基于keras-yolo3个人的细节理解
本文主要是对自己学习YOLOV3时记录与梳理,加深印象,同时希望能给希望掌YOLOV3的朋友一点启发。观看本文默认对YOLOv3有一定的了解,我不会把每一个知识点都写到。
我没有去看过作者的源代码,我看的是基于KERAS版本的代码,应该是差不多的。本文基于此代码,文中若有错误,希望告知改正。
KERAS版代码地址:https://github.com/qqwweee/keras-yolo3
项目下载下来再下载权重文,转成.H5的权重文件直接就能用,训练也很方便。你若想快速使用,推荐下面这篇博客
windows10+keras下的yolov3的快速使用及自己数据集的训练:https://blog.csdn.net/u012746060/article/details/81183006
一、网络结构与前向传播
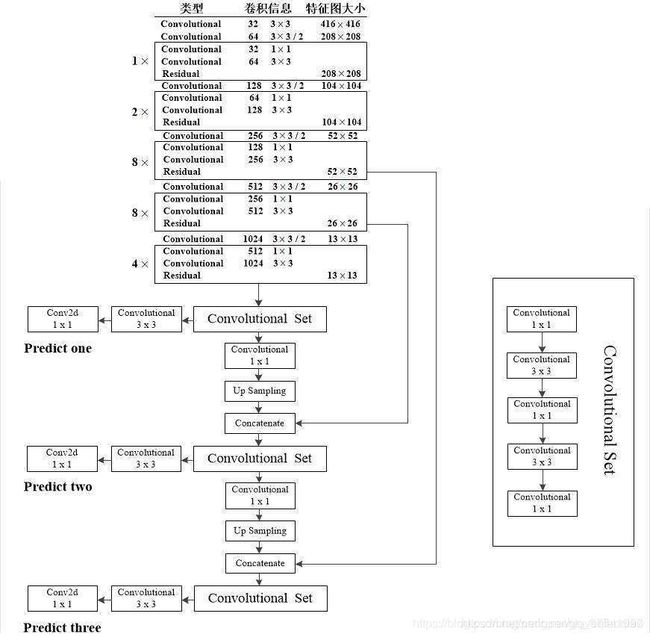
网络的输入采用的是416*416(网络的输入只要是32的倍数理论上都是可行的(全卷积),输入尺寸我可能会在后续试一试, 不在本篇叙述,本篇所说的都是在416*416的基础上说的。)。
个人喜欢把网络结构分成两个部份来看,1.darknet 53去掉输出层,2.三输出层。
网络结构个人觉得没什么讲的必要,稍微懂点神经网络的都能看明白,我简单说一下我觉得比较重要的地方:
1.整个网络没有池化层,特征图缩小是靠卷积时步长为2实现,
2.darknet 中加入了残差操作。
3.图像经过darknet输出的特征图缩小了32倍(这就 是输入需要是32的倍数的原因),以416*416为例,输出13*13.
4.yolov3的输出层有3个,是在不同的尺寸的特征图做的输出(13*13,26*26,52*52),加入了特征层的融合。
predict one :13*13 ,直接在13*13的特征图上进行了一些卷积操作,以COCO数据集为例,最终输出形状[batch,13,13,255]
predict two : 在predict one 的输出层(去掉最外面两层)基础上上采样(特征图尺寸*2),并与darknet中得到的26*26特征图(26*26的特征图有几个,取最后一个)做连接(重点,concatenate非add)。一系列卷积得到输出形状[batch,26,26,255]
predict three : 在predict two 的输出层(去掉最外面两层)基础上上采样(特征图尺寸*2),并与darknet中得到的52*52特征图(52*52的特征图有几个,取最后一个)做连接(重点,concatenate非add)。一系列卷积得到输出形状[batch,52,52,255]
5.输出数据的含意【batch ,S,S,3*(4个坐标信息+置信度+类别数80)】,s代表网格数,坐标信息后面会详细解释。
前向传播大致讲清楚了。一张416*416的图片输出网络,最终得到的是一个输出列表list([batch,13,13,255],[batch,26,26,255],[batch,52,52,255]),图片尺寸若不是416*416,转换成416成416的尺寸。
下面是贴出转换方式(预测,训练中也有类似操作)
def letterbox_image(image, size):
'''resize image with unchanged aspect ratio using padding'''
iw, ih = image.size
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
image = image.resize((nw,nh), Image.BICUBIC)
new_image = Image.new('RGB', size, (128,128,128))
new_image.paste(image, ((w-nw)//2, (h-nh)//2))
return new_image
二、怎么去做损失。
说损失前,不得不简单提一下YOLO的识别原理:
yolo将待识别图划分成S*S个格子,每个格子设有三个bounding box,用来识别中心点落在格子中的目标。yolo并没有直接预测bounding box的坐标,而是选取了个参照物计算中间结果,由中间结果和网络的输出做损失,这个参照物就anchor(注意和faster rcnn的有一定区别)。
我的理解就 是anchor是9个由试验得出来的先验框,尺寸分别是
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326yolo的输出有三层,每个网络有三个bounding box,正好对应9个anchor.
yolo的输出list( [13*13*(3*85)],[26*26*(3*85)],[52*52*(3*85)])
标签样式list( [13*13*3*85],[26*26*3*85],[52*52*3*85])
由一个图片样本到输入网络的true_y的全过程来说明其中的关系。

由图可见,上图中有两个目标。
第一步:图片转成41*416,坐标同步转换。
第二步:确定由哪个bounding box预测目标
确定方法:单个目标的面积和anchor的面积重合度最高(iou最大),此步是将目标框的中心点和anchor的中心点重合,算出与anchor最大的iou,选择iou最大的anchor,anchor与bounding box是一种绑定关系,确定了anchor就确定了bounding box,
bounding box 与anchor 的绑定关系:
13*13的特征图拥有最大的感受野,对应anchor 为116,90; 156,198; 373,326;(小的特征图预测大物体),
26*26的特征图拥有中等的感受野,对应anchor 为30,61; 62,45; 59,119 ;
52*52的特征图拥有较小的感受野,对应anchor 为10,13;16,30;33,23;
输出 为13*13*255 reshape 13*13*3*85, '3'代表着bounding box,例如上图样本中的人 与 373,326 anchor iou 最大(肉眼感觉未经计算,也可能是156,198),就由输出层的predict one 中的 第三个bounding box 对应。同理推26,52.此时,样本框与anchor就对应上了。
对应的anchor 确定后,输出层的选择也是确定了的(predict one,predict two , predict three选择哪个)。输出层的选择定下来,由哪个网格进行预测也是能确定下来。(样本中的框坐标是已知的,中心点落在哪个框就能确定下来。)
到此,一个样本中的框对应到哪个bounding box就讲完了。(给你一个坐标框,现已能找到对应三个输出层的哪层,哪个网格grid cell,第几个doundingbox.)
第三步:目标框与boundingbox的转换关系。(非常核心,包括网络输出中的4个坐标值)
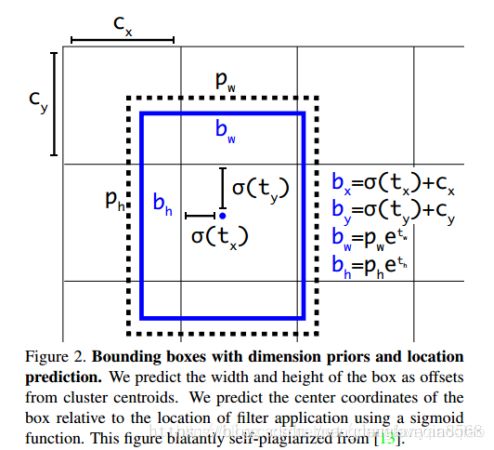
tx,ty,tw,th:神经网络的输出值,
cx,cy:本网格左上角坐标。
![]() 激活函数sigmoid().
激活函数sigmoid().
pw,ph:对应绑定的anchor w, h值
bx,by,bw,bh:预测出来的框的坐标。
以样本中人举例:假如![]() =0。7,
=0。7,![]() =0.3,其落在了CX =6,CY= 7的格子,那么他的实际中心点坐标为bx=(0.7+6) *32 =214.4 , by =(0.3+7)*32 = 233.6。(32是每个网格边长)
=0.3,其落在了CX =6,CY= 7的格子,那么他的实际中心点坐标为bx=(0.7+6) *32 =214.4 , by =(0.3+7)*32 = 233.6。(32是每个网格边长)
真正参与坐标损失计算的是:![]() ,
,![]() ,tw,th。点中心相对于检测其的网格左上角的偏移量,取值在0-1之间(保证了中心点一定是落在了本网格中) ;tw,th:宽高相对于绑定的anchor的偏移量。
,tw,th。点中心相对于检测其的网格左上角的偏移量,取值在0-1之间(保证了中心点一定是落在了本网格中) ;tw,th:宽高相对于绑定的anchor的偏移量。
因此,样本坐标需要根据上面公式反函数转换一下才能参与loss计算,
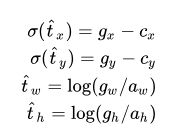
等号左边是转换的目标值,gx,gy,gw,gh代表样本中目标的中心点坐标,宽高,注意归一化。
梳理原始坐标信息转换成参与y_true:
1.每一个原始坐标与9个anchor做iou,选 出最大iou的anchor.
2.根据所选的anchor和坐标的中心点确定由某输出层,某网格,某bounding box来做预测
3.根据对应的公式将原始坐标转换成与网络输出对应的坐标,置信度设为1,类别设为1.
Y标签列表list( [13*13*3*85],[26*26*3*85],[52*52*3*85])初始全为零,当有一个目标是,添加一个进列表
还是以上图人为例,属于第一个输出,第7列,第6行,第三个bounding box,人在COCO数据中分类的下标为0,
predict one[7,6,3,0:4] =[![]()
![]() ,
,![]() ,
, ![]() ],predict one[7,6,3,4] =1,predict one[7,6,3,(5+0)] =1,
],predict one[7,6,3,4] =1,predict one[7,6,3,(5+0)] =1,
上图中还有个自行车,就不再进行细说了。由此可见,大部份的标签都是零。
至此,样本坐标怎么转换成参与损失计算的Y标签讲解完毕。
loss
现在标签有了,网络的输出也有了,该做损失计算。
yolov3的输出层除了wh,采用的是sigmoid激活函数,损失函数使用的是binary_crossentropy。wh损失函数采用的是差方。
有目标的,才计算4个坐标损失和分类损失,有没有目标都会计算置信度损失,
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy,
raw_pred[...,0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh-raw_pred[...,2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[...,4:5],
from_logits=True)+ (1-object_mask) * K.binary_crossentropy(object_mask,
raw_pred[...,4:5], from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[...,5:],
from_logits=True)
训练梳理完成。
预测推理:
此版代码预测的图片需要转换成416*416尺寸,想要实现任意图片输出的可以自行尝试。
1.图片转换成416*416尺寸,输入网络,得到网络输出。(别忘了训练时图片做了哪些处理,预测时保持一致)
2.算出每个bounding box的得分:box score 为在某个分类条件下的得分,值为 分类*置信度(一个框可以有多个类,实现多标签预测)
共有13*13*3,26*26*3, 52*52*3 共10647个预测
3.满足box score的保留,将网络输出坐标转换成真实预测坐标。
4.nms操作,得到保留的预测结果
5.坐标由缩放后的转换到原图,得到最终检测结果。
附:
yolov3网络结构的详图:
