android,java知识点总结(一)
List ,HashMap ,set ,HashTable ,eventBus ,LitPal ,OkHttp ,Glide ,热修复,线程安全,线程池,6.0以及5.0权限管理,7.0分屏画中画;材料设计语言,蓝牙,wifi,ViewDrapHelper,动画,排序,RandomAccess,Rxjava,注解,设计模式。类设计,项目结构设计。功能设计。泛型数据结构。SqlLiteOpenHelper。内存泄漏。adb命令等等
1、使用aapt进行apk信息的查看
aapt dump dadging 跟上apk路径
(必须要注意要配置aapt 环境变量)2、特殊字符在string.xml中需要进行转义
一般需要注意的就是< 、> 、@,?等等
可以使用
也可以是使用 \ ,使用
比如颜文字
<string-array name="emoji_array">
<item>⊙▽⊙item>
<item> ( ؕؔʘ̥̥̥̥ ه ؔؕʘ̥̥̥̥ )? item>
<item>( •̅_•̅ ) item>
<item><MSGCONTENT>" ]]>MSGCONTENT>item>
<item>(๑ ̄ ̫  ̄๑) item>
<item>눈_눈 item>
<item>ᕙ(⇀‸↼‵‵)ᕗitem>
<item> ( ・᷄ ᵌ・᷅ ) item>
<item>(৹ᵒ̴̶̷᷄﹏ᵒ̴̶̷᷅৹) item>
<item>( ˉ ⌓ ˉ ๑) item>
<item> o(〃\'▽\'〃)o item>
<item>₍₍ (̨̡ ‾᷄ᗣ‾᷅ )̧̢ ₎₎ item>
<item>( ¬_¬) item>
<item>( ゚皿゚) item>
<item>(▭-▭)✧ item>
<item>π_π item>
<item>(¬ω¬) item>
<item>(。•ˇ‸ˇ•。)item>
<item>(。・ω・。)ノ♡item>
<item>ू(ʚ̴̶̷́ .̠ ʚ̴̶̷̥̀ ू)item>
<item>ლ(●ↀωↀ●)ლitem>
<item>(ノ ̄д ̄)ノitem>
<item>⸂⸂⸜(രᴗര๑)⸝⸃⸃item>
<item>-_-||item>
<item>ɿ(。・ɜ・)ɾitem>
<item>p(´⌒`。q)item>
<item>⊙ω⊙item>
<item>ꉂ ೭(˵¯̴͒ꇴ¯̴͒˵)౨”item>
<item>(ღ˘⌣˘ღ)item>
<item>→_→ item>
<item>〜( ̄△ ̄〜)item>
<item>←_←item>
<item>؏؏☝ᖗ乛◡乛ᖘ☝؏؏item>
<item>\@_@item>
<item>(^3^)item>
<item>≥﹏≤item>
<item>^ω^item>
<item>^_^item>
<item>\^O^/item>
<item>T_Titem>
<item>◑▂◐item>
<item>-_-#item>
string-array>
3、android EditText
在获取到焦点的时候就会弹出软键盘,然后是不会执行onClick方法的,因为第一次点击如果是没有获取到焦点的话首先会获取焦点,然后下一次点击才会执行onCLick,如果需要首先执行onCLick的话,那么就要在布局中设置
android:clickable="true"
android:focusableInTouchMode=“false"
然后点击的时候会执行onClick,然后在里边可以设置
mEditText.setFocusable(true);
mEditText.setFocusableInTouchMode(true);
mEditText.requestFocus();
mEditText.requestFocusFromTouch();
然后就可以获取到焦点,然后在做软键盘的弹出4、EditText 添加onScrollListener
只在5.0以上(不包括5.0)有这个方法,必须要保证最小编译版本在23
5、关于List源码学习:
List 是一个接口,它继承了Collection接口,Collection继承了Iterable接口,
Iterable里边定义了Iterator,foreach,spliterator这么三个方法
Collection继承了以后在里边添加了add ,remove,clear,hashCode,equals,spliterator,retainAll,
addAll,removeAll,toArray,containsAll,contains等方法
List在继承了以后添加了get,set,indexOf,lastIndexOf,listIterator,subList,replaceAll,sort这几个方法。
我们在使用List的时候都是使用它的实现类ArrayList,LinkedList,Vector。
ArrayList的实现:
在实现了List接口以后我们会重写里边所有的方法,然后实现对应的功能,
ArrayList还继承了AbstracList这个抽象类,这个类继承自AbstractCollection,然后实现了List接口(抽象类的主要作用就是实现共有部分功能)
但是大部分功能都是在ArrayList中进行的实现。
ArrayList提供了三个构造方法
1、默认的无参构造方法,默认长度为10
public ArrayList() {
super();
this.elementData = EMPTY_ELEMENTDATA;
}2、指定集合长度
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}3、以集合为参数
public ArrayList(Collection c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
其中的elementData是一个object类型的数组,用来存放集合中的元素。
集合默认长度为10,如果要添加的元素超过了这个长度就会进行扩容,
调用ensureCapacity,ensureExplicitCapacity,ensureExplicitCapacity,grow()
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
最后是通过Arrays的copyOf方法复制一个新的长度为newCapacity的数组,新的长度就等于老的长度除以2 + 老的长度,然后在进行下边的判断计算最终的长度。
所以从这些流程可以看到ArrayList在数据频繁添加的过程中会有频繁的扩容操作,因为会有数组的copy过程,如果数据量很大的时候会影响性能,最后是能确定他的最终大小,在初始化的时候直接申请。
而且ArrayList是基于数组来进行数据元素的存储,所以在插入的过程中都会有元素的移动,插入速度相当慢。
查询
6 、adb monkey
首先确保android的adb命令是ok的。
然后就是monkey命令的参数说明。
adb shell 进入手机命令行
然后就可以执行 monkey 看到 monkey的参数说明
shell@PD1624:/ $ monkey
usage: monkey [-p ALLOWED_PACKAGE [-p ALLOWED_PACKAGE] ...]
[-c MAIN_CATEGORY [-c MAIN_CATEGORY] ...]
[--ignore-crashes] [--ignore-timeouts]
[--ignore-security-exceptions]//忽略安全检查
[--monitor-native-crashes] [--ignore-native-crashes] //忽略native 异常
[--kill-process-after-error]//发生错误时杀掉进程
[--hprof] //生成hprof文件
[--pct-touch PERCENT] [--pct-motion PERCENT]//该种类型事件的百分比
[--pct-trackball PERCENT]//轨迹球的事件百分比
[--pct-syskeys PERCENT]//系统事件百分比
[--pct-nav PERCENT] [--pct-majornav PERCENT]
[--pct-appswitch PERCENT] [--pct-flip PERCENT]
[--pct-anyevent PERCENT] [--pct-pinchzoom PERCENT]
[--pct-permission PERCENT]
[--pkg-blacklist-file PACKAGE_BLACKLIST_FILE]//黑名单
[--pkg-whitelist-file PACKAGE_WHITELIST_FILE]//白名单
[--wait-dbg] [--dbg-no-events]
[--setup scriptfile] [-f scriptfile [-f scriptfile] ...]
[--port port]
[-s SEED] //设置随机种子数,如果俩次seed值相同,那么对于同一事件那么执行的结果完全相同
[-v [-v] ...]
作用:命令行上的每一个-v都将增加反馈信息的详细级别。
Level0(默认-v),除了启动、测试完成和最终结果外只提供较少的信息。
Level1(-v -v),提供了较为详细的测试信息,如逐个发送到Activity的事件信息。
Level2(-v -v -v),提供了更多的设置信息,如测试中选中或未选中的Activity信息。
[--throttle MILLISEC] [--randomize-throttle]//事件的延迟时间(这个时间设置了以后不是特别准备,如果需要确定要跑多久的monkey的话需要计算执行一次时间所花费的时间,然后用时间除以一个事件的时长算出要执行的次数)
[--profile-wait MILLISEC]
[--device-sleep-time MILLISEC]//设备睡眠事件
[--randomize-script] //随机脚本
[--script-log]//脚本log
[--bugreport]//bug报告
[--periodic-bugreport]//定期bug报告
[--permission-target-system]
COUNT //数量
>> 使用这个命令输出monkey日志到目标地址的文件中(这个不是monkey命令,是命令统一的输出方式)从上边可以发现一个monkey命令的完整写法
- 简单的命令: monkey -v -p com.android.bluetooth 200
-v log级别
-p 后边跟包名
200 就是要执行事件的次数
这就是一个简单的monkey测试 - monkey -v -p com.guoyi.qinghua –pct-majornav 20 –monitor-native-crashes –ignore-security-exceptions –ignore-crashes –ignore-timeouts –kill-process-after-error -s 220 –throttle 300 500000 >> ../monkey.txt
- 因为monkey在测试过程中事件的延迟时间(这个时间设置了以后不是特别准确,如果需要确定要跑多久的monkey的话需要计算执行一次时间所花费的时间,然后用时间除以一个事件的时长算出要执行的次数)
如果–throttle 1000 ,那么计算次数的方式
count= (时长 单位毫秒)/(一次事件的时间)
monkey -v -v -v -p com.xxxx.xxx –throttle 1000 count
7、关于进入手机设置界面
可以通过抓包来获取当前ActivityManager来获取,当前跳转的activity的信息。下边是adb 命令
adb logcat | grep ActivityManager
进入系统设置的所有界面都可以通过Intent
只要设置不同的Settings就可以
Intent appIntent = new Intent();
appIntent = new Intent(Settings.ACTION_SETTINGS);
context.startActivity(appIntent);只要替换Settings的值就可以,
如果要进入其中一个应用的详情设置了Settings以后的话还需要传递包名
appIntent.setData(Uri.parse("package:" + context.getPackageName()));但是android系统没有专门的权限管理。
如果要进入权限管理必须要对不同系统进行区别,然后根据不同的定制系统来进行处理跳转。
//vivo权限管理界面
appIntent.setClassName("com.iqoo.secure", "com.iqoo.secure.safeguard.PurviewTabActivity");
然后可以通过adb 命令来启动一个页面
db shell am start -n com.android.settings/com.letv.leui.settings.LeUIMainSettings
8、关于EventBus源码学习
EventBus 的学习首先从 EventBus这个类开始。
这个类主要是用来进行EventBus的初始化,注册反注册,发送事件或者移除事件,是整个工具所暴露的可以进行操作的一个工作接口。
EventBus在初始化上边有俩种方式:
(1)、通过getDefault()
(2)、通过new EventBus()
但是实际创建方式都是通过Builder(建造者模式来进行创建)
跟所有的建造者模式一样,都是通过一个私有的构造方法以EventBusBuilder对象为参数来进行对象的创建。
然后调用register来进行注册。在调用register这个方法的时候会传递一个要注册的对象的。
然后会通过反射来获取这个对象中的所有的方法。然后会通过方法来找到其中订阅了EventBus的事件的方法。然后通过subscribe这个方法,把这些方法添加到订阅列表中。
public void register(Object subscriber) {
Class subscriberClass = subscriber.getClass();
List subscriberMethods = subscriberMethodFinder.findSubscriberMethods(subscriberClass);
synchronized (this) {
for (SubscriberMethod subscriberMethod : subscriberMethods) {
subscribe(subscriber, subscriberMethod);
}
}
} 反注册的流程与一般的订阅者都是一样的,把订阅的方法都从订阅队列进行删除。
剩下的就是事件的发送:
因为整个EventBus的架构就是观察者模式。
所以事件发送其实就是通过EventBus对象对所有订阅了这个事件的订阅者进行通知,然后在他订阅的方法里边就可以进行处理。
public void post(Object event) {
PostingThreadState postingState = currentPostingThreadState.get();
List然后postSingleEvent ->postSingleEventForEventType->postToSubscription 然后执行真正的事件发送。
private void postToSubscription(Subscription subscription, Object event, boolean isMainThread) {
switch (subscription.subscriberMethod.threadMode) {
case POSTING:
invokeSubscriber(subscription, event);
break;
case MAIN:
if (isMainThread) {
invokeSubscriber(subscription, event);
} else {
mainThreadPoster.enqueue(subscription, event);
}
break;
case BACKGROUND:
if (isMainThread) {
backgroundPoster.enqueue(subscription, event);
} else {
invokeSubscriber(subscription, event);
}
break;
case ASYNC:
asyncPoster.enqueue(subscription, event);
break;
default:
throw new IllegalStateException("Unknown thread mode: " + subscription.subscriberMethod.threadMode);
}
}说是发送,其实是通过反射来调用被订阅的方法。(只要我们能拿到被订阅的方法所在的类的对象,就可以执行他里边的方法)
也就是通过EventBus中的invokeSubscriber方法
void invokeSubscriber(PendingPost pendingPost) {
Object event = pendingPost.event;
Subscription subscription = pendingPost.subscription;
PendingPost.releasePendingPost(pendingPost);
if (subscription.active) {
invokeSubscriber(subscription, event);
}
}void invokeSubscriber(Subscription subscription, Object event) {
try {
subscription.subscriberMethod.method.invoke(subscription.subscriber, event);
} catch (InvocationTargetException e) {
handleSubscriberException(subscription, event, e.getCause());
} catch (IllegalAccessException e) {
throw new IllegalStateException("Unexpected exception", e);
}
}还有些要注意的类,就是HandlerPoster,这个类主要是维护了一个队列,用来管理要发送的事件。他的内在实现其实是通过Handler来进行的。handler就不需要多说了。
AsyncPoster 异步Poster,通过实现Runnable,通过ExectorService 进行线程管理。
BackgroundPoster后台Poster,通过实现Runnable进行实现,通过ExectorService 进行线程管理。
它使用的是Executors.newCachedThreadPool创建的缓存线程池。具体什么事缓存线程池可以看相关的文章。
private final static ExecutorService DEFAULT_EXECUTOR_SERVICE = Executors.newCachedThreadPool();总结:
**EventBus的整体架构是通过 观察者模式来进行事件的订阅,然后在订阅的事件发生了改变以后通知所有的订阅者。在这个过程中使用到了反射来进行。在订阅的时候通过反射获取到当前对象所定于的方法,在有改变的通过反射执行被订阅的方法,然后就可以处理自己的逻辑。
在发送事件的时候(post)我们会判断当前事件是在什么线程中执行。然后做相应的处理。
对与事件处理主要使用了Handler(初始化的时候默认是主线程Handler),
使用线程池进行事件的管理。
里边用到了多线程的并发处理:使用ThreadLocal ,CopyOrWriteArrayList;synchronized。
ThreadLocal 会为每一个线程创建一个副本对象,CopyOrWirteArrayList是通过copy一份数据,然后在Write的时候通过创建一个新的对象,然后对新的对象进行write,然后把新对象赋值给旧对象来保证线程安全。读取的时候通过使用旧的对象来进行,因为读取是不需要关注线程安全问题。
synchronized同步锁,只有持有这个方法的所的对象才能进入这个方法,其他的都要等待。**
9、关于RecycleView的使用
使用RecyvleView的方式很简单,跟使用ListView,GridView类似,只是RecycleView可以实现比这俩个控件更多的功能。只要通过LayoutManager进行设置。
RecycleView没有onItemClickListener,需要自己实现。
RecycleView 如果有错位的问题,那么肯定也是跟ListView一样因为复用引起的,其实修改原理都类似。个人觉得只要把复用的View里边的参数都还原成最初的状态(如果view成为最原始的状态,那么只要数据没有问题,就不会有错位的事了),然后通过tag来进行判断,然后在更新View即可。
RecycleView的adapter里边强制使用VIewHolder。为了减少重复创建对象的消耗(主要是会影响性能)。
RecycleView 滚动条的设置使用的是View的通用滚动条设置。
android:scrollbars=“horizontal" //设置滚动条的方向
android:scrollbarAlwaysDrawHorizontalTrack=“true" //设置总是绘制横向滚动条
android:scrollbarThumbHorizontal=“@drawable/scrollbar_line”//横向滚动条
android:scrollbarTrackHorizontal=“@drawable/scrollbar_line_track”//横向滚动条的轨道
android:paddingBottom="20dp"
android:scrollbarStyle=“outsideInset" //设置显示的位置
android:fadeScrollbars=“false" //是否一直显示如果要设置不一样粗细的滚动条与轨道,可以通过使用不同粗细的进度图片来实现,也可以通过
使用shape来自定义滚动条与轨道,自定义的时候滚动条的高度要比轨道的高,这样横向滚动条与轨道就会不一样粗细。
10、fresco是一个很强大的图片加载库,不同的功能都有相对应的库模块来处理。
11、android中点击电源键关闭屏幕的话。
如果现在屏幕是竖屏没有任何影响,如果是横屏,会销毁activity,然后在启动这个Activity 。会导致activity数据的丢失。如果只是数据可以通过onSaveInstance进行保存,但是如果正在进行通话或者长连接的功能,会导致功能中断。
解决方式:
1、使屏幕常亮
2、设置activity的
android:configChanges=“orientation|keyboardHidden|screenSize"12、jni 编译 :
(1)首先项目的sdk地址
创建native方法,然后点击studio的make project生成class文件
(2)然后切换到项目package目录下 (例如 com.xxx.xxx.xx)
调用 javaH -d ../jni “包名 + 类名”
然后会在jni文件夹下生成.h头文件。
然后创建c或c++文件,进行代码的编写,可以直接复制头文件到c或c++文件中。
提供的头文件里边的参数需要自定义名称。是一个空的实现。
(3)配置app.gradle文件
ndk {
moduleName"jnilib"
ldLibs "log", "z", "m"
abiFilters "armeabi", "armeabi-v7a", "x86"
}如果不知道studio支持的ndk可编译版本可以在gradle.properties添加
android.useDeprecatedNdk=true//可使用过时版本
(如果使用studio编译以后运行出现dlopen failed: cannot locate symbol “__aeabi_memcpy” referenced by “/data/app/com.example.chenpengfei.uninstallreceiver-2/lib/arm/libjnilib.so”,那么是因为sdk版本的问题,23及以下,或者更新studio到最新版本)
13、LinkedList源码学习:
关于LinkedList 类的功能来说,也是一个集合容器类,实现了List接口,但是他内部的数据结构跟ArrayList不一样,使用的是链表。而实现链表主要是通过Node这个类。
他继承了AbstractSequentialList,而这个类其实是继承了AbstractList。
他与ArrayList不一样的就是他实现了Deque接口。
因为它是基于Node实现的列表,那么需要关注的就是Node这个类
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
这个类会保存它上一个节点node,跟下一个节点node。
如果是有俩个节点那么a 节点的next指向b节点 ,pre也指向b,b的pre指向a,next也指向a,这样就形成了一个闭环。实现了双向链表。
如果是三个的话 a 节点的next 指向b ,pre指向c,b 节点的next 指向c,pre指向a,而c节点的next指向a,pre指向b。这样也是一个闭环。
所以LinkedList存储数据的时候特别快。直接把节点的指向改变了就可以了。
但是存储的时候也分几种情况:
如果是直接添加的话不管是添加到首部还是尾部都直接修改节点指向,但是如果是指定下标来进行添加的话,会折半查找到下边的node节点,然后在该节点处修改节点指向。速度会慢点。
但是查询的时候就需要类似上边的折半以后进行查找,然后返回该节点。速度就会比ArrayList慢很多。毕竟人家是实现了RendemAsscess接口,而且内部结构是array,查询没的比啊。
14、Vector源码学习
通过学习ArrayList 与LinkedList以后在学习Vector发现没有太多要注意的地方。
因为Vector是跟ArrayList基本上完全相同的,只是在某些地方有点区别。
Vector是线程安全的,在很多方法上都加了线程锁,synchronize,实现同步。内部结构完全就是ArrayList的结构,只是在容量扩展的时候
这是Vecctor的容量扩展
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}这是ArrayList的容量扩展
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
可以发现在进行容量扩展的时候 newCapacity的值在取值的时候有点区别
ArrayList是直接扩展为原来容量的3/2,但是Vector因为有 一个容量扩充的参数capacityIncrement
,如果不为0,那么每次扩展是在原来的基础上增加capacityIncrement的长度,否则就是原来的2倍。
因为跟ArrayList很相似,学习的过程中发现比较一下这几个实现了List接口的类更有用:
ArrayList、Vecotr、LinkedList的区别(源码角度):
区别:
1、
ArrayList、Vector使用的是数组的数据结构来进行数据的存储,实现了RandomAccess接口提供快速随机访问。 而LinkedList是通过链表这样的数据接口来存储数据,他实现了Deque接口,在随机访问方面性能很差,因为需要遍历这个链表中的节点(虽然是折半以后的遍历,但是一样很慢)
2、
容量扩展对于LinkedList来说是没有任何关系的,因为它不需要。但是对于ArrayList于Vector来说这是很重要的点。因为他们的初始容量都是10,除非你指定了他的容量。但是在把数据进行添加的过程中,他们会检查容量是否足够存放数据,如果不够就要进行容量的扩展。容量的扩展是通过创建一个新的容量的数组,然后指向上一个数组对象,创建的方式是调用一个系统的arrayCopy方法。
数据量很大的话对与性能有很大影响,使用的时候根据需要可以指定初始容量。
这就是他们之间的又一个不同点,插入效率,很明显LinkedList很快,但是Vector与ArrayList很慢
Android 虚拟现实开发
开发者中心地址:https://vr.google.com/daydream/developers/
按需要下载自己需要的sdk已经开发工具
15、HashMap源码学习
HashMap是一个存储键值对的容器类,通过学习他的源码来熟悉他的实现。
首先说下HashMap 1.8之前,最基本的实现是通过维护一个Entry[]的数组已经单链表来实现的数据存储。
就是当我们在创建一个HashMap以后,通过调用put方法,会进行很多判断,最后把我们要存放的数据添加到Entry[]数组中。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
// 得到key的哈希码
int hash = hash(key);
// 通过哈希码计算出bucketIndex
int i = indexFor(hash, table.length);
// 取出bucketIndex位置上的元素,并循环单链表,判断key是否已存在
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
// 哈希码相同并且对象相同时
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 新值替换旧值,并返回旧值
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// key不存在时,加入新元素
modCount++;
addEntry(hash, key, value, i);
return null;
} 但是在1.8以后,为了实现快速查找,添加了红黑树。里边维护的数组变为了Node[]数组,一个实现Map.Entry接口的类。这应该是1.8改动最大的地方。
1 public V put(K key, V value) {
2 // 对key的hashCode()做hash
3 return putVal(hash(key), key, value, false, true);
4 }
5
6 final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
7 boolean evict) {
8 Node[] tab; Node p; int n, i;
9 // 步骤①:tab为空则创建
10 if ((tab = table) == null || (n = tab.length) == 0)
11 n = (tab = resize()).length;
12 // 步骤②:计算index,并对null做处理
13 if ((p = tab[i = (n - 1) & hash]) == null)
14 tab[i] = newNode(hash, key, value, null);
15 else {
16 Node e; K k;
17 // 步骤③:节点key存在,直接覆盖value
18 if (p.hash == hash &&
19 ((k = p.key) == key || (key != null && key.equals(k))))
20 e = p;
21 // 步骤④:判断该链为红黑树
22 else if (p instanceof TreeNode)
23 e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
24 // 步骤⑤:该链为链表
25 else {
26 for (int binCount = 0; ; ++binCount) {
27 if ((e = p.next) == null) {
28 p.next = newNode(hash, key,value,null);
//链表长度大于8转换为红黑树进行处理
29 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
30 treeifyBin(tab, hash);
31 break;
32 }
// key已经存在直接覆盖value
33 if (e.hash == hash &&
34 ((k = e.key) == key || (key != null && key.equals(k)))) break;
36 p = e;
37 }
38 }
39
40 if (e != null) { // existing mapping for key
41 V oldValue = e.value;
42 if (!onlyIfAbsent || oldValue == null)
43 e.value = value;
44 afterNodeAccess(e);
45 return oldValue;
46 }
47 }
48 ++modCount;
49 // 步骤⑥:超过最大容量 就扩容
50 if (++size > threshold)
51 resize();
52 afterNodeInsertion(evict);
53 return null;
54 } 跟所有的容器类一样,这个类里边也定义size, modcout,loadFactor(负载因子),threshold(判断是否需要扩展的界限 他的值等于初始容量乘以 负载因子),默认的初始容量是 1<< 4 ,
Hash主要是通过散列表来进行存储,通过计算key的hash值,然后计算要存放的下标,然后放到数组中对应的位置。如果计算出来的hash相同,那么比较key是否相等,如果相等,那么久覆盖旧值,返回旧值,如果不相同,那么创建Node对象,然后与该位置中的Node链表进行连接,使Node链表的最新的节点是新创建的Node对象。
HashMap的扩容是扩容为 原来的2倍。
因为HashMap是通过散列表来进行存储,所以会有空间的浪费,也就是用空间换取时间。
查找的时候通过计算key的hash值,然后计算在数组中的下标,可以快速的进行查找。
HashMap中使用链表主要是为了解决碰撞问题,也就是会有相同的Hash值的问题。
16、HashSet源码:
HashSet用来存放单一数据,不在是键值对,而且存储到其中的数据没有顺序,但是他可以保证数据不会重复(前提是你要重新hashCode 以及equals方法)。
因为HashSet的底层实现是通过HashMap来进行实现的。通过他的构造方法可以看到:
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(Collection c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet() {
map = new HashMap<>();
}如果对HashMap源码了解的话很简单就可以看懂。
HashSet提供了add方法进行数据的添加,也提供了容器类基本的功能。
比如删除,是否包含,是否为空等等。
使用HashSet的时候遍历数据是通过HashMap的KeySet这个类进行的。
final class KeySet extends AbstractSet {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumersuper K> action) {
Node[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
} 从这个可以看出,我们可以是用ForEach,或者迭代器。
HashSet实现数据不重复就是重写了HashCode以及Equals方法:
是在他所继承的AbstractSet这个类中书写的:
使用HashSet的时候要注意他不是线程安全的,需要重新要存放数据的HashCode 与Equals方法。
HashSet没有办法实现快速存取,如果需要如果需要获取到某一个位置的数据可以先调用 toArray方法转换为数组,然后进行查找.返回的数据顺序与插入的顺序相反。
HashMap的keySet的效率比entrySet效率低,因为keySet是通过迭代key来进行迭代,entrySet通过迭代Node对象来进行,不需要通过key进行value的查找,所以速度更快。
17、Popwindow源码学习:
关于popWindow的源码其中最主要的是show 以及dismiss的原理;
做过悬浮窗开发的人肯定知道,如果我们要创建一个悬浮在当前Activity或者这个android系统上边的话,需要使用到的一个类肯定是WindowManager,通过WindowManager的addView的方法添加到界面上去,如果只是添加到当前Activity的话
18、Toast源码学习
也是通过WindowManager来进行实现的。
toast主要是通过TN这个类来进行最终的显示以及隐藏,如果要自己来控制显示以及隐藏可以通过反射来获取Toast中的mTN对象,然后通过这个对象用反射来调用show以及dismiss。
Toast中TN源码:
private static class TN extends ITransientNotification.Stub {
final Runnable mShow = new Runnable() {
@Override
public void run() {
handleShow();
}
};
final Runnable mHide = new Runnable() {
@Override
public void run() {
handleHide();
// Don't do this in handleHide() because it is also invoked by handleShow()
mNextView = null;
}
};
private final WindowManager.LayoutParams mParams = new WindowManager.LayoutParams();
final Handler mHandler = new Handler();
int mGravity;
int mX, mY;
float mHorizontalMargin;
float mVerticalMargin;
View mView;
View mNextView;
WindowManager mWM;
TN() {
// XXX This should be changed to use a Dialog, with a Theme.Toast
// defined that sets up the layout params appropriately.
final WindowManager.LayoutParams params = mParams;
params.height = WindowManager.LayoutParams.WRAP_CONTENT;
params.width = WindowManager.LayoutParams.WRAP_CONTENT;
params.format = PixelFormat.TRANSLUCENT;
params.windowAnimations = com.android.internal.R.style.Animation_Toast;
params.type = WindowManager.LayoutParams.TYPE_TOAST;
params.setTitle("Toast");
params.flags = WindowManager.LayoutParams.FLAG_KEEP_SCREEN_ON
| WindowManager.LayoutParams.FLAG_NOT_FOCUSABLE
| WindowManager.LayoutParams.FLAG_NOT_TOUCHABLE;
}
/**
* schedule handleShow into the right thread
*/
@Override
public void show() {
if (localLOGV) Log.v(TAG, "SHOW: " + this);
mHandler.post(mShow);
}
/**
* schedule handleHide into the right thread
*/
@Override
public void hide() {
if (localLOGV) Log.v(TAG, "HIDE: " + this);
mHandler.post(mHide);
}
public void handleShow() {
if (localLOGV) Log.v(TAG, "HANDLE SHOW: " + this + " mView=" + mView
+ " mNextView=" + mNextView);
if (mView != mNextView) {
// remove the old view if necessary
handleHide();
mView = mNextView;
Context context = mView.getContext().getApplicationContext();
String packageName = mView.getContext().getOpPackageName();
if (context == null) {
context = mView.getContext();
}
mWM = (WindowManager)context.getSystemService(Context.WINDOW_SERVICE);
// We can resolve the Gravity here by using the Locale for getting
// the layout direction
final Configuration config = mView.getContext().getResources().getConfiguration();
final int gravity = Gravity.getAbsoluteGravity(mGravity, config.getLayoutDirection());
mParams.gravity = gravity;
if ((gravity & Gravity.HORIZONTAL_GRAVITY_MASK) == Gravity.FILL_HORIZONTAL) {
mParams.horizontalWeight = 1.0f;
}
if ((gravity & Gravity.VERTICAL_GRAVITY_MASK) == Gravity.FILL_VERTICAL) {
mParams.verticalWeight = 1.0f;
}
mParams.x = mX;
mParams.y = mY;
mParams.verticalMargin = mVerticalMargin;
mParams.horizontalMargin = mHorizontalMargin;
mParams.packageName = packageName;
if (mView.getParent() != null) {
if (localLOGV) Log.v(TAG, "REMOVE! " + mView + " in " + this);
mWM.removeView(mView);
}
if (localLOGV) Log.v(TAG, "ADD! " + mView + " in " + this);
mWM.addView(mView, mParams);
trySendAccessibilityEvent();
}
}
private void trySendAccessibilityEvent() {
AccessibilityManager accessibilityManager =
AccessibilityManager.getInstance(mView.getContext());
if (!accessibilityManager.isEnabled()) {
return;
}
// treat toasts as notifications since they are used to
// announce a transient piece of information to the user
AccessibilityEvent event = AccessibilityEvent.obtain(
AccessibilityEvent.TYPE_NOTIFICATION_STATE_CHANGED);
event.setClassName(getClass().getName());
event.setPackageName(mView.getContext().getPackageName());
mView.dispatchPopulateAccessibilityEvent(event);
accessibilityManager.sendAccessibilityEvent(event);
}
public void handleHide() {
if (localLOGV) Log.v(TAG, "HANDLE HIDE: " + this + " mView=" + mView);
if (mView != null) {
// note: checking parent() just to make sure the view has
// been added... i have seen cases where we get here when
// the view isn't yet added, so let's try not to crash.
if (mView.getParent() != null) {
if (localLOGV) Log.v(TAG, "REMOVE! " + mView + " in " + this);
mWM.removeView(mView);
}
mView = null;
}
}
}
19、反射学习
关于java的反射:首先反射就是在程序运行的过程中可以动态的修改其状态以及行为的一种能力。
现在我们使用反射大部分是通过修改某一个类的其中一个对象的引用或者对其值的修改,达到修改对象的行为。
如果要对类中的方法或者实现进行修改就需要进行字节码注入操作,不在反射的学习中。
关于反射主要是通过Class这个类以及
java.lang.reflect
这个包下边Method,Field等等的来实现的。
20、android切换到桌面
Intent mHomeIntent;
mHomeIntent = new Intent(Intent.ACTION_MAIN, null);
mHomeIntent.addCategory(Intent.CATEGORY_HOME);
mHomeIntent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK | Intent.FLAG_ACTIVITY_RESET_TASK_IF_NEEDED) startActivity(mHomeIntent);
21、关于String ,StringBuffer,StringBuilder的比较
String 类是一个final类型的类,它是不能被修改的,也就是说
String s = “aaaaaa”
s = s + “bbbbb”因为String 是不能被修改的,所以上边的在执行的时候是重新创建一个String 对象,然后 赋值给s 。
所以如果在使用的时候是对String 对象来进行操作,是十分的耗时的,但是如果是直接对字符串进行操作,那么速度很快,都是jvm来进行操作的。
StringBuilder、StringBuffer是可变字符串对象,我们所有对字符串的操作都在这个对象上边,如果是对字符串对象进行操作的话,速度上要比String快上很多很多。
他们俩个都是继承了AbstractStringBuilder这个抽象类,在这个类中实现了大部分的功能,比如getValue,setLength,append ,reverse,等等,这个类还实现了CharSequence接口, 所以StringBuffer与StringBuilder都是在AbstractStringBuilder的基础上又进行了扩展,他们都实现了相同的三个接口java.io.Serializable, Appendable, CharSequence。
而他们俩个的区别就在于线程安全:
StringBuffer:线程安全 ,是因为它里边很多方法都是上锁的,通过synchronized来进行修饰的,所以在多线程中操作时是不会引起对象的因多线程操作而发生的数据不一致问题。
StringBuilder:非线程安全,与StringBuffer正好相反,所有的方法都么有加锁。但是如果在非多线程操作中,速度比StringBuffer要快。
22、6.0多进程无法安装总是提示安装失败。应用之间交互也需要设置关联启动
23、
5.0以后获取正在运行的程序只能获取到当前应用。而后台正在运行的服务以及应用都只能通过获取服务然后通过service或者process来进行判断。
因为6.0以后应用如果设置多进程是无法安装的。
获取方式:
/**
* 方法描述:判断某一Service或者应用是否正在运行
*
* @param context 上下文
* @param serviceName Service的全路径: 包名 + service的类名 (如果是判断应用是否安装直接传递包名)
* @return true 表示正在运行,false 表示没有运行
*/
public static boolean isServiceRunning(Context context, String serviceName) {
ActivityManager am = (ActivityManager) context.getSystemService(Context.ACTIVITY_SERVICE);
List runningServiceInfos = am.getRunningServices(200);
if (runningServiceInfos.size() <= 0) {
return false;
}
for (ActivityManager.RunningServiceInfo serviceInfo : runningServiceInfos) {
Log.e("TAG", serviceInfo.service.getClassName());
if (serviceInfo.process.equals(serviceName)) {
return true;
}
}
return false;
}
24、android aidl进程间通信要注意的点;
现在在做一个sdk用来让讯飞可以与我们公司的应用进行开发。
因为是要在进程间通信,所以肯定会使用Aidl来进行。
但是要注意的几点就是:
(1)进程间通信的话最好是不要把提供服务的service设置为独立的进程,要保证跟应用在同一个进程(2)还有就是进程间通信必
25、查看当前应用cpu内、存使用情况
adb shell
top -m 15 -s cpu //查询当前cpu占用前十的应用
dumpsys meminfo //查看手机上所有的内存信息
dumpsys battery//查看电量信息
dumpsys meminfo “要查看的应用的包名” //查询某一个应用的包名
top -d 1 | grep com.guoyi.qinghua //查询某一个应用的cpu使用情况
26、关于android 的应用程序cpu占用率问题
1、图片加载(图片加载使用好第三方框架,尽量不要使用Bitmap.create的方法)
android动画对于cpu的消耗还是很大的,如果是可以通过自定实现的动画使用自定义动画,如过是复杂动画,能用ObjectAnimator实现就不要用ValueAnimator来进行实。
不要使用动画来更新自定义的进度条或者是会根据时间间隔变化的View。可以用Timer或者Handler来替换。
可以减小图片的大小。
2、线程 (线程确保执行完成,或者可以手动控制)
3、布局加载(布局尽量减少布局层数)
4、网络(在进程网络访问的时候要先判断网状态)
5、定位(降低定位的时间间隔)
6、直播软件的编解码(在使用七牛播放器的时候,设置硬解码cpu的占有率比软解码低一半,如果cpu占用太高切换硬解码是一个好的选择)
27、android logo 尺寸
DENSITY SIZE LOCATION RATIO SCREEN MARGIN
XXXHDPI 192×192 drawable-xxxhdpi 4 640 DPI 12 to 16 pixels
XXHDPI 144×144 drawable-xxhdpi 3 480 DPI 8 to 12 pixels
XHDPI 96×96 drawable-xhdpi 2 320 DPI 6 to 8 pixels
HDPI 72×72 drawable-hdpi 1.5 240 DPI 4 to 6 pixels
MDPI 48×48 drawable-mdpi 1 160 DPI 3 to 4 pixels
MDPI 48×48 drawable (Cupcake) 1 160 DPI 3 to 4 pixels
LDPI 36×36 drawable-ldpi 0.75 120 DPI 2 to 3 pixels
NA 512×512 Google Play NA NA As required
28、ython环境配置以后在使用中出现的问题
python代码需要在开头插入
#!/usr/bin/python
用来生名python支持,然后通过import可以导入需要的类。
如果出现 -bash: ./**.py: /usr/bin/python^M: bad interpreter: No such file or directory
那么应该是不同系统编码格式引起的:在windows系统中编辑的.sh .py文件可能有不可见字符,所以在linux系统下执行会报以上异常信息。一般是因为windows行结尾和linux行结尾标识不同造成的。
解决:
1)在windows下转换:
利用一些编辑器如UltraEdit或EditPlus等工具先将脚本编码转换,再放到Linux中执行。转换方式如下(UltraEdit):File–>Conversions–>DOS->UNIX即可。
2)linux下直接替换:
sed -i ‘s/^M//g’ filename (注意^M 在linux 下写法 按^M 是回车换行符,输入方法是按住CTRL+v,松开v,按m)
3)也可在Linux中转换:
首先要确保文件有可执行权限
#sh>chmod a+x filename
然后修改文件格式
#sh>vi filename
利用如下命令查看文件格式
:set ff 或 :set fileformat
可以看到如下信息
fileformat=dos 或 fileformat=unix
利用如下命令修改文件格式
:set ff=unix 或 :set fileformat=unix
:wq (存盘退出) 或者使用:wq! 进行保存
最后再执行文件
#sh>./filename
如果配置了全局的python环境变量的话可以直接使用xxxx.py来执行py文件,或者要通过./xxxx.py
29、Bitmap.createBitmap中参数的理解
x的值不能小于0,width 不能小于0;
x+width 的值不能小于0,也不能大于原bitmap的宽度,
y的值与height与上边规则相同,
而通过这个方法创建的btimap是通过x与y来控制要截取的bitmap的起始位置,最后的width与height用来确定从x与y的位置截取开始到什么时候结束。
30、如果.9图片不正规可能导致android studio编译出现多线程问题
31、studio中svn的使用
studio中使用svn可以更新指定文件,也可以提交指定文件。
svn指定版本更新会把指定版本以下的代码都更新下来,不会更新指定版本以上的代码
svn 中revert 复原代码,只能复原没有提交的文件,如果提交时没有办法复原
32、RecycleView 的scrollToPosition方法,如果剩下的item个数不够一屏幕的话无法滚动。
但是可以使用 scrollBy(int x, int y) 滚动屏幕的宽度的距离就可以。
33、内存泄漏的理解,如何防止内存泄漏(以及内存泄漏会引起的问题)
关于内存泄漏其实最难的是定位问题出现。一个良好的代码习惯,能避免掉很多内存泄漏,但是也不能规避过所有的。以前都是在内存泄漏以后使用工具进行内存分析,找到内存泄漏的地方,然后进行修改,现在发现一个内存泄漏检测比较简单的一个工具leakcanary,可以去gitHub上直接查看源码,然后简单集成下就可以了。
内存泄漏:内存泄漏就是一个对象被别的对象引用,导致他应该被释放回收的时候,没有办法释放,对内存的持续占用,会导致android应用在给别的功能分配内存的时候,可能没有办法分配给这个功能那么多的内存,然后gc开始查找可以释放的内存,但是因为内存泄漏了(也就是那么没有办法释放的对象都是强引用),gc查找以后也不能释放出足够这个功能所需要占用的内存的时候,那么就会出现内存泄漏。
内存泄漏的解决办法:可以加大android系统给应用分配的内存上限,但是这个是治标不治本,最主要还是要修改内存泄漏的根本原因。一般发生内存泄漏的地方有(1)匿名内部类的使用(因为匿名内部类一般都会持有当前对象的引用,那么在内部类对象没有释放的时候,那么他所持有的引用也不会消失,就会导致内存泄漏)如果可以在Application中添加的回调监听,一定不要放在activity中,因为那样的话,在回调没有回调的时候,引用也会一直持有;(2)在开发中发现 集合类很容易引起内存泄漏,一般尽量不要把集合类创建为static类型,否则的话他里边的对象都不会得到释放,除非是从集合中移除。可以参考的文章:http://blog.csdn.net/u012808234/article/details/74942491
34、屏幕适配是android一直以来都很坚挺的问题呢,
因为android的开源性,各个厂商的定制,等等,导致android手机的分辨率是千奇百怪,但是我们适配一般也只适配主流的分辨率,不是所有。
那么在适配的过程中如何用最小的成本来适配最多屏幕,就是我们开发需要考虑的问题。
android 中推荐使用match_parent,warp_parent, xxxdl ,xxxsp,主要就是为了适配。
dp(dip或者叫dpi) 代表的是单位英寸内的像素点个数,他是跟像素无关,跟屏幕密度有关的。
android中屏幕密度越大也就是单位英寸内的像素点越多。屏幕显示的更清晰。
密度的计算方式:1920x1080 5英寸手机(对角线的长度,也就是手机左上角跟右下角的长度)
√(1920^2+1080^2)=2202.9071
2202.9/5=468.7021(ppi)≈469ppi
如果在480px 跟240px上 如果密度相同,那么1dp所占的大小也是相等的。这就是跟像素无关
160ppi 1dp 1px
320ppi 1dp 2px
480ppi 1dp 3px
密度因子以160为基础,也就是160 密度因子是1,密度因子= 密度/160
dp转px px = dp ✖️密度因子
知道了这个,但是如果只是简单的设置dp还是不能够适配大多数屏幕:
适配方式:
1、布局适配,根据不同分辨率创建不同的布局
优点是简单明了,只要根据不同的屏幕创建不同的布局即可,但是会导致的问题就是,布局文件的增多,如果里边对于图片的使用很多的话,那么会导致app打包以后的大小变的很大,要适配大部分屏幕,工作量比较大
2、布局的时候通过比例来进行适配,比如一个按钮占屏幕的几分之几
优点就是一套布局可以适配所有的屏幕,但是不是所有的布局都能用比例来适配
3、使用一套布局,然后创建不同分辨率的dimens.xml (创建不同分辨率的values比如values_480x1280)
4、一些动画或者效果,客户端如果可以实现的话,而且不是特别难的话,最好是自定义,动态的适配分辨率
5、在代码中动态修改控件的宽度等等参数
自定义资源文件夹的书写实例:(需要注意的是命名的类型优先级顺序不能调整否则会编译不通过)
values-mcc310(sim卡运营商)-en(语言)-sw320dp(屏幕最小宽度)-w720dp(屏幕最佳宽度)-h720dp(屏幕最佳高度)-large(屏幕尺寸)-long(屏幕长短边模式)-port(当前屏幕横竖屏显示模式)-car(dock模式)-night(白天或夜晚)-ldpi(屏幕最佳dpi)-notouch(触摸屏模类型)-keysexposed(键盘类型)-nokey(硬按键类型)-navexposed(方向键是否可用)-nonav(方向键类型)-v7(android版本)
values-mcc310-en-sw320dp-w720dp-h720dp-large-long-port-car-night-ldpi-notouch-keysexposed-nokeys-navexposed-nonav-v7(注意: 对于指定分辨率的属性(例如:values-hdpi-1024x600,values-hdpi-960x540,values-mdpi-1024x600),指定分辨率属性并没出现在官网的匹配属性集里,也没找到对于分辨率属性的详细说明,经测试,这个分辨率属性匹配并不准确,例如Galaxy Nexus(1280x720 ),却可以匹配到values-hdpi-1024x600,因此希望最好不使用分辨率属性。)
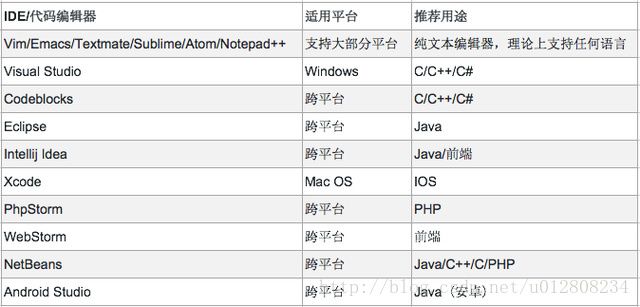
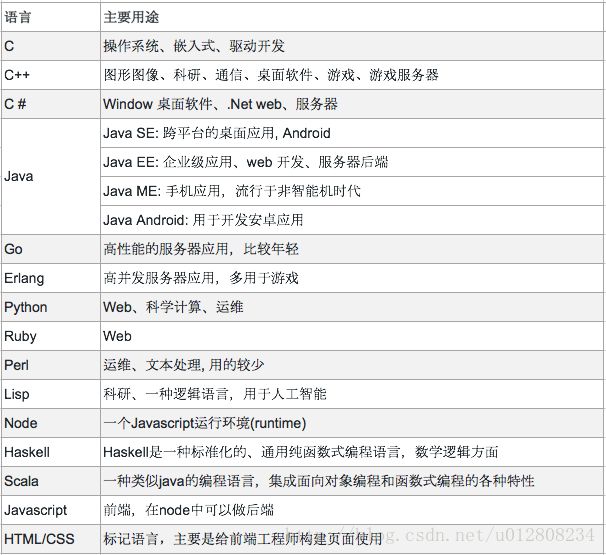
35、开发工程中编程语言的学习以及开发工具:
36 、多项目依赖同一个module,实现module的统一管理
现在做android的基本上都在用studio进行开发,如果开发一个项目还好,但是如果是多个项目,而且他们还有同样在使用的Module,那么就要维护很多套不同项目的,但是缺相同的Moudle,所以使用多项目依赖同样的Moudule可以很有效的减小代码的维护成本,减小开发时间。
方式:
- 首先创建一个项目,该项目包含所有公有的Module
打开要添加公有Module的项目,通过强制引用添加所需要的Module
打开项目的setting.gradle
如下配置:
include ‘:app’, ‘:framework’
include ‘:cuslibrary’ ,’:qhlibrary’ //添加项目所要包含的Module
project(‘:cuslibrary’).projectDir = new File(‘../AllModule/cuslibrary’) //导入该路径下的Moudle
project(‘:qhlibrary’).projectDir = new File(‘../AllModule/qhlibrary’) //导入该路径下的Moudle然后在该项目的app文件夹的根目录下边的build.gradle中添加Module的依赖
compile project(‘:cuslibrary’)
compile project(‘:qhlibrary’)保证不会有相同的文件或者类库的引用,然后运行ok
37、在使用svn的时候如果add 了一个不进行版本管理的文件会出现 E200009的错误
解决方式:svn st | grep ^? | awk '{print $2}' | xargs svn add38、android自定义view中自定义参数的使用
自定义view中使用自定义的参数:
主要分为下边几种类型:
- boolean 布尔类型
- String 字符串类型
- Integer 整数类型
- flag 位或运算
(1)属性定义:
name="名称">
name="windowSoftInputMode">
name = "stateUnspecified" value = "0" />
name = "stateUnchanged" value = "1" />
name = "stateHidden" value = "2" />
name = "stateAlwaysHidden" value = "3" />
name = "stateVisible" value = "4" />
name = "stateAlwaysVisible" value = "5" />
name = "adjustUnspecified" value = "0x00" />
name = "adjustResize" value = "0x10" />
name = "adjustPan" value = "0x20" />
name = "adjustNothing" value = "0x30" />
(2)属性使用:
name = ".StyleAndThemeActivity"
android:label = "@string/app_name"
android:windowSoftInputMode = "stateUnspecified | stateUnchanged | stateHidden">
name "android.intent.action.MAIN" />
name="android.intent.category.LAUNCHER" />
- color 颜色
- dimension 自定义dimen
- enum 枚举类型
"types" format="enum">
<enum name="EMOJI" value="0"/>
<enum name="SHORTCUT" value="1"/>
- float 浮点类型
reference 某一个资源的id
fraction 百分数
"pivotY" format = "fraction" /> 39、java 代理模式
java代理模式主要是为了分离类的实现与方法的调用,隐藏方法的实际实现。通过代理我们能解耦。
- 动态代理
public interface ProxyInterface {
String sayHello();
}
public class ProxyIml implements ProxyInterface {
@Override
public String sayHello() {
System.out.println("执行真实方法");
return"你好我是真实结果";
}
}
public class ProxyTest {
public static void main(String[] args){
//直接通过代理来创建一个动态代理的对象,这样的对象所有的方法调用都会被拦截到invoke方法中,最后可以返回的结果就是方法的执行结果。但是要注意,这样实现的对象不能调用invoke中 method的invoke方法,否则会死循环
ProxyInterface proxy = (ProxyInterface) Proxy.newProxyInstance(ProxyInterface.class.getClassLoader(), new Class[]{ProxyInterface.class}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("执行方法之前");
// method.invoke(proxy,args);
System.out.println("执行方法之后");
return "我是结果";
}
});
System.out.println(proxy.sayHello());
//创建一个具体的实现类对象
ProxyInterface proxyInterface = new ProxyIml();
//创建一个动态代理对象
ProxyInterface prox_sub = (ProxyInterface) Proxy.newProxyInstance(ProxyIml.class.getClassLoader(), new Class[]{ProxyInterface.class}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("执行方法之前");
method.invoke(proxyInterface);//如果方法没有参数,不需要传
System.out.println("执行方法之后");
return null;
}
});
System.out.println(proxy.sayHello());
}
}
- 静态代理
1 package ceshi1;
2 public interface Iuser {
3 void eat(String s);
4 } package ceshi1;
2 public class UserImpl implements Iuser {
3 @Override
4 public void eat(String s) {
5 System.out.println("我要吃"+s);
6 }
7 }
package ceshi1;
2 public class UserProxy implements Iuser {
3 private Iuser user = new UserImpl();
4 @Override
5 public void eat(String s) {
6 System.out.println("静态代理前置内容");
7 user.eat(s);
8 System.out.println("静态代理后置内容");
9 }
10 } package ceshi1;
2 public class ProxyTest {
3 public static void main(String[] args) {
4 UserProxy proxy = new UserProxy();
5 proxy.eat("苹果");
6 }
7 }静态代理就是对接口的二次实现来隐藏具体的实现。
40、android内存泄漏分析:
由于android系统对于内存使用很苛刻,所以如果内存使用不好,会出现很多问题比如内存泄漏,动画运行卡顿,接收用户信息缓慢,最后可能还有内存溢出。
所以为了让我们的应
用更坚强,我们就要对内存的使用进行更严格的检测,虽然java有gc进行内存的管理,但是我们错误的对象创建可能会导致内存无法回收,所以需要对错误的内存使用进行分析。
1. 使用Ecplise 或者Studio 来生成.hprof文件。
下边介绍Studio中如何生成该文件,
运行要分析的应用,然后对要检测的功能模块进行测试,当所有测试都完成以后,对于重要模块多次测试,最后点击
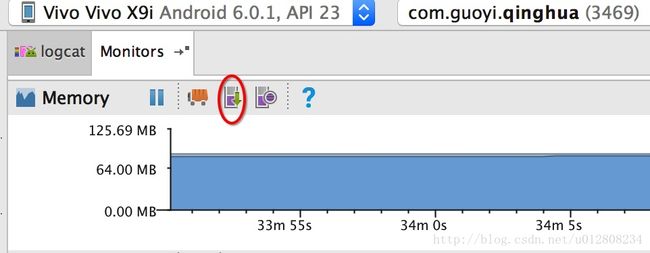
生成hprof文件,但是这样生成的文件Mat会报错,只能在Studio中查看,所有需要转一下。
点击Captures 然后找到生成的文件,右键
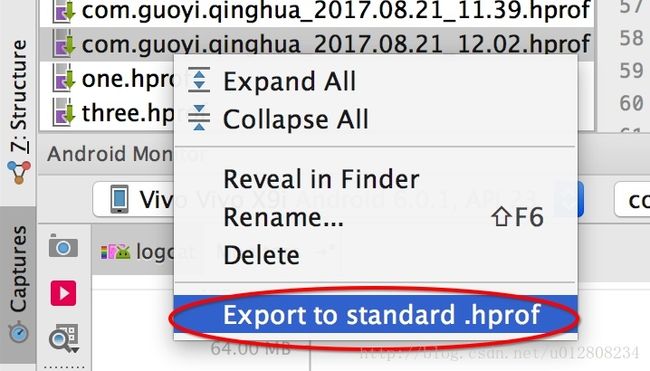
就可以使用Mat打开进行分析
- 现在android中使用最轻量级的工具leakcanary
使用方式很简单,主要集成了这个第三方库,然后在Application中初始化即可使用。
该方式会动态的检测app在运行过程中的内存泄漏的情况。
最后会在桌面生成Leaks这样一个快捷方式。里边会有出现内存泄漏的信息。根据提示找到问题原因,进行修改。
重点记录Mat工具的使用分析:
使用Mat工具可以对hprof文件进行分析,最后生成如下图。
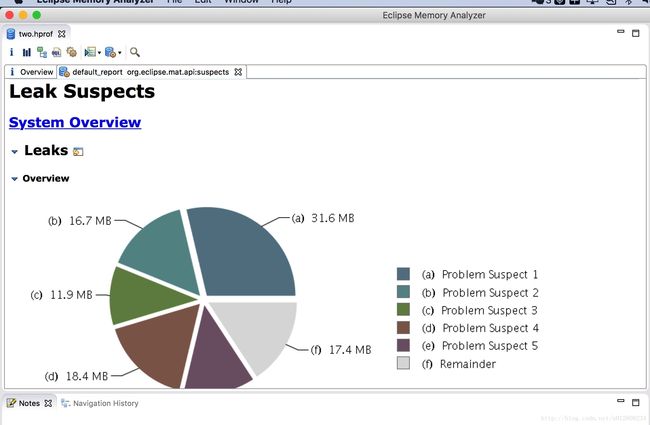
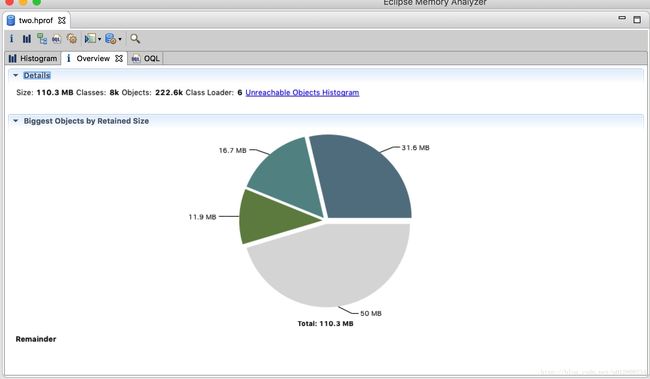
这是内存的使用情况。

上边的图从第二个开始都是进行内存分析的不同方式
1、 histogram:
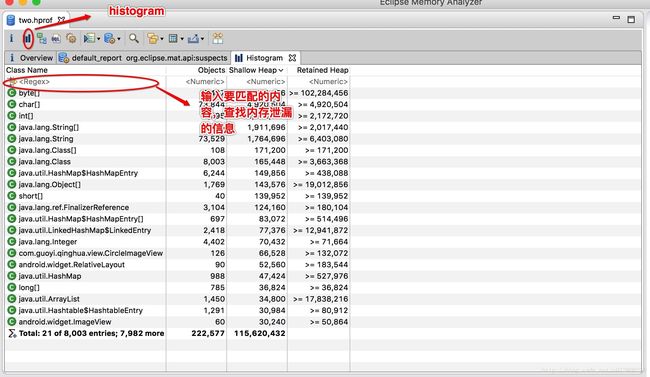
然后输入要查找内存泄漏的类名或者其他。
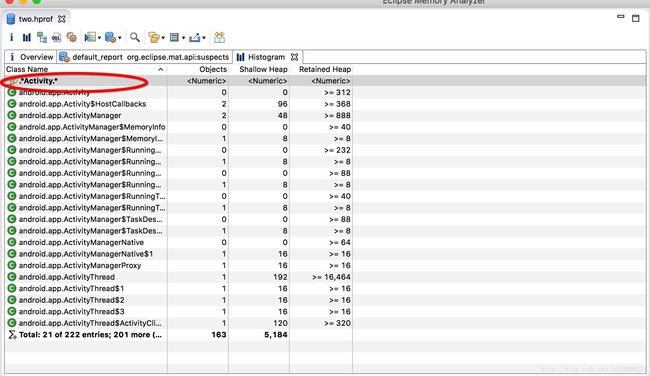
然后选择要检测的Activity的那一行,右键
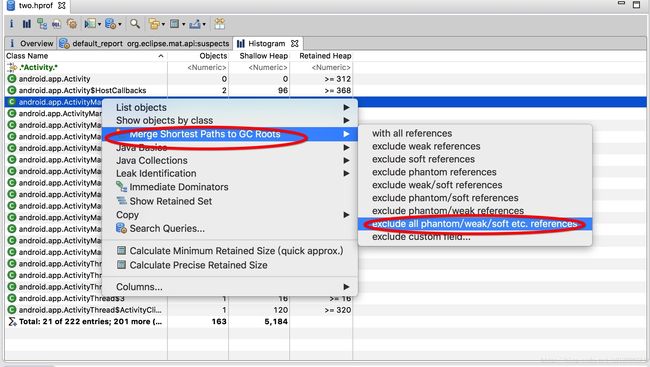
选择排除掉虚、弱,软引用的引用(这些gc会回收),
最后显示的就是这个类的引用。也就是可能引起内存泄漏的地方。
2、dominator_tree
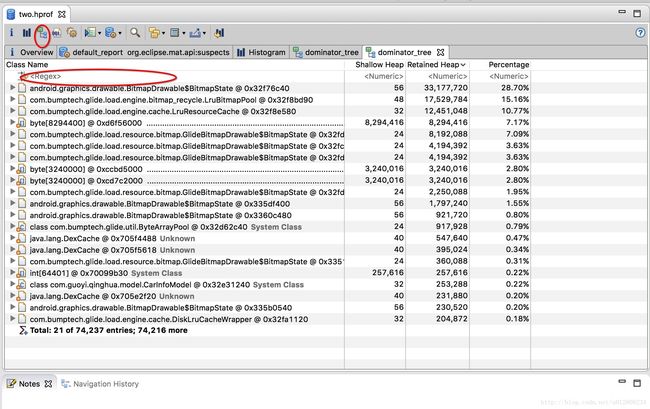 跟上边一个意思。
跟上边一个意思。
使用方式也相同
3、OQL
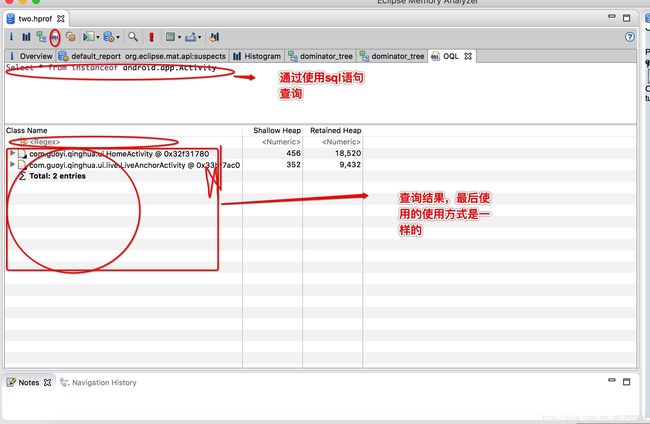
查询到需要的内容就可以做后边的操作了。
一般会对比应用生成的俩个hprof文件来具体分析内存的使用。
41、Android 源代码下载
https://pan.baidu.com/s/1ngsZs%EF%BC%8C%E5%AE%83%E6%8F%90%E4%BE%9B%E4%BA%86%E5%A4%9A%E4%B8%AAAndroid%E7%89%88%E6%9C%AC%E7%9A%84%E7%9A%84%E6%BA%90%E7%A0%81%E4%B8%8B%E8%BD%BD%E3%80%82#list/path=%2F&parentPath=%2F
42、android studio使用中出现异常:
如果在代码开发过程中异常关闭或者异常打断会导致studio中 .idea文件夹中的workSpace.xml文件出现异常的情况,比如没有结束的标签等等,只要删除该文件,然后重启studio即可
43、ScrollView中添加可滚动的文本内容而且居中显示,类似微信双击文本消息以后出现的放大文本显示一样
<ScrollView xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/sv_scrollview"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:fillViewport="true">
<LinearLayout
android:layout_width="match_parent"
android:layout_height="match_parent">
<TextView
android:id="@+id/tv_new_content"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:layout_margin="@dimen/d_32dp"
android:gravity="center"
android:text=""
android:textColor="@color/color_333333"
android:textSize="@dimen/s_24sp">
TextView>
LinearLayout>
ScrollView>
44、Kotlin 学习
自从这个新的编程语言出现以后,很多人都对这个语言都不熟悉,本人在学习以及使用的过程中遇到的问题以及解决方案,以及要注意的问题。
(http://blog.csdn.net/u012808234/article/details/77878788)
45、java中使用Float与Double精度问题
在java中在使用Float跟Double的计算的时候计算的时候出现精度问题,可能会出现计算结果
0.080000000000000005
0.5900000000000001
301.49999999999994
2.2329999999999999 高精度是为了进行科学计算的,如果不需要这么高精度,那么正常计算就可以使用BigDecimal
/**
* Created by chenpengfei on 17/9/13.
* 代码使用kotlin编写
*/
class ComputerTest{
}
fun main(args : Array){
var a = 0.05
var b = 0.01
var c = a + b;
println("c = $c")
var dd : BigDecimal = BigDecimal(a.toString())
var ddd : BigDecimal = BigDecimal(b.toString())
println("结果" + dd.add(ddd))
}
在程序开发过程中一定保证客户端与服务器端对于精度要一致。
46、 请找出一个int类型有穷随机数组中的最长连续序列
//例如数组{1,3,8,4,6,5,9}应当输出 3 4 5 6
import java.io.*;
import java.util.Arrays;
import java.util.ArrayList;
class myCode
{
//请找出一个int类型有穷随机数组中的最长连续序列
//例如下列数组应当输出 3 4 5 6
static int[] array = {
3, 100, 4, 6, 89, 5, 1, 88, 10, 11, 12, 13, 14, 15, 16
};
public static void main (String[] args) throws java.lang.Exception
{
for(int i = 1; i < array.length; i ++){
for(int j = i;j > 0; j --){
if(array[j] < array[j -1]){
int temp = array[j];
array[j] = array[j -1];
array[j -1] = temp;
}
}
}
System.out.println(Arrays.toString(array));
ArrayList counts = new ArrayList();
String s = "";
for(int i= 1; i< array.length; i ++){
if(array[i] - array[i -1] == 1){
s = s + array[i -1] + " ";
}else{
counts.add(s + array[i-1] + " ");
s = "";
}
}
int index = 0;
for(int i = 1; i < counts.size(); i ++) {
if(counts.get(i).length() > counts.get(i - 1).length()){
index = i;
}
}
System.out.println(counts.get(index));
}
}
47、android 开发热修复原理以及开源框架
android的热修复是在近几年特别火的一个功能,从android应用的插件化+热修复的功能中可以看到这个功能对于android来说是多么的被需要。在15、16年陆续的开源了很多框架,让我们对这个功能的整体实现的逻辑有了一定的了解。
热修复在目前是基于俩种不同的原理来实现的该功能:
- 基于底层实现,通过c/c++层来拦截或者修改方法的执行
基于dex分包,通过把要修改的类打包成一个dex文件,然后通过反射插入到dexElements这个数组的开始位置。让应用通过classLoader加载类的时候可以加载到修改过的类
第二种方式是现在用的最多的。但是需要应用重启才生效。
目前使用最广的开源框架:
- AndFix 阿里开源的一个热修复框架
https://github.com/alibaba/AndFix - Tinker 腾讯微信开源的热修复框架
https://github.com/alibaba/AndFix
(如果要插件化应用,可以使用360开源的框架DroidPlugin https://github.com/Qihoo360/DroidPlugin/ )
48 、android源码下载以及编译
源码编译资料
49、android让应用可以最大程度的存活
android应用总是在想着如何让用户可以一直使用这个app,让这个app可以一直存活在手机进程中,但是因为android手机内存问题,总会有不在使用的应用被回收,那么如何让我们的应用可以最大程度上存活呢。
有以下几种方式:
- 创建前台service ,使应用的优先级提高
- 通过设置Service为粘性service,让service被杀死的时候可以在重启
- 通过俩个service来互相唤醒,当其中一个被杀死以后,另外一个在重新启动该service
- 通过设置清单文件中应用的 android:persistent=”true”(但是这个需要把该应用设置为系统应用,也就是此apk需要放入到system/app目录下,成为一个systemapp)
- 账户同步,定时唤醒 (需要使用android账户系统功能)
- 使用AlarmManager唤醒
- 通过静态广播监听第三方应用的广播来唤醒
- 通过监听系统广播来唤醒
- 通过native层双进程守护(但是在5.0及以上就失效了,如果要在5.0以后也可以的话需要研究android 源码)