第十五届全国大学生智能汽车竞赛人工智能创意赛(预赛)
第一章 方案概述
1.1 车道线巡线部分方案概述
1.1.1 创新点
- 编写连续采集代码,实现小车的数据收避免每一圈便要下载 编写连续采集代码,实现小车的数据收避免每一圈便要下载 编写连续采集代码,实现小车的数据收避免每一圈便要下载 一 次数据和剔除的过程,极大地提高了收集效率 。
- 编写 文件合并的代码,实现众多数据得到最终模型训练集。
- 在车道线模型训练时,根据之前初赛的经验采用余弦衰减学习率设 在车道线模型训练时,根据之前初赛的经验采用余弦衰减学习率设 在车道线模型训练时,根据之前初赛的经验采用余弦衰减学习率设 置方法,使模型更快收敛效果好。
- 在控制小车自主运行时,试验用三次样条插值法、 在控制小车自主运行时,试验用三次样条插值法、 matlab拟合、分段式插值 拟合、分段式插值 拟合、分段式插值 等方法,对小车返回的预测值进行处理。
- 对小车使用分段式 PID算法控制,是 小车以最高速 度运行。
- 试验编写传统摄像头自动寻线算法和 OpenCV算法实现小车的自主运行,但 算法实现小车的自主运行,但 是最终发现两者均不如神经网络训练出的模型控制效果好。
- 在后期调试过程中, 发现存脏数据编写自动剔除代码在后期调试过程中, 发现存脏数据编写自动剔除代码在后期调试过程中, 发现存脏数据编写自动剔除代码剔除 后重新收集 。
- 对比测试低速收集数据与高所训练出来的模型效果,因为我们最终 对比测试低速收集数据与高所训练出来的模型效果,因为我们最终
1.1.2 技术实现路线
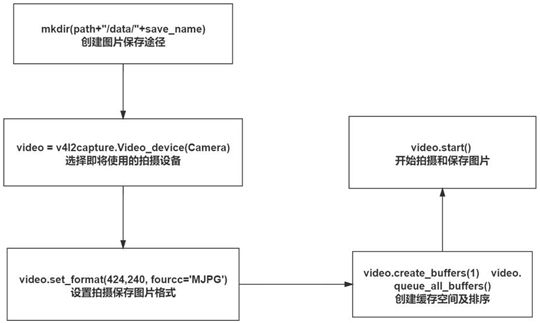
1. 数据采集
车道线数据的采集修改手柄代码使小车能够实现一直采集的功能,按照官方的车道线采集代码(data_coll.py),小车只能实现逐圈收集,于是我们修改该收集代码使其能连续收集,提高了收集效率。
多次收集的数据分散在各个文件夹中需要处理成一个文件夹且图片名称与txt 文件行数一一对应的标准形式。为提高效率,同时避免出现错误,我们编写车道线数据合成代码一键生成可用于训练的标准形式。
2. 模型训练
修改车道线模型优化方法为学习率余弦衰减,根据初赛训练模型效果的经验, 我们选择模型训练效果更好的学习率余弦衰减的设定来替换官方示例中的恒定 学习率,取得了更好的实际运行效果。
3. 数据调参
通过对数据的观测和数据统计,对数据进行分段处理,调节 PID 来实现小车的自主巡线。经过尝试和调参,同时对特定路况的 PID 单独调整和设置,使小车能够以最高速度顺滑地跑完全程。
4. 后期优化
S 弯接 Q 弯的实际表现较差,无法找到 predict 输出与实际应该打角的关系, 经过讨论,我们认为是数据采集时手柄操作不够娴熟而导致采集到的数据训练效果较差。于是修改数据集把有漏洞的数据剔除,填补新采集的数据,再进行训练。后期发现低速采集的数据不适用于高速状况下的状态判断,再次以 1600 的速度进行了重采,模型输出稳定性有了显著提高。
1.2 标志物识别部分方案概述
1.2.1 创新点
- 多角度、多距离、多情景地采集标志物图样,增加模型识别标志物地准确率。
- 编写 OpenCV 自动标注算法,利用算法提取各个标志特征,并对其进行高效精准地标注,极大程度上提高精度,节省人力,同时我们也尝试了 EasyDL 的只能标注,但是标注完成后无法下载数据集。
- 试验出官方外的其他模型,使用 PaddleX、PaddleDetection 工具里的模型进行训练,使用我们自己编写的 SSD 网络进行训练,最终经过剪枝、蒸馏变成可以上传到小车上的大小,但是由于小车上的软核无法升级,最终我们的模型无法部署到小车上。
- 编写各个标志物的识别代码,设定标志物之间的逻辑关系,设定标志物的识别条件,利用标志物来辅助车道线的运行。
- 调整标志物模型的预测周期,小车同时进行车道线和标志物模型的预测周期较长,将标志物模型的推测周期设定车道线预测周期的三倍,即每预测三次车道线,预测一次标志物,这样极大地提高了小车的运算速度,提高了控制小车串口指令的发送速率。
1.2.2 技术实现路线
标志物识别分为四个过程:数据采集、标志物标注、模型训练、标志物功能。
-
数据采集
为保证模型学习到正确的标志物信息,对于固定位置的标志,我们从多个角度、多种距离进行数据采集,保证数据的全面性;对于可移动的标志(障碍物、红绿灯),在固定标志基础上,对标志物摆放的不同角度进行了更多样化的采集。 -
标志物标注
由于人工使用 labelimg 标注费时费力且准确率无法得到保证,所以我们尝试使用 OpenCV 进行标注,通过阈值化、提取外接矩形框等方法提取图片信息对数据集进行自动标注。 -
模型训练
利用 PaddleX 等工具训练标志物模型并部署,全流程的 PaddleX 和自主选择库的 PaddleDetection 可以更为直观和方便的调整模型参数等,但由于软核升级后仍无法部署,且官方例程对标志物的实际识别效果足以达到需求,遂中止尝试。 根据初赛的模型训练经验,我们选择模型训练效果更好的学习率余弦衰减的
设定来替换官方示例中的恒定学习率,取得了很不错的收敛效果和实际效果。 -
标志物功能
经过四版的改进,我们最终确立了标志框位置、标志框置信度、标志位限制相结合的控制逻辑和精准延时、车道线边沿检测的辅助控制方法。
1.2.2 技术实现路线
标志物识别分为四个过程:数据采集、标志物标注、模型训练、标志物功能。
1. 数据采集
为保证模型学习到正确的标志物信息,对于固定位置的标志,我们从多个角度、多种距离进行数据采集,保证数据的全面性;对于可移动的标志(障碍物、红绿灯),在固定标志基础上,对标志物摆放的不同角度进行了更多样化的采集。
2. 标志物标注
由于人工使用 labelimg 标注费时费力且准确率无法得到保证,所以我们尝试使用 OpenCV 进行标注,通过阈值化、提取外接矩形框等方法提取图片信息对数据集进行自动标注。
3. 模型训练
利用 PaddleX 等工具训练标志物模型并部署,全流程的 PaddleX 和自主选择库的 PaddleDetection 可以更为直观和方便的调整模型参数等,但由于软核升级后仍无法部署,且官方例程对标志物的实际识别效果足以达到需求,遂中止尝试。 根据初赛的模型训练经验,我们选择模型训练效果更好的学习率余弦衰减的
设定来替换官方示例中的恒定学习率,取得了很不错的收敛效果和实际效果。
4. 标志物功能
经过四版的改进,我们最终确立了标志框位置、标志框置信度、标志位限制相结合的控制逻辑和精准延时、车道线边沿检测的辅助控制方法。
1.3 创意部分方案概述
创意部分包含两个项目:简易版如影随形、按标志物指示避障。
1.3.1 如影随形
根据决赛项目如影随形的规则:在比赛区域的起点和终点之间,随机放入了大量锥桶。比赛开始时,参赛队员从起点行进到终点,允许骑乘交通工具。车模跟随参赛队员,车模在运行过程中需要跟随参赛队员运行,最快到达终点且中途没有触碰锥桶的队伍获胜。 我们实现了简易的如影随形,以参赛队员手持AprilTag 码作为引导,小车识别 AprilTag 码,将识别到的 AprilTag 码中心点偏离图像中心的偏差转化为角度,实现小车跟随 AprilTag 码转弯,以此实现简易版如影随形。
主要实现效果为:小车在运行过程中跟随人运行,在自行设计的赛道中完整的运行一圈,且不碰撞赛道中的障碍物。根据如影随形需要全程跟随人的这一需求,我们使用了 AprilTag 作为标识,利用小车上的 OpenCV 对其进行识别,对AprilTag 进行灰度处理、高斯滤波、边缘检测、轮廓提取可以精准的找出标识位置,再进一步找出 AprilTag 的中心点坐标。由于小车上搭载的摄像头拍摄的图片分辨率为 320×240,以图片中心(160,120)与 AprilTag 的中心点进行比较, 可以计算出当前小车与人的相对位置的对应所需的打角,从而达到小车能够始终跟随人的踪迹。其中打角的确定是根据多次采集数据,最终拟合一条二次曲线, 使得打角顺滑且保证能够更好的跟随人。
1.3.2 避障
主要实现效果为:当小车检测到障碍物时,会按照障碍物上的箭头方向进行避障;当检测到调头标志时,会掉转车头运行(即再次从起点出发)。 针对避障创意部分,我们对标志物动作进行了进一步的方案设计和逻辑完善。
我们采用在绿色方块上用黑色 Mark 笔涂图案的方式对车辆的动作进行引导。由于目标较小且大体均为绿色正方体(见图 1.1),对识别的精度提出了很高的要求。 yolov3_tiny 模型的轻量化使得其在面对相似的小目标时误识别率较高、置信度较低。我们通过增大标志间的区分度、利用红绿灯一定会和斑马线一同出现、调头是出现在第一次停车之后等实际状况和运行需求来对识别结果加以过滤和限制。增加识别稳定性,同时增大不同标志的区分度,使之可以完成复杂动作。
例如:障碍块置于赛道上,在车辆行驶到赛道不同段时会多次识别到此障碍物。因此,我们设计了时间顺序逻辑以及障碍物目标框中心点阈值(超出阈值范围则认为不在当前行进路线上)来实现完整的避障表演流程。车辆在两次分别按照标志物上的箭头方向完成避障任务后,在绕行一圈回到停车起点后再次启动, 识别到前方的调头标志会自动调头,重新开始行进,实现了不循环赛道的长时间、全区段运行和持续避障、完成标志物元素对应动作(见图 1.2,1.3)。

▲ 图1.1,图1.2, 图1.3
第 2 章 问题描述
对于本次复赛赛题,我们经过分析后得出了先按照官方流程进行操作,再对效果不好的方面进行优化的总体调车思路。通过对官方资料的复现,提出了如下问题和解决方案。
2.1 车辆部分
1. 问题: 车体连接电脑状况不稳定,每次开机会耗费大量时间连接电脑;数据传输和指令传输不稳定导致车辆容易卡死。
解决:使用指令结束当前进程,可以不用每次在进程占用的时候重启车子; 编写连续采集程序,可以一次数据传输采集多圈数据;在确保程序正确的情况下使用 nohup 指令,可以让小车不在电脑上输出日志,减小断连导致的失控风险。
2. 问题: 手柄的控制二值化,无法进行详细控制,通过遥控无法采集到可以让神经网络训练出遵循统一规则的图片<–>输出关系。
解决:通过少量多次打角操控车辆转向,加大采集时的运行速度使得车辆转弯更加流畅。通过对训练出的车道线模型进行调优后再次使用此模型自动进行采集、然后再次调优的方式逼近完美路径。
3. 问题: 车载的 PaddleLite 环境版本太低且无法升级,导致 PaddleDetection 和 PaddleX 训练出的轻量级模型也无法正确推算,在经过各种尝试后确认无法搭载,也无法对车载 PaddleLite 进行升级。
解决: 在经过多天各方面尝试后, 发现只有 fluid 格式模型可以在PaddleLite0.0.1 版本上正常推断,又因为官方例程中给出的 yolov3_tiny 在增大训练集、改正图像颜色后可以达到识别速度和精度的要求,遂决定只对此模型进行配置上的优化,而不浪费时间搭载其它模型(性能达标,不需要继续浪费更多的时间在无用功上)。
2.2 车载代码部分
1. 问题: 官方代码内容全但是很多部分不需要被使用,会增加处理器的运算负担,需要重新整理。
解决:重新编写了 Auto_Driver_Client,优化冗余项、加载项和无关函数,减少不必要的算力浪费。
2. 问题: 官方模型中给出的部分代码无法正确执行,例如转置图片格式为 RGB 的语句,经多次查错后发现是这个语句没有正确运行导致车对于标志物的误判情况严重。
解决: 增加 BGR2RGB,这个问题的难度主要在排查上,发现车辆预测结果 和电脑端预测结果不同时,经过多次测试才找寻到问题根源。
3. 问题: 车载 CPU 处理性能有限,在多进程并行时,需要对每个进程中程序的功能做了限制;在 Auto_Driver 及 Auto_Driver_Client 中,若要保证车辆反应速度足够,就要改进算法来减小程序的时间复杂度。
解决: 减少 while 循环,简化循环内指令;对不明原因无法进入的 if 条件进行优化;对处理慢的程序的图像输入尺寸进行压缩,在保证准确率的前提下加速推算;减少标志物检测模型推算次数,在保证标志物不会漏检的前提下提升车道线预测值输出的反应速度。
2.3 车道线部分
1. 问题: 车道线部分模型使用二值化后图像进行训练,受到环境因素影响较小 (需调整二值化阈值),但标志物模型使用原图训练,环境明暗、地面反光、标志物摆放角度都会影响识别精度。
解决: 对训练图像进行图像增强;在不同光照条件下采集标志物图片,保证模型在各种环境下运行的稳定性;采集多角度、多状况车辆运行情况下的标志物照片(包括没有照全的照片和倾斜照片),提升识别准确率。
2. 问题: 由于采集数据使用的手柄只有三个值的输出,车道线模型推算出的结果十分不稳定,导致控制部分难以使用统一的规则达成。
解决:分段控制,根据赛道一圈中标志物的出现顺序判断车辆当前位置,分段对车道线模型的推算结果进行处理;结合二值化后的图像,对中线自上而下进行扫描,辅助判断转弯。
2.4 标志物部分
1. 问题: 手动标记标志物存在误差,会导致卷积神经网络无法正确提取到标志的全部信息,同时,手动标记标志物存在效率低下的问题,而采集的数据量少则会导致模型过拟合,鲁棒性差。
解决: 利用 OpenCV 进行自动标注,高效率且标注框极为准确。
2. 问题: 标志物目标检测预测框输出位置不正确。
解决: 在经过大量采样观察找寻规律后发现,预测框输出的数据默认为图片尺寸为 608*608,对 boxes 做变换后输出位置正确。
3. 问题: 标志物被检测到的时机不定,给标志物动作的执行带来极大不确定性。
解决: 改进标志物检测模型、增加远距离对标志物拍摄的数据集以达到提早 检测的目的;利用目标框中心坐标辅助判断车体相对于前方标志物的距离,在到达阈值后再进行相应动作(近距离检测到的目标框更容易精确定位)。
第 3 章 技术方案
3.1 车道线采集代码的实现或优化方案
在采集大量车道线数据的过程中,由于官方的代码没有中途暂停采集图像和数据的设置,因此想采集大量数据,需要一圈一圈采集、下载、重命名、删除 data 文件夹……如此往复,无疑浪费了中途的时间,收集起来也不是很方便,于是我们构思了连续多次采集的方案,修改代码,使得在一次采集结束后,采集程序可以再次被开启,并接着上次的数据继续存储,方便我们每次遥控后将车搬回原点直接开始采集,省去了中间步骤、提高了采集效率。
3.2 车道线数据处理及模型训练的实现或优化方案
3.2.1 车道线数据处理优化方案
为保证模型鲁棒性,需采集较大量的车道线图片、对应打角数据。在这个过程中,无论是逐次逐圈采集还是多圈采集,都需要将每次采集的车道线数据文件夹下载并进行合并,并保证图片的序号与描述文件的行数相对应、从 0 开始重新对图片进行命名,以减少在云端的数据预处理复杂度。为了减少人工合并对时间的浪费,我们自行编写合并代码(见附录)进行自动合并。
为提高识别精度,调整了 HSV 阈值使之更符合赛道环境,并测得角度中值, 同时对项目中生成训练列表和验证列表的代码进行修改,改善训练效果。
通过 python 的 os 模块遍历所有采集的数据文件夹,将每个文件夹中的图片文件进行排序、提取并重命名,描述文件内容按顺序提取,保证数据和标签的一一对应,将其整合在一个总的文件夹下。对所有文件进行如上操作,最终自动整合成总计超过十万组数据和标签的数据集。
3.2.2 车道线模型训练优化方案
1. 学习率余弦衰减
线上预赛使用 aistudio 平台训练模型,在选择模型并调优的过程中,我们接触过学习率恒定、学习率分段衰减以及学习率余弦衰减等学习率设定方法。此次, 我们选择训练效果较好的学习率余弦衰减来替换官方示例中的恒定学习率,取得了不错的收敛速度和效果。
2. 针对效果不佳的弯道重新采集
得到训练完成的模型之后,我们将其搭载上小车后运行 auto_driver.py 并测试其效果,发现赛道中的 S 弯和 Q 弯运行不理想,有部分压线以及识别错误、打角不完全的情况发生。由于数据量巨大,为避免重复性工作,我们仅剔除了部分采集效果不理想的数据,并且重新采集同位置数据并入,通过编写代码实现了上述过程的自动化处理。
1. 学习率余弦衰减
使用随机梯度下降算法来优化目标函数,在接近 loss 的全局最小值时,学习率应该变得更小来使得模型不会超调且尽可能接近最优解。而余弦衰减(cosine_decay)可以利用余弦函数的图像特性来调整学习率。余弦函数中随着 x 的增加函数值首先缓慢下降,然后加速下降,再缓慢下降:在初期以较为稳定的学习率稳步降低 loss;在中期快速衰减、抵近最优解;在后期设置极小的学习率并缓慢下降、在最优解附近震荡以求得和真实情况最大程度的逼近(见图 3.1)。
2. 针对效果不佳的弯道重新采集
在对训练好的模型进行适配(根据模型的输出,推算模型去给车辆输出对应打角)的过程中,我们发现对部分弯道输出的预测标签很不稳定,推测是由于采集的时候没能按照标准的道路行进,使得模型不能正确的拟合出这部分图像和输出标签的对应规则。因此,我们对限速部分及 Q 弯部分进行了重新采集,结合人工筛选和程序的自动整合,完成了对"脏数据"的替换。重新训练后,这部分弯道的模型输出变稳定。

3.3 标志物采集代码的实现或优化方案
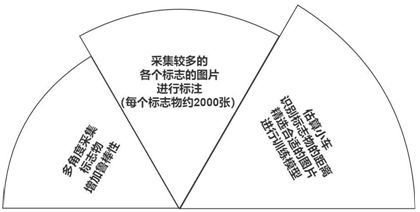
对于标志物的采集,我们采用将小车放在赛道上并在标志物前后反复以各种角度手推车的方法实现。一共采集了斑马线、红绿灯、直行、限速 10、取消限速、左转、停车七类标志,每类 2000 张左右。在手动筛选过后(将一些不包含标志物或者标志显示部分过少的图片剔除,保留了大小距离相对合适和一些略带模糊的图片,以增强模型的鲁棒性,提高小车在真实行进过程中的预测精度)。每类图片在 1300 到 1500 张不等,尽量保证数据集中各标签数量相当。涵盖了小车在行进过程中相对标志物不同距离和角度的图片(见图 3.2),避免模型学习到错误的信息,整体思路(见图 3.3,3.4)。

▲ 图3.2
▲ 图3.3
▲ 图3.4
3.4 标志物数据处理及模型训练的实现或优化方案
3.4.1 标志物数据处理优化方案
数据标注,在深度学习领域一直是一项重要而且费时费力的工作,数据标注的精准程度,决定了模型训练的优劣和预测结果的优劣。通常情况下需要人工标注,且使用 labelimg 等标注软件或者其他智能数据标注平台。我们首先尝试了EasyDL 平台上的智能标注,但标注完成后无法下载数据集。由于人为标注存在精度不高、标注速度较慢、不同人标注规则不尽相同且大量耗时耗力等问题,影响模型的训练和和最终的预测效果。因此我们编写了自动标注算法,采用OpenCV 对标志物进行高斯滤波、边缘检测、形态学滤波、阈值化、轮廓提取等图像处理步骤,将标志物自动识别并以高精度标注,这一步骤消除了人眼标注产生的误差,同时更重要的是节省了大量人工标注所需要的时间,使得我们能够有更多时间完成其他方面的优化。
通过 OpenCV 对标志物图片进行高斯滤波等预处理操作,然后根据每种标志物的特征(如颜色),进行 HSV 颜色阈值化,提取物体。或者直接利用最大类间方差法 OTSU 自适应阈值化方法–原理参考冈萨雷斯的《数字图像处理》。然后对阈值化的图像进行膨胀腐蚀等处理操作,消除噪点。再利用 OpenCV 中的findContours()函数提取标志物的轮廓,并对干扰物体轮廓进行筛选排除,例如对物体最小外接矩形框的长宽比、面积、旋转角度进行约束,直至找出符条件的标志物的最小外接矩形框。最后根据筛选获取出的信息,生成 xml 文件,实现标志物数据集的半自动标注。
- 对标志物图片的 HSV 颜色阈值化或 OTSU 自适应阈值化和三角 TRIANGLE 阈值化三角法求阈值[4] 最早见于 Zack 的论文《Automatic measurement of sister chromatid exchange frequency》主要是用于染色体的研究,该方法是使用直方图。