网站:
汽车之家:http://club.autohome.com.cn/ 以论坛为例
反爬虫措施:
在论坛发布的贴子正文中随机抽取某几个字使用span标签代替,标签内容位空,但css样式显示为所代替的文。这样不会
影响正常用户的阅读,只是在用鼠标选择的时候是选不到被替换的文字的,对爬虫则会造成采集内容不全的影响。
原理分析:
先看一下span标签的样式
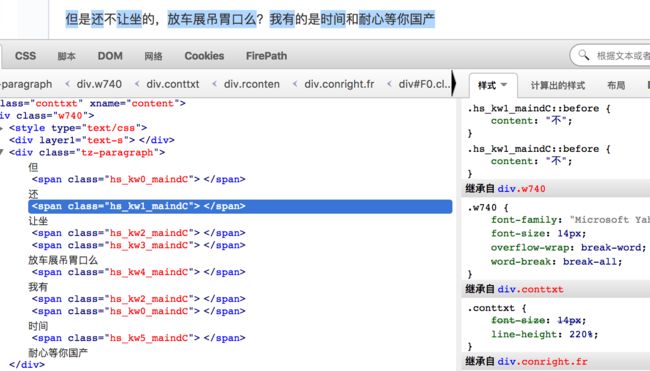
截图是火狐浏览器的firebug的html面板。我们可以看到正文中每个span标签的样式都是一个文字,我们只需要找到每个
span标签的class属性于文字的对应关系即可还原正文内容,于是我找了一下css样式是在哪里定义的。找到了这样一个文
件,在firebug的css面板中可以看到所有的css文件,然后我尝试打开了一下这个url,发现结果还是帖子页面而非css文件
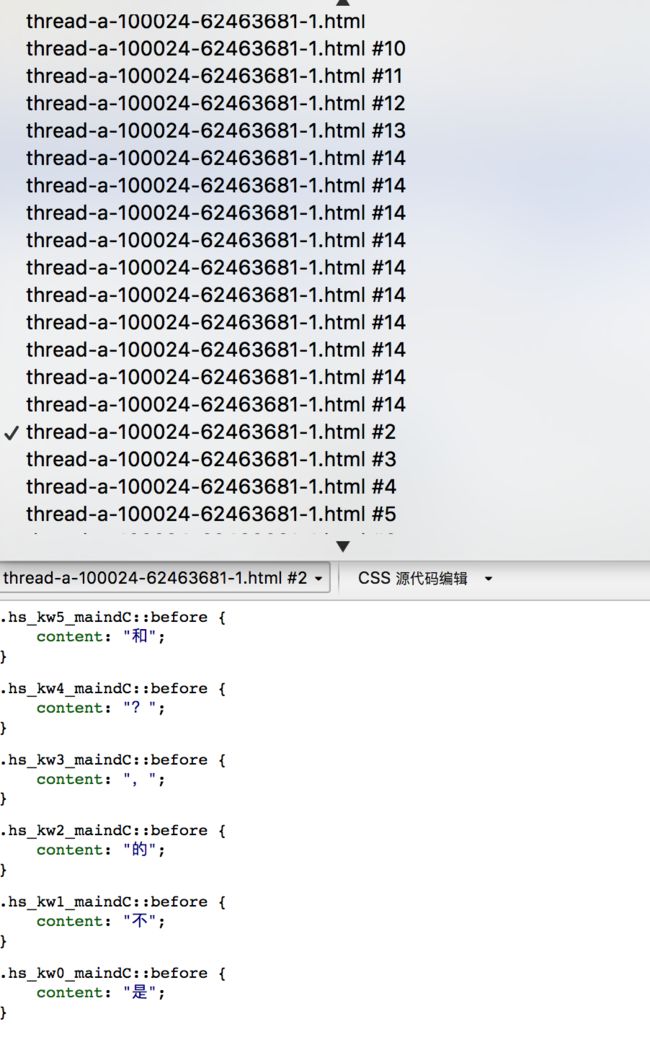
通过抓包也没有抓到类似这样的css文件,一番尝试无果后,我明白了,这个css文件应该是利用js生成的,于是我开始寻
找生成这样的文件的js代码,基本上就是拿各种关键词到各个js文件或者源代码中搜索,例如 ::before、content、hs_kw
等。然后发现js代码存在于网页源代码中,可以利用搜索 HS_ZY来定位到这段js代码,下面就是对js代码的分析破解了,

复制这段js代码到 http://jsbeautifier.org/ 一个js格式化工具网站。格式化之后,发现js代码是被混淆过的,这就比较蛋疼
了,幸好之前也接触过此类混淆,大概明白混淆的原理,无非就是将变量名随机替换,将完整代码拆分后用变量相加之类的,
于是在一番很麻烦的将各种变量手工替换回去之后,大概明白了js代码的主逻辑。
(function(hZ_) { functionEW_() { = DV_()[decodeURIComponent]('%E3%80%81%E3%80%82%E4%B8%80%E4%B8%8A%E4%B8%8B%E4%B8%8D%E4%BA%86%E4%BA%94%E5%92%8C%E5%9C%B0%E5%A4%9A%E5%A4%A7%E5%A5%BD%E5%B0%8F%E5%BE%88%E5%BE%97%E6%98%AF%E7%9A%84%E7%9D%80%E8%BF%9C%E9%95%BF%E9%AB%98%EF%BC%81%EF%BC%8C%EF%BC%9F' yc_()); = la_((yc_() 23; 3; 19; 17; 9; 1; 8; 12; 18; 13; 2; 4; 16; 5; 6; 21; 15; 11; 22; 14; 24; 0; 10; 7; 20), lf_(;)); = la_((10 _7, 6 _0; 2 _33, 14 _18; 8 _45, 8 _36; 0 _71, 16 _54; 13 _76, 3 _72; 0 _107, 16 _90; 15 _110, 1 _108; 4 _139, 12 _126; 9 _152, 7 _144; 10 _169, 6 _162; 4 _193, 12 _180; 11 _204, 5 _198; 3 _230, 13 _216; 1 _250, 15 _234; 13 _256, 3 _252; 6 _281, 10 _270; 9 _296, 7 _288; 13 _310, 3 _306; 6 _335, 10 _324; 7 _352, 9 _342; 6 _371, 10 _360; 5 _390, 11 _378; 5 _408, 11 _396; 7 _424, 9 _414; 6 _443, 10 _432lf_(;)), yc_(;)); Uj_(); return;; } function mS_() { for (Gx_ = 0; Gx_ < nf_.length; Gx_++) { var su_ = Pn_(nf_[Gx_], ','); var KN_ = ''; for (Bk_ = 0; Bk_ < su_.length; Bk_++) { KN_ += ui_(su_[Bk_]) + ''; } Kx_(Gx_, KN_); } } function NH_(Gx_) { return '.hs_kw' + Gx_ + '_maindC'; } function Ln_() { return '::before { content:' } })(document);
很简单的逻辑,预先定义好哪几个字要被替换,上面代码中的那个很多%的字符串就是被替换的文字串,然后定义好每个文
字的序号,最后按照文字的序号对文字串进行重新排序并生成css样式,注意,最一开始的span标签的class属性中是有个序
号的,这个序号就是用来定位应该对应哪个文字。
接下来要做的就是无非就是从js代码中找到这个文字串,找到文字串的顺序,然后进行重排,然后根据span标签序号对原文
进行反向替换,从而得到完整的内容。
破解步骤:
简单整理一下:
1、从js代码中找到被替换的文字串和顺序
2、重排文字串
3、对原文中span标签根据class序号进行替换
其实2、3都比较简单,重点是第一步,找到被替换的文字串和顺序,由于源代码中js代码是被混淆过的,无法直接看出哪个
是文字串,所以首先应该对js代码进行反混淆,这个反混淆也不是说非得完整的还原所有的js代码,其实只要能反混淆到能
让我们看出文字串和顺序是什么就行了。
说一下反混淆的思路,其实很简单。就是执行起来比较麻烦而已,混淆是利用将一个简单的变量定义成复杂的js代码的方法
实现的,但这种混淆方式其实是有限的(这个有限指的是混淆用的工具在生成混淆代码时肯定是人为预先定义好了几种模式
,人为定义的肯定是有限的,只要你把所有的模式找出来,就可以还原了)。举个例子
function iq_() { 'return iq_'; return '3'; }
这段代码其实你可以简单的认为就是变量iq()等于'3',使用正则匹配这样的代码模式,然后提取关键字:函数名和最后一个
return的值,然后将提取到的信息保存起来用于对js代码进行全文替换。
function cz_() { function _c() { return 'cz_'; }; if (_c() == 'cz__') { return _c(); } else { return '84'; } }
这段代码复杂了一些,增加了判断,不过也简单,利用正则匹配这样的模式,然后提取关键字:函数名、第一个return的值,
判断中==后面的值,最后一个return的值,然后自己进行判断来确定cz_()的值应该是多少,保存起来进行全文替换。
以此类推,每种模式都可以使用正则来提取关键字并进行全文替换来反混淆,最后我们会得到一个大概被还原的js代码,其
中的文字串和顺序都清晰可见,再使用正则匹配出来就可以了。需要注意的一点是有时候被替换的不是单个文字,而是一些
词语,这是找到的顺序是"3,1;23,5"这样的,不过这些小伎俩应该不算什么,很好解决。
PS1:
发现一种新的模式,以前没注意,span的class属性hs_kw后面还有一串字符,估计是用来标示类别的,一般的网页
上只有一种class,出现多种的时候对应的源码中就会存在多段js代码,每段js代码对应一种class,关键是找到js代码对应的
class类型,然后分类型替换就行了。
结语:
这个建议大家自己动手做一下,还是比较有意思的,完整的破解代码见我的github
https://github.com/duanyifei/antispider/blob/master/autohome.py