python之日期与时间处理模块及利用pandas处理时间序列数据
文章目录
- 时间序列
- 一.日期和时间数据类型及工具
- 1.1字符串与datetime互相转换
- 二.时间序列基础
时间序列
时间序列(time series)数据是一种重要的结构化数据形式,应用于多个领域,包括金融学、经济学、生态学、神经科学、物理学等。在多个时间点观察或测量到的任何事物都可以形成一段时间序列。很多时间序列是固定频率的,也就是说,数据点是根据某种规律定期出现的(比如每15秒、每5分钟、每月出现一次)。时间序列也可以是不定期的,没有固定的时间单位或单位之间的偏移量。时间序列数据的意义取决于具体的应用场景,主要有以下几种:
时间戳(timestamp),特定的时刻。
固定时期(period),如2007年1月或2010年全年。
时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例。
实验或过程时间,每个时间点都是相对于特定起始时间的一个度量。例如,从放入烤箱时起,每秒钟饼干的直径
一.日期和时间数据类型及工具
Python标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。我们主要会用到datetime、time以及calendar模块。datetime.datetime(也可以简写为datetime)是用得最多的数据类型:

datetime以毫秒形式存储日期和时间。timedelta表示两个datetime对象之间的时间差:
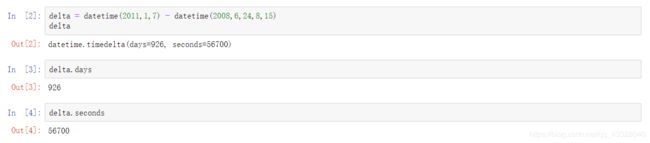
可以给datetime对象加上(或减去)一个或多个timedelta,这样会产生一个新对象:

datetime模块中的数据类型参见表10-1。虽然本章主要讲的是pandas数据类型和高级时间序列处理,但你肯定会在Python的其他地方遇到有关datetime的数据类型。

1.1字符串与datetime互相转换
你可以使用str方法或传递一个指定的格式给strftime方法来将日期转化为字符串:

下表列出了全部的格式化编码

datetime.strptime可以将字符串转换为日期:

datetime.strptime是通过已知格式进行日期解析的最佳方式。但是每次都要编写格式定义是很麻烦的事情,尤其是对于一些常见的日期格式。这种情况下,你可以用dateutil这个第三方包中的parser.parse方法(pandas中已经自动安装好了):

dateutil可以解析几乎所有人类能够理解的日期表示形式:
![]() 在国际通用的格式中,日出现在月的前面很普遍,传入dayfirst=True即可解决这个问题:
在国际通用的格式中,日出现在月的前面很普遍,传入dayfirst=True即可解决这个问题:
![]()
pandas通常是用于处理成组日期的,不管这些日期是DataFrame的轴索引还是列。to_datetime方法可以解析多种不同的日期表示形式。对标准日期格式(如ISO8601)的解析非常快:

它还可以处理缺失值(None、空字符串等):

NaT(Not a Time)是pandas中时间戳数据的null值。
二.时间序列基础
pandas最基本的时间序列类型就是以时间戳为索引的Series:
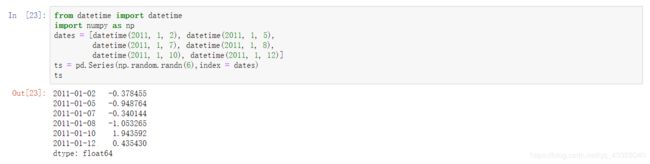
这些datetime对象实际上是被放在一个DatetimeIndex中的:

跟其他Series一样,不同索引的时间序列之间的算术运算会自动按日期对齐:

未完待续~~