简介
M项目, 是一个电子社保业务系统,2019.8月团队接手了这个项目的开发工作,到2020.7月客户的业务量翻了4倍,工作日同时在线员工数量40人,以下记录总结2019.8-至今项目的架构变化,以及项目中积累的一些经验。
[2019.8] 项目接手后的初始架构
物理架构
M项目的原始物理架构非常的简单,属于最简单的单机单体系统,大部分服务都寄宿在一台双核,8G内存的虚拟机中(包含MySQL数据库服务和文件存储服务),只有邮件发送服务使用的是第三方服务SendGrid。相对于客户最多10人同时在线的需求,日均300张发票的业务场景,此虚拟机的配置和物理架构足够支撑客户的业务。

逻辑架构
项目初期的逻辑架构也非常简单,有2个可用站点,分别是业务系统站点Gateway和项目宣传站点Portal。所有的业务都封装在Gateway API中。数据持久化使用了单机版的MySQL实例。
其中Gateway API是项目的核心部分,程序的所有业务代码都集中于此,小到发送邮件,创建PDF, 大到提交发票,社保索赔,支付订单都放置与此。这种设计方式很适合初期堆功能,虽然后期客户发展,这种设计造成了很大的问题,但是在项目初期,我觉着这种方式还是非常适合帮助客户快速拓展业务的。

在逻辑架构上,我觉着唯一存在问题就是Gateway API中寄宿的Job, 这里的Job,其实是一个定时任务组件,定期执行一定的业务操作,例如当客户的社保即将到期,需要发送提醒邮件。这里的问题是Gateway API是寄宿在VM的IIS中的,众所周知,IIS有自己的回收机制,所以在Gateway API中寄宿一个Job是非常不明智的,因为很容易出现Job线程被回收,定时任务不能正常执行。这里为了避免IIS回收,之前的团队添加了一个Windows定时任务,这个定时任务每10分钟调用一次Gateway API来确保Job不被IIS回收掉, 我们称之为“土办法”。实际上这里将定时任务寄宿在Windows Service才是更合理的方式。
代码分层
代码分层方面,项目从开始就使用了DDD的一套标准分层架构并引入了CQRS,这套分层架构非常的复杂,需要很高的成本,对开发人员的要求很高,特别不适合新开始的项目,特别是在不知道业务前景和未来规模的时候。架构设计的太复杂,会导致功能推进的速度很慢。实际实践中也印证了这一观点,当刚接手这个项目的时候,为了添加一个新功能,我们也确实花费超过正常编码2-3倍的时间,虽然熟练之后,能逐步缩小这个倍数,但是相对于一些简单分层就够,开发速度上还是有一定的差距。

实事求是的讲,除了没有使用DDD中的聚合概念,这套架构的设计上是没有太大问题的,甚至在后期客户业务量暴增的时候起到了很大的作用,例如,后来我们在添加业务日志的时候,由于项目使用了CommandBus, 这个功能实现起来非常的容易。所以我们也不能说当时使用这套分层架构就完全没有什么益处,但是总体上来说, 我觉着项目初期还是应该采取一些简单分层架构,使用架构演进的方式,根据客户业务来不断调整架构。
[2019.9] 启用GCP Cloud Storage和GCP MySQL
接手项目之后,团队接到的第一个任务是提升项目的安全性和可靠性。为了通过政府验收,每个电子社保系统需要保证系统中数据和文档的安全性,所有的数据都需要保留历史,所有的文档,票据都需要保留在澳洲本土至少7年.
所以之前在单服务器中安装独立MySQL服务,以及使用服务器自身的文件存储来保存发票和相关文档显然是非常危险的.如果稍有不慎,服务器硬盘损坏,就可能造成无法挽回的损失.
所以这里,团队选择改用GCP MySQL作为数据库服务,使用了GCP Cloud Storage作为文件存储服务.

针对数据库服务,我们启用了Failover机制,当主库宕机,系统会自动切换到Failover数据库,保证系统运行。这里主库和Failover库启用了自动同步,最大程度的保证了数据安全性.
针对文件存储服务,虽然GCP Storage给出了11个9的可用性保证,但是团队还是启用了Replication机制,来保证一个文件同时在2个Bucket中保留备份,最大程度的保证了文档的安全性
这里为了帮助客户减少开支,团队同样使用了GCP Cloud Storage过期策略
- 客户上传的发票附件,系统生成的政府社保记录,每个生成的客户对账单,都使用永不过期策略
- 系统产生的中间文件,临时日志文件都使用1天有效期的过期策略, 过期之后自动移除
这次架构变更的不足之处是,针对Web服务器的灾备没有做好计划和安排,没有做到及时的调整架构,此时其实已经察觉到了一些灾备方面的问题,如果此时Web服务器宕机,团队很难在5-10分钟内启动一台新主机来支撑业务,所有的发布代码都没有备份,重新发布代码需要大量时间.
PS: 此处的另外一个严重问题是,客户站点的域名管理是在另外一家澳洲公司手上,他们只负责将域名指向到指定的公网IP, 但是我们在创建GCP云主机的时候,没有购买固定公网IP, 所以一旦主机崩溃,重建新主机,也需要通过第三方公司重新配置域名指向,才能恢复系统使用。这就更难在短时间之后恢复一个已经宕机的系统了。这里的正确做法应该是购买固定公网IP, 将固定公网IP绑定到主机上,这样就算重建主机,也能在不通过第三方的情况下,恢复业务
其实此时是修改架构的最好时机,但是由于经验不足,大好的机会就错过了,后面由于业务量暴增,大部分时间都在处理新功能和性能方面的问题,所以最终灾备部分拖了很久才实现,现在想想以这种裸奔的方式维护一个生产项目,特别是和“钱”相关的项目,还是挺可怕的。
[2019.10] 分离PDF生成服务
在M系统中,有许多PDF生成的场景:
- 客户每月交易清单(Client Statement)
- 当月所有客户交易清单(All client statements in 1 month)
- 客户历史交易清单(All statements of one client)
- 供应商汇款清单(Payment Remittance)
- 自动生成发票(System genereted invoice)
在最初的项目中,开发团队使用了wkhtmltopdf组件,以及开源库DinkToPDF来生成项目中所需的PDF文件. 这种方式的问题是,wkhtmltopdf组件不是标准的.NET托管库,它是一个非托管的C++程序集,寄宿在IIS中有相当大的风险,如果IIS将其回收,会导致整站的PDF生成功能瘫痪。这个问题在客户业务量小的时候,没有什么大问题,就算出问题,也可以通过Stop/Start站点的方式恢复功能,但是在业务量大的时候,就变成了一个很大的问题,用户和系统的交互非常的频繁,你很难有机会去做一个Stop/Start站点的操作,而且这样手动处理生产问题的方式有点太粗暴了。
除此之外,另外一个非常严重的问题就是,所有的PDF文件都是用户请求之后立刻生成的,没有任何预生成的机制,这种方式会严重阻塞Web应用,甚至超时。你可以想想一下,客户下载每月所有客户交易清单(All client statements in 1 month)的时候,需要首先生成每个客户的交易清单,然后将他们组合,如果有2000个客户,每个客户的清单PDF大小是200KB, 那么组装和下载的文件大小就是接近400MB,这也极大的占用的服务器的带宽。
在和客户讨论过实际需求之后,团队决定将PDF生成服务从Gateway中分离出来,并将每月的客户交易清单改为每月1号凌晨闲时预生成,生成之后保存在GCP Cloud Storage中, 每次用户需要下载的文件时候,服务器端通过GCP SDK生成一个授权URL, 客户端通过这个授权URL从GCP Cloud Storage直接下载所需文件,这样也极大的保证的文档的安全性,只有授权的用户才能访问这些文件。
这样的做的好处有2点:
- 避免了用户在忙时占用大量服务器资源,阻塞网站
- 所有的文件都是从GCP Cloud Storage中直接下载,减少了Web服务器带宽的占用
从这里开始架构中加入了RabbitMQ消息队列,这里使用消息队列的原因是,在站点失去了立即生成PDF的功能之后,就必须保证所有的PDF都正常生成,否则用户在界面下载文件的时候会报错,使用了消息队列之后,所有的未完成的PDF生成请求都会记录在消息队列中,就算PDF Generator崩溃,可以重新启动一个实例,继续处理请求,不会导致任何文件生成请求丢失。
PS: 这里其实没有考虑死信的问题,后续做Email Service的时候才发现了这个问题。
完成这一部分修改之后,系统的架构图如下:

[2019.10] 追加业务日志工具 Log Tools
Log Tools是团队在10月份添加一个功能,最初只是作为辅助开发工具,记录一下程序日志,帮助团队开发任务的时候,追踪Bug。随着项目的不断进行和客户业务的不断扩大,客户和团队也越来越依赖这个工具,追踪一些线上问题。这个算是本项目中团队的亮点之一了。
- 客户可以通过日志工具
- 追踪员工工作情况,登录/登出历史,操作日志
- 追踪系统发出的邮件历史和详情
- [管理员]灾备相关的系统还原
- 团队可以根据日志来推断Bug原因,有些Bug的错误信息,甚至可以从工具日志中直接了解到,这在一个金融系统中尤为重要,如果没有日志,你很难从结果上判断出客户的操作步骤,以及产生Bug的原因。


引入日志工具后的架构图如下:

在Log Tools的实现上,团队充分利用了当前现有的架构,借助CommandBus非常容易的就实现了一个日志记录工具,因为所有业务操作的入口都是CommandBus, 所以在CommandBus的Send方法中可以记录所有想要追踪的信息。

CommandBus.cs
public void Send(T command) where T : ICommand
{
var logger = InjectContainer.GetInstance().GetLogger();
var commandValidator = InjectContainer.GetInstance>();
...
if (command != null)
{
logger.WriteJson("Request command", command);
}
if (commandValidator != null)
{
logger.WriteBusinessLog("Validate request", "Gateway is trying to validate the request.");
...
logger.WriteBusinessLog("Validate request", "Validation passed.");
}
var handler = InjectContainer.GetInstance>();
if (handler != null)
{
try
{
handler.Execute(command);
}
catch (Exception ex)
{
...
logger.WriteUnhandledErrorLog(ex.ToString());
throw ex;
}
finally
{
handler.Dispose();
}
...
}
如果想针对某个业务操作启用日志,只需要在对应控制器的action方法签名部分使用DomainLogger特性登记一下需要记录的业务操作类型即可。
[Route("Create")]
[HttpPost]
[RequestRole(AuthRoleType.Staff, AuthRoleType.Admin)]
[RequestPermission(PermissionFeatureType.Claims, PermissionActionType.Add, "Requires create support items permission")]
[DomainLogger("Create Claim Batch")]
public IActionResult Create([FromBody]Claim_Create_Model dto)
{
var command = BuildCommand();
command.Invoice_Item_IDs = dto.invoice_item_ids;
CommandBus.Send(command);
return CommandResult(command.ExecuteResult);
}
[2019.11] 从Goolge Cloud转移到AWS, 分离测试和生产环境
2019年11月,团队进行了一次整体站点的迁移,整个M站点从Google Cloud转移到了AWS。这其中的主要原因是Google Cloud的很多服务不太专业, 中间由于Failover数据库出现了一次非程序导致的崩溃问题,提了多次Ticket没有解决,最终还是团队自己在Google Cloud论坛中自己找到的解决的方法,所以团队决定进行整站的迁移,使用稳定性更强,服务更好的AWS.
这里服务转移的对应关系如下:
- GCP VM Instance -> AWS EC2
- GCP Storage -> AWS S3
- GCP MySQL -> AWS RDS MySQL
变更之后的架构图:
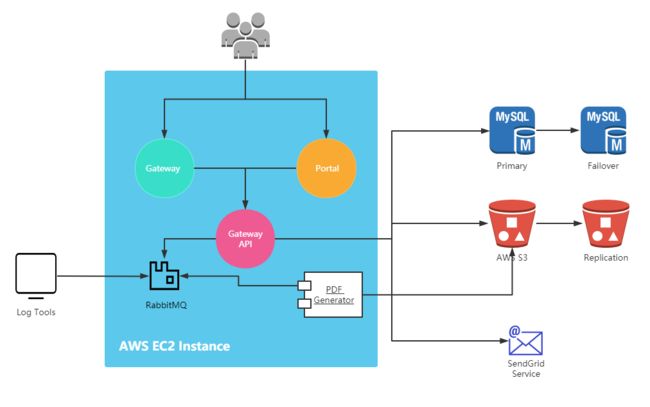
这次变更的时候,团队吸取了之前教训,在创建AWS EC2 Instance的时候,购买了固定公网IP, 这样我们可以将这个公网IP绑定到任意AWS EC2实例或者负载均衡器上。
PS: 使用AWS EC2的时候购买固定公网IP其实还是挺重要的,因为如果没有指定固定公网IP, AWS EC2实例在Stop/Start之后,公网IP会重新分配, 这点要特别注意。
在这次变更中,我们还通过购买额外的AWS EC2实例和AWS RDS MySQL实例,分离了测试和生产环境,这样进一步的提高的Gateway站点的业务处理能力,减少了开发对生产环境的印象。

[2020.3] Email Service变更, SendGrid不再支持BCC
在2020年3月份,团队收到第三方邮件提供商SendGrid的预警邮件,他们的邮件服务将不再支持BCC暗送功能,但是在M客户的实际业务中,BCC暗送的使用非常的频繁,这一次的功能变更导致我们不得不抛弃第三方邮件服务SendGrid, 改用基于Mailkit开发的邮件发送服务。为了保证邮件服务的健壮性,团队依然使用了RabbitMQ消息队列来传递待发送的邮件请求。
这里看似没有什么大问题,但是实际操作中团队遇到了一些没有预想到的错误。
- 客户使用的是Office 365邮箱,Office 365单账户每日最多发送10000封邮件,超出之后邮件服务异常,这在之前使用SendGrid发送邮件时是从来没有遇到过的。
- 当消息队列中某个发送邮件请求处理异常的时候,会导致整个消息队列阻塞,一直处理这个异常的请求,而团队没有加入死信队列的设置,导致队列积压,最多了时候积压了1000+封邮件。
Office 365单账户单日10000封邮件问题
Office 365邮箱,单账户每日最多发送10000个邮件请求,超出之后,剩余额度会在第二天0点重置。在客户业务少的时候,团队并没有发现这个问题,直到2020.4.1日客户首次单日发送数量超过10000之后,团队才发现这个问题。
PS: Office 365邮箱的每日10000封发件阈值是无法更改的,就算你讲邮箱账号升级到最高级别,此阈值也没有任何变化
针对这个问题团队的解决方式是,使用多个主账号基于Shared Box轮换发送邮件来解决。
这里需要说明一下项目使用的发件箱是几个Shared Box, 所谓的Shared Box就是可以挂靠在多个主邮箱下面的共享邮箱,使用主邮箱账户登录之后,可以使用Shared Box邮箱发件,这里主邮箱会作为主体来计算剩余的发件额度。
已下图为例,[email protected]和[email protected]是2个Shared Box, [email protected]和[email protected]是2个主账号。当你使用[email protected]和[email protected]登录邮箱之后,你就可以使用[email protected]和[email protected]作为发件人发送邮件,产生的额度是算在主账号[email protected]和[email protected]下面的,不会算在Shared Box邮箱上,这样你就可以用[email protected]和[email protected]账号以[email protected]和[email protected]的名义发送20000封邮件
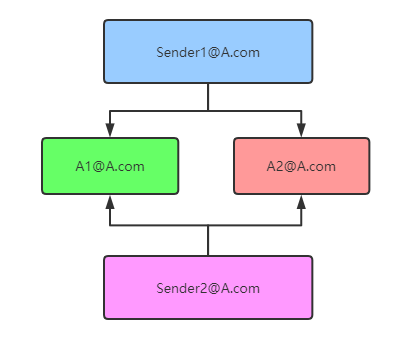
所以我们借此可以根据客户每日大概的发件数量,添加多个主账号,并分配相同的Shared Box,当一个主账号由于额度用满导致发送失败之后,我们可以自动切换到下一个可用的主账号。这样单日的10000封邮件的额度问题就解决了。
PS: 之前一直有个疑问就是SendGrid为啥没有这个问题?后来研究发现,SendGrid发件使用的是匿名服务器,发件人你填谁的都可以,发件不会经过发送人的邮件服务器,只是作为收件人收到邮件的时候,会收到提示,“当前邮件不是从真实的发件服务器发送过来的”。因此SendGrid也就根本没有什么10000封邮件请求的限制了。
异常消息的处理
2020.4月某天团队发现生产事故,消息队列中堆积了1000多封邮件,具体的原因是有一个异常消息进入队列,一直没有被消费掉,导致后续的邮件发送请求无法及时处理。此时团队才意识到此处功能缺少了一个死信队列的防护。
PS: 所谓的死信队列 , 即一个队列中的消息变为死信之后,它能被重新publish到另外一个死信Exchange中,死信Exchange将消息转发到另外一个队列中,这个队列就是死信队列
使用死信队列的好处就是当出现不能及时消费的消息时,队列不会被阻塞,后续的消息可以继续被消费,团队可以针对死信队列中的消息做调试和处理,手动消费掉这些异常的消息。
不过团队在当前项目中,没有直接使用死信队列,而是设计一个更为完善的处理方式。团队为邮件发送功能设计里3个队列,EmailRequestQueue、EmailRequestFailureQueue、EmailRequestUnavailableQueue。
EmailRequestQueue中存放了所有待发送的邮件请求EmailRequestFailureQueue中存放了所有发送失败3次的邮件请求EmailRequestUnavailableQueue中存放了所有的异常请求
当一个正常的邮件请求进入队列,处理程序处理请求时发生异常,且异常次数小于3时,程序会将消息ACK, 随后消息请求上记录失败次数+1, 并将其重新放入EmailRequestQueue队列中。
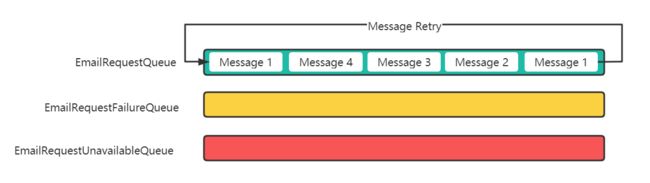
这样就算针对当前请求,处理程序出现异常,后续的邮件请求也可以正常被处理,当其他消息都处理完成之后,处理程序才会来重新尝试处理之前异常的消息,相当与是重试了一次。
当消息重试了3次都不能正常处理的,程序会将其ACK,并转发到EmailRequestFailureQueue中,并向团队发送Slack消息/邮件提醒,有异常发件请求。

针对这部分的消息,团队需要立即手动调试查找失败原因并手动消耗掉。
最后,如果一个非法的请求进入队列,程序会将其ACK,并转发到EmailRequestUnavailableQueue中,避免阻塞消息队列,这种消息一般都是由于错误格式的邮件请求导致的,所以团队并不需要立刻处理,每日统一处理一次即可。

完成以上修改之后,架构图如下:

[2020.6] 使用Slack作为通知服务
Slack是一个以聊天群组为基础的企业沟通和协作工具,Slack提供了非常丰富的接口,可以和大部分的工具集成,而且提供了多平台的客户端,保证了消息能及时准确的接收。开发人员甚至可以自己创建一个Slack App, 将自己的程序与Slack集成在一起。
使用Slack的免费版本,
- 开发人员可以创建最多5个Slack App
- 每个频道内可以发送的消息是无限的,但是仅保留最新的10000个消息
团队选择Slack的初衷,是作为日志工具和运维工具, 在测试环境和生产环境产生的所有异常日志都可以直接输出到Slack频道。在使用Slack之前,团队一直使用邮件通知来处理类似问题,但是问题是有时候邮箱服务会不稳定,Slack相较于邮件通知稳定性更好。
接入Slack之后的架构图:

[2020.6] 修改文件上传方式
Gateway系统原先的文件上传方式,是非常传统的Web文件上传方式,客户通过浏览器发送请求,将文件流发送给服务器,服务器再负责将文件流保存到其他存储位置,由于当前项目中团队使用了AWS S3作为存储服务,所以服务器在接收到客户发送的请求之后,又将当前请求的文件流通过AWS S3 SDK发送到了AWS S3。

从整个流程上,不难发现,这种上传方式,文件流其实被传输了2遍,而且上传的速度很大程度取决于服务器的带宽,而当前项目的主机是一台m2.xlarge, 它的网络配置是Low(后续升级到了m2.x2large, 网络配置是Low to Moderate), 即低网络带宽,所以当用户大规模上传文件的时候,就会占用服务器的大量带宽,导致服务器响应速度大幅度下降。
所以这里团队修改了上传文件的方式,改为客户通过浏览器,将文件流直接上传到AWS S3, 然后根据上传的结果,将文件基本信息保存到服务器, 这样完全释放了服务器应对大规模文件上传的带宽压力。
PS: 这里的文件上传借助了
AWS S3 Javascript SDK
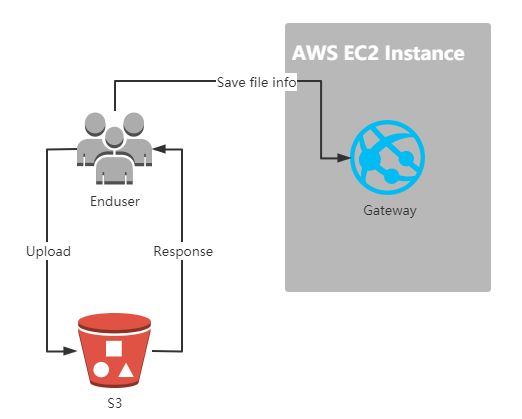
当然这种方式还是有2个需要注意的问题
- 使用这种上传方式,需要保证所有的客户网络都能直接访问到
AWS S3,如果是国内项目或者客户网络屏蔽AWS,可能没有办法这么实现。 - [重点]使用
AWS S3 Javascript SDK上传文件,需要前端代码中放置一个Access key, 请务必保证这个Key的授权范围,不要把不必要权限,特别是不要把FullAccess权限应用到这个Key上,因为前台代码人人可以获得,如果这个Key的权限过高,会将整个云资源处于非常危险的境地。这里最安全的做法是仅给出S3的PUT和POST的权限,仅能上传到一个指定桶即可。
[2020.7] Gateway中将Job移出
从2019.8-2020.7, M项目的业务量增长了4倍,同时在线的员工数量又原来的10+变为了现在的40人(这还没有包含社保客户和商店用户的在线数量),由于访问量的增大,网站性能和业务处理速度大幅度下降,纵向升级的方式的瓶颈越发明显,性能问题变成比业务功能开发更紧迫的问题。项目需要开始往分布式项目发展,Web App需要实现横向扩展。
这里阻碍实现横向扩展的一个问题就是整个项目的定时任务功能都是寄宿在Web App实例中的,如果保持现有架构,这里就要处理多Web App中定时任务的并发问题,这看起来非常不合理。因此定时任务的功能势必要移出Web App服务器,放到一个额外主机Service服务器中。
由于之前我们已经从Gateway API中移除了PDF Generator和Email Service,所以这里自然就可以将这些服务都转移到新主机中,这样也减小了Web App服务器的一些压力。
PS: 其实这里应该将RabbitMQ也换成独立PAAS服务,或者移动到Service主机中,这样Web App服务器就变成了一个更纯粹的Web host。
更新后代码架构图:

经验和教训
生产环境如何实现近似无Downtime部署?
对于生产环境,特别是高并发、高可用的生产项目,项目部署都是一个非常头疼的问题。以当前项目为例,在2019年的时候,由于业务量小,客户员工都在一个办公室上班,如果生产环境发现bug,团队可以在更改代码之后,发布hotfix的时候,通知所有员工暂停办公,然后使用Stop站点->发布代码->Start站点这种粗暴的方式来发布项目。进入2020年之后,随着客户业务量和同时在线人数的激增,以及疫情导致的远程办公,团队已经不可能选择使用Stop站点->发布代码->Start站点的方式来发布项目了,如果稍有不慎,就会打断客户员工正在执行的操作,造成不可挽回的错误。但是如果放弃白天部署代码,就意味着起码要承受1天的错误数据,这对于一个与“钱”相关的系统来说,简直就是无法想象的。
PS: Stop站点->发布代码->Start站点这几步就算操作的速度再快,也会花费几秒,甚至几十秒的时间,更不用说有的请求未结束,导致程序集被占用,导致新代码无法复制的问题。
团队必须实现一种无Downtime的优雅部署方式。
如果是一个已经启用负载均衡的分布式项目,实现起来可能更容易一些,我们可以通过创建新实例->发布新代码->修改负载权重,将新请求转发到新实例-> 移除旧实例的方式完成无Downtime部署。
由于M项目现在还没有达到需要负载均衡的程度,所以这里团队不能使用此方案,只能使用了IIS的回收机制,实现了一种近似无Downtime的部署方式。
其实和很多人一样,我之前一直认为IIS的回收和停止是没有区别的,后来在几位大神的指点下,自己做了下测试,确实如很多人所说,IIS的回收效果并不像直接停止站点那样粗暴,当IIS执行回收操作的时候,未结束的请求还是会使用旧代码来处理,但是新进入的请求,会自动使用新代码来处理,这样就保证了未结束的请求不会被意外中断,新进入的请求也能正确的处理。
那么我们的发布流程就可以变为这个样子:
- 如果服务器中旧代码的目录是A, 团队会创建一个新的目录B, 并将新代码发布到目录B
- 直接切换当前站点的映射目录,由A->B
- 回收当前站点的应用连接池
这3步操作甚至可以做成脚本自动化完成。大部分场景下都没有问题,只是在测试的时候发现,如果有长连接请求存在,回收之后,当前请求拿不到正确相应的问题,所以这里只能说是一种近似无Downtime的发布方式,但总体上讲比Stop站点->发布代码->Start站点安全的多。
PS: 这里其实使用Linux主机,配合nginx, consul, consul template和容器化技术也能实现类似的效果,但是当前项目还没有完成容器化的改造,所以这里也不考虑。
.NET Core项目中使用了大量Windows支持的路径格式,Linux不支持
当前项目中使用了很多的路径拼接,拼接的格式都是Windows路径格式。
public class FileFolderDefine
{
public static string LogFileFolder = "\\wwwroot\\log";
public static string TempFolder = "\\wwwroot\\cache\\temp\\";
public static string ClientApplicationDocumentFolder = "\\wwwroot\\upload\\client-application-document\\";
public static string ClientDocumentFolder = "\\wwwroot\\upload\\client-document\\";
public static string ClientStandingAuthorityDocumentFolder = "\\wwwroot\\upload\\client-standing-authority-document\\";
public static string ClientNoteDocumentFolder = "\\wwwroot\\upload\\client-note-document\\";
...
}
这样写的缺点就是当前项目只能跑在Windows上,不能在Linux上,甚至Docker容器中运行。这里正确的写法应该是使用Path.Combine方法进行路径拼接,这样才是最完备的方式。