最近几天,知乎大V@恶魔奶爸的一条朋友圈成了今日头条旗下“悟空问答”和知乎之间 battle 全面爆发的导火索。
今日头条今年一口气签了300多个知乎大V,刚把我也签了,而且是给钱的,年收入比普通白领高。签完以后所有内容不可以再发知乎。优质的内容创作者被抢完了,所以知乎的质量每况愈下...
知乎联合创始人张亮则表示:“至少在过去一年时间里,我都很希望有俩人赶紧离开知乎,一个是‘恶魔奶爸’,另一个是‘霍老爷’。”
火药味十足。
然而,今日头条和知乎之间的“战争”不仅仅是这么简单,在内容分发的技术上,以及AI人才的争夺上,两者也之间也展开了“竞赛”,而这场竞赛的表现形式之一就是“算法大赛”。
大家都知道,今日头条挖来了微软亚研院的前常务副院长马维英,掌管其人工智能实验室。实际上,知乎也在悄悄布局。
据AI科技大本营了解,知乎已经组建了一个机器学习团队,而本次算法大赛的负责人张瑞便是机器学习团队中的一员,曾经就职于百度和豌豆荚的张瑞。据介绍,张瑞在获得北京邮电大学硕士学位后一直从事搜索引擎及自然语言处理方向的研发工作。
既然两者都有数据,也有需求,那么通过举办算法大赛来为自己提供新思路,顺便扩大影响力并招揽人才也就在情理之中了。
知乎看山杯机器学习挑战赛
2016 年,今日头条联合中国人工智能学会联合、IEEE 中国举办了一场为期三个月 BYTE CUP国际机器学习竞赛。此次比赛的任务是建立模型,预测专家可能回答某一问题的概率,旨在更有效率地将头条问答中普通人的问题推送给愿意回答的专家。
今年 5 月 15 日,知乎算法团队联合中国人工智能学会、 IEEE 计算机协会和 IEEE 中国代表处,发起「知乎看山杯机器学习挑战赛」。大赛以语义分析应用为赛题,对知乎上的内容进行精准的自动化话题标注,以提升知乎的用户体验和提高内容分发效率。
可以看出,两者的赛题都是跟提高问答内容的分发效率直接相关的。要知道,今日头条的问答频道于 2016 年 7 月 14 日才在头条 App 内正式上线。因此,虽然知乎的算法大赛来的晚了些,但也算得上是反击今日头条的第一枪。
8 月 15日,创新工场、搜狗和今日头条又宣布共同发起“AI Challenger 全球 AI 挑战赛”,首届挑战赛将于 9 月 4 日正式拉开帷幕。
不过,AI Challenger 大赛还未开始,知乎的比赛结果已经于昨日(8 月 30 日)新鲜出炉:来自北京邮电大学模式识别实验室的 init 团队成功夺魁。
虽然知乎并不是第一家举行算法大赛的中国公司,但是这场比赛对国内的 AI 社区来说,依然有着积极的示范作用。至少,比携程大数据比赛的口碑要好得多。
让我们来一起回顾下这场比赛。
背景简介
目前,知乎上的内容分发的一个重要途径是通过关注关系生成的 Feed 流。关注关系可能是基于人,也可能是基于「话题」标签;从用户关注的话题标签为用户推荐内容,会更加契合用户对不同领域、不同类型的知识的需求。因此,对知乎上的内容进行精准的自动化话题标注,对提升知乎的用户体验和提高内容分发效率有非常重要的支撑作用。同时,对文本的语义进行理解和自动标注,尤其是在标签数量巨大、标签之间具有一定的相互关联关系的场景下的 tagging,也是目前自然语言处理的一个前沿研究方向。
任务描述
参赛者需要根据知乎给出的问题及话题标签的绑定关系的训练数据,训练出对未标注数据自动标注的模型。
标注数据中包含 300 万个问题,每个问题有 1 个或多个标签,共计1999 个标签。每个标签对应知乎上的一个「话题」,话题之间存在父子关系,并通过父子关系组织成一张有向无环图(DAG)。
由于涉及到用户隐私及数据安全等问题,本次比赛不提供问题、话题描述的原始文本,而是使用字符编号及切词后的词语编号来表示文本信息。同时,鉴于词向量技术在自然语言处理领域的广泛应用,比赛还提供字符级别的 embedding 向量和词语级别的 embedding 向量。
评测方法
知乎提供包含 217360 个问题的评测数据集,参赛者需要在这些问题上运行训练出的模型进行预测,并标注 Top 5 的话题标签,此外,预测出的话题标签之间存在顺序。
-
预测出的 5 个话题标签按照预测得分,从大到小排序。
-
话题标签默认是不重复的。遇到重复的话题标签,只保留第一次出现,并且其后的标签递补。去重后不满 5 个标签的,其余位置默认为 -1,-1 不和任何话题标签匹配。多于 5 个话题标签的,从第六位往后忽略。
-
评测标准:
准确率(Precision): 预测出的标签命中了标注标签中的任何一个即视为正确。最终的准确率为每个位置上的准确率按位置加权。准确率评测的公式如下: `math Precision = \sum_{pos \in \{1,2,3,4,5\}} \frac {Precision@pos} {log_{pos + 1}} `
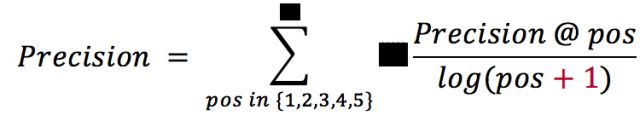
召回率(Recall): 预测出的 Top 5 标签中对原有标签的覆盖量。
最终评价指标为 Precision 和 Recall 的调和平均数。即:
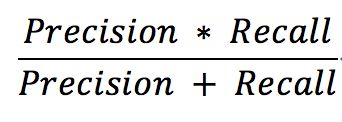
比赛结果
获奖选手是评审团队根据参赛队伍所提交的模型在验证数据集上的表现( 成 绩及排名链接-https://biendat a.com/competition/zh ihu/leaderboard/ ),而最终筛选确认。
为了验证结果,在获奖队伍提交其方法说明及可复现的代码和模型数据后,评审团队逐一评审了获奖队伍的方法及代码,并且随机抽取其中一些队伍提交的模型,使用另外一份验证数据集进行了结果的验证。本次比赛共有 7 支队伍获奖,获奖名单如下:
一等奖一名,奖金 40,000 元,获奖队伍是来自北京邮电大学的 init 团队;
二等奖两名,奖金 10,000 元,获奖队伍是:
-
来自北京邮电大学的 Koala 团队;
-
来自中科院计算所、Google 和百度的 YesOfCourse 团队;
三等奖四名,奖金 5,000 元,获奖队伍是:
-
来自 Microsoft 和北京大学的 NLPFakers 团队;
-
来自武汉大学、伦敦大学学院(University College London)的 Gower Street & 81 Road 团队;
-
来自北京邮电大学的 ye 团队;
-
来自郑州铁路局、同花顺公司、电子科技大学中山学院的 Yin & Bird 团队。
比赛亮点
知乎张瑞表示,所有获奖的 7 支队伍,都无一例外地使用了各种结构的深度神经网络(Deep Nerual Network,DNN),而传统的文本分类方法,例如支持向量机(Support Vector Machine,SVM)或者朴素贝叶斯(Naive Bayes)等方法,则使用较少。这也许说明,在一定程度上,深度神经网络已经成为 NLP 领域的主流方法。
-
init 团队:TextCNN + TextRNN + RCNN,共享 Embedding 进行联合学习,在模型集成方面,使用多模型、等权重的 Bagging 方法进行集成;在数据预处理方面,使用 delete 和 shuffle 进行数据增强;
-
Koala 团队:FastText + TextCNN + TextRNN,使用 boosting 的思想对神经网络进行逐层训练,各个网络之间使用加权平均的 bagging 方式;
-
YesOfCourse 团队:使用 TextCNN + LSTM/GRU + RCNN 作为基模型,并且利用 GBRank 融合多个神经网络的输出;
-
NLPFakers 团队:使用 TextCNN + RNN + RCNN 作为基模型,利用线性加权进行模型集成;在神经网络训练中使用了 attention 机制;
-
Gower Street & 81 Road 团队:使用 RNN 神经网络作为基础模型,并且将 Query-TopicTitle 的相似度与神经网络进行联合训练。最终使用 Bagging with Ensemble Selection 作为模型集成策略;
-
ye 团队:使用 TextCNN + BiGRU 作为基础模型,利用带有权重搜索的 bagging 作模型集成策略;
-
Yin&Bird 团队:利用 LSTM 和 Bayes 方法作为基础模型,并且利用 stacking 方法进行模型集成。
在对问题进行建模时,所有参赛队伍都将问题转化成了「文本多分类」或者「文本标签预测」的问题。在训练过程中,大多数团队都选用了交叉熵(Cross Entropy)作为损失函数。所有的参赛队伍都应用了集成学习的思想,利用多个模型的相互补充来提高成绩。同时选手们还针对自己对问题的理解对问题进行了非常多的优化,出现了一些很有亮点的优化方法。
例如:
第一名的 init 团队,在数据增强方面进行了富有创意的工作。init 团队在进行模型训练的时候,通过 delete 和 shuffle 机制来避免训练结果的过拟合,同时保证模型的差异性。init 团队在提交的评审材料中提到,仅仅通过数据增强机制,训练出来的多模型结果通过等权重的 bagging 方式得到的结果已经能够获得优于第二名结果的表现。
第二名的 Koala 团队,在进行神经网络训练的时候,使用了逐层 boosting 的方法,来提升单个神经网络模型的表现;根据其描述,这个优化可以使多层神经网络的表现提升 1.5 个百分点左右。
第三名的 YesOfCourse 团队将 tag precition 过程转化成了一个 Recall-Rarank 的两步问题;使用大量的神经网络模型来进行召回,并且将神经网络对标签的预测得分作为 GBRank 的特征输入,并且使用 Pairwise 的方式来对标签的排序进行优化,选择排序后的前 5 个标签作为模型的输出。从 YesOfCourse 团队提交的说明中看出,使用 Recall + Rerank 模型得到的结果,相对于 Non-Linear NN Ensemble 的结果,有千分之二以上的提升;同时,YesOfCourse 还尝试使用了多种 Loss Function 和多种 attention 机制来保证模型间的差异性。
第五名的 Gower Street & R1 Road 团队,则将数据提供的 topic 的标题信息利用了起来,使用 RNN + Question-Topic Similarity 信息进行模型的联合训练。将单模型的结果从 0.415 提升到了 0.419,并且使用 20 个模型的 ensemble,最终取得了 0.432 的好成绩。
算法大赛的未来
张瑞表示,关于这个问题本身,知乎很早就启动了相关的研究,例如 word2vec + CNN,LSTM 等,已经有一个相对成熟的版本在线上运行。
“我们绝不是「花小钱来骗大家的技术」。”张瑞称,“我们对参赛者抱有非常大的期待。相信通过比赛,大家能够从一些我们之前想不到的地方提出一些独特的见解,碰撞出一些思维的火花,对我们工作的进一步改进有很大启发。我们也非常希望参赛者们借助比赛,提升自己对自然语言处理领域的兴趣和能力,让大赛对彼此都能双赢。”
不过,目前AI领域最具影响力的大赛基本都是国外的,除了语言因素和发展的先后之外,高质量数据集的缺乏也是一大掣肘。张瑞在专栏上写道,“”
据张瑞介绍,除了这次比赛的文本标签数据集外,他们还将发布一些与知乎密切相关的数据集和机器学习任务,例如内容推荐、社交网络链接预测等数据集,这些数据集会在经过严格脱敏和审核后,陆续开放。
在算法越来越难以取得突破性进展的今天,高质量数据集的重要性进一步凸显。相对于那些大公司,高校学者和独立的开发者想要获得研究数据,更是难上加难。
与此同时,不论是知乎的“看山杯”,还是今日头条和创新工场、搜狗一起联合举行的“AI Challenger”,都通过算法比赛间接地为 AI 社区贡献了大量的数据。
因此,不管这些公司的初衷是为了扩大影响力,还是为了招揽人才,至少这是一个好的开始。