在浏览器输入一个URL回车之后发生了什么?
注意:本文的步骤是建立在,请求的是一个简单的HTTP请求,没有HTTPS、HTTP2、最简单的DNS、没有代理、并且服务器没有任何问题的基础上,尽管这不切实际。
大致流程:
- URL解析
- DNS查询
- TCP连接
- 处理请求
- 接受响应
- 渲染页面
1、URL解析
- 地址解析:
首先判断你输入的是一个合法的URL还是一个待搜索的关键词,并且根据你输入的内容进行自动完成、字符编码等操作。
- HSTS:
由于安全隐患,会使用HSTS强制客户端使用HTTPS访问页面。
- 其他操作:
浏览器还会进行一些额外的操作,比如安全检查、访问限制(以前国产浏览器限制996.icu)。
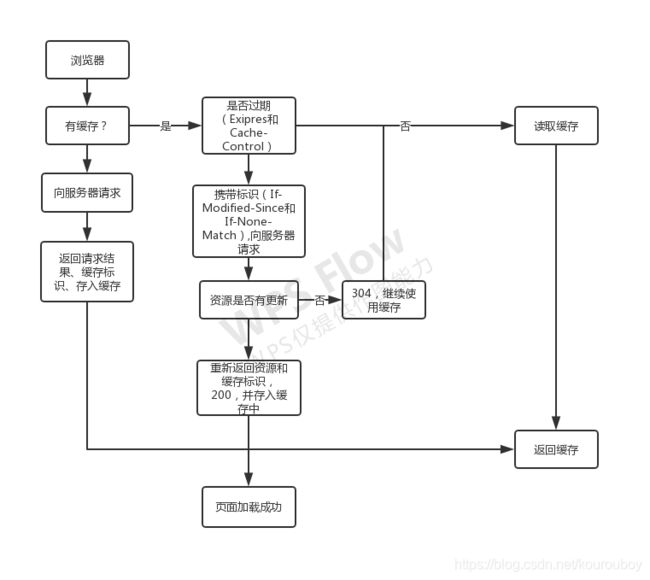
- 检查缓存:
2、DNS查询
- 基本步骤

1.浏览器缓存
浏览器会先检查是否在缓存中,没有则调用系统库函数进行查询。
2.操作系统缓存
操作系统也有自己的DNS缓存,但在这之前,会向检查域名是否存在本地的Hosts文件里,没有则向DNS服务器发送查询请求。
3.路由器缓存
路由器也有自己的缓存。
4.ISP DNS缓存
ISP DNS 就是在客户端电脑上设置的首选DNS服务器,它们在大多数情况下都会有缓存。
- 根域名服务器查询
在前面所有步骤没有缓存的情况下,本地DNS服务器会将请求转发到互联网上的根域。
- 需要注意的点
- 递归方式:一路查下去中间不返回,得到最终结果才返回信息(浏览器到本地DNS服务器的过程)
- 迭代方式:就是本地DNS服务器到根域名服务器查询的方式。
- 什么是DNS劫持
- 前端dns-prefetch优化
3、TCP连接
TCP/IP连接分为4层,在发送数据时,每层都要对数据进行封装:

1.应用层:发送HTTP请求
在前面的步骤我们已经得到服务器的IP地址,浏览器会开始构造一个HTTP报文,其中包括:
- 请求报头(Request Header):请求方法、目标地址、遵循的协议等等。
- 请求主体(其他参数)。
其中需要注意的点:
- 浏览器只能发送GET、POST方法,而打开网页使用的是GET方法。
2.传输层:TCP传输报文
传输层会发起一条到达服务器的TCP连接,为了方便传输,会对数据进行分割(以报文段为单位),并标记编号,方便服务器接收时能够准确地还原报文信息。
在建立连接之前,会先进行TCP三次握手。(前几篇文章中讲过)。
(可以查一下 SYN泛洪攻击)
3.网络层:IP协议查询Mac地址
将数据段打包,并加入源及目标的IP地址,并且负责寻找传输路线。
判断目标地址是否与当前地址处于同一网络中,是的话直接根据Mac地址发送,否则使用路由器表查找下一地址,以及使用ARP协议查询它的Mac地址。
“注意:在OSI参考模型中ARP协议位于链路层,但在TCP/IP中,它位于网络层。”
4.链路层:以太网协议
以太网协议:
根据以太网协议将数据分为以“帧”为单位的数据包,每一帧分为两个部分:
- 标头:数据包的发送者、接收者、数据类型
- 数据:数据包的具体内容
Mac地址:
以太网规定了连入网络的所有设备都必须具备“网卡”接口,数据包都是从一块网卡传递到另一块网卡,网卡的地址就是 Mac 地址。每一个 Mac 地址都是独一无二的,具备了一对一的能力。
广播
发送数据的方法很原始,直接把数据通过 ARP 协议,向本网络的所有机器发送,接收方根据标头信息与自身 Mac 地址比较,一致就接受,否则丢弃。
注意:接收方回应是单播。
“相关知识点:
”
ARP 攻击
服务器接受请求
接受过程就是把以上步骤逆转过来,参见上图。
4.服务器处理请求:
大致流程:
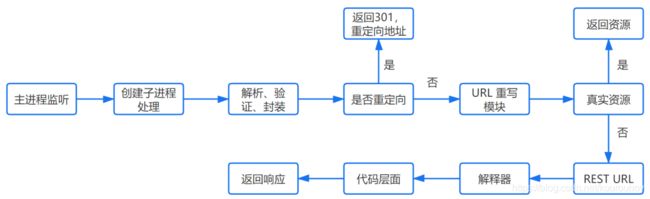
HTTPD
最常见的 HTTPD 有 Linux 上常用的 Apache 和 Nginx,以及 Windows 上的 IIS。
它会监听得到的请求,然后开启一个子进程去处理这个请求。
处理请求
接受 TCP 报文后,会对连接进行处理,对HTTP协议进行解析(请求方法、域名、路径等),并且进行一些验证:
-
验证是否配置虚拟主机
-
验证虚拟主机是否接受此方法
-
验证该用户可以使用该方法(根据 IP 地址、身份信息等)
重定向
假如服务器配置了 HTTP 重定向,就会返回一个 301永久重定向响应,浏览器就会根据响应,重新发送 HTTP 请求(重新执行上面的过程)。
“关于更多:详见这篇文章[2]
”
URL 重写
然后会查看 URL 重写规则,如果请求的文件是真实存在的,比如图片、html、css、js文件等,则会直接把这个文件返回。
否则服务器会按照规则把请求重写到 一个 REST 风格的 URL 上。
然后根据动态语言的脚本,来决定调用什么类型的动态文件解释器来处理这个请求。
以 PHP 语言的 MVC 框架举例,它首先会初始化一些环境的参数,根据 URL 由上到下地去匹配路由,然后让路由所定义的方法去处理请求。
5.浏览器接受响应
浏览器接收到来自服务器的响应资源后,会对资源进行分析。
首先查看 Response header,根据不同状态码做不同的事(比如上面提到的重定向)。
如果响应资源进行了压缩(比如 gzip),还需要进行解压。
然后,对响应资源做缓存。
接下来,根据响应资源里的 MIME[3] 类型去解析响应内容(比如 HTML、Image各有不同的解析方式)。
。。。