2019独角兽企业重金招聘Python工程师标准>>> 
先说明下配置:
web.xml,还是最简单的配置
Archetype Created Web Application
mvc
org.springframework.web.servlet.DispatcherServlet
1
mvc
/*
mvc-servlet.xml配置:
zh_CN
先说说服务器端数据到客户端的乱码:
第一种情况:
@Controller
public class StringAction {
@ResponseBody
@RequestMapping(value="/string",method=RequestMethod.GET)
public String testMessageConverter(String name){
return "中国";
}
}当访问 http://localhost:8080/string?name=aaa时,浏览器看到的是乱码:

分析过程:
有了上一篇文章的知识,便可以知道原因。首先由RequestMappingHandlerAdapter来调度执行,由于是@ResponseBody,所以从所有的已注册的HandlerMethodReturnValueHandler中找到了@ResponseBody的支持者RequestResponseBodyMethodProcess。然后就是根据客户端Accept字段指定的多个content-type和服务器端指定的content-type进行比较配对,选出最合适的一个content-type。此时@RequestMapping中并没有为produces指定相应的content-type,所以会获取所有的已注册的HttpMessageConverter所支持的content-type作为服务器端指定的content-type。在本工程中最终会选出text/html作为最终的content-type,服务器端数据要以text/html形式写入response的body中。有了返回值的类型为String和content-type为text/html,然后就是从已注册的HttpMessageConverter中找到一个支持这两者的HttpMessageConverter,然后就找到了StringHttpMessageConverter,它有两个构造函数,一个可以指定字符集,当你什么都没有指定时,默认使用ISO-8859-1。在将返回值"中国"以text/html形式写入response的body中时,StringHttpMessageConverter先从上述所选出的content-type(即text/html)中尝试获取字符集,若获取不到,则使用自己默认的ISO-8859-1,最终的写入代码为:StreamUtils.copy(s, charset, outputMessage.getBody());
s就是返回值"中国",charset就为StringHttpMessageConverter默认的ISO-8859-1,造成了编码方式不对,同时ISO-8859-1是不支持中文的,所以就出现了乱码。对以上过程还不清楚的,可以看上一篇文章的介绍。
在整个服务器端数据返回到浏览器的过程中,涉及到三次编码。
第一次:java文件以什么编码存放在硬盘中,目前我的工程全部使用UTF-8编码方式,所以程序中的中国是以UTF-8形式编码的
第二次:中国这个字符串是以什么编码方式转换成字节数组的,由于未指定@RequestMapping的produces属性,同时也未给StringHttpMessageConverter指定编码方式,最终‘中国’这个
字符串是以ISO-8859-1形式转换成字节数组的
第三次:数据发送给浏览器后,浏览器接收到一堆字节数组,浏览器又是以什么编码方式来解码的。
这样才能保证不会乱码,首先java文件是以UTF-8形式存储的,然后指定StringHttpMessageConverter或者@RequestMapping的produces的编码方式为UTF-8,最后发给浏览器的header中的content-type也为UTF-8,这样才不会乱码。
针对本工程:
解决方案一:
指定@RequestMapping的produces为"text/html;charset=UTF-8"即可解决乱码。
首先"中国"是以UTF-8编码的方式存在硬盘中,即硬盘中存储的是'-28 -72 -83;-27 -101 -67',然后又指定了response的content-type为"text/html;charset=UTF-8",此时StringHttpMessageConverter可以从这个content-type读取到编码方式,便不再采用默认的编码方式ISO-8859-1。执行"中国".getBytes("UTF-8")(即为上述所写的字节数组)将这些字节数组写人response的body中,同时设置response的content-type为produces的值即text/html;charset=UTF-8,浏览器拿到这个content-type便知道以UTF-8形式来解码这些字节数组,便又得到的'中国'。你也可以设置浏览器以GBK编码方式来解码这些字节数组,必然又会出现乱码。所以上述三个过程的编码都统一才会保证不会乱码。也就是你可以全部指定上述三个过程的编码全是GBK,仍然不会乱码。出现乱码必然是上述三个过程的编码不一致造成的。
解决方案二:
指定StringHttpMessageConverter的编码方式为UTF-8,如下:
它背后的内容先暂不解释,下一篇文章再介绍。这里只是在StringHttpMessageConverter构造时,传入一个UTF-8的字符集进去,会调用如下构造函数:
/**
* A constructor accepting a default charset to use if the requested content
* type does not specify one.
*/
public StringHttpMessageConverter(Charset defaultCharset) {
super(new MediaType("text", "plain", defaultCharset), MediaType.ALL);
this.defaultCharset = defaultCharset;
this.availableCharsets = new ArrayList(Charset.availableCharsets().values());
} 这样就更该了StringHttpMessageConverter的默认字符集编码为UTF-8。但是这样做有一个问题就是并没有为content-type的字符集设置为UTF-8。看如下代码:
/**
* This implementation delegates to {@link #getDefaultContentType(Object)} if a content
* type was not provided, calls {@link #getContentLength}, and sets the corresponding headers
* on the output message. It then calls {@link #writeInternal}.
*/
@Override
public final void write(final T t, MediaType contentType, HttpOutputMessage outputMessage)
throws IOException, HttpMessageNotWritableException {
final HttpHeaders headers = outputMessage.getHeaders();
if (headers.getContentType() == null) {
MediaType contentTypeToUse = contentType;
if (contentType == null || contentType.isWildcardType() || contentType.isWildcardSubtype()) {
contentTypeToUse = getDefaultContentType(t);
}
if (contentTypeToUse != null) {
headers.setContentType(contentTypeToUse);
}
}
if (headers.getContentLength() == -1) {
Long contentLength = getContentLength(t, headers.getContentType());
if (contentLength != null) {
headers.setContentLength(contentLength);
}
}
if (outputMessage instanceof StreamingHttpOutputMessage) {
StreamingHttpOutputMessage streamingOutputMessage =
(StreamingHttpOutputMessage) outputMessage;
streamingOutputMessage.setBody(new StreamingHttpOutputMessage.Body() {
@Override
public void writeTo(final OutputStream outputStream) throws IOException {
writeInternal(t, new HttpOutputMessage() {
@Override
public OutputStream getBody() throws IOException {
return outputStream;
}
@Override
public HttpHeaders getHeaders() {
return headers;
}
});
}
});
}
else {
writeInternal(t, outputMessage);
outputMessage.getBody().flush();
}
}关键是执行顺序,先是根据request的Accept指定的content-type和@RequestMapping的produces指定的content-type,或者是所有的HttpMessageConverter所支持的content-type选出一个最合适的content-type,最终选出为text/html,然后将它作为contentType参数传入上面的方法中,接下来就在设定header的content-type,根据代码最终会设置content-type为text/html但是不含字符集编码,然后才是调用StringHttpMessageConverter的写入方法,将中国以StringHttpMessageConverter的编码集UTF-8转换成字节数组写入resposne的body中。
此时,返回给浏览器的content-type字段并没有指定编码集,它将以它默认的方式来解码。
如下content-type并没有编码方式,而方案一的content-type是有编码方式的
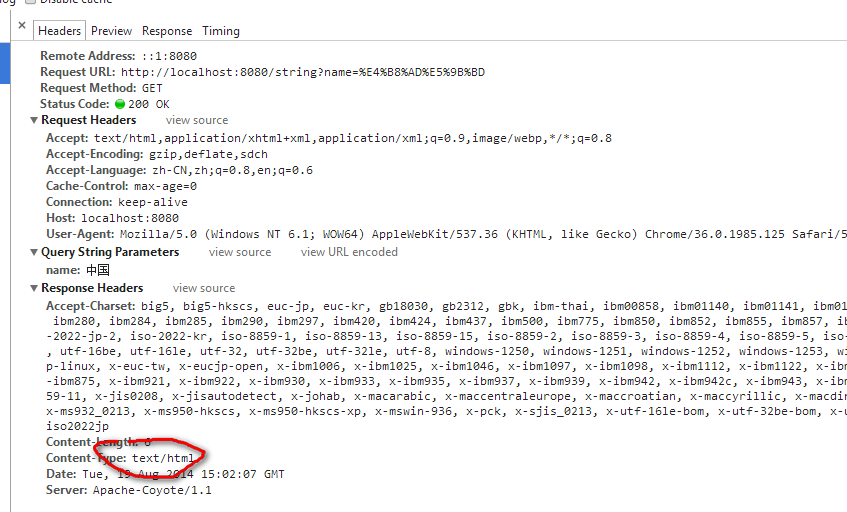
如果浏览器的默认编码为UTF-8则不会显示乱码,如果为GBK则会显示乱码。可以用chrome浏览器进行测试:
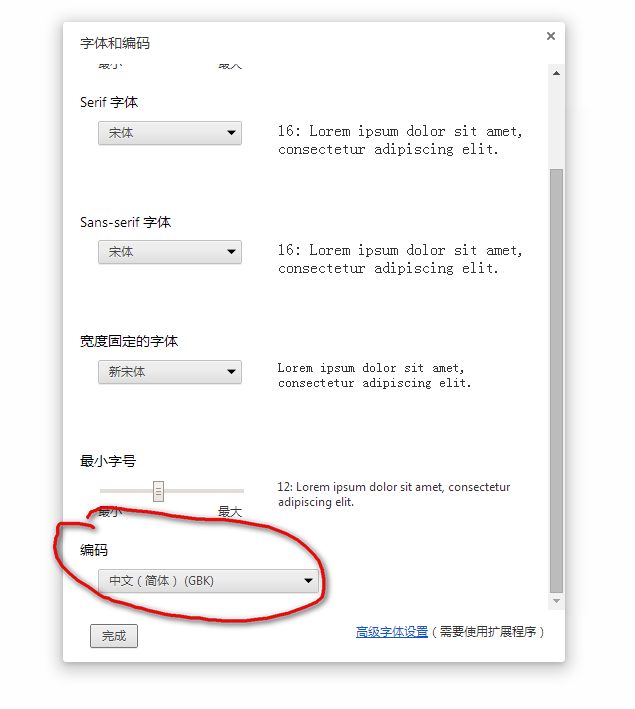
设置chrome浏览器的默认编码方式如下:
工具-》设置-》高级设置-》自定义字体
至此就说完了服务器端发送数据到浏览器这一过程中的乱码问题。然后接下来就要说浏览器客户端传数据到服务器端显示过程中的乱码问题。
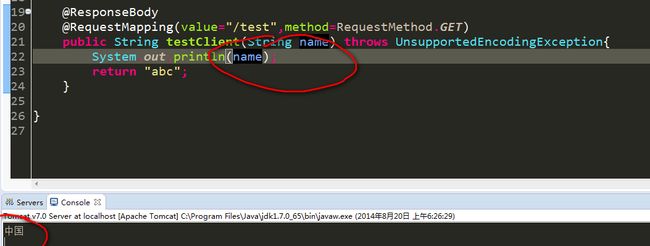
StringAction新加一个方法如下:
@ResponseBody
@RequestMapping(value="/test",method=RequestMethod.GET)
public String testClient(String name){
System.out.println(name);
return "abc";
}此时先不用管服务器端返回给浏览器的乱码问题,只关注浏览器端发送给服务器端的数据,在服务器端是否能打印出正常数据。
访问http://localhost:8080/test?name=中国,服务器端的打印情况为:

出现了乱码。
首先分析下整个过程涉及到几次编码:
第一次:当你输入http://localhost:8080/test?name=中国的时候,浏览器将以什么样的编码方式将中国转化成字节数组,这称为URL编码
第二次:当浏览器发送请求时,服务器是以请求的content-type来解析请求数据的,当浏览器请求没有指定content-type时,服务器又是采用什么样的编码来解析的
乱码的本质:这两次编码方式不一致
针对第一个过程,当你仅仅在浏览器上输入http://localhost:8080/test?name=中国来访问时,不同的浏览器会采用不同编码方式来将中国转换成字节数组。比如说chrome浏览器始终以UTF-8的编码形式将中国转换成字节数组。而目前我的IE浏览器则是以GBK的编码方式来转换的,你可以找一找如何设置浏览器的这些行为,本文不再说明。正是由于上述不同浏览器的不同处理情况,导致了可能用chrome发送服务器端正常,IE发送则乱码的现象。
针对第二个过程:由于我们未指定request的content-type,服务器来解析这些字节数组,它到底采用什么样的方式来解析呢,不同的服务器应该有不同的策略,并且可以进行设置。如Tomcat服务器,默认采用的是ISO-8859-1,你可以修改Tomcat的conf/server.xml文件来修改Tomcat的默认编码解析方式。
这里的tomcat版本是7,在tomcat8中已修订,不存在这个乱码问题
情况分析完了,针对我的工程就要解决这一乱码问题。
首先我使用chrmoe浏览器发送http://localhost:8080/test?name=中国,它默认以UTF-8形式发送给服务器,我的tomcat服务器没有更改默认的编码,即仍是采用ISO-8859-1来解析那些没有指定content-type的请求。
中国经过chrome浏览器的以UTF-8形式的编码变为-》%E4%B8%AD%E5%9B%BD,然后此请求没有指定content-type,所以tomcat将采用ISO-8859-1来解码,然后肯定就出现了乱码。
解决方式一:方法参数name是tomcat用ISO-8859-1解码出来的,我们需要再把它仍按照ISO-8859-1编码回去得到浏览器传过来的原始字节数组,这些字节数组就是chrome以UTF-8形式将中国编码的,所以我们只需要将这些字节数组以UTF-8方式再解码一次,就可以得到正常的数据了。其实就是撤销掉tomcat的解码操作,还原浏览器传过来的原始字节数组,然后再按照浏览器的编码方式来解码这些字节数组,代码如下:
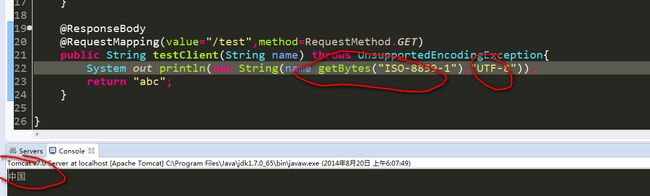
然而这种方式,只能针以UTF-8形式编码数据的浏览器,对于IE仍是乱码,若将代码改为以GBK来编码原始数据则IE是正常的,chrome则出问题:
@ResponseBody
@RequestMapping(value="/test",method=RequestMethod.GET)
public String testClient(String name) throws UnsupportedEncodingException{
System.out.println(new String(name.getBytes("ISO-8859-1"),"GBK"));
return "abc";
}解决方式二:就是更改服务器的默认编码配置,如tomcat,在conf/server.xml文件中
使用URIEncoding='UTF-8'。这个设置是针对url中的请求参数的编码的就是针对?name='中国'这种参数的编码
仍是上述问题,对于chrome是正常的,但对IE就乱码。由于chrome是以UTF-8编码的,服务器又是以UTF-8解码的,所以正常。对于IE,IE是以GBK编码的,服务器仍采用UTF-8来解码肯定出现乱码。对于chrome如下:
至此浏览器发送数据到服务器乱码,服务器发送数据到浏览器乱码的两个过程的原理都说完了。不知道你是否完全理解了,有没有信心去帮助别人解决乱码问题。
下一篇再详细说说Tomcat和CharacterEncodingFilter对乱码的参与