【存储】RAID 技术介绍和总结
【存储】RAID 技术介绍和总结
简介
RAID是一个我们经常能见到的名词。但却因为很少能在实际环境中体验,所以很难对其原理 能有很清楚的认识和掌握。本文将对RAID技术进行介绍和总结,以期能尽量阐明其概念。
RAID全称为独立磁盘冗余阵列(Redundant Array of Independent Disks),基本思想就是把多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、 容量巨大的硬盘。RAID通常被用在服务器电脑上,使用完全相同的硬盘组成一个逻辑扇区,因此操作系统只会把它当做一个硬盘。 RAID分为不同的等级,各个不同的等级均在数据可靠性及读写性能上做了不同的权衡。 在实际应用中,可以依据自己的实际需求选择不同的RAID方案。
标准RAID
RAID 0
RAID0称为条带化(Striping)存储,将数据分段存储于 各个磁盘中,读写均可以并行处理。因此其读写速率为单个磁盘的N倍(N为组成RAID0的磁盘个数),但是却没有数 据冗余,单个磁盘的损坏会导致数据的不可修复。

大多数striping的实现允许管理者通过调节两个关键的参数来定义数据分段及写入磁盘的 方式,这两个参数对RAID0的性能有很重要的影响。
STRIPE WIDTH
stripe width是指可被并行写入的 stripe 的个数,即等于磁盘阵列中磁盘的个数。
STRIPE SIZE
也可称为block size(chunk size,stripe length,granularity),指写入每个磁 盘的数据块大小。以块分段的RAID通常可允许选择的块大小从 2KB 到 512KB不等,也有更 高的,但一定要是2的指数倍。以字节分段的(比如RAID3)一般的stripe size为1字节或者 512字节,并且用户不能调整。 stripe size对性能的影响是很难简单估量的,最好在实际应用中依自己需求多多调整并 观察其影响。通常来说,减少stripe size,文件会被分成更小的块,传输数据会更快,但 是却需要更多的磁盘来保存,增加positioning performance,反之则相反。应该说,没有 一个理论上的最优的值。很多时候,也要考虑磁盘控制器的策略,比如有的磁盘控制器会等 等到一定数据量才开始往磁盘写入。
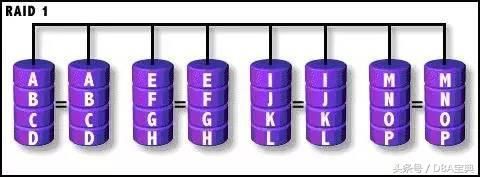
RAID 1
镜像存储(mirroring),没有数据校验。数据被同等地写入两个或多个磁盘中,可想而知,写入速度会比较 慢,但读取速度会比较快。读取速度可以接近所有磁盘吞吐量的总和,写入速度受限于最慢 的磁盘。 RAID1也是磁盘利用率最低的一个。如果用两个不同大小的磁盘建立RAID1,可以用空间较小 的那一个,较大的磁盘多出来的部分可以作他用,不会浪费。
RAID 2
RAID0的改良版,加入了汉明码(Hanmming Code)错误校验。
汉明码能够检测最多两个同时发生的比特错误,并且能够更正单一比特的错误。汉明码的位 数与数据的位数有一个不等式关系,即:
2^P ≥ P + D +1
P代表汉明码的个数,D代表数据位的个数,比如4位数据需要3位汉明码,7位数据需要4位汉 明码,64位数据时就需要7位汉明码。RAID2是按1bit来分割数据写入的,而P:D就代表了数据 盘与校验盘的个数。所以如果数据位宽越大,用于校验的盘的比例就越小。由于汉明码能够 纠正单一比特的错误,所以当单个磁盘损坏时,汉明码便能够纠正数据。
RAID 2 因为每次读写都需要全组磁盘联动,所以为了最大化其性能,最好保证每块磁盘主 轴同步,使同一时刻每块磁盘磁头所处的扇区逻辑编号都一致,并存并取,达到最佳性能。 如果不能同步,则会产生等待,影响速度。
与RAID0相比,RAID2的传输率更好。因为RAID0一般stripe size相对于RAID2的1bit来说 实在太大,并不能保证每次都是多磁盘并行。而RAID2每次IO都能保证是多磁盘并行,为了 发挥这个优势,磁盘的寻道时间一定要减少(寻道时间比数据传输时间要大几个数量级),所 以RAID2适合于连续IO,大块IO(比如视频流服务)的情况。
RAID 3
类似于RAID2,数据条带化(stripe)存储于不同的硬盘,数据以字节为单位,只是RAID3使用单块磁盘存储简单的 奇偶校验信息,所以最终磁盘数量为 N+1 。当这N+1个硬盘中的其中一个硬盘出现故障时, 从其它N个硬盘中的数据也可以恢复原始数据,当更换一个新硬盘后,系统可以重新恢复完整 的校验容错信息。

由于在一个硬盘阵列中,多于一个硬盘同时出现故障率的几率很小,所以一般情况下,使用 RAID3,安全性是可以得到保障的。RAID 3会把数据的写入操作分散到多个磁盘上进行,不管是向哪一个数据盘写入数据, 都需要同时重写校验盘中的相关信息。因此,对于那些经常需要执行大量写入操作的应用来 说,校验盘的负载将会很大,无法满足程序的运行速度,从而导致整个RAID系统性能的下降。 鉴于这种原因,RAID 3更加适合应用于那些写入操作较少,读取操作较多的应用环境,例如 数据库和WEB服务器等。
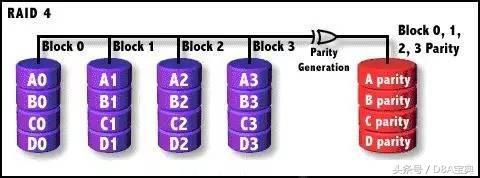
RAID 4
与RAID3类似,但RAID4是按块(扇区)存取。无须像RAID3那样,哪怕每一次小I/O操作也要涉 及全组,只需涉及组中两块硬盘(一块数据盘,一块校验盘)即可,从而提高了小量数据 I/O速度。
RAID 5
奇偶校验(XOR),数据以块分段条带化存储。校验信息交叉地存储在所有的数据盘上。

RAID5把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和 相对应的数据分别存储于不同的磁盘上,其中任意N-1块磁盘上都存储完整的数据,也就是 说有相当于一块磁盘容量的空间用于存储奇偶校验信息。因此当RAID5的一个磁盘发生损坏 后,不会影响数据的完整性,从而保证了数据安全。当损坏的磁盘被替换后,RAID还会自动 利用剩下奇偶校验信息去重建此磁盘上的数据,来保持RAID5的高可靠性。
RAID 5可以理解为是RAID 0和RAID 1的折衷方案。RAID 5可以为系统提供数据安全保障,但 保障程度要比镜像低而磁盘空间利用率要比镜像高。RAID 5具有和RAID 0相近似的数据读取 速度,只是因为多了一个奇偶校验信息,写入数据的速度相对单独写入一块硬盘的速度略慢。
RAID 6
类似RAID5,但是增加了第二个独立的奇偶校验信息块,两个独立的奇偶系统使用不同的算法, 数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。但RAID 6需要分配给 奇偶校验信息更大的磁盘空间,相对于RAID 5有更大的“写损失”,因此“写性能”非常差。
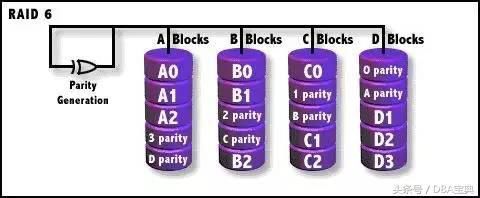
由图所知,每个硬盘上除了都有同级数据XOR校验区外,还有一个针对每个数据 块的XOR校验区。当然,当前盘数据块的校验数据不可能存在当前盘而是交错存储的。从数 学角度来说,RAID 5使用一个方程式解出一个未知变量,而RAID 6则能通过两个独立的线性 方程构成方程组,从而恢复两个未知数据。
伴随着硬盘容量的增长,RAID6已经变得越来越重要。TB级别的硬盘上更容易造成数据丢失, 数据重建过程(比如RAID5,只允许一块硬盘损坏)也越来越长,甚至到数周,这是完全不可接受的。而RAID6允许两 块硬盘同时发生故障,所以渐渐受到人们的青睐。
伴随CD,DVD和蓝光光盘的问世,存储介质出现了擦除码技术,即使媒介表面出现划痕,仍然可以播放,大多数常见的擦除码算法已经演变为上世纪60年代麻省理工学院林肯实验室开 发的Reed-Solomon码。实际情况中,多数RAID6实现都采用了标准的RAID5教校验比特和Reed-Solomon码 。而纯擦除码算法的使用使得RAID 6阵列可以失效两块以上的硬盘,保护力度更强,有些实现方法提供了多种级别的保护,甚至允许用户(或存储管理员)指定保护级别。
混合RAID
RAID 01
顾名思义,是RAID0和RAID1的结合。先做条带(0),再做镜像(1)。
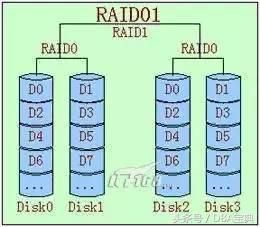
RAID 10
同上,但是先做镜像(1),再做条带(0)

RAID01和RAID10非常相似,二者在读写性能上没有什么差别。但是在安全性上RAID10要好于 RAID01。如图中所示,假设DISK0损坏,在RAID10中,在剩下的3块盘中,只有当DISK1故障, 整个RAID才会失效。但在RAID01中,DISK0损坏后,左边的条带将无法读取,在剩下的3快盘 中,只要DISK2或DISK3两个盘中任何一个损坏,都会导致RAID失效。
RAID10和RAID5也是经常用来比较的两种方案,二者都在生产实践中得到了广泛的应用。 RAID10安全性更高,但是空间利用率低。至于读写性能,与cache有很大关联,最好根据实 际情况测试比较选择。
非标准RAID
DRFS
DRFS,即DistributedRaidFileSystem,是一种尝试将RAID与Hadoop的DFS结合起来的技术。 通常的HDFS在实践中需要将replication factor设为3以保证数据完整性,而如果利用 RAID的stripe和partity(奇偶校验)技术,将数据分为多个块,并且存储各个块的校验信 息(XOR或擦除码)。有了这些措施,块的副本数就可以降低并且保证同样的数据可靠性,就能节省相当一部 分的存储空间。
DRFS包含以下几个组件:
-
DRFS client: 提供应用程序访问DRFS的接口,在发现读取到的文件有损坏时修复,整个操作对应用程序透明
-
RaidNode: 创建,维护检验文件的daemon
-
BlockFixer: 周期性地检查文件,重新计算校验和,修复文件.
-
RaidShell: 类似于hadoop shell.
-
ErasureCode: 即DRFS所使用的生成校验码的算法,可为XOR或者Reed-Solomon算法。 XOR仅能创建一个校验字节,而Reed-Solomon则可以创建无数位(位数越多,能恢复的数 据也越多),如果使用Reed-Solomon,replication甚至可以降为1,缺点是降低了数据读 写的并行程度(只能从单机读写)。
实现
软件实现
现在很都操作系统都提供了RAID的软件实现,主要由以下几个方面:
-
由软件在多个设备上创建RAID,比如linux上的mdadm工具.具体使用方法可查看参考链接中 的例子。
-
LVM或者Veritas,虚拟卷管理工具
-
文件系统实现 :btrfs,ZFS,GPFS.这些文件都可以直接管理多个设备上的数据,实 现了类似各级RAID的功能。
-
在已有文件系统之上提供数据校验功能的RAID系统(RAID-F)
固件/驱动实现
软件实现并总是与系统的启动进程兼容,硬件实现(RAID控制器)总是太贵并且都是厂商专有的技术,所以 有了一中混合的实现:系统启动时,由固件(firmware)来实现RAID,系统启动的差不多了,由驱动来管 理RAID。当然,这需要操作系统对这种驱动提供支持。
QC工作站服务器RAID详解[RAID0/RAID1/RAID10/RAID5]
如果你家QC安装了服务器,那么你必须要明白RAID,如果您现在不了解RAID,请先收藏,后面一定会用到!
一.RAID定义
RAID(RedundantArray of Independent Disk 独立冗余磁盘阵列)技术是加州大学伯克利分校1987年提出,最初是为了组合小的廉价磁盘来代替大的昂贵磁盘,同时希望磁盘失效时不会使对数据的访问受损失而开发出一定水平的数据保护技术。RAID就是一种由多块廉价磁盘构成的冗余阵列,在操作系统下是作为一个独立的大型存储设备出现。RAID可以充分发挥出多块硬盘的优势,可以提升硬盘速度,增大容量,提供容错功能够确保数据安全性,易于管理的优点,在任何一块硬盘出现问题的情况下都可以继续工作,不会受到损坏硬盘的影响。
二、 RAID的几种工作模式(仅讨论 RAID0,RAID1,RAID5,RAID10这四种,这四种比较典型)
1、RAID0 (又称为Stripe或Striping--分条)
即Data Stripping数据分条技术。RAID 0可以把多块硬盘连成一个容量更大的硬盘群,可以提高磁盘的性能和吞吐量。RAID 0没有冗余或错误修复能力,成本低,要求至少两个磁盘,一般只是在那些对数据安全性要求不高的情况下才被使用。
特点:
| 容错性: |
没有 |
冗余类型: |
没有 |
| 热备盘选项: |
没有 |
读性能: |
高 |
| 随机写性能: |
高 |
连续写性能: |
高 |
| 需要的磁盘数: |
只需2个或2*N个(这里应该是多于两个硬盘都可以) |
可用容量: |
总的磁盘的容量 |
| 典型应用: |
无故障的迅速读写,要求安全性不高,如图形工作站等。 |
||
RAID 0的工作方式:
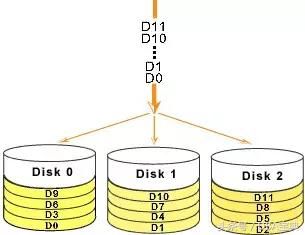
如图1所示:系统向三个磁盘组成的逻辑硬盘(RADI 0 磁盘组)发出的I/O数据请求被转化为3项操作,其中的每一项操作都对应于一块物理硬盘。我们从图中可以清楚的看到通过建立RAID 0,原先顺序的数据请求被分散到所有的三块硬盘中同时执行。
从理论上讲,三块硬盘的并行操作使同一时间内磁盘读写速度提升了3倍。但由于总线带宽等多种因素的影响,实际的提升速率肯定会低于理论值,但是,大量数据并行传输与串行传输比较,提速效果显著显然毋庸置疑。
RAID 0的缺点是不提供数据冗余,因此一旦用户数据损坏,损坏的数据将无法得到恢复。
RAID 0具有的特点,使其特别适用于对性能要求较高,而对数据安全不太在乎的领域,如图形工作站等。对于个人用户,RAID 0也是提高硬盘存储性能的绝佳选择。
计算机技术发展迅速,但硬盘传输率也成了性能的瓶颈。怎么办?IDE RAID技术的成熟让我们轻松打造自己的超高速硬盘。在实际应用中,RAID 0硬盘阵列能比普通IDE 7200转ATA 133硬盘快得多,时至今日,在大多数的高端或者玩家主板上我们都能找到一颗PROMISE或者HighPoint的RAID芯片,同时发现它们提供的额外几个IDE接口。没错,RAID已经近在眼前,难道你甘心放弃RAID为我们带来的性能提升吗?答案当然是否定的!
实用的IDE RAID
RAID可以通过软件或硬件实现。像Windows 2000就能够提供软件的RAID功能,但是这样需要消耗不小的CPU资源,降低整机性能。而硬件实现则是一般由RAID卡实现的,高档的SCSI RAID卡有着自己专用的缓存和I/O处理器,但是对于家庭用户来说这样的开销显然是承受不了的,毕竟为了实现RAID买两个或者更多的HDD已经相当不容易了。我们还有一种折中的办法——IDE RAID。或许这才是普通人最容易接受的方法。虽然IDE RAID在功能和性能上都有所折中,但相对于低廉的价格,普通用户看来并不在意。
为什么要用RAID 0
RAID 0至少需要两块硬盘才能够实现,它的容量为组成这个系统的各个硬盘容量之和,这几块硬盘的容量要相同,在家用IDE RAID中一般级联两块硬盘,一定要用同型号同容量的硬盘。RAID 0模式向硬盘写入数据的时候把数据一分为二,分别写入两块硬盘,读取数据的时候则反之,这样的话,每块硬盘只要负担一半的数据传输任务,得到的结果也就是速度的增加。
实现方式:
(1)、RAID 0最简单方式(我觉得这个方式不是它本意所提倡的)
就是把x块同样的硬盘用硬件的形式通过智能磁盘控制器或用操作系统中的磁盘驱动程序以软件的方式串联在一起,形成一个独立的逻辑驱动器,容量是单独硬盘的 x倍,在电脑数据写时被依次写入到各磁盘中,当一块磁盘的空间用尽时,数据就会被自动写入到下一块磁盘中,它的好处是可以增加磁盘的容量。
速度与其中任何一块磁盘的速度相同,如果其中的任何一块磁盘出现故障,整个系统将会受到破坏,可靠性是单独使用一块硬盘的1/n。
(2)、RAID 0的另一方式(常指的RAID 0就是指的这个)
是用n块硬盘选择合理的带区大小创建带区集,最好是为每一块硬盘都配备一个专门的磁盘控制器,在电脑数据读写时同时向n块磁盘读写数据,速度提升n倍。提高系统的性能。
2、RAID 1 (又称为Mirror或Mirroring--镜像)
RAID 1称为磁盘镜像:把一个磁盘的数据镜像到另一个磁盘上,在不影响性能情况下最大限度的保证系统的可靠性和可修复性上,具有很高的数据冗余能力,但磁盘利用率为50%,故成本最高,多用在保存关键性的重要数据的场合。RAID 1的操作方式是把用户写入硬盘的数据百分之百地自动复制到另外一个硬盘上。
RAID 1有以下特点:
(1)、RAID 1的每一个磁盘都具有一个对应的镜像盘,任何时候数据都同步镜像,系统可以从一组镜像盘中的任何一个磁盘读取数据。
(2)、磁盘所能使用的空间只有磁盘容量总和的一半,系统成本高。
(3)、只要系统中任何一对镜像盘中至少有一块磁盘可以使用,甚至可以在一半数量的硬盘出现问题时系统都可以正常运行。
(4)、出现硬盘故障的RAID系统不再可靠,应当及时的更换损坏的硬盘,否则剩余的镜像盘也出现问题,那么整个系统就会崩溃。
(5)、更换新盘后原有数据会需要很长时间同步镜像,外界对数据的访问不会受到影响,只是这时整个系统的性能有所下降。
(6)、RAID 1磁盘控制器的负载相当大,用多个磁盘控制器可以提高数据的安全性和可用性。
RAID 1的工作方式:

如图2所示:当读取数据时,系统先从RAID1的源盘读取数据,如果读取数据成功,则系统不去管备份盘上的数据;如果读取源盘数据失败,则系统自动转而读取备份盘上的数据,不会造成用户工作任务的中断。当然,我们应当及时地更换损坏的硬盘并利用备份数据重新建立Mirror,避免备份盘在发生损坏时,造成不可挽回的数据损失。
raid 1的优缺点
由于对存储的数据进行百分之百的备份,在所有RAID级别中,RAID 1提供最高的数据安全保障。同样,由于数据的百分之百备份,备份数据占了总存储空间的一半,因而Mirror(镜像)的磁盘空间利用率低,存储成本高。 Mirror虽不能提高存储性能,但由于其具有的高数据安全性,使其尤其适用于存放重要数据,如服务器和数据库存储等领域。
3、 RAID 5 (可以理解为是RAID 0和RAID 1的折衷方案,但没有完全使用RAID 1镜像理念,而是使用了“奇偶校验信息”来作为数据恢复的方式,与下面的RAID10不同。)
| 容错性: |
有 |
冗余类型: |
奇偶校验 |
| 热备盘选项: |
有 |
读性能: |
高 |
| 随机写性能: |
低 |
连续写性能: |
低 |
| 需要的磁盘数: |
三个或更多 |
||
| 可用容量: |
(n-1)/n的总磁盘容量(n为磁盘数) |
||
| 典型应用: |
随机数据传输要求安全性高,如金融、数据库、存储等。 |
||

RAID 5 是一种存储性能、数据安全和存储成本兼顾的存储解决方案。以四个硬盘组成的RAID 5为例,其数据存储方式如图4所示:图中,Ap为A1,A2和A3的奇偶校验信息,其它以此类推。由图中可以看出,RAID 5不对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
RAID 5可以理解为是RAID 0和RAID 1的折衷方案。RAID 5可以为系统提供数据安全保障,但保障程度要比Mirror低而磁盘空间利用率要比Mirror高。RAID 5具有和RAID 0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘空间利用率要比RAID 1高,存储成本相对较低。
4、RAID 10 (可以理解为是RAID 0和RAID 1的折衷方案,但没有完全使用RAID 1镜像理念,而是使用了“奇偶校验信息”来作为数据恢复的方式)
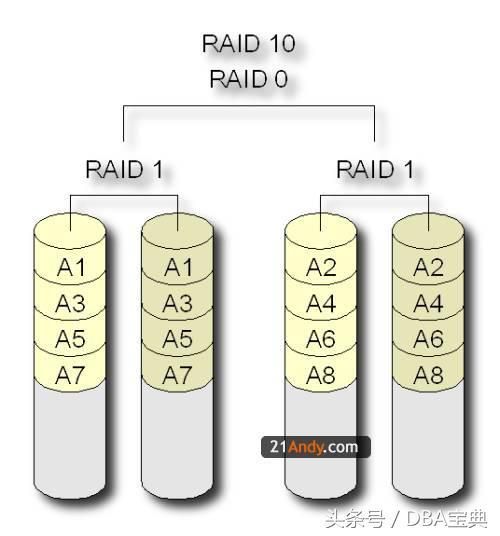
RAID10也被称为镜象阵列条带。象RAID0一样,数据跨磁盘抽取;象RAID1一样,每个磁盘都有一个镜象磁盘, 所以RAID 10的另一种会说法是 RAID 0+1。RAID10提供100%的数据冗余,支持更大的卷尺寸,但价格也相对较高。对大多数只要求具有冗余度而不必考虑价格的应用来说,RAID10提供最好的性能。使用RAID10,可以获得更好的可靠性,因为即使两个物理驱动器发生故障(每个阵列中一个),数据仍然可以得到保护。RAID10需要4 + 2*N 个磁盘驱动器(N >=0),而且只能使用其中一半(或更小, 如果磁盘大小不一)的磁盘用量, 例如 4 个 250G 的硬盘使用RAID10 阵列,实际容量是 500G。
RAID总结:
| 类型 |
读写性能 |
安全性 |
磁盘利用率 |
成本 |
应用方面 |
| RAID0 |
最好(因并行性而提高) |
最差(完全无安全保障) |
最高(100%) |
最低 |
个人用户 |
| RAID1 |
读和单个磁盘无分别,写则要写两边 |
最高(提供数据的百分之百备份) |
差(50%) |
最高 |
适用于存放重要数据,如服务器和数据库存储等领域。 |
| RAID5 |
读:RAID 5=RAID 0(相近似的数据读取速度)
写:RAID 5<对单个磁盘进行写入操作(多了一个奇偶校验信息写入) |
RAID 5<=""> |
RAID 5>RAID 1 |
RAID 5<=""> |
是一种存储性能、数据安全和存储成本兼顾的存储解决方案。 |
| RAID10 |
读:RAID10=RAID0
写:RAID10=RAID1 |
RAID10=RAID1 |
RAID10=RAID1(50%) |
RAID10=RAID1 |
集合了RAID0,RAID1的优点,但是空间上由于使用镜像,而不是类似RAID5的“奇偶校验信息”,磁盘利用率一样是50% |
关于Raid0,Raid1,Raid5,Raid10的总结
本文转载:科技新鲜事
RAID0
定义:
RAID 0又称为Stripe或Striping,它代表了所有RAID级别中最高的存储性能。RAID 0提高存储性能的原理是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求。这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。
工作原理:
系统向三个磁盘组成的逻辑硬盘(RAID0 磁盘组)发出的I/O数据请求被转化为3项操作,其中的每一项操作都对应于一块物理硬盘。通过建立RAID 0,原先顺序的数据请求被分散到所有的三块硬盘中同时执行。从理论上讲,三块硬盘的并行操作使同一时间内磁盘读写速度提升了3倍。 但由于总线带宽等多种因素的影响,实际的提升速率肯定会低于理论值,但是,大量数据并行传输与串行传输比较,提速效果显著显然毋庸置疑。
优缺点:
读写性能是所有RAID级别中最高的。
RAID 0的缺点是不提供数据冗余,因此一旦用户数据损坏,损坏的数据将无法得到恢复。RAID0运行时只要其中任一块硬盘出现问题就会导致整个数据的故障。一般不建议企业用户单独使用。
总结:
磁盘空间使用率:100%,故成本最低。
读性能:N*单块磁盘的读性能
写性能:N*单块磁盘的写性能
冗余:无,任何一块磁盘损坏都将导致数据不可用。
RAID1
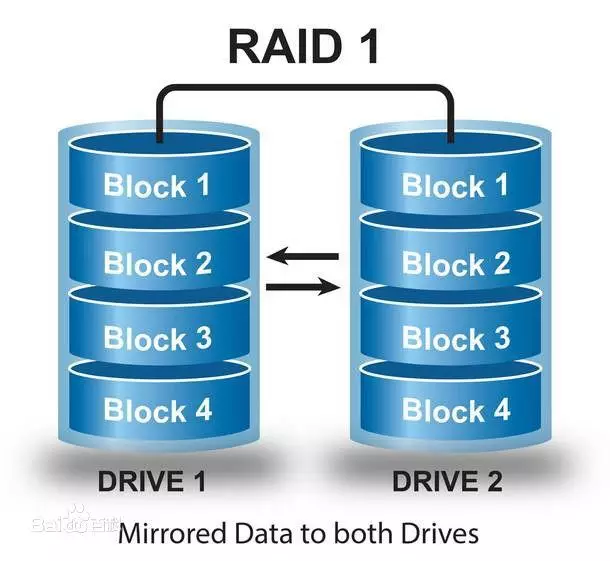
定义:
RAID 1通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据。当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID 1可以提高读取性能。RAID 1是磁盘阵列中单位成本最高的,但提供了很高的数据安全性和可用性。当一个磁盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据。
工作原理:
RAID1是将一个两块硬盘所构成RAID磁盘阵列,其容量仅等于一块硬盘的容量,因为另一块只是当作数据“镜像”。RAID1磁盘阵列显然是最可靠的一种阵列,因为它总是保持一份完整的数据备份。它的性能自然没有RAID0磁盘阵列那样好,但其数据读取确实较单一硬盘来的快,因为数据会从两块硬盘中较快的一块中读出。RAID1磁盘阵列的写入速度通常较慢,因为数据得分别写入两块硬盘中并做比较。RAID1磁盘阵列一般支持“热交换”,就是说阵列中硬盘的移除或替换可以在系统运行时进行,无须中断退出系统。RAID1磁盘阵列是十分安全的,不过也是较贵一种RAID磁盘阵列解决方案,因为两块硬盘仅能提供一块硬盘的容量。RAID1磁盘阵列主要用在数据安全性很高,而且要求能够快速恢复被破坏的数据的场合。
在这里,需要注意的是,读只能在一块磁盘上进行,并不会进行并行读取,性能取决于硬盘中较快的一块。写的话通常比单块磁盘要慢,虽然是并行写,即对两块磁盘的写入是同时进行的,但因为要比较两块硬盘中的数据,所以性能比单块磁盘慢。
优缺点:
RAID1通过硬盘数据镜像实现数据的冗余,保护数据安全,在两块盘上产生互为备份的数据,当原始数据繁忙时,可直接从镜像备份中读取数据,因此RAID1可以提供读取性能。RAID1是硬盘中单位成本最高的,但提供了很高的数据安全性和可用性,当一个硬盘失效时,系统可以自动切换到镜像硬盘上读/写,并且不需要重组失效的数据。
总结:
磁盘空间使用率:50%,故成本最高。
读性能:只能在一个磁盘上读取,取决于磁盘中较快的那块盘
写性能:两块磁盘都要写入,虽然是并行写入,但因为要比对,故性能单块磁盘慢。
冗余:只要系统中任何一对镜像盘中有一块磁盘可以使用,甚至可以在一半数量的硬盘出现问题时系统都可以正常运行。
RAID 5
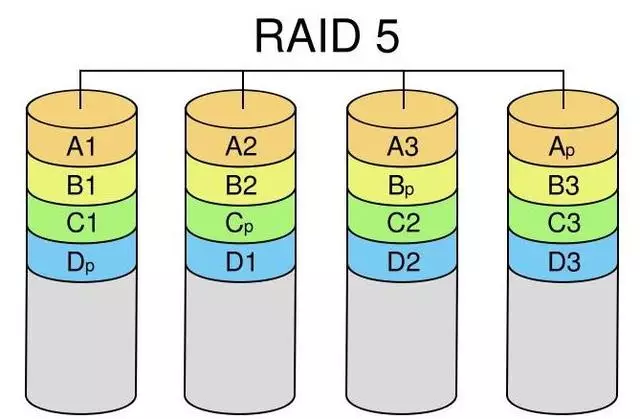
定义:
RAID 5是RAID 0和RAID 1的折中方案。RAID 5具有和RAID0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID5的磁盘空间利用率要比RAID 1高,存储成本相对较低,是目前运用较多的一种解决方案。
工作原理:
RAID5把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上,其中任意N-1块磁盘上都存储完整的数据,也就是说有相当于一块磁盘容量的空间用于存储奇偶校验信息。因此当RAID5的一个磁盘发生损坏后,不会影响数据的完整性,从而保证了数据安全。当损坏的磁盘被替换后,RAID还会自动利用剩下奇偶校验信息去重建此磁盘上的数据,来保持RAID5的高可靠性。
做raid 5阵列所有磁盘容量必须一样大,当容量不同时,会以最小的容量为准。 最好硬盘转速一样,否则会影响性能,而且可用空间=磁盘数n-1,Raid 5 没有独立的奇偶校验盘,所有校验信息分散放在所有磁盘上, 只占用一个磁盘的容量。
总结:
磁盘空间利用率:(N-1)/N,即只浪费一块磁盘用于奇偶校验。
读性能:(n-1)*单块磁盘的读性能,接近RAID0的读性能。
写性能:比单块磁盘的写性能要差(这点不是很明白,不是可以并行写入么?)
冗余:只允许一块磁盘损坏。
RAID10

定义:
RAID10也被称为镜象阵列条带。象RAID0一样,数据跨磁盘抽取;象RAID1一样,每个磁盘都有一个镜象磁盘, 所以RAID 10的另一种会说法是 RAID 0+1。RAID10提供100%的数据冗余,支持更大的卷尺寸,但价格也相对较高。对大多数只要求具有冗余度而不必考虑价格的应用来说,RAID10提供最好的性能。使用RAID10,可以获得更好的可靠性,因为即使两个物理驱动器发生故障(每个阵列中一个),数据仍然可以得到保护。RAID10需要4 + 2*N 个磁盘驱动器(N >=0), 而且只能使用其中一半(或更小, 如果磁盘大小不一)的磁盘用量, 例如 4 个 250G 的硬盘使用RAID10 阵列, 实际容量是 500G。
实现原理:
Raid10其实结构非常简单,首先创建2个独立的Raid1,然后将这两个独立的Raid1组成一个Raid0,当往这个逻辑Raid中写数据时,数据被有序的写入两个Raid1中。磁盘1和磁盘2组成一个Raid1,磁盘3和磁盘4又组成另外一个Raid1;这两个Raid1组成了一个新的Raid0。如写在硬盘1上的数据1、3、5、7,写在硬盘2中则为数据1、3、5、7,硬盘中的数据为0、2、4、6,硬盘4中的数据则为0、2、4、6,因此数据在这四个硬盘上组合成Raid10,且具有raid0和raid1两者的特性。
虽然Raid10方案造成了50%的磁盘浪费,但是它提供了200%的速度和单磁盘损坏的数据安全性,并且当同时损坏的磁盘不在同一Raid1中,就能保证数据安全性。假如磁盘中的某一块盘坏了,整个逻辑磁盘仍能正常工作的。
当我们需要恢复RAID10中损坏的磁盘时,只需要更换新的硬盘,按照RAID10的工作原理来进行数据恢复,恢复数据过程中系统仍能正常工作。原先的数据会同步恢复到更换的硬盘中。
总结:
磁盘空间利用率:50%。
读性能:N/2*单块硬盘的读性能
写性能:N/2*单块硬盘的写性能
冗余:只要一对镜像盘中有一块磁盘可以使用就没问题。
MySQL数据库Raid存储方案
作为一名DBA,选择自己的数据存储在什么上面,应该是最基本的事情了。但是很多DBA却容易忽略了这一点,我就是其中一个。之前对raid了解的并不多,本文就记录下学习的raid相关知识。
一、RAID的基础知识
【定义】RAID(Redundant Array of Independent Disk)是一种独立冗余磁盘阵列。
1、为什么要使用RAID?
我们知道,单块磁盘无论是从性能上、容量上、还是安全上都存在单点问题,如果把多块硬盘组成一个group,当成一个逻辑驱动器,从而实现同时从多块硬盘存取数据,那样可以提高了存储的吞吐量,同时也提高了存取速度和扩大存储容量。
RAID(Redundant Array of Independent Disk 独立冗余磁盘阵列)技术就是专门干这事的。RAID就是一种由多块廉价磁盘构成的冗余阵列,在操作系统下是作为一个独立的大型存储设备出现。RAID可以充分发挥出多块硬盘的优势,可以提升硬盘速度,增大容量,提供容错功能够确保数据安全性,易于管理的优点,在任何一块硬盘出现问题的情况下都可以继续工作,不会受到损坏硬盘的影响,这对于数据库存储领域是非常必要的。
2、RAID的几种工作级别
我们比较常用的RAID级别有RAID-0、RAID-1、RAID-10/RAID-01、RAID-5,其他的如RAID-3、RAID-4、RAID-6就不在此介绍了。
- RAID-0
RAID-0采用数据分条技术(Striped)把多块磁盘串联成一个更为庞大的磁盘组,可以提高磁盘的性能和吞吐量。它读写数据的速度是最快的,要求比较低,要求两个磁盘即可做RAID-0,相对成本是最低的,但是RAID-0不提供冗余或奇偶校验数据的功能,如果驱动器出现故障,数据将无法恢复,安全性最弱。一般只是在那些对性能要求高、数据安全性要求不高的情况下才被使用,不适合数据库的存储。

- RAID-1
RAID-1采用镜像(Mirroring)的方式冗余数据。RAID-1要求至少两个或2xN个磁盘,每次写数据时会同时写入镜像盘。这种阵列可靠性很高,但其有效容量减小到总容量的一半,同时这些磁盘的大小应该相等,否则总容量只具有最小磁盘的大小。RAID-1的数据安全性在所有的RAID级别上来说是最好的。但是其磁盘的利用率却只有50%,是所有RAID级别中最低的。

- RAID-10
由于RAID-0和RAID-1都存在明显的优点和缺点,为了结合两者的优点、避免两者的缺点,从而产生了RAID-10,RAID-10适合用在速度需求高,又要完全容错,当然成本也很多的应用。不过在做RAID-10时需要注意的是先做RAID-1,再做RAID-0还是先做RAID-0,再做RAID-1,二者还是有区别的。举个栗子,假如现在有四块磁盘:
先做RAID-0,再做RAID-1:每两块磁盘先做RAID-0,在此基础上,再把两个RAID-0做成RAID-1。这时如果A类或者B类磁盘同时有一个故障,整个RAID将不可用。
(RAID 0) A = (Drive A1 + Drive A2) (Striped) (RAID 0) B = (Drive B1 + Drive B2) (Striped) (RAID-1)AB = (A + B) (Mirrored)
先做RAID-1,再做RAID-0:每两块磁盘先做RAID-1,在此基础上,再把两个RAID-1做成RAID-0。这时只有A类或者B类磁盘两个都故障时,整个RAID才不可用。
(RAID-1) A = (Drive A1 + Drive A2) (Mirrored) (RAID-1) B = (Drive B1 + Drive B2) (Mirrored) (RAID-0)AB = (A + B) (Striped)
综合上面来看,先做RAID-1,再做RAID-0相对更安全,建议这种方式,所以我们平时说的RAID-10就是先做RAID-1,再做RAID-0。
- RAID-5
RAID-5应该处于RAID-0和RAID-1之间的一种工作模式,它尽量平衡RAID-0和RAID-1的优点和缺点,是我们平时使用比较多的一种模式。做RAID-5至少需要三块磁盘,它采用校验码冗余数据,校验信息分布在多个磁盘上,当数据每次写入到磁盘上,同时还需要写入校验信息,因此写入性能相对不如RAID-0。当某个磁盘出现故障,可以使用其他磁盘上校验信息来恢复数据。相对RAID-1,它磁盘空间利用率为(N-1)/N
3、RAID的几种工作级别优缺点

【注】以上的高、中、低只是相对于RAID-0、RAID-1、RAID-10、RAID-5而言。
二、如何判断RAID级别、写入策略、电池状况
1、判断RAID级别:MegaCli64工具输入磁盘信息如下:

[root()@xxxx ~]# MegaCli64 -LdInfo -lAll -aALL Adapter 0 -- Virtual Drive Information: Virtual Drive: 0 (Target Id: 0) Name : RAID Level : Primary-1, Secondary-0, RAID Level Qualifier-0 Size : 278.875 GB Is VD emulated : No Mirror Data : 278.875 GB State : Optimal Strip Size : 64 KB Number Of Drives : 2 Span Depth : 1 Default Cache Policy: WriteBack, ReadAhead, Direct, No Write Cache if Bad BBU Current Cache Policy: WriteBack, ReadAhead, Direct, No Write Cache if Bad BBU Default Access Policy: Read/Write Current Access Policy: Read/Write Disk Cache Policy : Disabled Encryption Type : None Default Power Savings Policy: Controller Defined Current Power Savings Policy: None Can spin up in 1 minute: Yes LD has drives that support T10 power conditions: Yes LD's IO profile supports MAX power savings with cached writes: No Bad Blocks Exist: No PI type: No PI Is VD Cached: No Virtual Drive: 1 (Target Id: 1) Name : RAID Level : Primary-1, Secondary-0, RAID Level Qualifier-0 Size : 2.180 TB Is VD emulated : Yes Mirror Data : 2.180 TB State : Optimal Strip Size : 64 KB Number Of Drives per span : 2 Span Depth : 3 Default Cache Policy: WriteBack, ReadAhead, Direct, No Write Cache if Bad BBU Current Cache Policy: WriteBack, ReadAhead, Direct, No Write Cache if Bad BBU Default Access Policy: Read/Write Current Access Policy: Read/Write Disk Cache Policy : Disabled Encryption Type : None Default Power Savings Policy: Controller Defined Current Power Savings Policy: None Can spin up in 1 minute: No LD has drives that support T10 power conditions: No LD's IO profile supports MAX power savings with cached writes: No Bad Blocks Exist: No PI type: No PI Is VD Cached: No
网上有人仅仅通过RAID Level列中的Primary-1, Secondary-0, RAID Level Qualifier-0来判断,我认为不是很准确。先来了解下Primary、Secondary、RAID Level Qualifier啥意思?
Primary字段:基本上可以确定RAID的级别,但是无法区分是RAID-1和RAID-10,因为有情况下他们的Primary值都是Primary-1, Secondary-0, RAID Level Qualifier-0
在这种情况下如何区分RAID-1和RAID-10?我认为还得结合另外两列进行判断:
Number Of Drives per span : 2 #每个区段有2块磁盘 Span Depth : 3 #一共三个区段 结合primary-1,该RAID表示一共六块磁盘,每两个做RAID-1,最后将三个RAID-1做RAID-0
【总结:如何判断RAID级别】:
1) 除了RAID-1和RAID-10,其他级别通过Primary字段值就可以判断;
2) 至于RAID-1和RAID-10,还需要结合Number Of Drives (per span)、Span Depth两列的值,如果Span Depth值为1表示为RAID-1,不为1表示RAID-10;还有一种情况:Primary-1, Secondary-3, RAID Level Qualifier-0也是表示RAID-10;
2、判断RAID写入策略和电池状态
RAID的写入策略对IO性能有很大影响,有两种写入策略:
WriteBack:表示写入到磁盘缓存上,写入性能好,如果采用此策略,RAID必须支持电池可用,否则一旦断点,数据将丢失。
WriteThrough:表示直接写入到硬盘上,写入性能没有WriteBack好,一般没有电池时采用此策略
2.1)查看RAID的写入策略
[root()@xxxx ~]# MegaCli64 -LDInfo -Lall -aALL|grep 'Cache Policy' ********************************************************************************** Default Cache Policy: WriteBack, ReadAdaptive, Direct, Write Cache OK if Bad BBU Current Cache Policy: WriteBack, ReadAdaptive, Direct, Write Cache OK if Bad BBU 以上表示采用WriteBack(回写)策略,如果电池坏了也强制写入cache
Default Cache Policy: WriteThrough, ReadAheadNone, Direct, No Write Cache if Bad BBU
Current Cache Policy: WriteThrough, ReadAheadNone, Direct, No Write Cache if Bad BBU
如果是这个,表示采用WriteThrough策略
**********************************************************************************
Disk Cache Policy : Disabled #表示硬盘的cache,一般这里禁用,防止丢失数据
2.2)查看电池状态
[root()@xxxx ~]# MegaCli64 -adpbbucmd -aall |grep -E 'Battery State|Charger Status|isSOHGood|Relative State of Charge' Battery State : Operational #电池状态,operational表示正在运行 Relative State of Charge: 98 % #电池电量,如果低于15%,那么写入策略会由WB转变为WC,IO性能下降,需要关注 Charger Status: Complete #充电情况,表示已完成 isSOHGood: Yes #不是Yes需要关注
三、MySQL适合的RAID存储方案
通过上面对RAID的了解,我们已经知道各级别RAID的优缺点,对于MySQL数据库的存储,如何选择RAID级别呢?
我们可以根据MySQL各种文件类型分别选择,MySQL数据库重要的文件类型有:
1、数据文件(frm,ibd):存储核心的数据,非常重要,安全性要求高,同时需要频繁的写入、更新数据,磁盘性能要求也比较高,首先建议物理磁盘是SSD,对于RAID的选择,如果预算足够,建议RAID-10,其次是RAID-5 2、二进制日志文件:写入非常频繁,写性能要求高,由于从库依赖该文件,安全性也很重要,综合成本考虑,可以用两块SATA硬盘,做成RAID-1即可。 3、redo文件,共享表空间文件:安全性要求高,如果预算足够,RAID-10,通常RAID-1也是可以的,一般而言,redo文件和共享表空间和数据文件存储在一起即可。
参考文章:
http://www.chinastor.com/a/jishu/raid/yes.html
http://blog.csdn.net/haiross/article/details/38557373
http://ju.outofmemory.cn/entry/92025
一张“神图”看懂单机/集群/热备/磁盘阵列(RAID)

单机部署(stand-alone):只有一个饮水机提供服务,服务只部署一份
集群部署(cluster):有多个饮水机同时提供服务,服务冗余部署,每个冗余的服务都对外提供服务,一个服务挂掉时依然可用
热备部署(hot-swap):只有一个桶提供服务,另一个桶stand-by,在水用完时自动热替换,服务冗余部署,只有一个主服务对外提供服务,影子服务在主服务挂掉时顶上
磁盘阵列RAID(Redundant Arrays of independent Disks)

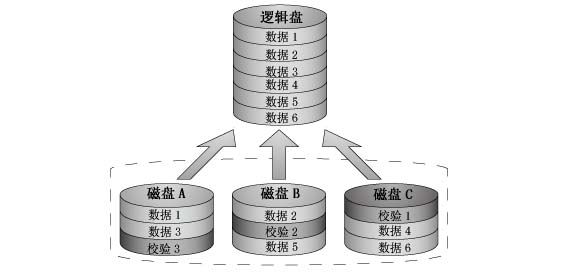
RAID0:存储性能高的磁盘阵列,又称striping,它的原理是,将连续的数据分散到不同的磁盘上存储,这些不同的磁盘能同时并行存取数据(速度块)

RAID1:安全性高的磁盘阵列,又称mirror,它的原理是,将数据完全复制到另一个磁盘上,磁盘空间利用率只有50%(冗余,数据安全)
RAID0+1:RAID0和RAID1的综合方案,这也是国企用的比较多的存储方案(速度快,安全性又高,但是很贵)

RAID5:RAID0和RAID1的折衷方案,读取速度比较快(不如RAID0,因为多存储了校验位),安全性也很高(可以利用校验位恢复数据),空间利用率也不错(不完全复制,只冗余校验位),这也是互联网公司用的比较多的存储方案
About Me
...............................................................................................................................
● 本文整理自网络
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-07-01 09:00 ~ 2017-07-31 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。





来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26736162/viewspace-2142521/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/26736162/viewspace-2142521/