CRNN-基于序列的(端到端)图像文本识别
文章目录
- 一、前言
- 二、网络架构
- 2.1 特征序列提取
- 2.2. 序列标注
- 2.3. 转录
- 2.3.1 标签序列的概率
- 2.3.2 无字典转录
- 2.3.3 基于词典的转录
- 2.4. 网络训练
- 4. 总结
一、前言
在现实世界中,稳定的视觉对象,如场景文字,手写字符和乐谱,往往以序列的形式出现,而不是孤立地出现。与一般的对象识别不同,识别这样的类序列对象通常需要系统预测一系列对象标签,而不是单个标签。因此,可以自然地将这样的对象的识别作为序列识别问题。
ICCV 2017 澳大利亚阿德莱德大学沈春华老师组的作品Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks (https://arxiv.org/pdf/1707.03985.pdf) 。是目前为止第一篇提出端到端OCR文字检测+识别的文章。
本文是 An End-to-End Trainable Neural Network for Image-based Sequence Recognition and ItsApplication to Scene Text Recognition https://arxiv.org/pdf/1507.05717v1.pdf
卷积循环神经网络(CRNN),它是DCNN和RNN的组合。— 一种将特征提取,序列建模和转录整合到统一框架中的新型神经网络架构。
- 提出一种新的架构具有四个不同的特性:
- (1)与大多数现有的组件需要单独训练和协调的算法相比,它是端对端训练的。
- (2)它自然地处理任意长度的序列,不涉及字符分割或水平尺度归一化。
- (3)它不仅限于任何预定义的词汇,并且在 无词典和 基于词典的场景文本识别任务中都取得了显著的表现。
- (4)它产生了一个有效而小得多的模型,这对于现实世界的应用场景更为实用。在包括 IIIT-5K,Street View Text和ICDAR 数据集在内的标准基准数据集上的实验证明了提出的算法比现有技术的更有优势。
- 对于类序列对象,CRNN与传统神经网络模型相比具有一些独特的优点:
- (1)可以直接从序列标签(例如单词)学习,不需要详细的标注(例如字符);
- (2)直接从图像数据学习信息表示时具有与DCNN相同的性质,既不需要手工特征也不需要预处理步骤,包括二值化/分割,组件定位等;
- (3)具有与RNN相同的性质,能够产生一系列标签;
- (4)对类序列对象的长度无约束,只需要在训练阶段和测试阶段对高度进行归一化;
- (5)与现有技术相比,它在场景文本(字识别)上获得更好或更具竞争力的表现。
- (6)它比标准DCNN模型包含的参数要少得多,占用更少的存储空间。
二、网络架构
CRNN的网络架构由三部分组成,包括卷积层,循环层和转录层,从底向上。
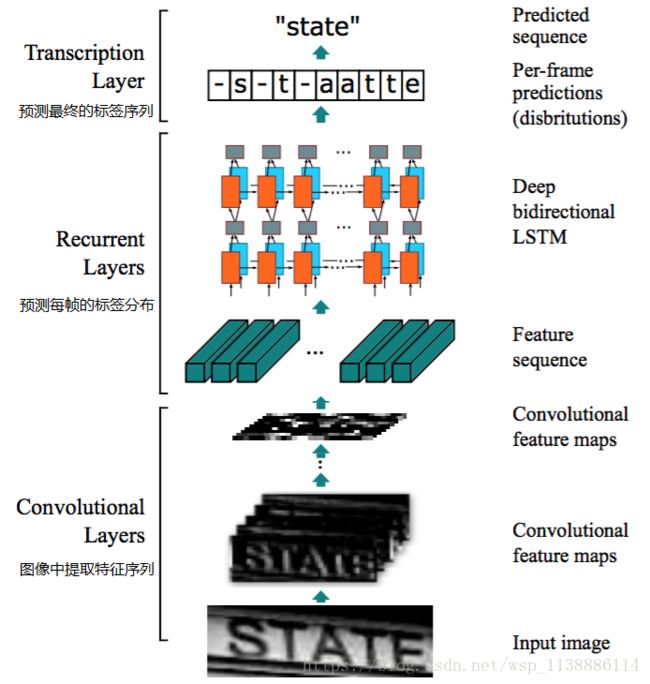
在CRNN的底部,卷积层自动从每个输入图像中提取特征序列。在卷积网络之上,构建了一个循环网络,用于对卷积层输出的特征序列的每一帧进行预测。采用CRNN顶部的转录层将循环层的每帧预测转化为标签序列。虽然CRNN由不同类型的网络架构(如CNN和RNN)组成,但可以通过一个损失函数进行联合训练。

在300dpi的分辨率下,一个中文汉字的宽度大约为50pix,一个英文字母的宽度大约为20pix,作者上面提供的网络模型,经过4个pooling和最后一个卷积(valid模式),总共会使得原图的宽度缩小pow(2,5)倍,即缩小32倍。而实际使用中,假设都使用一个像素预测一个结果,一个英文字母最多可以缩小20倍,一个中文最多可以缩小50倍。所以作者32倍的缩放对英文会有问题。我这里的建议是,将第三个或者第四个pooling的stride改为(1,2),这样就会使得最终的宽度只缩小16倍。从而满足实际需要。
2.1 特征序列提取
在CRNN模型中,通过采用标准CNN模型(去除全连接层)中的卷积层和最大池化层来构造卷积层的组件。这样的组件用于从输入图像中提取序列特征表示。在进入网络之前,所有的图像需要缩放到相同的高度。然后从卷积层组件产生的特征图中提取特征向量序列,这些特征向量序列作为循环层的输入。具体地,特征序列的每一个特征向量在特征图上按列从左到右生成。这意味着第i个特征向量是所有特征图第i列的连接。在我们的设置中每列的宽度固定为单个像素。
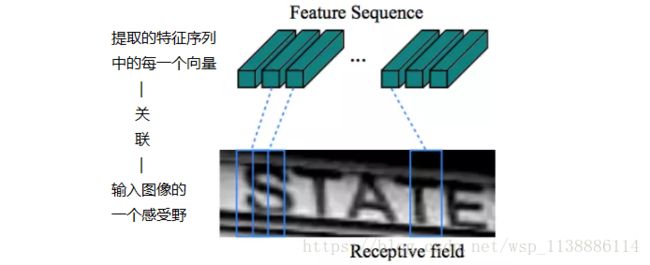
由于卷积层,最大池化层和元素激活函数在局部区域上执行,因此它们是平移不变的。因此,特征图的每列对应于原始图像的一个矩形区域(称为感受野),并且这些矩形区域与特征图上从左到右的相应列具有相同的顺序。如图2所示,特征序列中的每个向量关联一个感受野,并且可以被认为是该区域的图像描述符。
2.2. 序列标注
一个深度双向循环神经网络是建立在卷积层的顶部,作为循环层。
循环层预测特征序列 x = x 1 , . . . , x T x = x_1,...,x_T x=x1,...,xT 中每一帧 x t x_t xt的标签分布 y t y_t yt。
循环层的优点是三重的:
- 首先,RNN具有很强的捕获序列内上下文信息的能力。对于基于图像的序列识别使用上下文提示比独立处理每个符号更稳定且更有帮助。以场景文本识别为例,宽字符可能需要一些连续的帧来完全描述(参见图2)。此外,一些模糊的字符在观察其上下文时更容易区分,例如,通过对比字符高度更容易识别“il”而不是分别识别它们中的每一个。
- 其次,RNN可以将误差差值反向传播到其输入,即卷积层,从而允许我们在统一的网络中共同训练循环层和卷积层。
- 第三,RNN能够从头到尾对任意长度的序列进行操作。
传统的RNN单元在其输入和输出层之间具有自连接的隐藏层。
每次接收到序列中的帧 x t x_t xt时,它将使用非线性函数来更新其内部状态 h t h_t ht,该非线性函数同时接收当前输入 x t x_t xt和过去状态 h t − 1 h_{t−1} ht−1作为其输入: h t = g ( x t , h t − 1 ) h_t = g(x_t, h_{t−1}) ht=g(xt,ht−1)。那么预测 y t y_t yt是基于 h t h_t ht的。
以这种方式,过去的上下文 { x t ′ } t ′ < t \lbrace x_{t\prime} \rbrace _{t \prime < t} {xt′}t′<t被捕获并用于预测。
然而,传统的RNN单元有梯度消失的问题,这限制了其可以存储的上下文范围,并给训练过程增加了负担。
长短时记忆(LSTM)是一种专门设计用于解决这个问题的RNN单元。
- LSTM由一个存储单元和三个多重门组成,即输入,输出和遗忘门。
- 在概念上,存储单元存储过去的上下文,并且输入和输出门允许单元长时间地存储上下文。
- 同时,单元中的存储可以被遗忘门清除。LSTM的特殊设计允许它捕获长距离依赖,这经常发生在基于图像的序列中。

LSTM是定向的,它只使用过去的上下文。然而,在基于图像的序列中,两个方向的上下文是相互有用且互补的。将两个LSTM,一个向前和一个向后组合到一个双向LSTM中。深层结构允许比浅层抽象更高层次的抽象,并且在语音识别任务中取得了显著的性能改进。
在循环层中,误差在上图b所示箭头的相反方向传播,即反向传播时间(BPTT)。在循环层的底部,传播差异的序列被连接成映射,将特征映射转换为特征序列的操作进行反转并反馈到卷积层。实际上,我们创建一个称为“Map-to-Sequence”的自定义网络层,作为卷积层和循环层之间的桥梁。
2.3. 转录
转录是将RNN所做的每帧预测转换成标签序列的过程。数学上,转录是根据每帧预测找到具有最高概率的标签序列。
在实践中,存在两种转录模式,即无词典转录和基于词典的转录。
- 词典是一组标签序列,预测受拼写检查字典约束。
- 在无词典模式中,预测时没有任何词典。在基于词典的模式中,通过选择具有最高概率的标签序列进行预测。
2.3.1 标签序列的概率
我们采用Graves等人[15]提出的联接时间分类(CTC)层中定义的条件概率。按照每帧预测 y = y 1 , . . . , y T y=y_1,...,y_T y=y1,...,yT对标签序列 l l l定义概率,并忽略 l l l中每个标签所在的位置。因此,当我们使用这种概率的负对数似然作为训练网络的目标函数时,我们只需要图像及其相应的标签序列,避免了标注单个字符位置的劳动。
条件概率的公式简要描述如下:
- 输入是序列 y = y 1 , . . . , y T y = y_1,...,y_T y=y1,...,yT,其中 T T T是序列长度。这里,每个 y t ∈ ℜ ∣ L ′ ∣ y_t \in \Re^{|{ L}'|} yt∈ℜ∣L′∣是在集合 L ′ = L L' = L L′=L上的概率分布,
- 其中 L { L} L包含了任务中的所有标签(例如,所有英文字符),以及由-表示的“空白”标签。序列到序列的映射函数 B {B} B定义在序列 π ∈ L ′ T \boldsymbol{\pi}\in{L}'^{T} π∈L′T上,其中 T T T是长度。
- B {B} B将 π \boldsymbol{\pi} π映射到 l \mathbf{l} l上,首先删除重复的标签,然后删除blank。例如, B {B} B将“–hh-e-l-ll-oo–”(-表示blank)映射到“hello”。然后,条件概率被定义为由 B {B} B映射到 l \mathbf{l} l上的所有 π \boldsymbol{\pi} π的概率之和:
(1) p ( l ∣ y ) = ∑ π : B ( π ) = l p ( π ∣ y ) , p( \mathbf{l}| \mathbf{y})=\sum_{ \boldsymbol{ \pi}:{B}( \boldsymbol{ \pi})= \mathbf{l}}p( \boldsymbol{\pi}| \mathbf{y}),\tag{1} p(l∣y)=π:B(π)=l∑p(π∣y),(1)
π \boldsymbol{\pi} π的概率定义为 p ( π ∣ y ) = ∏ t = 1 T y π t t p(\boldsymbol{\pi}|\mathbf{y})=\prod_{t=1}{T}y_{\pi_{t}}{t} p(π∣y)=∏t=1Tyπtt, y π t t y_{\pi_{t}}^{t} yπtt是时刻 t t t时有标签 π t \pi_{t} πt的概率。由于存在指数级数量的求和项,直接计算方程1在计算上是不可行的。然而,使用[15]中描述的前向算法可以有效计算方程1。
2.3.2 无字典转录
在这种模式下,将具有方程1中定义的最高概率的序列 l ∗ \mathbf{l}{*} l∗作为预测。由于不存在用于精确找到解的可行方法,我们采用[15]中的策略。序列 l ∗ \mathbf{l}{*} l∗通过 l ∗ ≈ B ( arg max π p ( π ∣ y ) ) \mathbf{l}^{*}\approx{B}(\arg\max_{\boldsymbol{\pi}}p(\boldsymbol{\pi}|\mathbf{y})) l∗≈B(argmaxπp(π∣y))近似发现,即在每个时间戳 t t t采用最大概率的标签 π t \pi_{t} πt,并将结果序列映射到 l ∗ \mathbf{l}^{*} l∗。
2.3.3 基于词典的转录
在基于字典的模式中,每个测试采样与词典 D {D} D相关联。基本上,通过选择词典中具有方程1中定义的最高条件概率的序列来识别标签序列,即 l ∗ = arg max l ∈ D p ( l ∣ y ) \mathbf{l}^{*}=\arg\max_{\mathbf{l}\in{D}}p(\mathbf{l}|\mathbf{y}) l∗=argmaxl∈Dp(l∣y)。
然而,对于大型词典,例如5万个词的Hunspell拼写检查词典[1],对词典进行详尽的搜索是非常耗时的,即对词典中的所有序列计算方程1,并选择概率最高的一个。
为了解决这个问题,我们观察到, 2.3.2中描述的通过无词典转录预测的标签序列通常在编辑距离度量下接近于实际结果。 这表示我们可以将搜索限制在最近邻候选目标 N δ ( l ′ ) {N}_{\delta}(\mathbf{l}') Nδ(l′),其中 δ \delta δ是最大编辑距离, l ′ \mathbf{l}' l′是在无词典模式下从 y \mathbf{y} y转录的序列:
(2) l ∗ = arg max l ∈ N δ ( l ′ ) p ( l ∣ y ) . \mathbf{l}^{*}=\arg\max_{\mathbf{l}\in{N}_{\delta}(\mathbf{l}')}p(\mathbf{l}|\mathbf{y}).\tag{2} l∗=argl∈Nδ(l′)maxp(l∣y).(2)
可以使用BK树数据结构[9]有效地找到候选目标 N δ ( l ′ ) {N}_{\delta}(\mathbf{l}') Nδ(l′),这是一种专门适用于离散度量空间的度量树。BK树的搜索时间复杂度为 O ( log ∣ D ∣ ) O(\log|{D}|) O(log∣D∣),其中 ∣ D ∣ |{D}| ∣D∣是词典大小。
因此,这个方案很容易扩展到非常大的词典。在我们的方法中,一个词典离线构造一个BK树。然后,我们使用树执行快速在线搜索,通过查找具有小于或等于 δ \delta δ编辑距离来查询序列。
2.4. 网络训练
X = { I i , l i } i {X}= \left \{ I_i,\textbf{l}_i \right \} _i X={Ii,li}i表示训练集, I i I_{i} Ii是训练图像, l i \mathbf{l}_{i} li是真实的标签序列。目标是最小化真实条件概率的负对数似然:
(3) O = − ∑ I i , l i ∈ X log p ( l i ∣ y i ) , O=- \sum_{I_{i},\mathbf{l}_{i}\in{X}}\log p(\mathbf{l}_{i}|\mathbf{y}_{i}),\tag{3} O=−Ii,li∈X∑logp(li∣yi),(3)
y i \mathbf{y}_{i} yi是循环层和卷积层从 I i I_{i} Ii生成的序列。目标函数直接从图像和它的真实标签序列计算代价值。因此,网络可以在成对的图像和序列上进行端对端训练,去除了在训练图像中手动标记所有单独组件的过程。
网络使用随机梯度下降(SGD)进行训练。梯度由反向传播算法计算。特别地,在转录层中,如[15]所述,误差使用前向算法进行反向传播。在循环层中,应用随时间反向传播(BPTT)来计算误差。
为了优化,我们使用ADADELTA[37]自动计算每维的学习率。与传统的动量[31]方法相比,ADADELTA不需要手动设置学习率。更重要的是,我们发现使用ADADELTA的优化收敛速度比动量方法快。
4. 总结
在本文中,我们提出了一种新颖的神经网络架构,称为卷积循环神经网络(CRNN),其集成了卷积神经网络(CNN)和循环神经网络(RNN)的优点。
CRNN能够获取不同尺寸的输入图像,并产生不同长度的预测。它直接在粗粒度的标签(例如单词)上运行,在训练阶段不需要详细标注每一个单独的元素(例如字符)。
此外,**由于CRNN放弃了传统神经网络中使用的全连接层,因此得到了更加紧凑和高效的模型。**所有这些属性使得CRNN成为一种基于图像序列识别的极好方法。
在场景文本识别基准数据集上的实验表明,与传统方法以及其它基于CNN和RNN的算法相比,CRNN实现了优异或极具竞争力的性能。这证实了所提出的算法的优点。此外,CRNN在光学音乐识别(OMR)的基准数据集上显著优于其它的竞争者,这验证了CRNN的泛化性。
实际上,CRNN是一个通用框架,因此可以应用于其它的涉及图像序列预测的领域和问题(如汉字识别)。进一步加快CRNN,使其在现实应用中更加实用,是未来值得探索的另一个方向。
鸣谢与参考
References
http://mc.eistar.net/~xbai/
http://mc.eistar.net/~xbai/CRNN/crnn_code.zip
https://github.com/bgshih/crnn
https://github.com/Belval/CRNN
[1] http://hunspell.sourceforge.net/. 4, 5
[2] https://musescore.com/sheetmusic. 7, 8
[3] http://www.capella.de/us/index.cfm/products/capella-scan/info-capella-scan/. 8
[4] http://www.sibelius.com/products/photoscore/ultimate.html. 8
[5] J. Almaza ́n, A. Gordo, A. Forne ́s, and E. Valveny. Word spotting and recognition with embedded attributes. PAMI, 36(12):2552–2566, 2014. 2, 6, 7
[6] O. Alsharif and J. Pineau. End-to-end text recognition with hybrid HMM maxout models. ICLR, 2014. 6, 7
[7] Y. Bengio, P. Y. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. NN, 5(2):157–166, 1994. 3
[8] A. Bissacco, M. Cummins, Y. Netzer, and H. Neven. Photoocr: Reading text in uncontrolled conditions. In ICCV, 2013. 1, 2, 6, 7
[9] W. A. Burkhard and R. M. Keller. Some approaches to best-match file searching. Commun. ACM, 16(4):230–236, 1973.4
[10] R. Collobert, K. Kavukcuoglu, and C. Farabet. Torch7: A matlab-like environment for machine learning. In BigLearn, NIPS Workshop, 2011. 6
[11] F. A. Gers, N. N. Schraudolph, and J. Schmidhuber. Learning precise timing with LSTM recurrent networks. JMLR, 3:115–143, 2002. 3
[12] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014. 1, 3
[13] V. Goel, A. Mishra, K. Alahari, and C. V. Jawahar. Whole is greater than sum of parts: Recognizing scene text words. In ICDAR, 2013. 6, 7
[14] A. Gordo. Supervised mid-level features for word image representation. In CVPR, 2015. 2, 6, 7
[15] A. Graves, S. Ferna ́ndez, F. J. Gomez, and J. Schmidhuber. Connectionist temporal classification: labelling unseg- mented sequence data with recurrent neural networks. In ICML, 2006. 4, 5
[16] A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, and J. Schmidhuber. A novel connectionist system for unconstrained handwriting recognition. PAMI, 31(5):855–868, 2009. 2
[17] A. Graves, A. Mohamed, and G. E. Hinton. Speech recognition with deep recurrent neural networks. In ICASSP, 2013. 3
[18] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997. 3
[19] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015. 6
[20] M. Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman. Synthetic data and artificial neural networks for natural scene text recognition. NIPS Deep Learning Workshop, 2014. 5
[21] M. Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman. Deep structured output learning for unconstrained text recognition. In ICLR, 2015. 6, 7
[22] M. Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman. Reading text in the wild with convolutional neural networks. IJCV (Accepted), 2015. 1, 2, 3, 6, 7
[23] M. Jaderberg, A. Vedaldi, and A. Zisserman. Deep features for text spotting. In ECCV, 2014. 2, 6, 7
[24] D. Karatzas, F. Shafait, S. Uchida, M. Iwamura, L. G. i Bigorda, S. R. Mestre, J. Mas, D. F. Mota, J. Almaza ́n, and L. de las Heras. ICDAR 2013 robust reading competition. In ICDAR, 2013. 5
[25] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012. 1, 3
[26] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998. 1
[27] S. M. Lucas, A. Panaretos, L. Sosa, A. Tang, S. Wong, R. Young, K. Ashida, H. Nagai, M. Okamoto, H. Yamamoto, H. Miyao, J. Zhu, W. Ou, C. Wolf, J. Jolion, L. Todoran, M. Worring, and X. Lin. ICDAR 2003 robust reading competitions: entries, results, and future directions. IJDAR, 7(2-3):105–122, 2005. 5
[28] A. Mishra, K. Alahari, and C. V. Jawahar. Scene text recognition using higher order language priors. In BMVC, 2012. 5, 6, 7
[29] A. Rebelo, I. Fujinaga, F. Paszkiewicz, A. R. S. Marc ̧al, C. Guedes, and J. S. Cardoso. Optical music recognition: state-of-the-art and open issues. IJMIR, 1(3):173–190, 2012. 7
[30] J. A. Rodr ́ıguez-Serrano, A. Gordo, and F. Perronnin. Label embedding: A frugal baseline for text recognition. IJCV, 113(3):193–207, 2015. 2, 6, 7
[31] D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Neurocomputing: Foundations of research. chapter Learning Representations by Back-propagating Errors, pages 696–699. MIT Press, 1988. 5
[32] K. Simonyan and A. Zisserman. Very deep convolu- tional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014. 5
[33] B. Su and S. Lu. Accurate scene text recognition based on recurrent neural network. In ACCV, 2014. 2, 6, 7
[34] K. Wang, B. Babenko, and S. Belongie. End-to-end scene text recognition. In ICCV, 2011. 5, 6, 7
[35] T. Wang, D. J. Wu, A. Coates, and A. Y. Ng. End-to-end text recognition with convolutional neural networks. In ICPR, 2012. 1, 6, 7
[36] C. Yao, X. Bai, B. Shi, and W. Liu. Strokelets: A learned multi-scale representation for scene text recognition. In CVPR, 2014. 2, 6, 7
[37] M. D. Zeiler. ADADELTA: anadaptive learning rate method. CoRR, abs/1212.5701, 2012. 5
https://www.jianshu.com/p/14141f8b94e5