【集合】01HashMap原理深入解析
HashMap内部是基于哈希表实现的键值对存储,继承 AbstractMap 并且实现了 Map 接口。
结构和底层原理
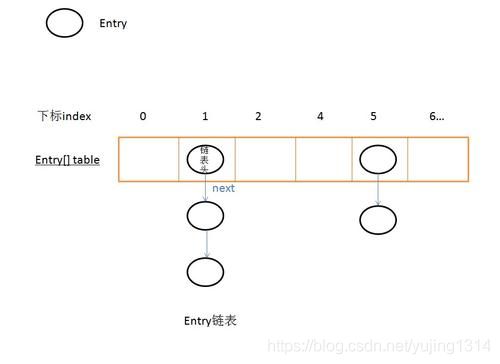
数组里面每个地方都存了Key-Value这样的实例,在Java7叫Entry在Java8中叫Node。
JDK1.8之前
基本的数据结构如下,一个key,value被称为一个Entry

因为每个数据刚开始都是Null,所以在put插入的时候会根据key的hash去计算一个index值,如果hash的Index值一样形成hash冲突,就会向下图一样形成链表
如何扩容
扩容分为两步
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新哈希?,来看一下 Hash的公式
Hash的公式—> index = HashCode(Key) & (Length - 1)
因为扩容之后长度变了,Hash的规则也随之改变。
扩容前
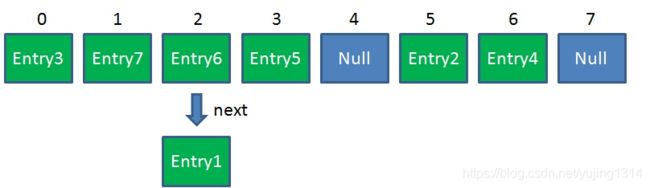
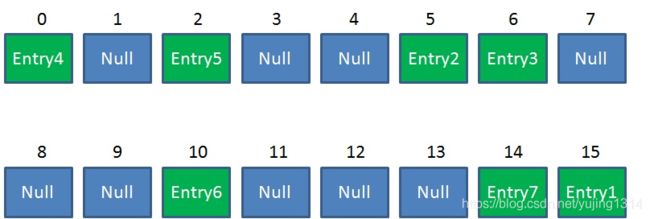
扩容后之后
HashMap为什么线程不安全(jdk1.7)
JDK1.7之前采用头插法
假如有3个线程分别插入A-B-C如下图所示,此时要插入D,且index为2,因为负载因子为0.75,所以插入第二个元素就会触发扩容
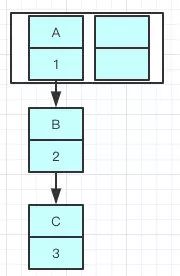
B的下一个指针指向了A

一旦几个线程都调整完成,就可能出现环形链表

具体如何出现的环形链表呢?
未扩容前
扩容后
在多线程环境下,假设有两个线程A和B都在进行put操作。线程A在执行到transfer函数中第11行代码处挂起
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length; // 将复制出的新数组的长度给新的容量
// 将原有数组的Entry分别操作
for (Entry e : table) {
// 当原有数组的一个Entry不为空时
while(null != e) {
// 将这个节点指针指向next,当A线程第一次执行时,next=B;
Entry next = e.next;
// 如果是扩容rehash为true
if (rehash) {
// 判断e的key是否为null,如果是则赋值0,否则重新hash
e.hash = null == e.key ? 0 : hash(e.key);
}
// 求出重新Hash之后的index值
int i = indexFor(e.hash, newCapacity);
// e节点指向新数组索引为i的元素
e.next = newTable[i];
// 将e节点放入新数组索引为i的数组位置
newTable[i] = e; // A线程在此挂起
// 将B给e
e = next;
}
}
}
线程A的运行结果如下:
分析:A线程挂起时,e.next = newTable[i]这行代码已经执行了,因为此时newTable[i]还没有值,也就是结点A指向了空元素而B数组依然指向C,C指向null

线程A挂起后,此时线程B正常执行,并完成resize操作,结果如下:
当线程B执行完毕,由于JMM,现在newTable和table中的Entry都是主存中最新值,B指向A,A指向Null
newTable[0]=e ----> newTable[0]=A
e=next ----> e=B

继续循环
e=B
next=e.next ----> next=A【从主存中取值】
e.next=newTable[0] ----> e.next=A【从主存中取值】
newTable[0]=e ----> newTable[0]=B
e=next ----> e=A
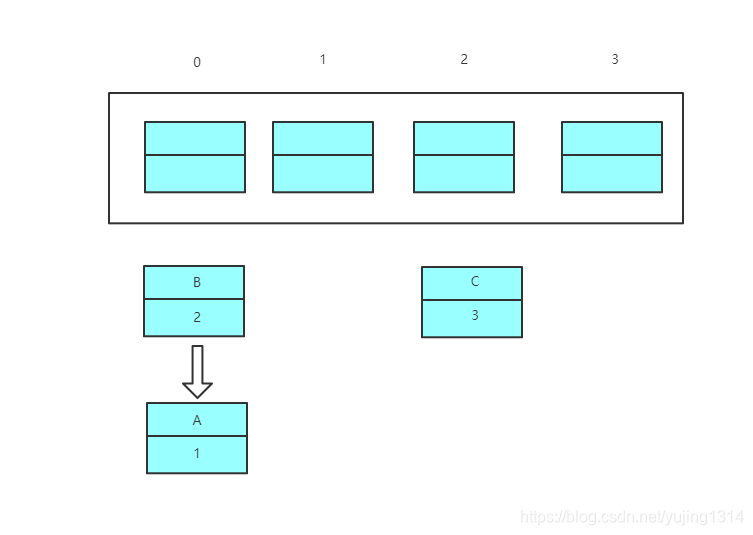
因为代码中 while(null != e) 才会结束,e=A则不会结束,继续执行
e=A
next=e.next ----> next=null
e.next=newTable[0] ----> e.next=B 即:A.next=B
newTable[0]=e ----> newTable[0]=A
e=next ----> e=null
此时形成了环形链表,e=null结束循环
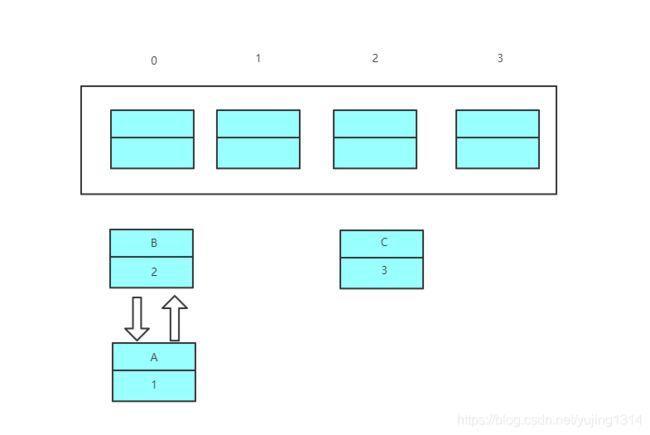
轮询hashmap的数据结构,就会在这里发生死循环
JDK1.8之后
基本数据结构
如下图,JDK1.8之后HashMap底层采用数组+链表+红黑树的数据结构,默认容量16,负载因子0.75

默认容量为什么是16
首先看一下,HashMap如何求索引
static int indexFor(int h, int length) {
return h & (length-1);
}
可以看出采用的是& 运算
由下面的公式可以分析
X % 2^n = X & (2^n – 1)
只要保证length的长度是2^n 的话,就可以实现取模运算了
初始容量只要是2^n就可以了,16是一个经验值
传入的默认容量是最终的容量吗?
不是的,HashMap会经过下面的代码,自动给你扩容到2的指数幂
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
总之,HashMap根据用户传入的初始化容量,利用无符号右移和按位或运算等方式计算出第一个大于该数的2的幂。
为什么扩容是2倍
为了保证HashMap的容量永远是2的指数幂,来保证求索引公式正确
return h & (length-1);
在JDK 1.7和JDK 1.8中,HashMap初始化这个容量的时机不同。JDK 1.8中,在调用HashMap的构造函数定义HashMap的时候,就会进行容量的设定。而在JDK 1.7中,要等到第一次put操作时才进行这一操作。
HashMap为什么线程不安全(jdk1.8)
不再采用头插法方式,而是采用尾插法,因此不会出现环形链表的情况,但是却依然不安全,看看HashMap的put方法

在多线程环境下,线程A,B都走到了630行处,都判断了此处节点为空,此时A挂起,B插入新节点之后A恢复,A线程插入的值会覆盖B线程插入的值。
总结
- HashMap是线程不安全的,jdk1.7因为头插法所以容易死循环,jdk1.8则会发生覆盖,要想解决线程安全问题可以更换collections下面的同步容器,推荐使用juc包下的concurrentHashMap
- HashMap的初始值是16是一个经验值,最终目的是为了方便计算索引时使用位与运算,提高效率
- 扩容是2倍也有为了保持容量为2的指数幂的原因
- 容量为2的指数幂也实现了让值均匀分布,因为在使用不是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。