提升有监督学习效果的实战解析
上海站 | 高性能计算之GPU CUDA培训
4月13-15日 三天密集式学习 快速带你晋级
阅读全文
>
三天密集式学习 快速带你晋级
阅读全文
>
正文共6534个字,16张图,预计阅读时间18分钟。
最近很长时间没有和大家分享东西了,最近一直在忙公司的项目,先说一声抱歉。
之前写过销售预估算法,但是被诸多大佬吐槽有监督学习部分毫无深度,其实我是想写给一些刚入门的朋友看的,这边我boss最近也想让我总结一些相对"上档次"的一点的东西,我做了一些稍微深入一点的总结,希望能够给新人朋友有稍微深入的方法介绍。
去年年末的那段时间里,看了很多天池大赛里面得高分的选手的算法思路,大概总结了有监督学习中的一些核心流程及重要细节:
feature processing tricks
这个是老生常谈的问题,但是我还是看到了一些不错的点,比如根据high importance feature剔除高度缺失的cases这些等等
single feature + crossing feature
交叉特征组合原始特征,可以显著的提升auc,提高命中的准确程度,这边除了FM,我们也可以在常规的算法中去实现这个trick
有监督学习架构思路
下面,我们来看看针对每个点,具体是如何实现的,及我们需要注意哪些相关的东西:
case and feature selection
我们在做模型训练之前通常会对模型的feature做一些删减,比如共线性检验,去除掉相似度过高的连续feature;比如变异度检验,去除掉一些数据变化差异过小的feature等等。然而,在常规的样本处理中,我们通常只会根据初始的数据分布去看,比如用户在feature上缺失大于来某个阈值才回去剔除这个用户;其实,在深入的思考一下这个问题,会发现,如果用户在高重要性的feature缺失程度高去剔除才更合理一些,这样想可能不是很清晰,这边看下面这个feature flow:

针对uid来看,如果普通的统计的话,uid3的null的个数5个,uid5的null的个数4个,我们应该优先剔除uid3,再考虑剔除uid5,因为null过多的用户所能提供的信息量会相对的少,会增大泛化误差。
但如果我们提前知道,对于判断label的能力,feature3>feature5>feature6>feature8>其他,那么uid5在高重要性的缺失情况极度严重于uid3,所以我们应该优先剔除uid5,相对于上面一种情况,我们预先知道feature的重要性排序就显得很重要了。关于如何判断提供了几种简单的方法:
方差膨胀系数:我们认为,在数据归一化之后,数据波动的更大的feature能够提供的信息量相对而言也是更大的,举个很明显的例子,如果feature1全都是1的话,它对我们判断用户是否下单这样结果毫无意义。
互信息:我一直认为,互信息是判断feature重要性的非常好的方法。方差膨胀系数只单纯了考虑feature本身的特征,而互信息在考虑feature的同时也考虑了label之间的关系,H(X,Y) = H(X) - H(X/Y),这个信息量的公式很好的解释了这一点。
xgb's importance:如果互信息是方差膨胀系数的进阶,那么xgb's importance则是互信息的进阶,在考虑label与feature之间的关系的时候,同时还考虑了feature与feature之间的关系,这样得出来的重要性排序更加全面了一些。
除此之外:
Logistic regression的params的参数
Recursive feature elimination(递归参数选择方法)
Pearson Correlation
Distance correlation
Mean decrease impurity/Mean decrease accuracy
...
诸如这样的方法很多,需要根据数据的形式,目标变量的形式,时间成本,效率等等综合考虑,这边只是给大家梳理一下常规的方法,至于实际使用的情况,需要大家累积项目经验。
在空值或者异常值的处理上,基本上分为2个派别,要么剔除这个feature或者case,要么填充这个feature或者case,它们的缺点也显而易见,随意剔除会减少判断的信息,如果数据较少的时候,会降低模型的效果;填充的话会造成困惑,到底是众数?平均数?中位数?最大值?最小值?现在很多人的处理方法都是观察数据的分布,如果偏态分布就考虑分位数填充,如果是正态分布就考虑均值或者众数填充,相对而言,这样处理的时间成本会更高,而且很多时候解释的说服力不是很强。
我在看了17年3月份JD的订单预估赛,17年的天池工业赛等等的高分答案中,不得不说,有一个分箱的方法确实能够提高0.5-1.5的auc,我之前思考过,可能存在的原因:
保存了原始的信息,没有以填充或者删除的方式改变真实的数据分布
让feature存在的形式更加合理,比如age这个字段,其实我们在乎的不是27或者28这样的差别,而是90后,80后这样的差别,如果不采取分箱的形式,一定程度上夸大了27与26之前的差异
在数据计算中,不仅仅加快了计算的速度而且消除了实际数据记录中的随机偏差,平滑了存储过程中可能出现的噪音
这边就直接给大家分享一下我的梳理:
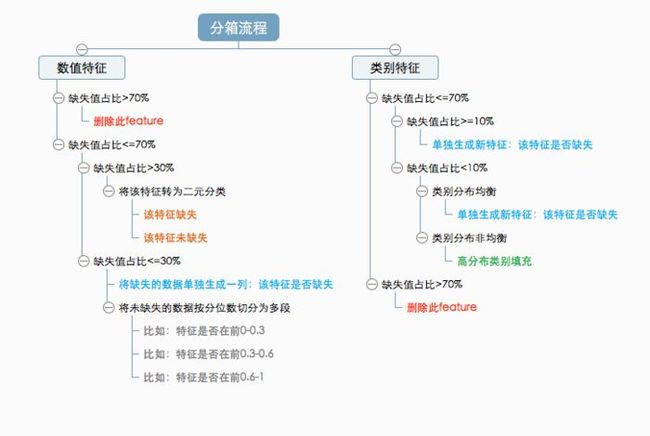
这边涉及到一个问题,连续数值特征是否一定要切为离散特征,建议综合考虑以下几个问题:a.所使用的算法是否为knn、svm这样的距离计算的算法b.是否在实际业务中依赖于离散判断c.连续数值特征的实际意义是否支持离散化。如果以上问题都没有问题的话,我建议优先考虑离散化连续特征,在一定程度上,离散完的feature有更好的解释意义。
我们在之前的FM理论解析及应用中提到过特征交叉这个概念,当时的文章中紧接着通过矩阵的计算技巧:
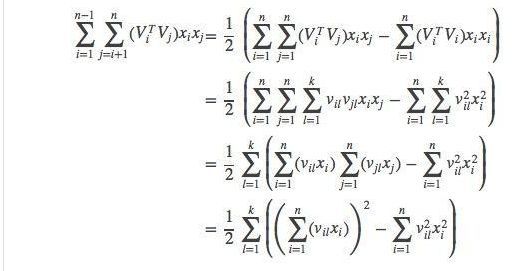
构造了全部feature的C(n,2)的形式,后面追加了线性模型,这样一定程度上可以提高分类算法的准确度。这是一个非常好的将低维特征向高维转化的方式,所以在我们其他算法的过程中也可以借鉴这种思路,但是假设我们初始的feature量特别多,比如我在日常的CTR预估或者feature梳理的过程中,很容易就整理500以上的feature集合,如果仅考虑C(n,2)的形式的话,就有250*499个feature的新增组合,这个是不可能接受的,所以回到我们上面一节feature processing tricks中提到的case and feature selection就是一个非常好的解决办法,我们可以先通过比如xgboost中的importance:
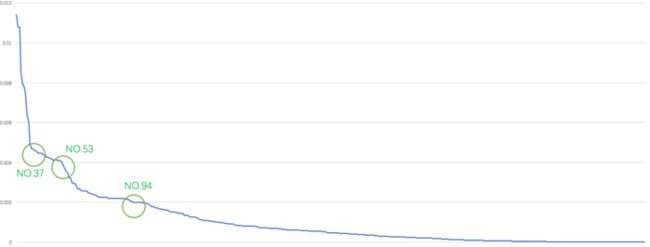
我这边实际的画出了我做下单概率预测时初始筛选完成后的417个feature经过xgboost初步分类后的importance,可以很明显看前37,前53,前94个feature对应了三次importance的拐点,我们可以在这些拐点中选择一个既能够涵盖绝大多数的信息量,又不会造成后续交叉特征个数过多的值,比如我这边选择的是60,那么我接下来会生成的新的的交叉feature就是30*59个,比不做处理下的417*208要小很多倍,而且相对而言不会减少很多的信息量。
整体的流程我这边也画出来了,希望能够给大家一个比较清晰的认识:
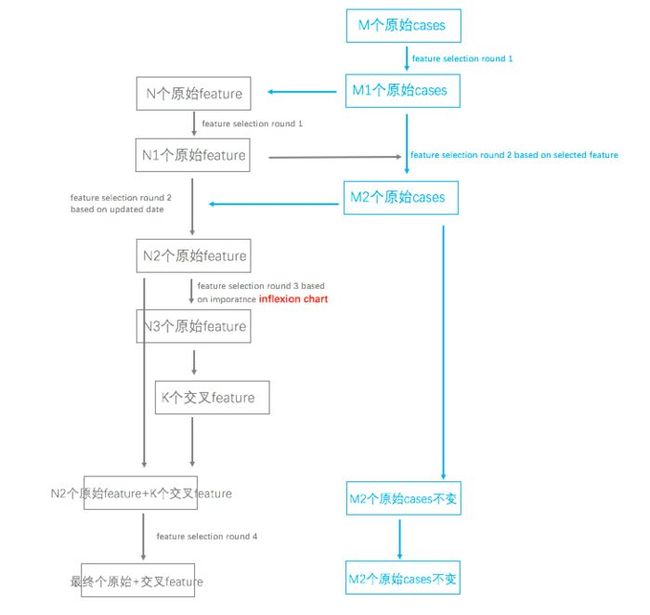
可以看到,样本cases在经过了最初的空值筛选及第一轮高重要性feature后的空值筛选后,就保持不变了,而特征feature的筛选过程则贯穿了整个交叉特征生成流。
我相信在读的各位,不论是机器学习从业者抑或是算法工程师甚至是其他研发工程师,一定看过类似如下的快速拖动的模块流:
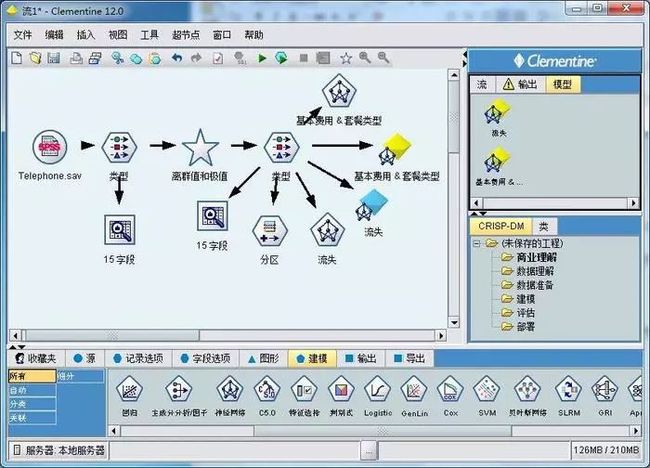
机器学习工具Clementine截图
它相当于把每个功能封装到一个固定的盒子中,当我们需要使用某个模块的时候,进行模块的操作,不需要的时候直接切断模块的流向即可,我们甚至可以空值每个模块的var及bias的偏向程度,在bagging和stacking的思路框架中,我非常常用的就是类似这样的思想:确定好我要进行的组合模块的组合方式(stacking还是bagging还是blending),再确定这次为想要做的子模块是什么,在根据组合形式及子模块细微调节每个子模块。
首先,子模块可以有哪些?
svm分类/回归
logistic分类/回归
神经网络分类/回归
xgboost分类/回归
gbdt分类/回归
xgboost叶子节点index
gbdt叶子节点index
randomforest分类/回归
elastic net
除了这些,还有么?当然,如果你愿意的话,每一个你自己构造出来的分类或者回归的single model都可以成为你bagging或者stacking或者blending之前的子模块。
这边的方法可谓是多种多样,百花齐放,很大程度上来讲,你在天池也好,kaggle也好,你能前十还是前十开外决定因素是你的feature处理的好坏,但是你能拿第一还是第十很大程度上就是依赖你的子模块构造及子模块组合上。这边给大家分享我最近看到的比较有意思的三个子模块形式:
读过我之前写的SVM理论解析及python实现这篇文章的朋友应该还记得,我当时说过svm在10.7%的数据集中取得第一,算是传统的机器学习方法中非常值得一学的算法,但是实际应用中,在处理大规模数据问题时存在训练时间过长和内存空间需求过大的问题比较让人头疼,wepon同学采取的方法如下:
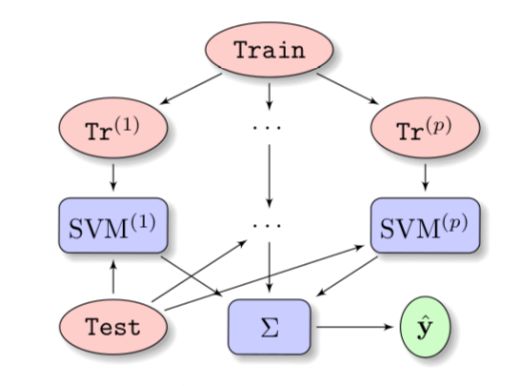
这种方法看似增加了计算复杂度,实际上是却是减小的,假设原始训练数据大小是n,则在原始数据上训练的复杂度是o(n2),将数据集n分成p份,则每份数据量是(n/p),每一份训练一个子svm,复杂度是o((n/p)2),全加起来o(n^2/p),复杂度比在原始数据上训练减小了p倍。变向的解决了在量大的数据集合上使用svm,提高速度同时保证质量这个问题。论文支持建议参考Ensemble SVM。
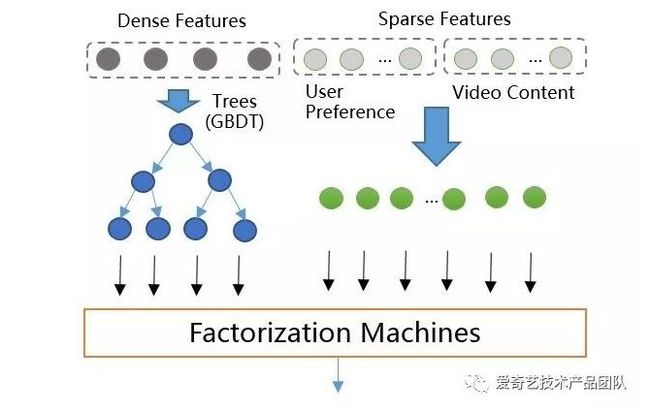
我们分别来解释一下左右的Dense features 和 Spare Features。
首先,左侧这块很好理解,在上一次的文章中,我们已经讲了如何利用xgboost或者gbdt获得用户的数据落在的每棵树上面的叶子节点的index值:
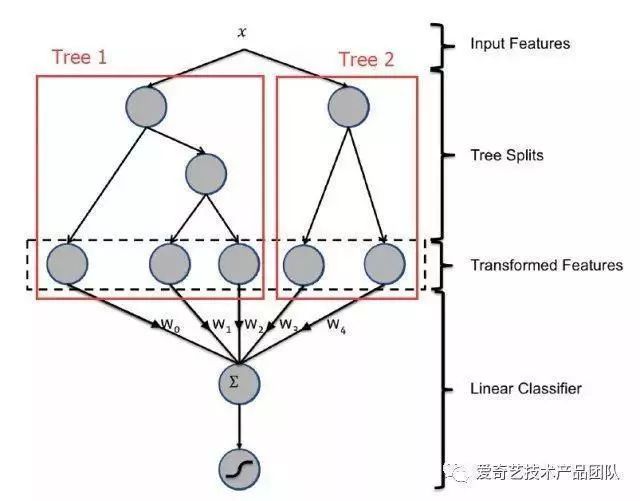
如果有不清楚的同学,请回顾一下上次讲的内容。
右侧这块分别写了user preference 和video content,当然这是因为它是视频公司的原因,在我实际的使用中,我用的是user preference 和 item content,这里的preference和content其实就是你个人信息及行为的向量化的形式。
最简单的表示就是把你的基本信息和item信息先onehotencoding,再首尾相接成一个超长的vector,这就是一个稀疏的Spare Features。
当然除了这种粗暴的办法,还有比如我们在若干天之前讲过的深度学习下的电商商品推荐中的word2vec的技巧,先将所有的用户随机生成为我们需要的长度N维下一一对应的向量,在通过huffman编码的形式找到每个item对应的Huffman树子的唯一路径,再通过在每个节点上生成一个logsitic分类的办法,使得所有该路径成立的概率最高,以此来修正我们最初随便生成的N维向量,最后这个N维向量就可以看作是一个Spare Features。
还有么?当然,我私下问了我之前在该公司任职的同学,他们还有一种思路就是划分数据集到M个子集,每个子集上面生成一个xgboost,然后每个子集取xgboost的叶子节点,相当于把左侧的Dense features复制了M份Dense features放在了右边的Spare Features,最后会得到一个M+1个Dense features。实际使用起来的效果完全不比word2vec的结果差。
Domonkos Tikk和Alexandros Karatzoglou在《Session-based Recommendations with Recurrent Neural Networks》文章中提到了可以用循环神经网络RNN来预估用户的行为,如下图:
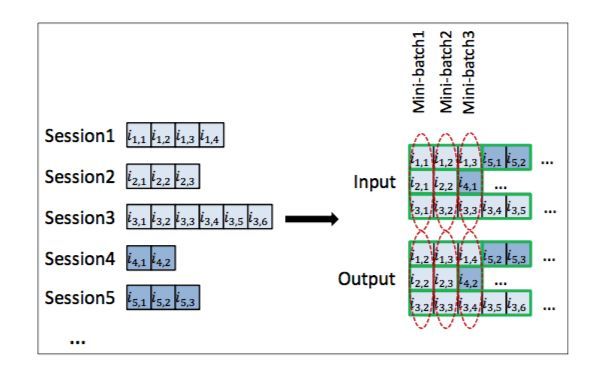
我们可以清晰的看到,针对每个用户Session1,他的行为由i1.1变化至i1.4其实是一个有序的过程,我们可以设计一个从i1.1---->i1.2,i1.2---->i1.3,i1.3---->i1.4这样的一个循环流程。同时在他的文章中还解释了这样的设计解决的两个问题:
the length of sessions can be very different
breaking down into fragments
一来通过了首尾相接,解决不同用户的session不同长度;二来通过了embedding layer,解决了不完整session下预测的可能。具体网络设计如下: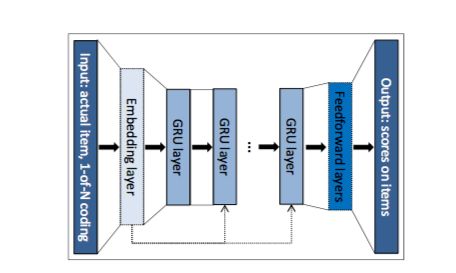
模型的更新流可以参考下面:
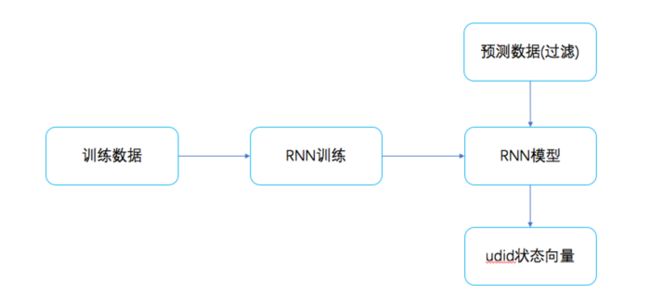
我们只需要拿到每个用户的item流下所对应的state即可,这state就包含了这个用前M次的操作潜藏信息,同时我们还可以随意定义这个信息向量的长度,这个就可以看作用户状态向量,作为子模块的输出。
这个思路的缺点就是,要预测的基础数据不存在时序性,效果极差。比如滴滴打车的下单过程,从登陆到打到车的时间最短在20s,最长在1分钟,否则用户就退出了app,这样的情况下,时序性质就显得格外薄弱,强行用这样的RNN获得的用户属性非常不存在代表性。
bagging

这个是我们Kaggle&TianChi分类问题相关纯算法理论剖析就强调过的bagging的最简单的形式,在每个子模块的设计选择过程中要尽可能的保证:
low biase
high var
也就是说子模块可以适当的过拟合,增加子模型拟合准确程度,通过加权平均的时候可以降低泛化误差。
stacking
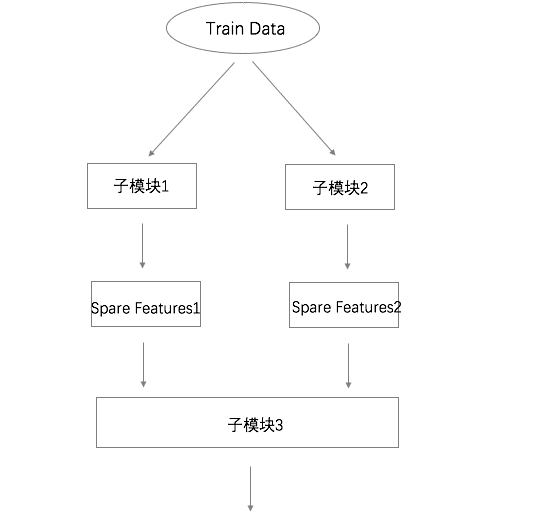
这个是我们Kaggle&TianChi分类问题相关纯算法理论剖析就强调过的stacking的最简单的形式,在每个子模块1、子模块2的设计选择过程中要尽可能的保证:
high biase
low var
在子模块3的时候,要保证:
low biase
high var
也就是说,在子模块1,2的选择中,我们需要保证可稍欠拟合,在子模块3的拟合上再保证拟合的准确度及强度。
blending
我们知道单个组合子模块的结果不够理想,如果想得到更好的结果,需要把很多单个子模块的结果融合在一起:
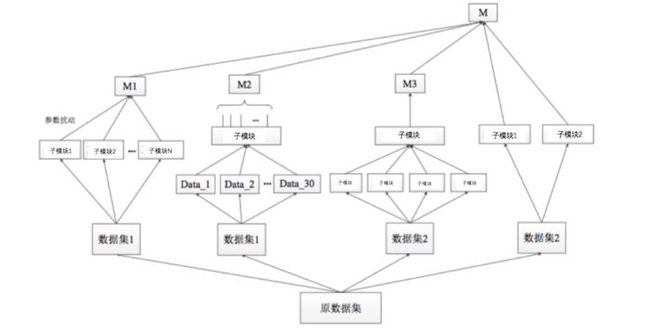
这种方法也可以提高我们最后的预测的效果。
关于有监督学习的方法大概就梳理到这边,最后希望能够给一些新人同学对有监督的理解和实战有一些帮助。
没啥广告要打,就这样吧。
[1] 周志华。《机器学习》,清华大学出版社,3.7,2016
[2] wepon。 《PPD_RiskControlCompetition》
[3] 爱奇艺技术产品团队。 《爱奇艺个性化推荐排序实践》
[4] slade。 《Kaggle&TianChi分类问题相关纯算法理论剖析》
[5] E Cernadas,D Amorim。 《Do we need hundreds of classifiers to solve real world classification problems?》
[6] slade。 《深度学习下的电商商品推荐》
[7] Domonkos Tikk,Alexandros Karatzoglo。 《Session-based Recommendations with Recurrent Neural Networks》
[8] slade. 《FM理论解析及应用》
原文链接:https://www.jianshu.com/p/cde181d5a9f2
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python