Unity Shader入门精要学习笔记 - 第13章 使用深度和法线纹理
转载自 冯乐乐的 《Unity Shader 入门精要》
获取深度和法线纹理
虽然在Unity里获取深度和法线纹理的代码非常简单,但是我们有必要在这之前首先了解它们背后的实现原理。
深度纹理实际上就是一张渲染纹理,只不过它里面存储的像素值不是颜色值而是一个高精度的深度值。由于被存储在一张纹理中,深度纹理里的深度值范围是[0,1],而且通常是非线性分布的。那么,这些深度值是从哪里得到的呢?总体来说,这些深度值来自于顶点变换后得到的归一化的设备坐标(Normalized Device Coordinates, NDC)。一个模型要想最终被绘制在屏幕上,需要把它的顶点从模型空间变换到齐次裁剪坐标系下,这是通过在顶点着色器中乘以MVP变换矩阵得到的。在变换的最后一步,我们需要使用一个投影矩阵来变换顶点,当我们使用的是透视投影类型的摄像机时,这个投影矩阵就是非线性的。
下图显示了之前给出的Unity中透视投影对顶点的变换过程,下图最左侧的图显示了投影变换前,即观察空间下视锥体的结果以及相应的顶点位置,中间的图显示了应用透视裁剪矩阵后的变换结果,即顶点着色器阶段输出的顶点变换结果,最右侧的图则是底层硬件进行了透视除法后得到的归一化的设备坐标。需要注意的是,这里的投影过程是建立在Unity对坐标系的假定上的,也就是说,我们针对的是观察空间为右手坐标系,使用列矩阵在矩阵右侧进行相乘,且变换到NDC后z分量范围将在[-1,1]之间的情况。而类似DirectX 这样的图形接口中,变换后z分量范围将在[0,1]之间。

下图显示了再使用正交摄像机时投影变换的过程。同样变换后会得到一个范围为[-1,1]的立方体。正交投影使用的变换矩阵是线性的。
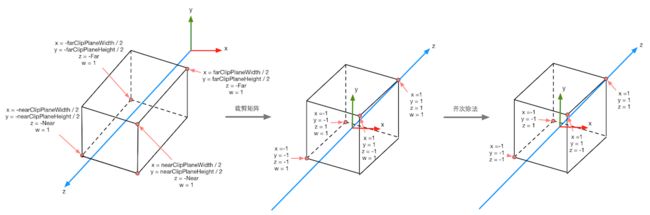
在得到NDC后,深度纹理中的像素值就可以很方便地计算得到了,这些深度值就对应了NDC中顶点坐标的z分量的值。由于NDC中z分量的范围在[-1,1],为了让这些值能够存储在一张图像中,我们需要使用下面的公式对其进行映射:
![]()
其中,d对应了深度纹理中的像素值,Z(ndc)对应了NDC坐标中的z分量的值。
在Unity中,深度纹理可以直接来自于真正的深度缓存,也可以是由一个单独的Pass渲染而得,这取决于使用的渲染路径和硬件。通常来讲,当使用延迟渲染路径时,深度纹理理所当然可以访问到,因为延迟渲染会把这些信息渲染到G-buffer 中。而当无法直接获取深度缓存时,深度和法线纹理是通过一个单独的Pass渲染而得的。具体实现是,Unity会使用着色器替换技术选择那些渲染类型为Opaque的物体,判断它们使用的渲染队列是否小于2500,如果满足条件,就把它渲染到深度和法线纹理中。因此,要想让物体能够出现在深度和法线纹理中,就必须在Shader中设置正确的RenderType 标签。
在Unity中,我们可以选择让一个摄像机生成一张深度纹理或是一张深度+法线纹理。当渲染前者,即只需要一张单独的深度纹理时,Unity会直接获取深度缓存或是按之前讲到的着色器替换技术,选取需要的不透明物体,并使用它投射阴影时使用的Pass(即LightMode被设置为ShadowCaster的Pass)来得到深度纹理。如果Shader 中不包含这样一个Pass,那么这个物体就不会出现在深度纹理中(当然,它也不能向其他物体投射阴影)。深度纹理的精度通常是24位或16位,这取决于使用的深度缓存的精度。如果选择生成一张深度+法线纹理,Unity会创建一张和屏幕分辨率相同、精度为32位的(纹理),其中观察空间下的法线信息会被编码进纹理的R和G通道,而深度信息会被编码进B和A通道。法线信息的获取在延迟渲染中是可以非常容易就得到的,Unity只需要合并深度和法线缓存即可。而在前向渲染中,默认情况下是不会创建法线缓存的,因此Unity底层使用了一个单独的Pass把整个场景再次渲染一遍来完成。这个Pass被包含在Unity内置的一个Unity Shader 中,我们可以在内置的builtin_shaders-xxx/DefaultResources/Camera-DepthNormalTexture.shader文件中找到这个用于渲染深度和法线信息的Pass。
在Unity中,获取深度纹理是非常简单的,我们只需要告诉Unity“把深度纹理给我!”然后再在Shader中直接访问特定的纹理属性即可。这个与Unity沟通的过程是通过在脚本中设置摄像机的depthTextureMode来完成的,例如我们可以通过下面的代码来获取深度纹理:
camera.depthTextureMode = DepthTextureMode.Depth;同理,如果想要获取深度+法线纹理,我们只需要在代码中这样设置:
camera.depthTextureMode = DepthTextureMode.DepthNormals;我们还可以组合这些模式,让一个摄像机同时产生一张深度和深度+法线纹理:
camera.depthTextureMode |= DepthTextureMode.Depth;
camera.depthTextureMode |= DepthTextureMode.DepthNormals;
float d = SMAPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv);float d = SMAPLE_DEPTH_TEXTURE_PROJ(_CameraDepthTexture, UNITY_PROJ_COORD(i.srcPos));当通过纹理采样得到深度值后,这些深度值往往是非线性的,这种非线性来自于透视投影使用的裁剪矩阵。然而,在我们的计算过程中通常是需要线性的深度值,也就是说,我们需要把投影后的深度值变换到线性空间下,例如视角空间下的深度值。那么,我们应该如何进行这个转换呢?实际上,我们只需要倒推顶点变换的过程即可。下面我们以透视投影为例,推导如何由深度纹理中的深度信息计算得到视角空间下的深度值。
我们之前已知,当我们使用透视投影的裁剪矩阵P(clip)对视角空间下的一个顶点进行变换后,裁剪空间下顶点的z和w分量为:
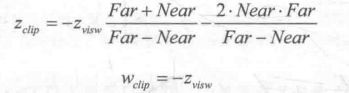
其中,Far 和 Near 分别是远近裁剪平面的距离。然后,我们通过齐次除法就可以得到NDC下的z分量:
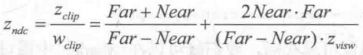
之前我们知道,深度纹理中的深度值是 通过下面的公式由NDC计算而得的:
![]()
由上面的这些式子,我们可以推导出用d表示而得的Z(visw)的表达式:
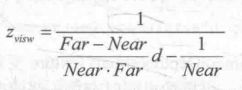
由于在Unity使用的视角空间中,摄像机正向对应的z值均为负值,因此为了得到深度值的正数表示,我们需要对上面的结果取反,最后得到的结果如下:
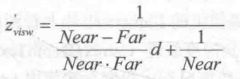
它的取值范围就是视锥体深度范围,即[Near,Far]。如果我们想要得到范围在[0, 1]之间的深度值,只需要把上面得到的结果除以Far即可。这样,0就表示该点与摄像机位于同一位置,1表示该点位于视锥体的远裁剪平面上。结果如下:
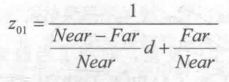
幸运的是,Unity提供了两个辅助函数来为我们进行上述的计算过程——LinearEyeDepth 和 Linear01Depth。LinearEyeDepth 负责把深度纹理的采样结果转换到视角空间下的深度值,也 就是我们上面得到的Z(visw)。而 Linear01Depth 则会返回一个范围在[0, 1]的线性深度值,也就是我们上面得到的Z(01),这两个函数内部使用了内置的_ZBufferParams变量来得到远近裁剪平面的距离。
如果我们需要获取深度+法线纹理,可以直接使用tex2D函数对_CameraDepthNormalsTexture 进行采样,得到里面存储的深度和法线信息。Unity提供了辅助函数来为我们队这个采样结果进行解码,从而得到深度值和法线方向。这个函数是DecodeDepthNormal,它在UnityCG.cginc里被定义:
inline void DecodeDepthNormal(float4 enc, out float depth,out float3 normal){
depth = DecodeFloatRG(enc.zw);
normal = DecodeViewNormalStereo(enc);
}很多时候,我们希望可以查看生成的深度和法线纹理,以便对Shader进行调试。Unity 5 提供了一个方便的方法来查看摄像机生成的深度和法线纹理,这个方法就是利用帧调试器。下图显示了帧调试器查看到的深度纹理和深度+法线纹理。

使用帧调试器查看到的深度纹理是非线性空间的深度值,而深度+法线纹理都是由Unity编码后的结果。有时,显示出线性空间下的深度信息或解码后的法线方向会更加有用。此时,我们可以自行在片元着色器中输出转换或解码后的深度和法线值,如下图所示。

输出代码非常简单,我们可以使用类似下面的代码来输出线性深度值:
float depth = SMAPLE_DEPTH_TEXTURE(_CameraDepthTexture,i.uv);
float linearDepth = Linear01Depth(depth);
return fixed4(linearDepth,linearDepth,linearDepth,1.0);
fixed3 normal = DecodeViewNormalStereo(tex2D(_CameraDepthNormalsTexture, i.uv).xy);
return fixed4(normal * 0.5 + 0.5, 1.0);
在查看深度纹理时,我们得到的画面可能几乎是全黑或全白的。这时我们可以把摄像机的远裁剪平面的距离(Unity默认为1000)调小,使视锥体的范围刚好覆盖场景的所在区域。这是因为,由于投影变换时需要覆盖从近裁剪平面到远裁剪平面的所有深度区域,当远裁剪平面的距离过大时,会导致离摄像机较近的距离被映射到非常小的深度值,如果场景是一个封闭的区域,那么这就会导致画面看起来几乎是全黑的。相反,如果场景是一个开放区域,且物体离摄像机的距离较远,就会导致画面几乎是全白的。
再谈运动模糊
在之前,我们学习了如何通过混合多张屏幕图像来模拟运动模糊的效果。但是,另外一种应用更加广泛的技术则是使用速度映射图。速度映射图中存储了每个像素的速度,然后使用这个速度来决定模糊的方向和大小。速度缓冲的生成有多种方法,一种方法是把场景中所有物体的速度渲染到一张纹理中。但这个方法的缺点在于需要修改场景中所有物体的Shader代码,使其添加计算速度的代码并输出到一个渲染纹理中。
《GPU Gems》在第27章中介绍了一种生成速度映射图的方法。这种方法利用深度纹理在片元着色器中为每个像素计算其在世界空间下的位置,这是通过使用当前的视角*投影矩阵的逆矩阵对NDC下的顶点坐标进行变换得到的。当得到世界空间中的顶点坐标后,我们计算前一帧和当前帧的位置差,生成该像素的速度。这种方法的有点是可以在一个屏幕后处理步骤中完成整个效果的模拟,但缺点是需要在片元着色器中进行两次矩阵乘法的操作,对性能有所影响。
为了使用深度纹理模拟运动模糊,我们进行如下准备工作:
1)新建场景,去掉天空盒子
2)搭建一个测试运动模糊的场景,构建了一个包含3面墙的方法,并放置了4个立方体。
3)在摄像机上新建一个脚本MotionBlurWithDepthTexture.cs
4)新建一个Shader Chapter13-MotionBlurWithDepthTexture
我们先编写MotionBlurWithDepthTexture.cs 脚本
public class MotionBlurWithDepthTexture : PostEffectsBase {
public Shader motionBlurShader;
private Material motionBlurMaterial = null;
public Material material {
get {
motionBlurMaterial = CheckShaderAndCreateMaterial(motionBlurShader, motionBlurMaterial);
return motionBlurMaterial;
}
}
private Camera myCamera;
public Camera camera {
get {
if (myCamera == null) {
myCamera = GetComponent();
}
return myCamera;
}
}
//定义运动模糊时模糊图像使用的大小
[Range(0.0f, 1.0f)]
public float blurSize = 0.5f;
//保存上一帧摄像机的视角*投影矩阵
private Matrix4x4 previousViewProjectionMatrix;
void OnEnable() {
camera.depthTextureMode |= DepthTextureMode.Depth;
previousViewProjectionMatrix = camera.projectionMatrix * camera.worldToCameraMatrix;
}
void OnRenderImage (RenderTexture src, RenderTexture dest) {
if (material != null) {
material.SetFloat("_BlurSize", blurSize);
material.SetMatrix("_PreviousViewProjectionMatrix", previousViewProjectionMatrix);
Matrix4x4 currentViewProjectionMatrix = camera.projectionMatrix * camera.worldToCameraMatrix;
Matrix4x4 currentViewProjectionInverseMatrix = currentViewProjectionMatrix.inverse;
material.SetMatrix("_CurrentViewProjectionInverseMatrix", currentViewProjectionInverseMatrix);
previousViewProjectionMatrix = currentViewProjectionMatrix;
Graphics.Blit (src, dest, material);
} else {
Graphics.Blit(src, dest);
}
}
}
Shader "Unity Shaders Book/Chapter 13/Motion Blur With Depth Texture" {
Properties {
_MainTex ("Base (RGB)", 2D) = "white" {}
//模糊图像时使用的参数
_BlurSize ("Blur Size", Float) = 1.0
}
SubShader {
CGINCLUDE
#include "UnityCG.cginc"
sampler2D _MainTex;
half4 _MainTex_TexelSize;
sampler2D _CameraDepthTexture;
float4x4 _CurrentViewProjectionInverseMatrix;
float4x4 _PreviousViewProjectionMatrix;
half _BlurSize;
struct v2f {
float4 pos : SV_POSITION;
half2 uv : TEXCOORD0;
half2 uv_depth : TEXCOORD1;
};
v2f vert(appdata_img v) {
v2f o;
o.pos = mul(UNITY_MATRIX_MVP, v.vertex);
o.uv = v.texcoord;
o.uv_depth = v.texcoord;
//进行平台差异化处理
#if UNITY_UV_STARTS_AT_TOP
if (_MainTex_TexelSize.y < 0)
o.uv_depth.y = 1 - o.uv_depth.y;
#endif
return o;
}
fixed4 frag(v2f i) : SV_Target {
// Get the depth buffer value at this pixel.
float d = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv_depth);
// H is the viewport position at this pixel in the range -1 to 1.
float4 H = float4(i.uv.x * 2 - 1, i.uv.y * 2 - 1, d * 2 - 1, 1);
// Transform by the view-projection inverse.
float4 D = mul(_CurrentViewProjectionInverseMatrix, H);
// Divide by w to get the world position.
float4 worldPos = D / D.w;
// Current viewport position
float4 currentPos = H;
// Use the world position, and transform by the previous view-projection matrix.
float4 previousPos = mul(_PreviousViewProjectionMatrix, worldPos);
// Convert to nonhomogeneous points [-1,1] by dividing by w.
previousPos /= previousPos.w;
// Use this frame's position and last frame's to compute the pixel velocity.
float2 velocity = (currentPos.xy - previousPos.xy)/2.0f;
float2 uv = i.uv;
float4 c = tex2D(_MainTex, uv);
uv += velocity * _BlurSize;
for (int it = 1; it < 3; it++, uv += velocity * _BlurSize) {
float4 currentColor = tex2D(_MainTex, uv);
c += currentColor;
}
c /= 3;
return fixed4(c.rgb, 1.0);
}
ENDCG
Pass {
ZTest Always Cull Off ZWrite Off
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
ENDCG
}
}
FallBack Off
}全局雾效
雾效是游戏里经常使用的一种效果。Unity内置的雾效可以产生基于距离的线性或指数雾效。然而,要想在自己编写的顶点/片元着色器中实现这些雾效,我们需要在Shader 中添加#pragma multi_compile_fog 指令,同时还需要使用相关的内置宏,例如UNITY_FOG_COORDS、UNITY_TRANSFER_FOG和UNITY_APPLY_FOG等。这种方法的缺点在于,我们不仅需要为场景中所有物体添加相关的渲染呆吗,而且能够实现的效果也非常有限。当我们需要对雾效进行一些个性化操作时,例如使用基于高度的雾效等,仅仅使用Unity内置的雾效就变得不再可行。
我们使用一种基于屏幕后处理的全局雾效的实现。使用这种方法,我们不需要更改场景内渲染的物体所使用的Shader 代码,而仅仅依靠一次屏幕后处理的步骤即可。这种方法的自由度高,我们可以方便地模拟各种雾效,例如均匀的雾效、基于距离的线性/指数雾效、基于高度的雾效等。我们可以得到类似下图中的结果。
基于屏幕后处理的全局雾效的关键是,根据深度纹理来重建每个像素在世界空间下的位置。尽管之前我们在模拟运动模糊时已经实现了这个要求,即构建出当前像素的NDC坐标,再通过当前摄像机的视角*投影矩阵的逆矩阵来得到世界空间下的像素坐标,但是,这样的实现需要在片元着色器中进行矩阵乘法的操作,而这通常会影响游戏性能。我们学习一个快速从深度纹理中重建世界坐标的方法。这种方法首先对图像空间下的视锥体射线(从摄像机出发,指向图像上的某点的射线)进行插值,这条射线存储了该像素在世界空间下到摄像机的方向信息。然后,我们把该射线和线性化后的视角空间下的深度值相乘,再加上摄像机的世界位置,就可以得到该像素在世界空间下的位置。当我们得到世界坐标后,就可以轻松地使用各个公式来模拟全局雾效了。
我们知道,坐标系中的一个顶点坐标可以通过它相对于另一个顶点坐标的偏移量来求得。重建像素的世界坐标也是基于这样的思想。我们只需要知道摄像机在世界空间下的位置,以及世界空间下该像素相对于摄像机的偏移量,把它们相加就可以得到该像素的世界坐标。整个过程可以使用下面的代码来表示:
float4 worldPos = _WorldSpaceCameraPos + linearDepth * interpolateRay;其中,_WorldSpaceCameraPos 是摄像机在世界空间下的位置,这可以由Unity 的内置变量直接访问得到。而linearDepth * interpolatedRay 则可以计算得到该像素相对于摄像机的偏移量,linearDepth 是由深度纹理得到的线性深度值,interpolatedRay 是由顶点着色器输出并插值后得到的射线,它不仅包含了该像素到摄像机的方向,也包含了距离信息。
interpolatedRay 来源于对近裁剪平面的4个角的某个特定向量的插值,这4个向量包含了它们到摄像机的方向和距离信息,我们可以利用摄像机的近裁剪平面距离、FOV、横纵比计算而得。下图显示了计算时使用的一些辅助向量。

为了方便计算,我们可以先计算两个向量——toTop 和 toRight,它们是起点位于近裁剪平面中心、分别指向摄像机正上方和正右方的方向。它们的计算公式如下:

其中,Near 是近裁剪平面的距离,FOV是竖直方向的视角范围,camera.up、camera.right分别对应了摄像机的正上方和正右方。当得到这两个辅助向量后,我们就可以计算4个角相对于摄像机的方向了。我们以左上角为例,它的计算公式如下:
![]()
同理,其他3个角的计算也是类似的:

注意,上面求得的4个向量不仅包含了方向信息,它们的模对应了4个点到摄像机的空间距离。由于我们得到的线性深度值并非是点到摄像机的欧式距离,而是在z方向上的距离,因此,我们不能直接使用深度值和4个角的单位方向的乘积来计算它们到摄像机的偏移量,如下图所示。
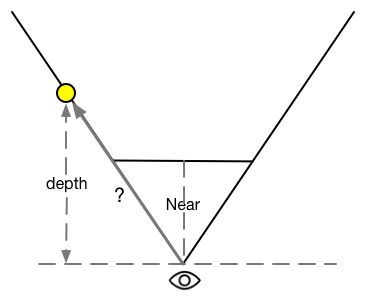
想要在深度值转换成到摄像机的欧式距离也很简单,我们以TL点为例,根据相似三角形原理,TL所在的射线上,像素的深度值和它到摄像机的实际距离的比等于近裁剪平面的距离和TL向量的模的比,即
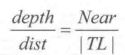
由此可得,我们需要的TL距离摄像机的欧式距离dist:
![]()
由于4个点相互对称,因此其他3个向量的模和TL相等,即我们可以使用同一个因子和单位向量相乘,得到它们对应的向量值:
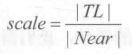
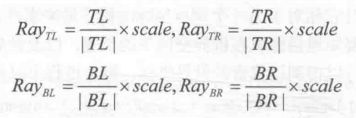
屏幕后处理的原理是使用特定的材质去渲染一个刚好填充整个屏幕的四边形面片。这个四边形面片的4个顶点就对应了近裁剪平面的4个角。由此,我们可以把上面的计算结果传递给顶点着色器,顶点着色器根据当前的位置选择它所对应的向量,然后再将其输出,经插值后传递给片元着色器得到interpolatedRay,我们就可以利用之前提到的公式重建该像素在世界空间下的位置了。
在简单的雾效实现中,我们需要计算一个雾效系数f,作为混合原始颜色和雾的颜色的混合系数:
float3 afterFog = f*fogColor + (1 - f) * origColor;
Linear:
![]()
Exponential:
![]()
Exponential Squared:
![]()
我们使用类似线性雾的计算方式,计算基于高度的雾效。具体方法是,当给定一点在世界空间下的高度y后,f的计算公式为:

为了在Unity中实现基于屏幕后处理的雾效,我们需要进行如下准备工作。
1)新建一个场景,去掉天空盒子。
2)构建一个包含3面墙的房间,放置两个立方体和两个球体
3)在摄像机上新建一个脚本FogWithDepthTexture.cs。
4)新建一个Shader Chapter13-FogWithDepthTexture。
首先,我们编写FogWithDepthTexture.cs
public class FogWithDepthTexture : PostEffectsBase {
public Shader fogShader;
private Material fogMaterial = null;
public Material material {
get {
fogMaterial = CheckShaderAndCreateMaterial(fogShader, fogMaterial);
return fogMaterial;
}
}
private Camera myCamera;
public Camera camera {
get {
if (myCamera == null) {
myCamera = GetComponent();
}
return myCamera;
}
}
private Transform myCameraTransform;
public Transform cameraTransform {
get {
if (myCameraTransform == null) {
myCameraTransform = camera.transform;
}
return myCameraTransform;
}
}
//控制雾的浓度
[Range(0.0f, 3.0f)]
public float fogDensity = 1.0f;
//控制雾的颜色
public Color fogColor = Color.white;
//雾效的起始高度
public float fogStart = 0.0f;
//雾效的终止高度。
public float fogEnd = 2.0f;
void OnEnable() {
camera.depthTextureMode |= DepthTextureMode.Depth;
}
void OnRenderImage (RenderTexture src, RenderTexture dest) {
if (material != null) {
Matrix4x4 frustumCorners = Matrix4x4.identity;
//先计算近裁剪平面的四个角对应的向量
float fov = camera.fieldOfView;
float near = camera.nearClipPlane;
float aspect = camera.aspect;
float halfHeight = near * Mathf.Tan(fov * 0.5f * Mathf.Deg2Rad);
Vector3 toRight = cameraTransform.right * halfHeight * aspect;
Vector3 toTop = cameraTransform.up * halfHeight;
Vector3 topLeft = cameraTransform.forward * near + toTop - toRight;
float scale = topLeft.magnitude / near;
topLeft.Normalize();
topLeft *= scale;
Vector3 topRight = cameraTransform.forward * near + toRight + toTop;
topRight.Normalize();
topRight *= scale;
Vector3 bottomLeft = cameraTransform.forward * near - toTop - toRight;
bottomLeft.Normalize();
bottomLeft *= scale;
Vector3 bottomRight = cameraTransform.forward * near + toRight - toTop;
bottomRight.Normalize();
bottomRight *= scale;
//将4个向量存储在矩阵类型的frustumCorners 中
frustumCorners.SetRow(0, bottomLeft);
frustumCorners.SetRow(1, bottomRight);
frustumCorners.SetRow(2, topRight);
frustumCorners.SetRow(3, topLeft);
material.SetMatrix("_FrustumCornersRay", frustumCorners);
material.SetFloat("_FogDensity", fogDensity);
material.SetColor("_FogColor", fogColor);
material.SetFloat("_FogStart", fogStart);
material.SetFloat("_FogEnd", fogEnd);
Graphics.Blit (src, dest, material);
} else {
Graphics.Blit(src, dest);
}
}
}
Shader "Unity Shaders Book/Chapter 13/Fog With Depth Texture" {
Properties {
_MainTex ("Base (RGB)", 2D) = "white" {}
_FogDensity ("Fog Density", Float) = 1.0
_FogColor ("Fog Color", Color) = (1, 1, 1, 1)
_FogStart ("Fog Start", Float) = 0.0
_FogEnd ("Fog End", Float) = 1.0
}
SubShader {
CGINCLUDE
#include "UnityCG.cginc"
float4x4 _FrustumCornersRay;
sampler2D _MainTex;
half4 _MainTex_TexelSize;
sampler2D _CameraDepthTexture;
half _FogDensity;
fixed4 _FogColor;
float _FogStart;
float _FogEnd;
struct v2f {
float4 pos : SV_POSITION;
half2 uv : TEXCOORD0;
half2 uv_depth : TEXCOORD1;
float4 interpolatedRay : TEXCOORD2;
};
v2f vert(appdata_img v) {
v2f o;
o.pos = mul(UNITY_MATRIX_MVP, v.vertex);
o.uv = v.texcoord;
o.uv_depth = v.texcoord;
#if UNITY_UV_STARTS_AT_TOP
if (_MainTex_TexelSize.y < 0)
o.uv_depth.y = 1 - o.uv_depth.y;
#endif
int index = 0;
if (v.texcoord.x < 0.5 && v.texcoord.y < 0.5) {
index = 0;
} else if (v.texcoord.x > 0.5 && v.texcoord.y < 0.5) {
index = 1;
} else if (v.texcoord.x > 0.5 && v.texcoord.y > 0.5) {
index = 2;
} else {
index = 3;
}
#if UNITY_UV_STARTS_AT_TOP
if (_MainTex_TexelSize.y < 0)
index = 3 - index;
#endif
o.interpolatedRay = _FrustumCornersRay[index];
return o;
}
fixed4 frag(v2f i) : SV_Target {
float linearDepth = LinearEyeDepth(SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv_depth));
float3 worldPos = _WorldSpaceCameraPos + linearDepth * i.interpolatedRay.xyz;
float fogDensity = (_FogEnd - worldPos.y) / (_FogEnd - _FogStart);
fogDensity = saturate(fogDensity * _FogDensity);
fixed4 finalColor = tex2D(_MainTex, i.uv);
finalColor.rgb = lerp(finalColor.rgb, _FogColor.rgb, fogDensity);
return finalColor;
}
ENDCG
Pass {
ZTest Always Cull Off ZWrite Off
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
ENDCG
}
}
FallBack Off
}再谈边缘检测
之前我们曾介绍如何使用Sobel算子对屏幕图像进行边缘检测,实现描边的效果。但是,这种直接利用颜色信息进行边缘检测的方法会产生很多我们不希望得到的边缘线,如下图所示。

可以看出,物体的纹理、阴影等位置也被描上黑边,而这往往不是我们希望看到的。我们将学习如何在深度和法线纹理上进行边缘检测,这些图像不会受纹理和光照的影响,而仅仅保存了单钱渲染物体的模型信息,通过这样的方式检测出来的边缘更加可靠。我们可以得到类似下图中的结果。
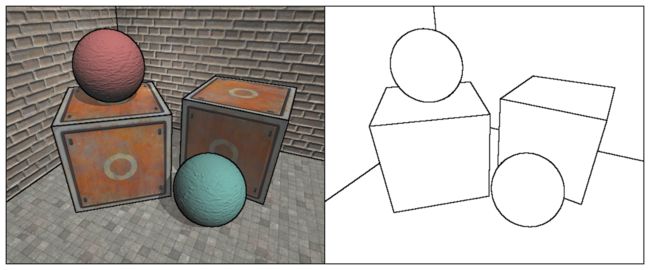
我们使用Robert算子来进行边缘检测。它使用的卷积核如下图所示。
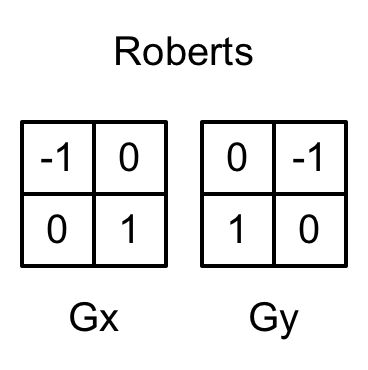
Roberts 算子的本质就是计算左上角和右下角的插值,乘上右上角和左下角的差值,作为评估边缘的依据。在下面的实现中,我们也会按这样的方式,取对角方向的深度或法线值,比较它们之间的差值,如果超过某个阈值,就认为它们之间存在一条边。
我们进行如下准备工作。
1)新建一个场景,去掉天空盒子。
2)构建一个包含3面墙的房间,放置两个立方体和两个球体。
3)摄像机上添加EdgeDetectNormalsAndDepth.cs 脚本
4)新建一个Shader Chapter13-EdgeDetectNormalAndDepth。
我们先修改EdgeDetectNormalsAndDepth.cs 脚本
public class EdgeDetectNormalsAndDepth : PostEffectsBase {
public Shader edgeDetectShader;
private Material edgeDetectMaterial = null;
public Material material {
get {
edgeDetectMaterial = CheckShaderAndCreateMaterial(edgeDetectShader, edgeDetectMaterial);
return edgeDetectMaterial;
}
}
[Range(0.0f, 1.0f)]
public float edgesOnly = 0.0f;
public Color edgeColor = Color.black;
public Color backgroundColor = Color.white;
public float sampleDistance = 1.0f;
public float sensitivityDepth = 1.0f;
public float sensitivityNormals = 1.0f;
void OnEnable() {
GetComponent().depthTextureMode |= DepthTextureMode.DepthNormals;
}
//[ImageEffectOpaque] 让透明物体不被描边
[ImageEffectOpaque]
void OnRenderImage (RenderTexture src, RenderTexture dest) {
if (material != null) {
material.SetFloat("_EdgeOnly", edgesOnly);
material.SetColor("_EdgeColor", edgeColor);
material.SetColor("_BackgroundColor", backgroundColor);
material.SetFloat("_SampleDistance", sampleDistance);
material.SetVector("_Sensitivity", new Vector4(sensitivityNormals, sensitivityDepth, 0.0f, 0.0f));
Graphics.Blit(src, dest, material);
} else {
Graphics.Blit(src, dest);
}
}
}
Shader "Unity Shaders Book/Chapter 13/Edge Detection Normals And Depth" {
Properties {
_MainTex ("Base (RGB)", 2D) = "white" {}
_EdgeOnly ("Edge Only", Float) = 1.0
_EdgeColor ("Edge Color", Color) = (0, 0, 0, 1)
_BackgroundColor ("Background Color", Color) = (1, 1, 1, 1)
_SampleDistance ("Sample Distance", Float) = 1.0
_Sensitivity ("Sensitivity", Vector) = (1, 1, 1, 1)
}
SubShader {
CGINCLUDE
#include "UnityCG.cginc"
sampler2D _MainTex;
half4 _MainTex_TexelSize;
fixed _EdgeOnly;
fixed4 _EdgeColor;
fixed4 _BackgroundColor;
float _SampleDistance;
half4 _Sensitivity;
sampler2D _CameraDepthNormalsTexture;
struct v2f {
float4 pos : SV_POSITION;
half2 uv[5]: TEXCOORD0;
};
v2f vert(appdata_img v) {
v2f o;
o.pos = mul(UNITY_MATRIX_MVP, v.vertex);
half2 uv = v.texcoord;
o.uv[0] = uv;
#if UNITY_UV_STARTS_AT_TOP
if (_MainTex_TexelSize.y < 0)
uv.y = 1 - uv.y;
#endif
o.uv[1] = uv + _MainTex_TexelSize.xy * half2(1,1) * _SampleDistance;
o.uv[2] = uv + _MainTex_TexelSize.xy * half2(-1,-1) * _SampleDistance;
o.uv[3] = uv + _MainTex_TexelSize.xy * half2(-1,1) * _SampleDistance;
o.uv[4] = uv + _MainTex_TexelSize.xy * half2(1,-1) * _SampleDistance;
return o;
}
half CheckSame(half4 center, half4 sample) {
half2 centerNormal = center.xy;
float centerDepth = DecodeFloatRG(center.zw);
half2 sampleNormal = sample.xy;
float sampleDepth = DecodeFloatRG(sample.zw);
// difference in normals
// do not bother decoding normals - there's no need here
half2 diffNormal = abs(centerNormal - sampleNormal) * _Sensitivity.x;
int isSameNormal = (diffNormal.x + diffNormal.y) < 0.1;
// difference in depth
float diffDepth = abs(centerDepth - sampleDepth) * _Sensitivity.y;
// scale the required threshold by the distance
int isSameDepth = diffDepth < 0.1 * centerDepth;
// return:
// 1 - if normals and depth are similar enough
// 0 - otherwise
return isSameNormal * isSameDepth ? 1.0 : 0.0;
}
fixed4 fragRobertsCrossDepthAndNormal(v2f i) : SV_Target {
half4 sample1 = tex2D(_CameraDepthNormalsTexture, i.uv[1]);
half4 sample2 = tex2D(_CameraDepthNormalsTexture, i.uv[2]);
half4 sample3 = tex2D(_CameraDepthNormalsTexture, i.uv[3]);
half4 sample4 = tex2D(_CameraDepthNormalsTexture, i.uv[4]);
half edge = 1.0;
edge *= CheckSame(sample1, sample2);
edge *= CheckSame(sample3, sample4);
fixed4 withEdgeColor = lerp(_EdgeColor, tex2D(_MainTex, i.uv[0]), edge);
fixed4 onlyEdgeColor = lerp(_EdgeColor, _BackgroundColor, edge);
return lerp(withEdgeColor, onlyEdgeColor, _EdgeOnly);
}
ENDCG
Pass {
ZTest Always Cull Off ZWrite Off
CGPROGRAM
#pragma vertex vert
#pragma fragment fragRobertsCrossDepthAndNormal
ENDCG
}
}
FallBack Off
}