数据库和缓存双写一致性方案
常用的缓存策略
通常我们使用数据库和缓存的套路是这样的。
查询
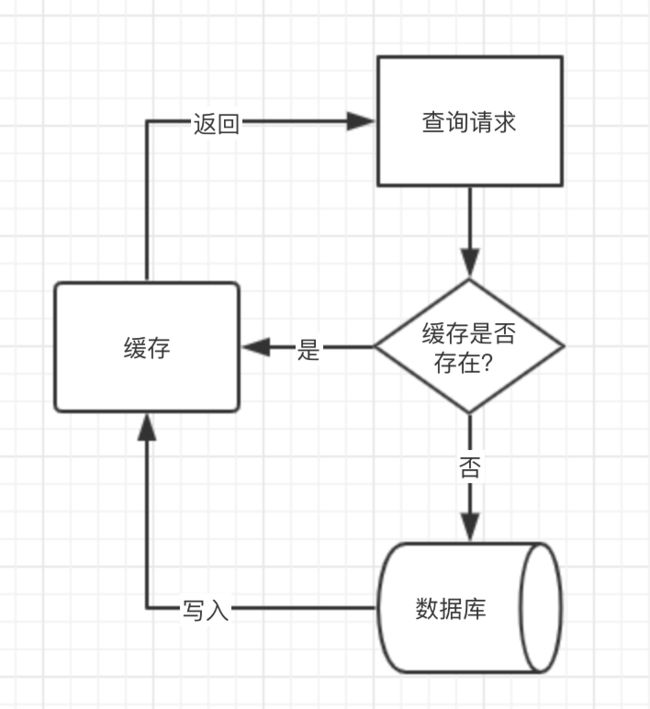
- 先查询缓存,如果命中直接返回
- 如果未命中缓存,则查询数据库,并放入缓存。
代码实例:
public String select(Integer key) {
// 从redis中获取数据
String redisStr = getRedisStr(key);
if (StringUtils.isNotEmpty(redisStr)) {
log.info("【demo查询】从缓存中获取数据【{}】", redisStr);
return redisStr;
}
log.info("【demo查询】缓存中未获取到数据【{}】", redisStr);
String s = gasMapper.selectName(key);
if (StringUtils.isEmpty(s)) {
return s;
}
setRedis(key, s, EXPIRE_TIME);
log.info("【demo查询】存入缓存key【{}】,value【{}】", getKey(key), s);
return s;
}
更新
更新策略则有很多版本,大体可以总结为以下三种:
- 方案一:先更新数据库,再更新缓存
- 方案二:先清除缓存,再更新数据库
- 方案三:先更新数据库,再清除缓存
分析三种方案的利弊
先更新数据库,再更新缓存
假设我们有这么一个场景:
- 线程A更新数据库。如:
update table set name = '线程-A' where id = 5 - 线程B更新数据库。如:
(update table set name = '线程-B' where id = 5) - 线程B更新缓存 。如:
(set 5 '线程-B') - 线程A更新缓存 。如:
(set 5 '线程-A')
【方案一代码实例】
public void updateOptionOne(Integer key, String value) {
// 1. 更新数据库
gasMapper.updateName(key, value);
String name = Thread.currentThread().getName();
if (name.equals("线程-A")) {
try {
Thread.sleep(1000);
log.info("【方案一更新方式】模拟线程阻塞,线程名【{}】",name);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 2. 更新缓存
setRedis(key, value, EXPIRE_TIME);
}
【测试用例】
@Test
public void optionOneTest() {
Integer key = 27388;
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread threadA = new Thread(() -> {
demoService.updateOptionOne(key, "线程-A");
countDownLatch.countDown();
});
threadA.setName("线程-A");
threadA.start();
Thread threadB = new Thread(() -> {
demoService.updateOptionOne(key, "线程-B");
countDownLatch.countDown();
});
threadB.setName("线程-B");
threadB.start();
try {
countDownLatch.await();
String s = gasMapper.selectName(key);
String cacheValue = demoService.getCacheValue(key);
System.out.printf("从数据库中获取的数据:" + s + "\n从缓存中获取的数据:" + cacheValue);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
【执行结果】:

【结论】这种场景存在以下两种弊端:
- 写入不一致
因为两个线程都是写入操作,在某一时刻会出现线程B的操作比A快。这样就会导致,数据库中name=‘线程-B’,而缓存中数据value=‘线程-B’,并且每次都会返回value=‘线程-A’。出现数据写入不一致问题。
- 占用缓存资源
如果该数据不是热点数据,每次修改完数据库,就放入缓存。会占用缓存资源。
先清除缓存,再更新数据库
假设有以下这一种场景:
- 线程A清除缓存。如:
(del 5) - 线程B没有命中缓存,查询数据。如:
(select name from table where id = 5)-> ‘旧值’ - 线程B将旧值写入缓存。如:
(set A = ‘旧值’) - 线程A将新值写入数据库。如:
(update table set name = '线程-A' where id = 5)
【方案二代码实例】
public void updateOptionTwo(Integer key, String value) {
// 1. 清除缓存
removeRedis(String.valueOf(key));
try {
log.info("【方案二更新方式】模拟线程阻塞,线程名【{}】",Thread.currentThread().getName());
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 2. 更新数据库
gasMapper.updateName(key, value);
}
【测试用例】
@Test
public void optionTwoTest() {
Integer key = 27388;
try {
// 等待环境配置加载完毕
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread threadA = new Thread(() -> {
demoService.updateOptionTwo(key, "线程-A");
countDownLatch.countDown();
});
threadA.setName("线程-A");
threadA.start();
Thread threadB = new Thread(() -> {
demoService.select(key);
countDownLatch.countDown();
});
threadB.setName("线程-B");
threadB.start();
try {
countDownLatch.await();
String s = gasMapper.selectName(key);
String cacheValue = demoService.getCacheValue(key);
System.out.printf("从数据库中获取的数据:" + s + "\n从缓存中获取的数据:" + cacheValue);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
【执行结果】

【结论】
因为线程B的查询操作可能比线程A的写入操作快,所以会出现读写并发导致的数据库与缓存不一致问题。
先更新数据库,再清除缓存
假设有以下这种场景:
- 线程B没有命中缓存,查询数据库。如:
(select name from table where id = 5)-> name = ‘旧值’ - 线程A写入数据库 。如
(update table set name = '线程-A' where id = 5) - 线程A清除缓存 。如
(del 5) - 线程B将旧值写入缓存。如
(set 5 '旧值')
【方案三代码实例】
public String select(Integer key) {
// 从redis中获取数据
String redisStr = getRedisStr(key);
if (StringUtils.isNotEmpty(redisStr)) {
log.info("【demo查询】从缓存中获取数据【{}】", redisStr);
return redisStr;
}
log.info("【demo查询】缓存中未获取到数据【{}】", redisStr);
String s = gasMapper.selectName(key);
if (StringUtils.isEmpty(s)) {
return s;
}
try {
log.info("【方案三查询方式】模拟线程阻塞,线程名【{}】", Thread.currentThread().getName());
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
setRedis(key, s, EXPIRE_TIME);
log.info("【demo查询】存入缓存key【{}】,value【{}】", getKey(key), s);
return s;
}
public void updateOptionThree(Integer key, String value) {
try {
log.info("【方案三查询方式】模拟线程阻塞,线程名【{}】晚执行一会儿", Thread.currentThread().getName());
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 1. 更新数据库
gasMapper.updateName(key, value);
// 2. 清除缓存
removeRedis(String.valueOf(key));
}
【测试用例】
@Test
public void optionThreeTest() {
Integer key = 28523;
try {
// 等待环境配置加载完毕
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread threadB = new Thread(() -> {
demoService.select(key);
countDownLatch.countDown();
});
threadB.setName("线程-B");
threadB.start();
Thread threadA = new Thread(() -> {
demoService.updateOptionThree(key, "线程-A");
countDownLatch.countDown();
});
threadA.setName("线程-A");
threadA.start();
try {
countDownLatch.await();
String s = gasMapper.selectName(key);
String cacheValue = demoService.getCacheValue(key);
System.out.printf("从数据库中获取的数据:" + s + "\n从缓存中获取的数据:" + cacheValue);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
【执行结果】
[updateOptionThree]【方案三查询方式】模拟线程阻塞,线程名【线程-A】晚执行一会儿
[select]【demo查询】缓存中未获取到数据【null】
[select]【方案三查询方式】模拟线程阻塞,线程名【线程-B】
[select]【demo查询】存入缓存key【privilege:demo:28523】,value【旧值】

【结论】
这种场景一般出现在,线程B查询数据库的操作比线程A的写入操作还要慢,导致数据库和缓存不一致。但是,通常数据库的查询操作要比写入快很多,所以是一种小概率的异常场景。
引入队列解决双写不一致问题
方案三已经可以避免90%以上双写不一致的问题。但是,还是会有一些特殊场景会产生数据不一致的bug。那么如何解决这种场景下的不一致问题呢?
这时候,我首先想到使用队列来解决。

操作步骤如下所描述
- 读请求查询缓存,如果未命中,则写入队列。
- 读请求将查询结果写入缓存,并清除队列中的值。
- 写请求检测队列是否存在值,如果存在,等待步骤2执行完成。
- 写请求写入数据库
- 写请求清除缓存中的值
【引入队列的代码实例】
public void updateByQueue(Integer key, String value) {
// 1. 判断队列是否存在key,存在则一直等待
while (StringUtils.isNotEmpty(queueMap.get(key))) {
log.info("【引入队列】存在正在查询key的方法,等待...");
}
updateOptionThree(key, value);
}
public String select(Integer key) {
// 从redis中获取数据
String redisStr = getRedisStr(key);
if (StringUtils.isNotEmpty(redisStr)) {
log.info("【demo查询】从缓存中获取数据【{}】", redisStr);
return redisStr;
}
log.info("【demo查询】缓存中未获取到数据【{}】", redisStr);
// 待查询的值加入队列
queueMap.put(key,"AAA");
String s = gasMapper.selectName(key);
if (StringUtils.isEmpty(s)) {
return s;
}
try {
log.info("【方案三查询方式】模拟线程阻塞,线程名【{}】", Thread.currentThread().getName());
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
setRedis(key, s, EXPIRE_TIME);
// 清除队列中的值
queueMap.remove(key);
log.info("【demo查询】存入缓存key【{}】,value【{}】", getKey(key), s);
return s;
}
【测试用例】
@Test
public void updateByQueueTest() {
Integer key = 28523;
try {
// 等待环境配置加载完毕
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread threadB = new Thread(() -> {
demoService.select(key);
countDownLatch.countDown();
});
threadB.setName("线程-B");
threadB.start();
Thread threadA = new Thread(() -> {
demoService.updateByQueue(key, "线程-A");
countDownLatch.countDown();
});
threadA.setName("线程-A");
threadA.start();
try {
countDownLatch.await();
String s = gasMapper.selectName(key);
String cacheValue = demoService.getCacheValue(key);
System.out.printf("从数据库中获取的数据:" + s + "\n从缓存中获取的数据:" + cacheValue);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
【执行结果】

引入队列可以保证缓存和数据库的写入一致性
参考文献
https://coolshell.cn/articles/17416.html
https://www.cnblogs.com/rjzheng/p/9041659.html