hadoop MapReduce的输出压缩算法的设置(四种方法)
MapReduce的过程中,一个job结束之后,会输出处理完毕的数据集,也就是reduce的处理结果。我们可以将这些结果采用指定的压缩算法输出到指定的文件夹中。
map端数据的压缩:要求是reduce从map端进行数据拉取的时候,传输速度要快,此时适合选择snappy数据压缩算法。
reduce端数据压缩:reduce端数据最终输出到HDFS上进行数据存储,要求是数据的占用空间要小,所以,可以选择gzip进行数据压缩。
常用的四种方法:
方法一:通过配置参数进行传值
原理:这些配置会被加载到conf对象中,供job的mapreduc任务使用。
缺点:对于大长串的参数不建议放在这里,会导致参数传递混乱,建议放在xml中进行配置。
优点:-D传参不用改变源码,这点是十分重要的,要知道,我们的项目都会被打成jar包部署在服务器集群上,不用修改源码即可传参,十分灵活。
在Idea中,在edit Configurations中配置,其实就是通过将参数传给main函数进行设置压缩格式。
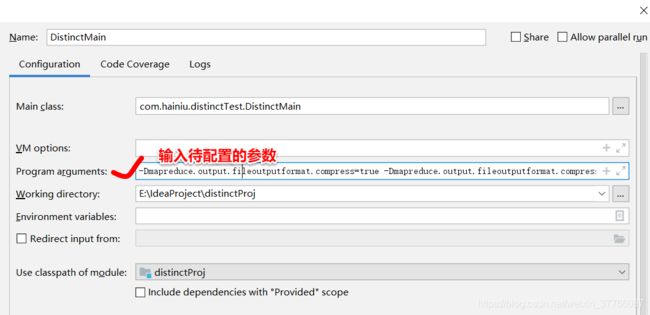
格式:-Dname=value
示例:
上图中Program arguments的参数如下(后面两个参数是输入输出路径):
-Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.ip.compress.GzipCodec /tmp/mr/input /tmp/mr/output
方法二:
在Tool接口的run方法中,设置输出格式,添加以下两行代码:
FileOutputFormat.setCompressOutput(job,true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);方法三:
在Tool接口的run方法中,利用Configuration对象进行设置,如下:
conf.set(FileOutputFormat.COMPRESS,"true");
conf.set(FileOutputFormat.COMPRESS_CODEC,GzipCodec.class.getName());等价于:
conf.set("mapreduce.output.fileoutputformat.compress","true");
conf.set("mapreduce.output.fileoutputformat.compress.codec",GzipCodec.class.getName());方法四:通用配置,采用xml
在java的resouces文件中,添加mapred-site.xml文件,文件结构如图:
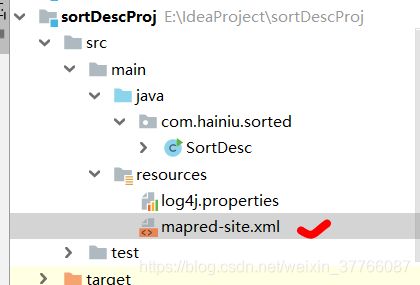
文件的内容如下:
mapreduce.map.output.compress
true
map是否启用压缩
mapreduce.map.output.compress.codec
org.apache.hadoop.io.compress.SnappyCodec
map采用何种压缩算法
mapreduce.output.fileoutputformat.compress
true
reduce是否启用压缩
mapreduce.output.fileoutputformat.compress.codec
org.apache.hadoop.io.compress.GzipCodec
reduce采用何种压缩算法
总结:
1 加载顺序(从源码可以看出来):首先加载xml配置文件,再加载-D参数,如果遇到和xml相同的参数,那么重写参数。
最后加载的是conf.set,conf.set遇到-D参数相同的设置,则重写。源码如下:
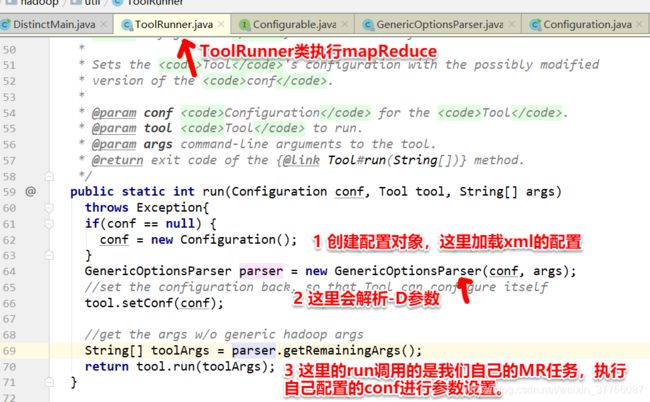
2 优缺点:
-D参数配置:灵活,但是不适合大长串的参数
conf.set()的方式:可以进行单个job任务的mr配置
XML的配置:公司的集群配置有权限设置。同时,所有集群的hadoop项目都会加载这个配置文件。