python 字典对象 底层实现 源码分析 PyDictObject(dict)
PyDictObject
本文参考的是 3.8.0a0 版本的代码,详见 cpython 源码分析 基本篇
以后都在 github 更新,请参考 图解python dict
dict 顾名思义是字典,通常来讲一个字典对象都是通过 HashTable 实现,HashTable 里面有一排桶,根据哈希算法不同的 key 映射到不同的或者相同的桶的位置,然后把 key/value 对存储到对应的桶里,因为哈希算法的时间复杂度是 O(1),所以dict的平均查询/增删减改的时间复杂度也会是 O(1)
下面我们来看下 Python 的 PyDictObject
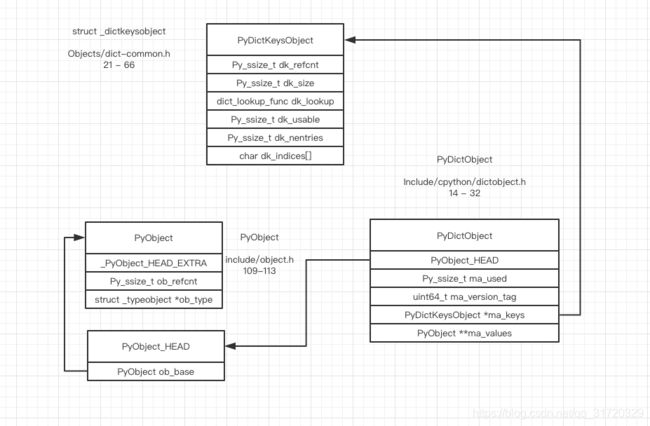
PyDictObject 的信息主要存储在以下的四个位置:
Objects/dictobject.c
Objects/dict-common.h
Include/dictobject.h
cpython/dictobject.h
并且由上图可知,PyDictObject 主要由以下几部分构成
PyObject_HEAD python 对象基本信息
Py_ssize_t ma_used 字典里存储的元素的数量
uint64_t ma_version_tag 一个标记来表示字典对象版本,如果这个字典是全局唯一,则每次更改字典这个值也会跟着改变
PyDictKeysObject *ma_keys: 是实际存储数据的哈希表,具体有下面两种存储方式
PyObject **ma_values: 参考下面列出的两种存储方式
如果 ma_values 是空的值,则这个字典对象是 "combined" 字典对象,
如果 ma_values 是空的值,则这个字典对象是 "splitted" 对象,key 和 value 都存储在 ma_keys 里面
combined table:
ma_values 是空的值, 此时 dk_refcnt == 1, key 和 value 都存储在 PyDictObject->ma_keys (PyDictKeysObject)
split table:
ma_values 不为空, 此时 dk_refcnt >= 1, key 存储在 PyDictObject->ma_keys 而 value 存储在 PyDictObject->ma_values
PyDictKeysObject
看到上面的 combined table/split table/图上画的 PyDictKeysObject 感觉到云里雾里,和传统的哈希表不太一样,下面我们来分析一下具体的字段以及实现
PyDictKeysObject 是这个哈希表具体的存储方式,在 python3.6 以前,哈希表中具体的存储空间是如下方式分配的

而在 python3.6 之后,引入了一种新的存储机制来对存储空间进行优化,如下图所示

此时,indices 是一个数组,他的大小就是哈希表的大小,对于每个key,在 indices 上面进行哈希取模,找到的是对应的位置,再到 entries 里面对应的位置取出实际的 key 和 value
以上图为例,哈希表的大小为7,实际只有3个key/value存储在里面,余下的4个key/value 都是空的位置,假设每个 hash_key/key/value 长度为 8 个 bytes,那么第一种方法存储这 3 个对象需要的空间为 3 * 8 * 7 = 168 bytes,而第二种方法存储这三个对象需要的空间为: indices(1bytes/格) 1 * 7 + 3 * 8 * 3 = 79 bytes, 节省了 53% 左右的空间占用,并且第二种存储结构更加紧凑,比起第一种,对 cpu 的缓存系统来说更加友好,
比方说,遍历哈希表读取key/value时,每次读取某一对key/value,cpu 会把这一对附近的内存空间一起取到最近一级的缓存中,如果是第一种存储分散的方法,可能这次取到cpu缓存中的 key/value 相邻空间中存储的都是未占用的值,需要读取下一个 key/value的时候他并不在cpu的缓存中, 需要重新一级一级把下一个key/value对以及相邻的空间再读取上来,会浪费很多 cpu cycle。
而第二种存储紧凑的方法,相邻空间中一定是有值的 key/value,产生cpu的 cache miss 概率会小很多。
好了,了解了 Python 对 PyDictKeysObject 存储方式的改进,下面我们来看一下 PyDictKeysObject 在当前版本中的 memory layout

源码中的注释如下所示
/*
layout:
+---------------+
| dk_refcnt |
| dk_size |
| dk_lookup |
| dk_usable |
| dk_nentries |
+---------------+
| dk_indices |
| |
+---------------+
| dk_entries |
| |
+---------------+
*/dk_refcnt 引用计数器数目
dk_size 这张哈希表的大小(存储的元素的数目)
dk_lookup 查找表中的元素的函数
dk_usable 在 dk_entries 中可用的数量
dk_nentries 在 dk_entries 中使用中的数量
dk_indices 和 dk_entries 参考上图新的存储方式
combined table 是当你新建 dict 等方式创建字典对象时,使用的是这种结构,也是如上图所示的结构
split table 是PEP412引入的为了提高内存使用率而使用的一种字典实现,不同的 PyDictObject 共享一个 PyDictKeysObject 对象,其中的 key 和 hash 值相同,而 value 为空,真正的 value 存储在 PyDictObject 的 ma_values 里面,在创建/继承了很多个类或者类实例的情况下,split table 可以节省很多空间,因为这些类的属性名称大部分都是相同的
参考资料:
[Python-Dev] More compact dictionaries with faster iteration
Faster, more memory efficient and more ordered dictionaries on PyPy
PEP412