调参复现)
4 三个网络结构相同的网络 进行begging boosting 投票。
这个在性能好的硬件上 可以实现3个网络并行

1量化+
2 Binary Neural Networks 位运算 but 第一层 和最后一层比较敏感 一般使用8 bit 方式
3训练的时候可以使用量化吗(对 梯度 中间结果等)
4 mismatch 问题
5 给出理论分析固定那些模型有最小的bit 值
6 量化+ 硬件加速 或者 TVM
其他:
BN层的量化:BN层使用量化会是loss 出现非常大的误差变化,是现在为解决的问题。
CVPR2019 提出了一些关于检测量化的paper。