在《第一篇|Spark概览》一文中,对Spark的整体面貌进行了阐述。本文将深入探究Spark的核心组件--Spark core,Spark Core是Spark平台的基础通用执行引擎,所有其他功能均建立在该引擎之上。它不仅提供了内存计算功能来提高速度,而且还提供了通用的执行模型以支持各种应用程序,另外,用户可以使用Java,Scala和Python API开发应用程序。Spark core是建立在统一的抽象RDD之上的,这使得Spark的各个组件可以随意集成,可以在同一个应用程序中使用不同的组件以完成复杂的大数据处理任务。本文主要讨论的内容有:
什么是RDD
- RDD的设计初衷
- RDD的基本概念与主要特点
- 宽依赖与窄依赖
- stage划分与作业调度
RDD操作算子
- Transformations
- Actions
共享变量
- 广播变量
- 累加器
- 持久化
- 综合案例
什么是RDD
设计初衷
RDD(Resilient Distributed Datasets)的设计之初是为了解决目前存在的一些计算框架对于两类应用场景的处理效率不高的问题,这两类应用场景是迭代式算法和交互式数据挖掘。在这两种应用场景中,通过将数据保存在内存中,可以将性能提高到几个数量级。对于迭代式算法而言,比如PageRank、K-means聚类、逻辑回归等,经常需要重用中间结果。另一种应用场景是交互式数据挖掘,比如在同一份数据集上运行多个即席查询。大部分的计算框架(比如Hadoop),使用中间计算结果的方式是将其写入到一个外部存储设备(比如HDFS),这会增加额外的负载(数据复制、磁盘IO和序列化),由此会增加应用的执行时间。
RDD可以有效地支持多数应用中的数据重用,它是一种容错的、并行的数据结构,可以让用户显性地将中间结果持久化到内存中,并且可以通过分区来优化数据的存放,另外,RDD支持丰富的算子操作,用户可以很容易地使用这些算子对RDD进行操作。
基本概念
一个RDD是一个分布式对象集合,其本质是一个只读的、分区的记录集合。每个RDD可以分成多个分区,不同的分区保存在不同的集群节点上(具体如下图所示)。RDD是一种高度受限的共享内存模型,即RDD是只读的分区记录集合,所以也就不能对其进行修改。只能通过两种方式创建RDD,一种是基于物理存储的数据创建RDD,另一种是通过在其他RDD上作用转换操作(transformation,比如map、filter、join等)得到新的RDD。
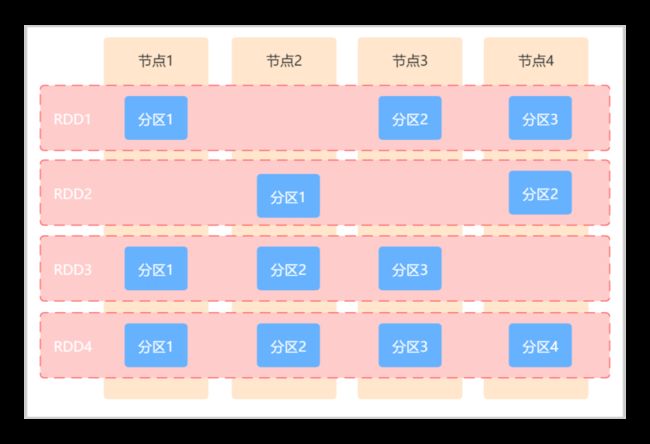
RDD不需要被物化,它通过血缘关系(lineage)来确定其是从RDD计算得来的。另外,用户可以控制RDD的持久化和分区,用户可以将需要被重用的RDD进行持久化操作(比如内存、或者磁盘)以提高计算效率。也可以按照记录的key将RDD的元素分布在不同的机器上,比如在对两个数据集进行JOIN操作时,可以确保以相同的方式进行hash分区。
主要特点
- 基于内存
RDD是位于内存中的对象集合。RDD可以存储在内存、磁盘或者内存加磁盘中,但是,Spark之所以速度快,是基于这样一个事实:数据存储在内存中,并且每个算子不会从磁盘上提取数据。
- 分区
分区是对逻辑数据集划分成不同的独立部分,分区是分布式系统性能优化的一种技术手段,可以减少网络流量传输,将相同的key的元素分布在相同的分区中可以减少shuffle带来的影响。RDD被分成了多个分区,这些分区分布在集群中的不同节点。
- 强类型
RDD中的数据是强类型的,当创建RDD的时候,所有的元素都是相同的类型,该类型依赖于数据集的数据类型。
- 懒加载
Spark的转换操作是懒加载模式,这就意味着只有在执行了action(比如count、collect等)操作之后,才会去执行一些列的算子操作。
- 不可修改
RDD一旦被创建,就不能被修改。只能从一个RDD转换成另外一个RDD。
- 并行化
RDD是可以被并行操作的,由于RDD是分区的,每个分区分布在不同的机器上,所以每个分区可以被并行操作。
- 持久化
由于RDD是懒加载的,只有action操作才会导致RDD的转换操作被执行,进而创建出相对应的RDD。对于一些被重复使用的RDD,可以对其进行持久化操作(比如将其保存在内存或磁盘中,Spark支持多种持久化策略),从而提高计算效率。
宽依赖和窄依赖
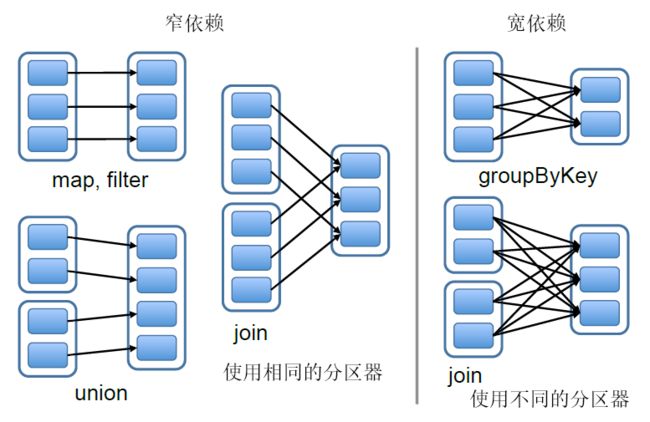
RDD中不同的操作会使得不同RDD中的分区产不同的依赖,主要有两种依赖:宽依赖和窄依赖。宽依赖是指一个父RDD的一个分区对应一个子RDD的多个分区,窄依赖是指一个父RDD的分区对应与一个子RDD的分区,或者多个父RDD的分区对应一个子RDD分区。关于宽依赖与窄依赖,如下图所示:
Stage划分
窄依赖会被划分到同一个stage中,这样可以以管道的形式迭代执行。宽依赖所依赖的分区一般有多个,所以需要跨节点传输数据。从容灾方面看,两种依赖的计算结果恢复的方式是不同的,窄依赖只需要恢复父RDD丢失的分区即可,而宽依赖则需要考虑恢复所有父RDD丢失的分区。
DAGScheduler会将Job的RDD划分到不同的stage中,并构建一个stage的依赖关系,即DAG。这样划分的目的是既可以保障没有依赖关系的stage可以并行执行,又可以保证存在依赖关系的stage顺序执行。stage主要分为两种类型,一种是ShuffleMapStage,另一种是ResultStage。其中ShuffleMapStage是属于上游的stage,而ResulStage属于最下游的stage,这意味着上游的stage先执行,最后执行ResultStage。
- ShuffleMapStage
ShuffleMapStage是DAG调度流程的中间stage,它可以包含一个或者多个ShuffleMapTask,用与生成Shuffle的数据,ShuffleMapStage可以是ShuffleMapStage的前置stage,但一定是ResultStage的前置stage。部分源码如下:
private[spark] class ShuffleMapStage(
id: Int,
rdd: RDD[_],
numTasks: Int,
parents: List[Stage],
firstJobId: Int,
callSite: CallSite,
val shuffleDep: ShuffleDependency[_, _, _],
mapOutputTrackerMaster: MapOutputTrackerMaster)
extends Stage(id, rdd, numTasks, parents, firstJobId, callSite) {
// 省略代码
}
}- ResultStage
ResultStage可以使用指定的函数对RDD中的分区进行计算并得到最终结果,ResultStage是最后执行的stage,比如打印数据到控制台,或者将数据写入到外部存储设备等。部分源码如下:
private[spark] class ResultStage(
id: Int,
rdd: RDD[_],
val func: (TaskContext, Iterator[_]) => _,
val partitions: Array[Int],
parents: List[Stage],
firstJobId: Int,
callSite: CallSite)
extends Stage(id, rdd, partitions.length, parents, firstJobId, callSite) {
// 省略代码
}
上面提到Spark通过分析各个RDD的依赖关系生成DAG,通过各个RDD中的分区之间的依赖关系来决定如何划分stage。具体的思路是:在DAG中进行反向解析,遇到宽依赖就断开、遇到窄依赖就把当前的RDD加入到当前的stage中。即将窄依赖划分到同一个stage中,从而形成一个pipeline,提升计算效率。所以一个DAG图可以划分为多个stage,每个stage都代表了一组关联的,相互之间没有shuffle依赖关系的任务组成的task集合,每个task集合会被提交到TaskScheduler进行调度处理,最终将任务分发到Executor中进行执行。
Spark作业调度流程
Spark首先会对Job进行一系列的RDD转换操作,并通过RDD之间的依赖关系构建DAG(Direct Acyclic Graph,有向无环图)。然后根据RDD依赖关系将RDD划分到不同的stage中,每个stage按照partition的数量创建多个Task,最后将这些Task提交到集群的work节点上执行。具体流程如下图所示:

- 1.构建DAG,将DAG提交到调度系统;
- 2.DAGScheduler负责接收DAG,并将DAG划分成多个stage,最后将每个stage中的Task以任务集合(TaskSet)的形式提交个TaskScheduler做下一步处理;
- 3.使用集群管理器分配资源与任务调度,对于失败的任务会有相应的重试机制。TaskScheduler负责从DAGScheduler接收TaskSet,然后会创建TaskSetManager对TaskSet进行管理,最后由SchedulerBackend对Task进行调度;
- 4.执行具体的任务,并将任务的中间结果和最终结果存入存储体系。
RDD操作算子
Spark提供了丰富的RDD操作算子,主要包括两大类:Transformation与Action,下面会对一些常见的算子进行说明。
Transformation
下面是一些常见的transformation操作,值得注意的是,对于普通的RDD,支持Scala、Java、Python和R的API,对于pairRDD,仅支持Scala和JavaAPI。下面将对一些常见的算子进行解释:
- map(func)
/**
* 将每个元素传递到func函数中,并返回一个新的RDD
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}- filter(func)
/**
* 筛选出满足func函数的元素,并返回一个新的RDD
*/
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}- flatMap(func)
/**
* 首先对该RDD所有元素应用func函数,然后将结果打平,一个元素会映射到0或者多个元素,返回一个新RDD
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}- mapPartitions(func)
/**
* 将func作用于该RDD的每个分区,返回一个新的RDD
*/
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}- union(otherDataset)
/**
* 返回一个新的RDD,包含两个RDD的元素,类似于SQL的UNION ALL
*/
def union(other: RDD[T]): RDD[T] = withScope {
sc.union(this, other)
}- intersection(otherDataset)
/**
* 返回一个新的RDD,包含两个RDD的交集
*/
def intersection(other: RDD[T]): RDD[T] = withScope {
this.map(v => (v, null)).cogroup(other.map(v => (v, null)))
.filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }
.keys
}- distinct([numPartitions]))
/**
* 返回一个新的RDD,对原RDD元素去重
*/
def distinct(): RDD[T] = withScope {
distinct(partitions.length)
}
- groupByKey([numPartitions])
/**
* 将pairRDD按照key进行分组,该算子的性能开销较大,可以使用PairRDDFunctions.aggregateByKey
*或者PairRDDFunctions.reduceByKey进行代替
*/
def groupByKey(): RDD[(K, Iterable[V])] = self.withScope {
groupByKey(defaultPartitioner(self))
}
- reduceByKey(func, [numPartitions])
/**
* 使用reduce函数对每个key对应的值进行聚合,该算子会在本地先对每个mapper结果进行合并,然后再将结果发送到reducer,类似于MapReduce的combiner功能
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
- aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions])
/**
* 使用给定的聚合函数和初始值对每个key对应的value值进行聚合
*/
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {
aggregateByKey(zeroValue, defaultPartitioner(self))(seqOp, combOp)
}
- sortByKey([ascending], [numPartitions])
/**
* 按照key对RDD进行排序,所以每个分区的元素都是排序的
*/
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)] = self.withScope
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
- join(otherDataset, [numPartitions])
/**
* 将相同key的pairRDD JOIN在一起,返回(k, (v1, v2))tuple类型
*/
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))] = self.withScope {
join(other, defaultPartitioner(self, other))
}
- cogroup(otherDataset, [numPartitions])
/**
* 将相同key的元素放在一组,返回的RDD类型为(K, (Iterable[V], Iterable[W1], Iterable[W2])
* 第一个Iterable里面包含当前RDD的key对应的value值,第二个Iterable里面包含W1 RDD的key对应的 * value值,第三个Iterable里面包含W2 RDD的key对应的value值
*/
def cogroup[W1, W2](other1: RDD[(K, W1)], other2: RDD[(K, W2)], numPartitions: Int)
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2]))] = self.withScope {
cogroup(other1, other2, new HashPartitioner(numPartitions))
}
- coalesce(numPartitions)
/**
* 该函数用于将RDD进行重分区,使用HashPartitioner。第一个参数为重分区的数目,第二个为是否进行 * shuffle,默认为false;
*/
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = new Random(hashing.byteswap32(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition),
new HashPartitioner(numPartitions)),
numPartitions,
partitionCoalescer).values
} else {
new CoalescedRDD(this, numPartitions, partitionCoalescer)
}
}
- repartition(numPartitions)
/**
* 可以增加或者减少分区,底层调用的是coalesce方法。如果要减少分区,建议使用coalesce,因为可以避 * 免shuffle
*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
Action
一些常见的action算子如下表所示
| 操作 | 含义 |
|---|---|
| count() | 返回数据集中的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 以数组的形式返回数据集中的前n个元素 |
| reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 |
| foreach(func) | 将数据集中的每个元素传递到函数func中运行 |
共享变量
Spark提供了两种类型的共享变量:广播变量和累加器。广播变量(Broadcast variables)是一个只读的变量,并且在每个节点都保存一份副本,而不需要在集群中发送数据。累加器(Accumulators)可以将所有任务的数据累加到一个共享结果中。
广播变量
广播变量允许用户在集群中共享一个不可变的值,该共享的、不可变的值被持计划到集群的每台节点上。通常在需要将一份小数据集(比如维表)复制到集群中的每台节点时使用,比如日志分析的应用,web日志通常只包含pageId,而每个page的标题保存在一张表中,如果要分析日志(比如哪些page被访问的最多),则需要将两者join在一起,这时就可以使用广播变量,将该表广播到集群的每个节点。具体如下图所示:
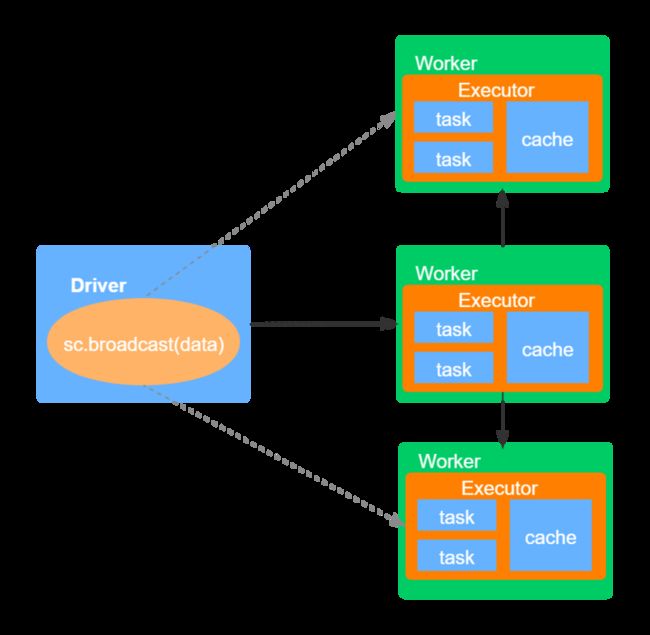
如上图,首先Driver将序列化对象分割成小的数据库,然后将这些数据块存储在Driver节点的BlockManager上。当ececutor中执行具体的task时,每个executor首先尝试从自己所在节点的BlockManager提取数据,如果之前已经提取的该广播变量的值,就直接使用它。如果没有找到,则会向远程的Driver或者其他的Executor中提取广播变量的值,一旦获取该值,就将其存储在自己节点的BlockManager中。这种机制可以避免Driver端向多个executor发送数据而造成的性能瓶颈。
基本使用方式如下:
// 模拟一个数据集合
scala> val mockCollection = "Spark Flink Hadoop Hive".split(" ")
mockCollection: Array[String] = Array(Spark, Flink, Hadoop, Hive)
// 构造RDD
scala> val words = sc.parallelize(mockCollection,2)
words: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[7] at parallelize at :29
// 模拟广播变量数据
scala> val mapData = Map("Spark" -> 10, "Flink" -> 20,"Hadoop" -> 15, "Hive" -> 9)
mapData: scala.collection.immutable.Map[String,Int] = Map(Spark -> 10, Flink -> 20, Hadoop -> 15, Hive -> 9)
// 创建一个广播变量
scala> val broadCast = sc.broadcast(mapData)
broadCast: org.apache.spark.broadcast.Broadcast[scala.collection.immutable.Map[String,Int]] = Broadcast(4)
// 在算子内部使用广播变量,根据key取出value值,按value升序排列
scala> words.map(word => (word,broadCast.value.getOrElse(word,0))).sortBy(wordPair => wordPair._2).collect
res5: Array[(String, Int)] = Array((Hive,9), (Spark,10), (Hadoop,15), (Flink,20))
累加器
累加器(Accumulator)是Spark提供的另外一个共享变量,与广播变量不同,累加器是可以被修改的,是可变的。每个transformation会将修改的累加器值传输到Driver节点,累加器可以实现一个累加的功能,类似于一个计数器。Spark本身支持数字类型的累加器,用户也可以自定义累加器的类型。

基本使用
可以通过sparkContext.longAccumulator() 或者SparkContext.doubleAccumulator()分别创建Long和Double类型的累加器。运行在集群中的task可以调用add方法对该累加器变量进行累加,但是不能够读取累加器的值,只有Driver程序可以通过调用value方法读取累加器的值。
object SparkAccumulator {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(SparkShareVariable.getClass.getSimpleName)
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
val list = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13)
val listRDD = sc.parallelize(list)
var counter = 0 //外部变量
//初始化一个accumulator,初始值默认为0
val countAcc = sc.longAccumulator("my accumulator")
val mapRDD = listRDD.map(num => {
counter += 1 //在算子内部使用了外部变量,这样操作不会改变外部变量的值
if (num % 3 == 0) {
//遇到3的倍数,累加器+1
countAcc.add(1)
}
num * 2
})
mapRDD.foreach(println)
println("counter = " + counter) // counter = 0
println("countAcc = " + countAcc.value) // countAcc = 4
sc.stop()
}
}
尖叫提示:我们在dirver中声明的一些局部变量或者成员变量,可以直接在transformation中使用,但是经过transformation操作之后,是不会将最终的结果重新赋值给dirver中的对应的变量。因为通过action触发transformation操作之后,transformation的操作都是通过DAGScheduler将代码打包,然后序列化,最后交由TaskScheduler传送到各个Worker节点中的Executor去执行,在transformation中执行的这些变量,是自己节点上的变量,不是dirver上最初的变量,只不过是将driver上的对应的变量拷贝了一份而已。
自定义累加器
Spark提供了一些默认类型的累加器,同时也支持自定义累加器。通过继承AccumulatorV2类即可实现自定义累加器,具体代码如下:
class customAccumulator extends AccumulatorV2[BigInt, BigInt]{
private var num:BigInt = 0
/**
* 返回该accumulator是否为0值,比如一个计数器,0代表zero,如果是一个list,Nil代表zero
*/
def isZero: Boolean = {
this.num == 0
}
// 创建一个该accumulator副本
def copy(): AccumulatorV2[BigInt, BigInt] = {
new customAccumulator
}
/**
* 重置accumulator的值, 该值为0,调用 `isZero` 必须返回true
*/
def reset(): Unit = {
this.num = 0
}
// 根据输入的值,进行累加,
// 判断为偶数时,累加器加上该值
def add(intVal: BigInt): Unit = {
if(intVal % 2 == 0){
this.num += intVal
}
}
/**
* 合并其他的同一类型的accumulator,并更新该accumulator值
*/
def merge(other: AccumulatorV2[BigInt, BigInt]): Unit = {
this.num += other.value
}
/**
* 定义当前accumulator的值
*/
def value: BigInt = {
this.num
}
}
使用该自定义累加器
val acc = new customAccumulator
val newAcc = sc.register(acc, "evenAcc")
println(acc.value)
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => acc.add(x))
println(acc.value)
持久化
持久化方法
在Spark中,RDD采用惰性求值的机制,每次遇到action操作,都会从头开始执行计算。每次调用action操作,都会触发一次从头开始的计算。对于需要被重复使用的RDD,spark支持对其进行持久化,通过调用persist()或者cache()方法即可实现RDD的持计划。通过持久化机制可以避免重复计算带来的开销。值得注意的是,当调用持久化的方法时,只是对该RDD标记为了持久化,需要等到第一次执行action操作之后,才会把计算结果进行持久化。持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。
Spark提供的两个持久化方法的主要区别是:cache()方法默认使用的是内存级别,其底层调用的是persist()方法,具体源码片段如下:
def persist(newLevel: StorageLevel): this.type = {
if (isLocallyCheckpointed) {
persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true)
} else {
persist(newLevel, allowOverride = false)
}
}
/**
* 使用默认的存储级别持久化RDD (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* 使用默认的存储级别持久化RDD (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
/**
* 手动地把持久化的RDD从缓存中移除
*/
def unpersist(blocking: Boolean = true): this.type = {
logInfo("Removing RDD " + id + " from persistence list")
sc.unpersistRDD(id, blocking)
storageLevel = StorageLevel.NONE
this
}
持计划存储级别
Spark的提供了多种持久化级别,比如内存、磁盘、内存+磁盘等。具体如下表所示:
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | 默认,表示将RDD作为反序列化的Java对象存储于JVM中,如果内存不够用,则部分分区不会被持久化,等到使用到这些分区时,会重新计算。 |
| MEMORY_AND_DISK | 将RDD作为反序列化的Java对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上. |
| MEMORY_ONLY_SER (Java and Scala) | 将RDD序列化为Java对象进行持久化,每个分区对应一个字节数组。此方式比反序列化要节省空间,但是会占用更多cpu资源 |
| MEMORY_AND_DISK_SER (Java and Scala) | 与 MEMORY_ONLY_SER, 如果内存放不下,则溢写到磁盘。 |
| DISK_ONLY | 将RDD的分区数据存储到磁盘 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 与上面的方式类似,但是会将分区数据复制到两个集群 |
| OFF_HEAP (experimental) | 与MEMORY_ONLY_SER类似,将数据存储到堆外内存 off-heap,需要将off-heap 开启 |
持久化级别的选择
Spark提供的持久化存储级别是在内存使用与CPU效率之间做权衡,通常推荐下面的选择方式:
- 如果内存可以容纳RDD,可以使用默认的持久化级别,即MEMORY_ONLY。这是CPU最有效率的选择,可以使作用在RDD上的算子尽可能第快速执行。
如果内存不够用,可以尝试使用MEMORY_ONLY_SER,使用一个快速的序列化库可以节省很多空间,比如 Kryo 。
tips:在一些shuffle算子中,比如reduceByKey,即便没有显性调用persist方法,Spark也会自动将中间结果进行持久化,这样做的目的是避免在shuffle期间发生故障而造成重新计算整个输入。即便如此,还是推荐对需要被重复使用的RDD进行持久化处理。
综合案例
- case 1
/**
* 1.数据集
* [orderId,userId,payment,productId]
* 1,108,280,1002
* 2,202,300,2004
* 3,210,588,3241
* 4,198,5000,3567
* 5,200,590,2973
* 6,678,8000,18378
* 7,243,200,2819
* 8,236,7890,2819
* 2.需求描述
* 计算Top3订单金额
*
* 3.结果输出
* 1 8000
* 2 7890
* 3 5000
*/
object TopOrder {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TopN").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val lines = sc.textFile("E://order.txt")
var num = 0;
val result = lines.filter(line => (line.trim().length > 0) && (line.split(",").length == 4))
.map(_.split(",")(2)) // 取出支付金额
.map(x => (x.toInt,""))
.sortByKey(false) // 按照支付金额降序排列
.map(x => x._1).take(3) // 取出前3个
.foreach(x => {
num = num + 1
println(num + "\t" + x)
})
}
}
- case 2
/**
* 1.数据集(movielensSet)
* 用户电影评分数据[UserID::MovieID::Rating::Timestamp]
* 电影名称数据[MovieId::MovieName::MovieType]
* 2.需求描述
* 求平均评分大于5的电影名称
*
*/
object MovieRating {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("MovieRating").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
// 用户电影评分数据[UserID::MovieID::Rating::Timestamp]
val userRating = sc.textFile("E://ml-1m/ratings.dat")
// 电影名称数据[MovieId::MovieName::MovieType]
val movies = sc.textFile("E://ml-1m/movies.dat")
//提取电影id和评分,(MovieID, Rating)
val movieRating = userRating.map { line => {
val rating = line.split("::")
(rating(1).toInt, rating(2).toDouble)
}
}
// 计算电影id及其平均评分,(MovieId,AvgRating)
val movieAvgRating = movieRating
.groupByKey()
.map { rating =>
val avgRating = rating._2.sum / rating._2.size
(rating._1, avgRating)
}
//提取电影id和电影名称,(MovieId,MovieName)
val movieName = movies.map { movie =>
val fields = movie.split("::")
(fields(0).toInt, fields(1))
}.keyBy(_._1)
movieAvgRating
.keyBy(_._1)
.join(movieName) // Join的结果(MovieID,((MovieID,AvgRating),(MovieID,MovieName)))
.filter(joinData => joinData._2._1._2 > 5.0)
.map(rs => (rs._1,rs._2._1._2,rs._2._2._2))
.saveAsTextFile("E:/MovieRating/")
}
}
总结
本文对Spark Core进行了详细讲解,主要包括RDD的基本概念、RDD的操作算子、共享变量以及持计划,最后给出两个完整的Spark Core编程案例。下一篇将分享Spark SQL编程指南。
公众号『大数据技术与数仓』,回复『资料』领取大数据资料包