预测模型——灰色模型
网上有许多大佬写的灰色预测模型,写的非常的棒,但是我个人感觉,在公式部分,许多大佬在写最小二乘法得出a,b的值的时候并不是那么细致,所以我写这一篇灰色模型既是详细介绍公式的由来,同时也是为后续我要写的组合模型,如灰色模型与神经网络的结合,灰色模型与马尔可夫链式模型的结合做一个铺垫,希望对大家有帮助。
1,灰色系统介绍
灰色系统是由华中科技大学的邓聚龙教授于80年代初创立,该系统作为新兴的横断学科,在短短的二十年里已得到了长足的发展。 其已经成为社会,经济,科教,科技等很多领域进行预测,决策,评估,规划,控制,系统分析和建模的重要方法之一。特别是它对于时间序列短,统计数据少,信息不完全系统的建模与分析,具有非常显著的功效。
灰色预测是一种对含有不确定因素的系统进行预测的方法。灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。其用等时距观测到的反映预测对象特征的一系列数量值构造灰色预测模型,预测未来某一时刻的特征量,或达到某一特征量的时间。
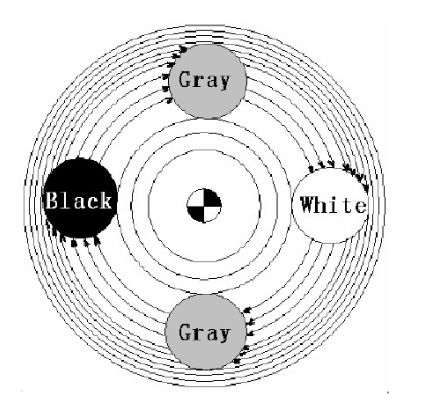
2.1 灰色系统的基本原理
公理1,差异信息原理
”差异“是信息,凡信息必有差异。
公理2,解的非唯一性原理
信息不完全,不确定的解是非唯一的。该原理是灰色系统理论解决实际问题所遵循的基本法则。
公理3,最少信息原理
灰色系统理论的特点是充分开发利用已占有的”最少信息”。
公理4,认知根据原理
信息是认知的根据。
公理5,新信息优先原理
新信息对认知的作用大于老信息。
公理6,灰性不灭原理
“信息不完全”是绝对的。
2.2 灰生成技术
灰色序列生成:是一种通过对原始数据的挖掘,整理来寻求数据变化的现实规律的途径,简称灰生成。
灰生成特点:在保持原序列形式的前提下,改变序列中的数据的值与性质。一切灰色序列都能通过某种生成弱化其随机性,显现其规律性。
灰生成的作用
-
统一序列的目标性质,为灰决策提供基础。
2.将摆动序列转化为单调增长序列,以利于灰建模。
3.揭示潜藏在序列中的递增势态,变不可比为可比序列。
常见的几种灰色生成类型:
1.累加生成算子(AGO)
2.逆累加生成算子(IAGO)
3.均值生成算子(MEAN)
4.级比生成算子
1.累加生成算子(AGO)
定义 累加生成算子是对原序列中的数据依次累加得到的数列。

我们对比一下生成后的区别
说白了就是运用累加从而使得一个无规律的数列,变成一个递增数列。

2.逆累加生成算子(IAGO)
逆累加生成算子其实就是累减生成,上面是累加,计算步骤跟上面差不多,就是变成了减号罢了。
首先我们先生成序列

我们举个例子
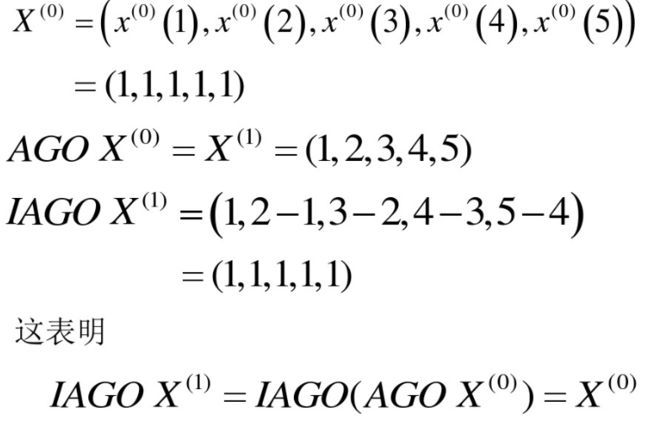
3.均值生成算子(MEAN)
看到标题大家可能就知道怎么计算了,我们需要将序列中的前后相邻的两数取平均数,以获得生成新的序列。
![]()
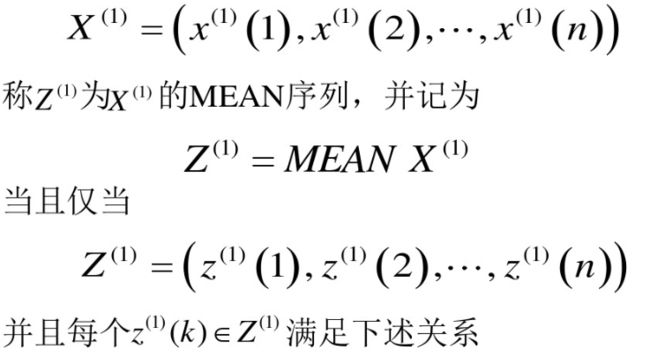

我们接着举例

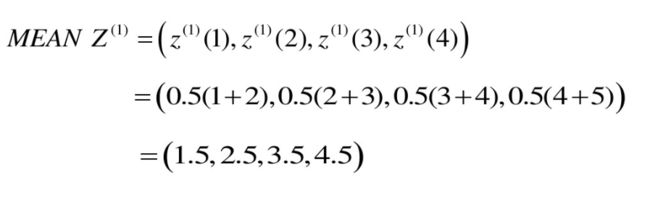
4.级比生成算子

2.3 GM(1,1)模型
我们先简单说明一下模型成立的前提,灰色理论认为一个系统的行为现象虽然是朦胧的,数据是复杂的,但是他一定会包含一定的规律在其中,如果你了解过傅里叶,那么你可以很轻松的理解一个系统暗含规律的情况。灰数的生成就是为了从杂乱的数据中找到规律。因此灰色模型所用的数据是生成数据而非原始数据。

我们在这里先引入最小二乘法,我们再继续。(大家高中都学过,但是我还是详细解释一下,为了让零基础的朋友都能“学废”这个模型。)
最小二乘法一般应用于线性回归,例子我就不举了,直接上公式。
y=β0+β1x这是我们要求的回归曲线,目前的问题就是β0和β1怎么求。
首先我们要明确:
1.我们假设在测量系统中不存在有系统误差,只存在有纯偶然误差。比如体重计或者身高计本身有问题,测量出来的数据都偏大或者都偏小,这种误差是绝对不存在的。(或者说这不能叫误差,这叫错误)
2.误差是符合正态分布的,因此最后误差的均值为0(这一点很重要)
明确了上面两点以后,重点来了:为了计算β0,β1的值,我们采取如下规则:β0,β1应该使计算出来的函数曲线与观察值的差的平方和最小。用数学公式描述就是:
在这里大家可能会有疑问,为撒子要用平方,而不是绝对值方差,从数学的角度来看,绝对值的现实情况要复杂的多,而平方相对更加容易一点。
接下来我们明确如何求解:

y=β0+β1x
相信大家看完如何求解之后对最小二乘法已经有了了解,那么我们就需要引入矩阵表达式,因为矩阵表达是才是解读灰色预测模型的关键。
当我们有许多变量时,我们就需要引入矩阵表达式,假如我们有许多变量,我们的线性函数表达式如下

这个最后的最优解非常非常非常重要!!!!!!!!
大家会在后续的灰色预测模型中见到它。
2.4 G(1,1)模型参数确定
在这个公式中

a和b是参数,这个公式是不是和最小二乘法特别像,我们开始定义矩阵
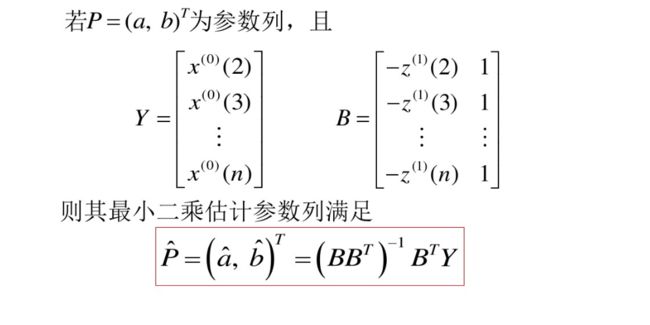
看到了嘛,这个公式出现了,不知道计算过程的,抓紧去上面补课!!
下面我们来求解这个函数
通过对一般微分方程的剖析定义的灰导数,从而我们可以利用离散的数据序列建立近似的微分方程模型:

很多人疑问这个方程怎么来的,其实这个方程的建立就是拟合的过程,而为什么要选用微分方程,而不是线性方程,或者指数方程,这是因为邓教授受到美国加利福尼亚教授T.C.Hisa的影响,“对于生命科学,经济学生物医学最好是建立微分方程”。
白化方程其实就是列出的G(1,1)模型基本形式的前身。
下面我给大家推导一下,让大家明白到底怎么来的。首先,我们将白化方程离散化,即两边同时积分

上式中左边第二个式子中

因此我们得到了上面所述的基本形式
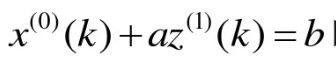
因此我们有了a,b参数的计算方法,计算出a,b然后代回到白化方程中。
我们可得到
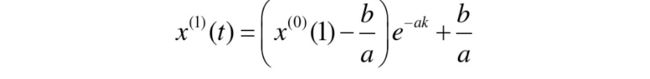
然后我们得出
看到这个公式大家可能会懵一下,这原始数列预测值是啥?
记得我们在处理原始数据时,是不是将它们累加生成数据,所以得出第一个公式预测的结果是生成数据的预测值,因此要把它们减去前一项,从而还原成原始数据。所以得出了原始数据的预测公式。
3.1 模型精度的检验
既然我们完成了模型,是不是要检验一下它呢?在这个模型中一般采用残差,相对误差来计算该模型的精度。
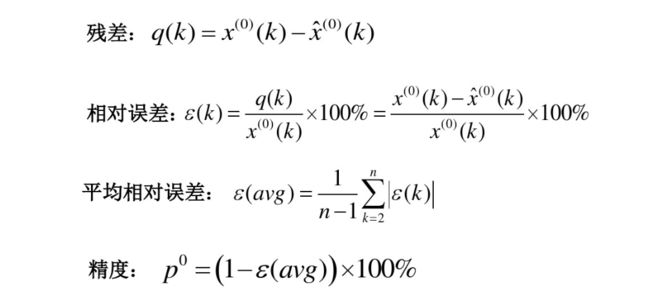
4. 总结
第一步:级比检验,建模可行性分析
第二步:数据变换处理
第三步:用G(1,1)建模
第四步:模型检验
5. 实例
下列图表为某城市1986-1992年交通噪声平均声级数据
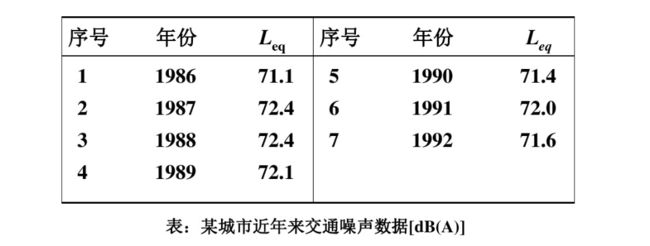
1,我们建立交通噪声平均声级数据时间序列:

3.判断级比:
我们可以看到所有数据均符合,故可以进行建模






接下来,我用DPS系统来给大家演示一下
首先创建数据集合

接着我们选择预测两年的数据
得出结果
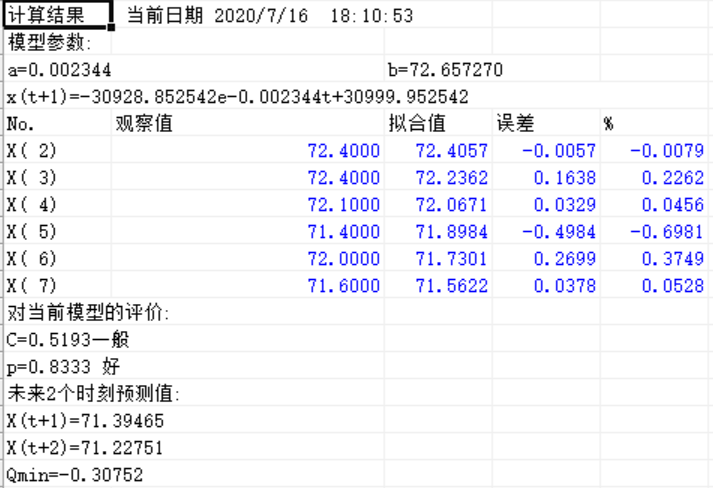
我们可以观察到,该模型拟合效果非常的好,将小数点保留一位时,与原始数据相差无几。而且P值为0.8333在保留一位小数的情况下,P值为0.998.故精度很高。
这节就先讲到这里,接下来我会具体介绍有关灰色模型的组合模型。
大家有需要可以加公众号哈~
