PyPDF2 | 利用 Python 实现 PDF 分割
1. PDF 分割
由于疫情影响被迫在家上网课,因此教材也只能用电子版。但有一门教材是对开的扫描版,导致在 iPad 上阅读很不友好,因此决定寻找一个工具将 PDF 对半分开。

在百度了一番后,发现大多都是使用 Adobe Acrobat 软件进行剪裁,这完全不 Pythonic,因此又找了用 Python 处理 PDF 文件的方法,最后发现了 PyPDF2 这个库,本文将利用这个库,实现对 PDF 的分割。
首先,你需要通过 pip 安装这个库:
pip install PyPDF2
实现切割 PDF 的思想很简单,只要我们能测量出 PDF 的长宽,接着分别将左右裁剪拼接即可,而 PyPDF2 已经提供了这些功能:
# PdfFileReader 模块用于读取 pdf
# PdfFileWriter 模块用于创建要保存的 pdf
from PyPDF2 import PdfFileReader, PdfFileWriter
# 1. 读取 pdf
pdf_input = PdfFileReader(open('xxx.pdf', 'rb'))
# 2. 创建要保存的 pdf 对象
pdf_output = PdfFileWriter()
# 3. 选取第一页 pdf 读取长宽
page = pdf_input_left.getPage(0)
width = float(page.mediaBox.getWidth())
height = float(page.mediaBox.getHeight())
# 4. 计算 pdf 的总页数
page_count = pdf_input_left.getNumPages()
# 5. 修改某一页 pdf 的尺寸
page = pdf_input.getPage(i)
page.mediaBox.lowerLeft = (x,y)
page.mediaBox.lowerRight = (x,y)
page.mediaBox.upperLeft = (x,y)
page.mediaBox.upperRight = (x,y)
# 6. 将修改好的 pdf 添加到我们要输出的文件中
pdf_output.addPage(page)
# 7. 循环所有的页数后,将文件输出为 pdf 文件
pdf_output.write(open('xxx,pdf', 'wb'))
需要注意的是,PyPDF2 默认将较短的边作为 X 轴,较长的边作为 Y 轴,对应的坐标如下:
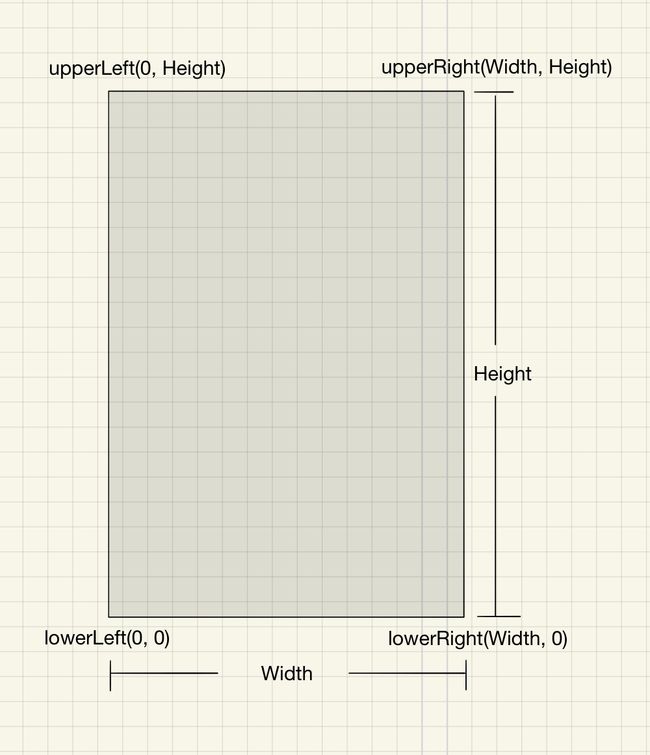
然而我们的 PDF 是横向比例的,如下图所示:

相当于:
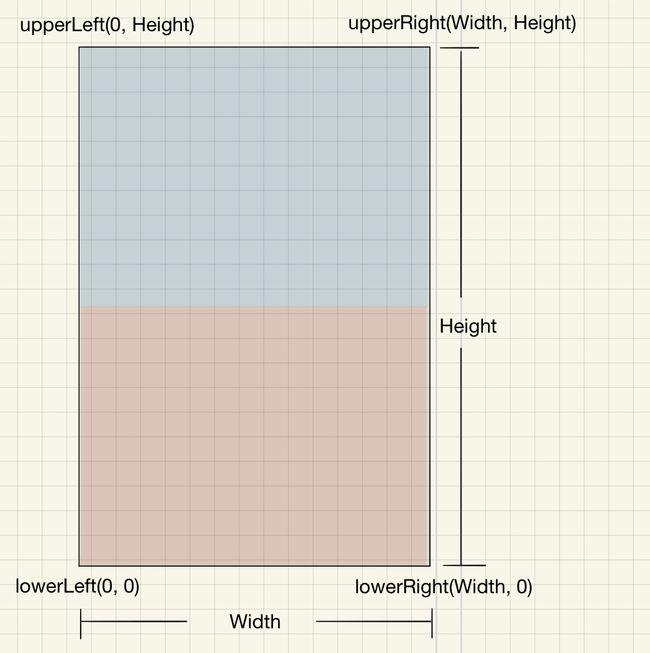
即:
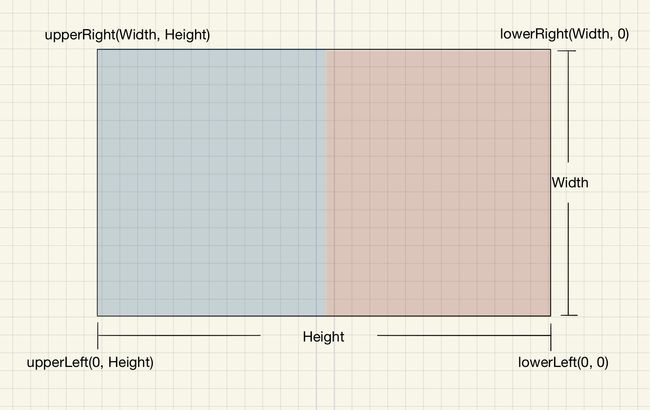
要注意与图 1 坐标的区别。
在弄清楚了 PyPDF 的坐标后,我们就可以通过调整四个角的坐标来分别获得左右两个 PDF 了,对于左边的 PDF,其对应的坐标为:

因此坐标设置如下:
page_left.mediaBox.lowerLeft = (0, height/2)
page_left.mediaBox.lowerRight = (width, height/2)
page_left.mediaBox.upperLeft = (0, height)
page_left.mediaBox.upperRight = (width, height)
而右半图的坐标为:
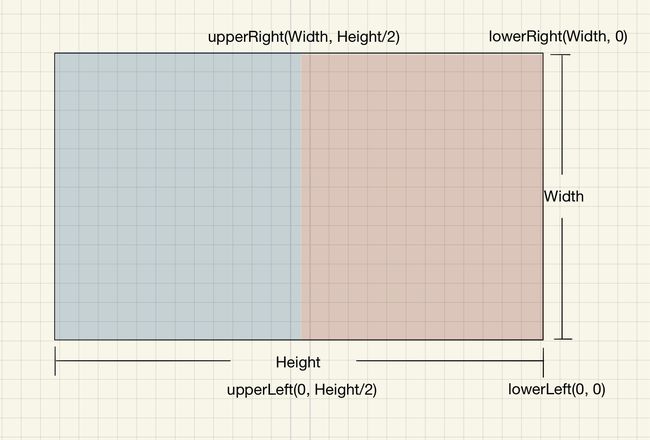
对应的坐标设置为:
page_right.mediaBox.lowerLeft = (0, 0)
page_right.mediaBox.lowerRight = (width, 0)
page_right.mediaBox.upperLeft = (0, height/2)
page_right.mediaBox.upperRight = (width, height/2)
最后汇总得:
from PyPDF2 import PdfFileReader, PdfFileWriter
infile = '应用多元统计分析 高惠璇.pdf'
outfile = '应用多元统计分析 高惠璇 split.pdf'
pdf_input_left = PdfFileReader(open(infile, 'rb'))
pdf_input_right = PdfFileReader(open(infile, 'rb'))
pdf_output = PdfFileWriter()
page = pdf_input_left.getPage(0)
width = float(page.mediaBox.getWidth())
height = float(page.mediaBox.getHeight())
page_count = pdf_input_left.getNumPages()
for i in range(page_count):
# left page
page_left = pdf_input_left.getPage(i)
page_left.mediaBox.lowerLeft = (0, height/2)
page_left.mediaBox.lowerRight = (width, height/2)
page_left.mediaBox.upperLeft = (0, height)
page_left.mediaBox.upperRight = (width, height)
pdf_output.addPage(page_left)
# right page
page_right = pdf_input_right.getPage(i)
page_right.mediaBox.lowerLeft = (0, 0)
page_right.mediaBox.lowerRight = (width, 0)
page_right.mediaBox.upperLeft = (0, height/2)
page_right.mediaBox.upperRight = (width, height/2)
pdf_output.addPage(page_right)
pdf_output.write(open(outfile, 'wb'))
看下转换效果,Bingo!

2. 调整边缘
转换后发现,PDF 存在这黑边,因此我们可以通过调整对应的坐标来减少黑边的现象:

from PyPDF2 import PdfFileReader, PdfFileWriter
def pdf_split(infile, outfile, left_margin=0, right_margin=0, down_margin=0):
pdf_input_left = PdfFileReader(open(infile, 'rb')) # 读取切割为左边的 pdf
pdf_input_right = PdfFileReader(open(infile, 'rb')) # 读取切割为右边的 pdf
pdf_output = PdfFileWriter() # 定义要保存的 pdf
page = pdf_input_left.getPage(0) # 选取第一页 来读取 pdf 的长宽
width = float(page.mediaBox.getWidth())
height = float(page.mediaBox.getHeight())
page_count = pdf_input_left.getNumPages() # 读取 pdf 页数
for i in range(page_count):
# 切割左边 pdf
page_left = pdf_input_left.getPage(i)
page_left.mediaBox.lowerLeft = (0, height/2)
page_left.mediaBox.lowerRight = (width, height/2)
page_left.mediaBox.upperLeft = (down_margin, height-left_margin)
page_left.mediaBox.upperRight = (width, height-left_margin)
pdf_output.addPage(page_left)
# 切割右边 pdf
page_right = pdf_input_right.getPage(i)
page_right.mediaBox.lowerLeft = (down_margin, right_margin)
page_right.mediaBox.lowerRight = (width, right_margin)
page_right.mediaBox.upperLeft = (down_margin, height/2)
page_right.mediaBox.upperRight = (width, height/2)
pdf_output.addPage(page_right)
pdf_output.write(open(outfile, 'wb')) # 保存 pdf
print('Done!')
infile = '应用多元统计分析 高惠璇.pdf'
outfile = '应用多元统计分析 高惠璇 split.pdf'
left_margin=10
right_margin=10
down_margin = 20
pdf_split(infile, outfile, left_margin, right_margin, down_margin)
Done!
看下最后效果:

其他文章推荐
机器学习算法与 Python 实现专栏
SQL 入门教程专栏