李宏毅机器学习-----逻辑回归Logistic Regression
接上上一节的内容,我们认为通过概率模型最后推导出来函数还是为了求出最优的w和b,所以为什么不直接找一个function来直接求呢?那就是今天要介绍的Logistic Regretion!
[上节链接]链接
逻辑回归的Function Set
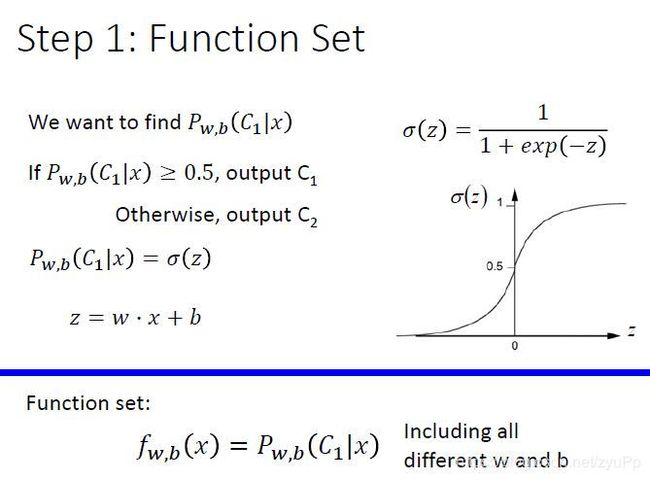
后验概率 P w , b ( C 1 ∣ x ) P_{w,b}(C_1|x) Pw,b(C1∣x)就是 σ ( z ) \sigma(z) σ(z),而z=wx+b,推导出function set就是 f w , b ( x ) = P w , b ( C 1 ∣ x ) f_{w,b}(x)=P_{w,b}(C_1|x) fw,b(x)=Pw,b(C1∣x),受w和b所控制的function
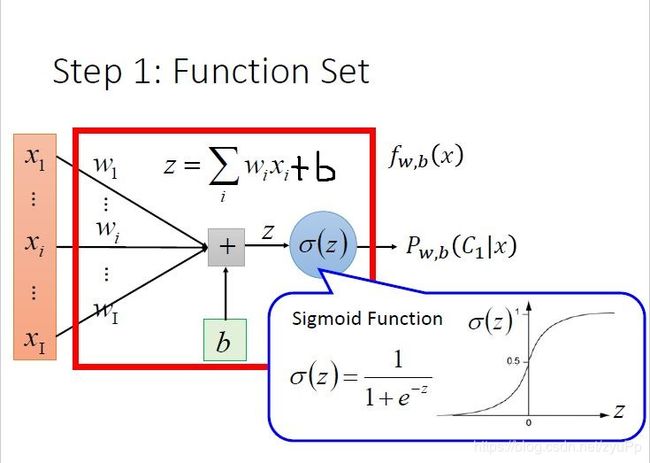
如果我们图像化这个function,就是上图这个样子啦!~
逻辑回归与线性回归比较

逻辑回归就是做多了一步,把wx+b放进sigmoid函数中,要求输出在0至1之间。
Step2:定义损失函数

假设有一组training data,size是N,而且分别有自己的类别标签C,给定一组 w和b,就可以计算这组w,b下产生上图N个训练数据的概率, f w , b ( x 3 ) f_{w,b}(x^3) fw,b(x3)是 x 3 x^3 x3属于C1的机率,因为它是C2,所以要用 1 − f w , b ( x 3 ) 1-f_{w,b}(x^3) 1−fw,b(x3),最好的w和b,就是让概率 L ( w , b ) L(w,b) L(w,b)最大的时候, w ∗ , b ∗ = a r g m a x w , b L ( w , b ) w ^∗ ,b^ ∗ =argmax _{w , b} L(w,b) w∗,b∗=argmaxw,bL(w,b)

将训练集数字化,Class1等于1,Class2等于0,并且将式中求max通过取负自然对数转化为求min,化成 − l n -ln −ln的格式之后,相乘就等于相加

将 − l n L ( w , b ) −lnL(w,b) −lnL(w,b)改写为上图中带蓝色下划线式子的样子,图中蓝色下划线实际上代表的是两个伯努利分布(0-1分布,两点分布)的 cross entropy(交叉熵)
假设有两个分布 p 和 q,这两个分布的交叉熵就是H(p,q),交叉熵代表的含义是这两个分布有多接近,如果两个分布是一模一样的话,那计算出的交叉熵就是0

- 逻辑回归怎么定义一个function的好坏呢?
如果把function的输出和target(算出的function和真实的 y ^ n \hat{y}^n y^n)都看作是两个伯努利分布,所做的事情就是希望这两个分布越接近越好,cross entropy最小使得Loss最小 - 线性回归定义function好坏?
函数f(x)的输出减去真实值 y ^ n \hat{y}^n y^n的平方,这是我们需要最小化的对象。
疑 问 : 为 什 么 逻 辑 回 归 不 用 线 性 回 归 的 平 方 误 差 的 计 算 方 式 呢 ? \color{red}{疑问:为什么逻辑回归不用线性回归的平方误差的计算方式呢?} 疑问:为什么逻辑回归不用线性回归的平方误差的计算方式呢?
而 是 用 交 叉 熵 , 后 续 再 详 细 解 说 , 有 点 复 杂 \color{red}{而是用交叉熵,后续再详细解说,有点复杂~} 而是用交叉熵,后续再详细解说,有点复杂
Step3:找最好的函数
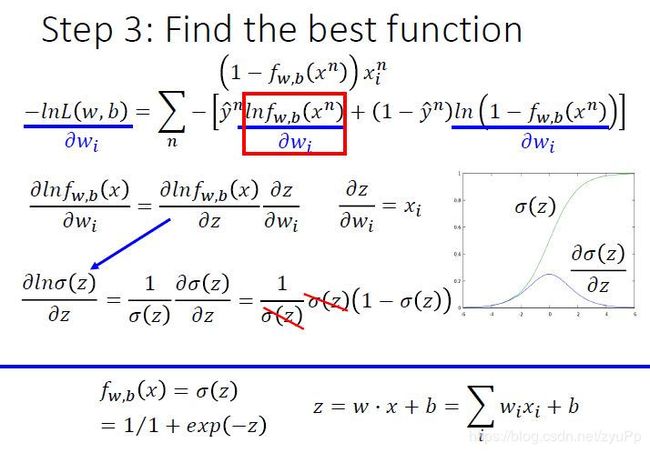
找最好的function,就是最小化 − l n L ( w , b ) -ln L(w,b) −lnL(w,b),用梯度下降方法即可。
- 先算出 l n f w , b ( x n ) lnf_w,_b(x^n) lnfw,b(xn)对 w i w_i wi 的偏微分
- f w , b ( x ) f_w,_b(x) fw,b(x)可以用 σ ( z ) \sigma{(z)} σ(z)表示,而z可以用 w i 和 b w_i和 b wi和b表示,所以利用链式法则展开
- 再算出 l n ( 1 − f w , b ( x n ) ) ln(1-f_w,_b(x^n)) ln(1−fw,b(xn))对 w i w_i wi 的偏微分
- 同第二步的求解方式(链式法则,分解计算)
备 注 : ( l n x ) ′ = 1 / x , s i g m o i d 求 导 : s ( x ) ′ = s ( x ) ⋅ ( 1 − s ( x ) ) \color{red}{备注:(lnx)'= 1/x ,sigmoid求导:s(x)'=s(x)\cdot(1-s(x)) } 备注:(lnx)′=1/x,sigmoid求导:s(x)′=s(x)⋅(1−s(x))

计算完微分之后,分别把下面两个东西带回进去公式里:
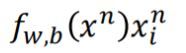
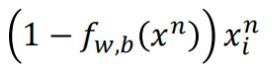

现在 w i w_i wi的更新取决于学习率 η , x i n x^n_i xin 以及上图的紫色划线部分;紫色下划线部分直观上看就是真正的目标 y n y^n yn与我们的function差距有多大。
比较线性回归和逻辑回归如何挑选最好function

公式是长得一模一样的;区别在于:
对于逻辑回归,target y n y^n yn是0或者1,输出是介于0和1之间。而线性回归的target可以是任何实数,输出也可以是任何值。
损失函数:为什么不用线性回归的平方误差?

我们尝试使用square error来计算逻辑回归,当做到第三步,我们对函数求微分的时候,得到式子。假设 y ^ n = 1 \hat y^n=1 y^n=1,如果 f w , b ( x n ) = 1 f_w,_b(x_n)=1 fw,b(xn)=1,就是非常接近target,偏微分为0;而 f w , b ( x n ) = 0 f_w,_b(x_n)=0 fw,b(xn)=0的时候,偏微分还是0。

假设 y ^ n = 0 \hat y^n=0 y^n=0,结果是一样的,微分值还是0
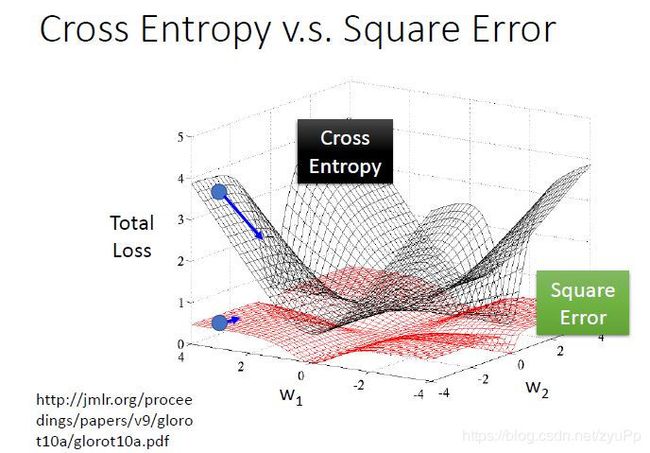
如果是交叉熵,距离target越远,微分值就越大,就可以做到距离target越远,更新参数越快。而平方误差在距离target很远的时候,微分值非常小,会造成移动的速度非常慢,可能跑好久都跑不出来。
判别模型与生成模型的区别
逻辑回归称之为判别方法
用高斯来描述后验概率称之为生成方法

function set是一样的,如果是逻辑回归,就直接找出w和b出来;如果是概率生成模型,就要找出 μ 1 , μ 2 , Σ − 1 \mu^1,\mu^2,\Sigma^{-1} μ1,μ2,Σ−1,然后在把w和b算出来
这两个方法算出来的w和b是不一样的,用的是同一个model,但是做了不同的假设,逻辑回归没有做任何假设,在生成模型中是做了假设的,假设是高斯分布等等。

上图是前一篇的例子,图中画的是只考虑两个因素,如果考虑所有因素,结果是逻辑回归的效果好一些,通常有人会说判别模型通常比生成模型表现得要好,为什么会这样呢?下面举个例子:
例子(判别总比生成好?):

上图的训练集有13组数据,类别1里面两个特征都是1,剩下的(1, 0), (0, 1), (0, 0) 都认为是类别2;然后给一个测试数据(1, 1),它是哪个类别呢?人类来判断的话,不出意外基本都认为是类别1。下面看一下朴素贝叶斯分类器(Naive Bayes)会有什么样的结果。
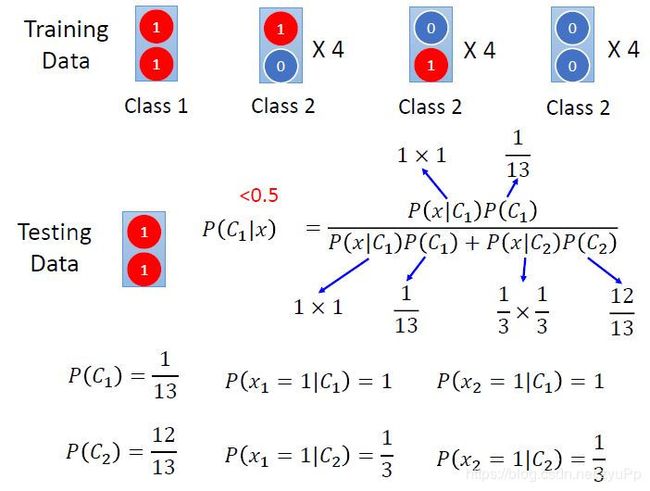
先列出先验概率P(C1)和P(C2),然后看看P(x|C)的概率。
x属于 C i C_i Ci 的概率等于每个特征属于 C i C_i Ci概率的乘积
计算出 P ( C 1 ∣ x ) P(C_1|x) P(C1∣x)的结果是小于0.5的,即对于朴素贝叶斯分类器来说,测试数据 (1, 1)是属于类别2的。
其实这是合理,因为实际上训练集的数据量太小,但是对于 (1, 1)可能属于类别2这件事情,朴素贝叶斯分类器是有假设这种情况存在的(机器脑补这种可能性)。所以结果和人类直观判断的结果不太一样
判别方法不一定比生成方法好

- training data很少的时候,generative model表现得更好,因为它比起discriminative model,受data影响的程度更小,它会无视一些data,去遵从它的假设(脑补)
- 当data是noisy的,比较多噪声(label有问题),而generative model对于噪声数据有更好的鲁棒性(robust),因为可以把一些有问题的data忽视掉
- 先验和类相关的概率可以从不同的来源估计。语音识别大都使用神经网络来进行处理,是判别方法,但事实上整个语音识别是 Generative 的方法,DNN只是其中的一块而已;因为还是需要算一个先验概率,就是某句话被说出来的概率,而估计某句话被说出来的概率不需要声音数据,只需要爬很多的句子,就能计算某句话出现的机率,这就是language model。Priors部分用文字数据处理,class-dependent部分用语音数据处理。
多类别分类
只说过程,不说原理;
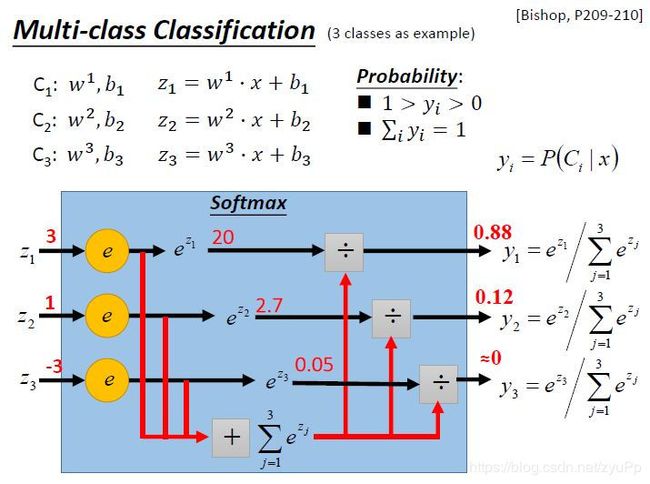
假设有3个类别,每个都有自己的weight和bias,写出 z 1 z 2 z 3 z_1z_2z_3 z1z2z3
把 z 1 z 2 z 3 z_1z_2z_3 z1z2z3放入softmax函数,函数里面分别把 z 1 z 2 z 3 z_1z_2z_3 z1z2z3做exponential(指数化),然后把结果加起来得到总和,再分别用 exponential 的结果除以相加的结果,得到 y 1 y 2 y 3 y_1y_2y_3 y1y2y3
做完Softmax之后输出会被限制住,y都介于0到1之间,并且和是1。Softmax做事情就是对最大值进行强化,意思是把大的值和小的值,之间的间隔拉得更开
输入x,属于类别1的概率是0.88,属于类别2的概率是0.12,属于类别3的概率是0。
为什么Softmax的输出可以用来估计后验概率?(拓展阅读)
假设有3个类别,这3个类别都是高斯分布,它们也共用同一个协方差矩阵,进行类似上一篇讲述的推导,就可以得到Softmax。
信息论学科中有一个 Maximum Entropy(最大熵)的概念,也可以推导出Softmax。简单说信息论中定义了一个最大熵。指数簇分布的最大熵等价于其指数形式的最大似然界。二项式的最大熵解等价于二项式指数形式(sigmoid)的最大似然,多项式分布的最大熵等价于多项式分布指数形式(softmax)的最大似然,因此为什么用sigmoid函数,那是因为指数簇分布最大熵的特性的必然性。假设分布求解最大熵,引入拉格朗日函数,求偏导数等于0,直接求出就是sigmoid函数形式。还有很多指数簇分布都有对应的最大似然界。而且,单个指数簇分布往往表达能力有限,就引入了多个指数簇分布的混合模型,比如高斯混合,引出了EM算法。像LDA就是多项式分布的混合模型。
定义目标值
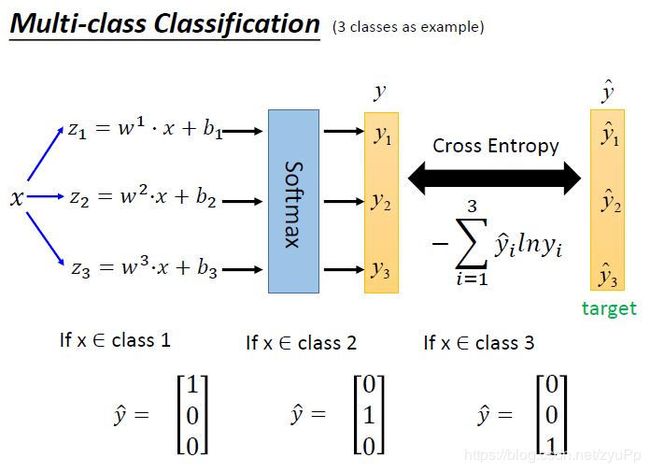
两边都要当作probability distribution来看,用cross entropy来比较训练出来的y和真实值 y ^ \hat y y^,我们不能把类别1定义为1,类别2定义为2,类别3定义为3,这样会人为制造了相关性(1类和3类远一点,2类和3类近一点),但可以将 y ^ \hat{y} y^定义为矩阵,这样就避免了。而且为了计算交叉熵, y ^ \hat{y} y^也需要是个概率分布才可以.
逻辑回归的缺陷
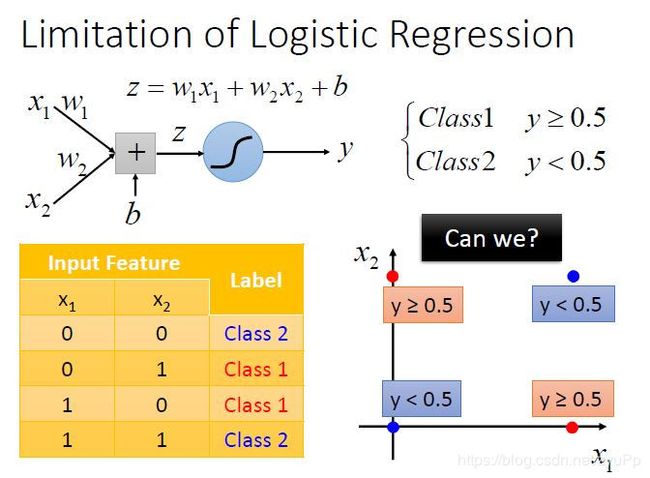
没法做这个题目,boundary是一条直线,无法分类两个对角线的位置
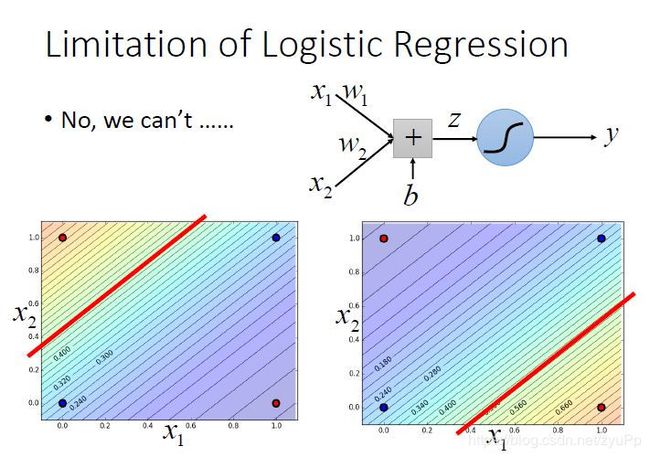
逻辑回归所能做的分界线就是一条直线,没有办法将红蓝色用一条直线分开
假设坚持使用logistic regression的话,可以尝试用特征转换
特征转化
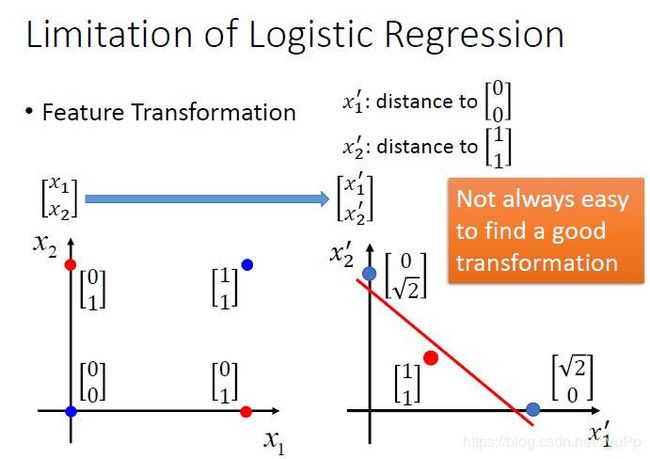
特征转换的方式很多,举例类别1转化为某个点到 (0,0) 点的距离,类别2转化为某个点到 (1,1)点的距离。然后问题就转化右图,此时就可以处理了。但是实际中并不是总能轻易的找到好的特征转换的方法。
级联逻辑回归模型
有时候我们不知道如何找到好的feature transformation的方法,我们希望这个transformation让机器自己产生,所以就让多个model级联起来
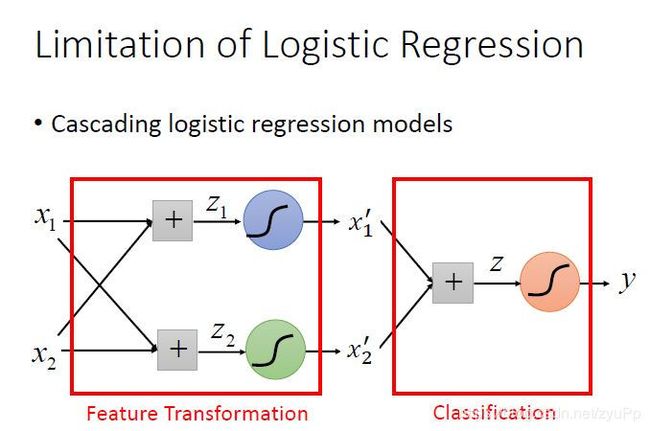
可以将很多的逻辑回归接到一起,就可以进行特征转换。比如上图就用两个逻辑回归 对 z 1 , z 2 z_1,z_2 z1,z2来进行特征转换,然后对于 x 1 ′ , x 2 ′ x_1^{'},x_2^{'} x1′,x2′,只要最后可以用一条直线把那些点分开,就可以再用一个逻辑回归z来进行分类。
刚才的例子:
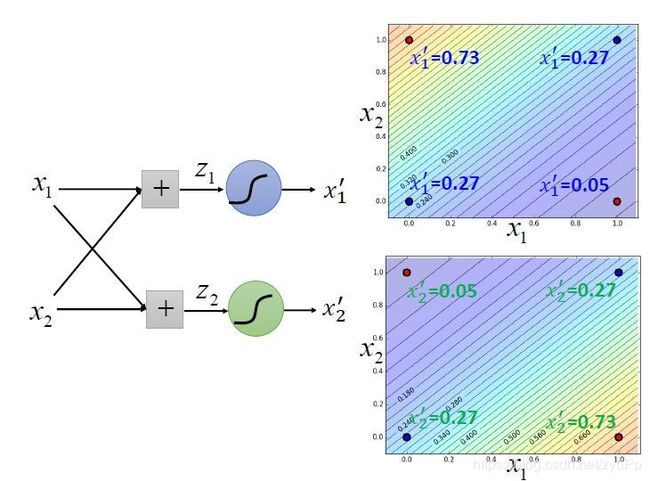
对两个sigmoid函数调整参数,使得数据点可以分开
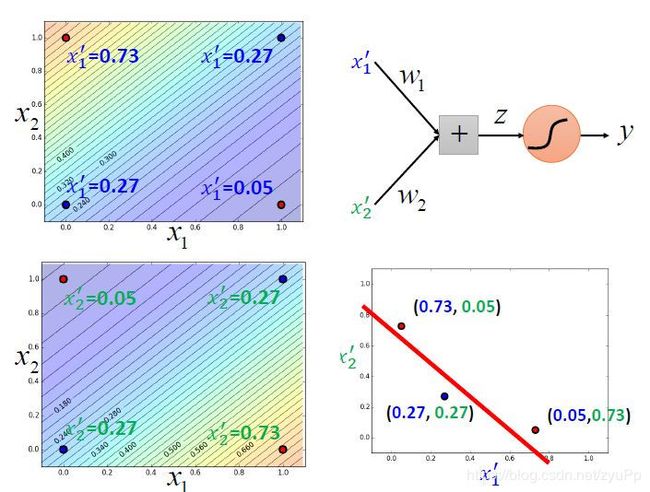
经过这样的转换之后,数据点就被处理为可以进行分类的结果。如果我们只有一个逻辑回归,处理不了这个问题;当我们有三个逻辑回归级联在一起,就可以解决问题了。
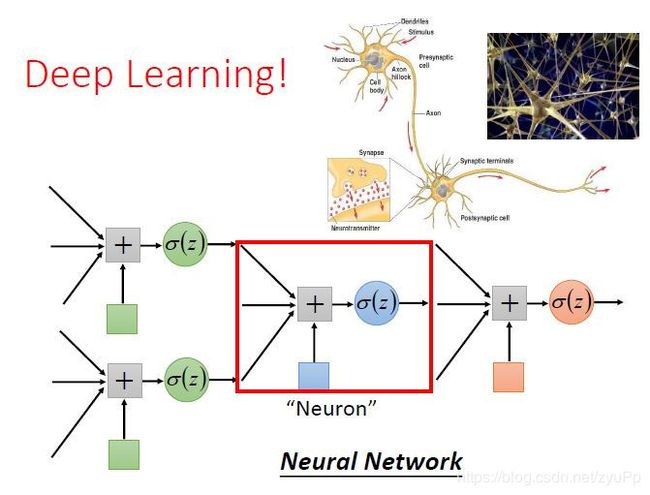
一个逻辑回归的输入可以来源于其他逻辑回归的输出,这个逻辑回归的输出也可以是其他逻辑回归的输入。把每个逻辑回归称为一个 Neuron(神经元),把这些神经元连接起来的网络,就叫做 Neural Network(神经网络)。