Matlab环境下PSO粒子群优化算法的模型测试
Matlab环境下PSO粒子群优化算法的模型测试
- 一、粒子群优化算法简介
- 1.1简介
- 1.2背景
- 1.3与遗传算法相比较
- 1.3.1共同点
- 1.3.2不同点
- 1.4PSO优缺点
- 1.5关于参数的设置
- 二、算法流程
- 三、代码模型
- 3.1源代码(不变参数)
- 3.2源代码(改变惯性权重参数)
- 3.3源代码(改变加速因子和惯性权重参数)
- 3.3源代码(只改变加速因子参数)
- 3.4源代码(将sizepop改为50)
- 3.3源代码(将适应度函数维数改变不同的值)
一、粒子群优化算法简介
1.1简介
粒子群优化算法(Particle Swarm optimization,PSO)又翻译为粒子群算法、微粒群算法、或微粒群优化算法。是通过模拟鸟群觅食行为而发展起来的一种基于群体协作的随机搜索算法。
1.2背景
模拟捕食
PSO模拟鸟群的捕食行为。一群鸟在随机搜索食物,在这个区域里只有一块食物。所有的鸟都不知道食物在那里。但是他们知道当前的位置离食物还有多远。那么找到食物的最优策略是什么呢。最简单有效的就是搜寻离食物最近的鸟的周围区域。
PSO从这种模型中得到启示并用于解决优化问题。PSO中,每个优化问题的解都是搜索空间中的一只鸟。我们称之为“粒子”。所有的粒子都有一个由被优化的函数决定的适应值(fitnessvalue),每个粒子还有一个速度决定他们飞翔的方向和距离。然后粒子们就追随当前的最优粒子在解空间中搜索。
PSO初始化
PSO初始化为一群随机粒子(随机解),然后通过迭代找到最优解,在每一次叠代中,粒子通过跟踪两个“极值”来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值pBest,另一个极值是整个种群找到的最优解,这个极值是全局极值gBest。另外也可以不用整个种群而只是用其中一部分最优粒子的邻居,那么在所有邻居中的极值就是局部极值。
值得注意的是,由于POS每一次的初始化都是随机的粒子,因此导致每一次的实验结果都不同。所以为了综合不同参数下的训练情况,此次模型测试采用同一参数计算十次取平均值的方法得出最优适应度。
1.3与遗传算法相比较
1.3.1共同点
①种群随机初始化。
②对种群内的每一个个体计算适应值(fitness value)。适应值与最优解的距离直接有关。
③种群根据适应值进行复制。
④如果终止条件满足的话,就停止,否则转步骤② 。
从以上步骤,我们可以看到PSO和遗传算法有很多共同之处。两者都随机初始化种群,而且都使用适应值来评价系统,而且都根据适应值来进行一定的随机搜索。两个系统都不是保证一定找到最优解。但是,PSO没有遗传操作如交叉(crossover)和变异(mutation),而是根据自己的速度来决定搜索。粒子还有一个重要的特点,就是有记忆。
1.3.2不同点
与遗传算法比较,PSO的信息共享机制是很不同的。在遗传算法中,染色体(chromosomes)互相共享信息,所以整个种群的移动是比较均匀的向最优区域移动。在PSO中, 只有gBest (orlBest) 给出信息给其他的粒子, 这是单向的信息流动。整个搜索更新过程是跟随当前最优解的过程。与遗传算法比较, 在大多数的情况下,所有的粒子可能更快的收敛于最优解。
1.4PSO优缺点
演化计算的优势,在于可以处理一些传统方法不能处理的。例子例如不可导的节点传递函数或者没有梯度信息存在。
但是缺点在于:
1、在某些问题上性能并不是特别好。
2.网络权重的编码而且遗传算子的选择有时比较麻烦。
最近已经有一些利用PSO来代替反向传播算法来训练神经网络的论文。研究表明PSO 是一种很有潜力的神经网络算法。PSO速度比较快而且可以得到比较好的结果。而且还没有遗传算法碰到的问题。
1.5关于参数的设置

进化次数maxgen:即总迭代的数目,即循环条件
粒子数sizepop: 即种群规模, 一般取 20–40. 其实对于大部分的问题10个粒子已经足够可以取得好的结果, 不过对于比较难的问题或者特定类别的问题, 粒子数可以取到100 或 200
变量取值范围Vmax:即位置的变量维度,根据对应的变量取值范围取设置限制速度围,根据具体要求不宜设置过大或者过小。
加速因子: c1 和 c2 通常等于 2. 不过在文献中也有其他的取值. 但是一般 c1 等于 c2 并且范围在0和4之间
全局PSO和局部PSO: 我们介绍了两种版本的粒子群优化算法: 全局版和局部版. 前者速度快不过有时会陷入局部最优. 后者收敛速度慢一点不过很难陷入局部最优. 在实际应用中, 可以先用全局PSO找到大致的结果,再用局部PSO进行搜索.
惯性权重:根据具体情况设置,惯性表示受影响的权重占比,一般前期惯性取大有利于迭代找出最优,到迭代后期则需要适当降低惯性权重。
二、算法流程
流程
标准PSO的算法流程如下:
1)初始化一群微粒(群体规模为m),包括随机的位置和速度;
2)评价每个微粒的适应度;
3)对每个微粒,将它的适应值和它经历过的最好位置pbest的作比较,如果较好,则将其作为当前的最好位置pbest;
4)对每个微粒,将它的适应值和全局所经历最好位置gbest的作比较,如果较好,则重新设置gbest的索引号;
5)变化微粒的速度和位置;
6)如未达到结束条件(通常为足够好的适应值或达到一个预设最大代数Gmax),回到步骤2)。
其数学概念如下:

三、代码模型
此次试验我们要展示的是根据迭代的次数来动态的调整三个主要的影响参数,我们将通过动态修改C1 ,C2 和W 的值来看看具体的影响。
3.1源代码(不变参数)
参数不随着迭代次数的增加而发生改变,而是根据原定的数据不改变。
这里将数据初始化为以下的值
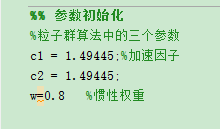

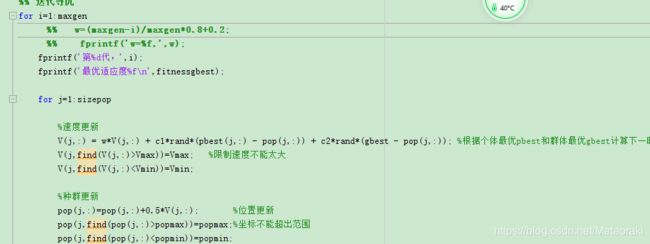

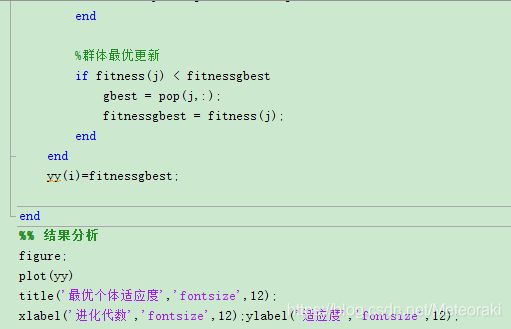
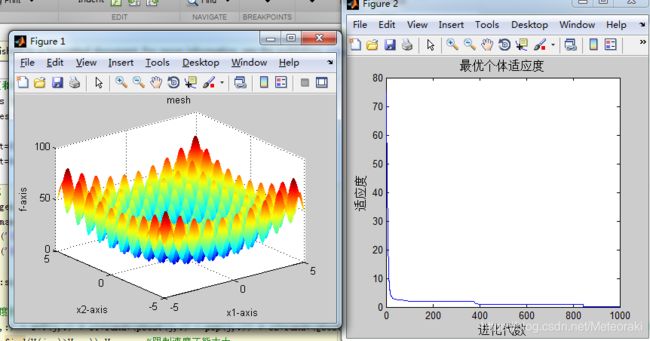
其中实验结果:
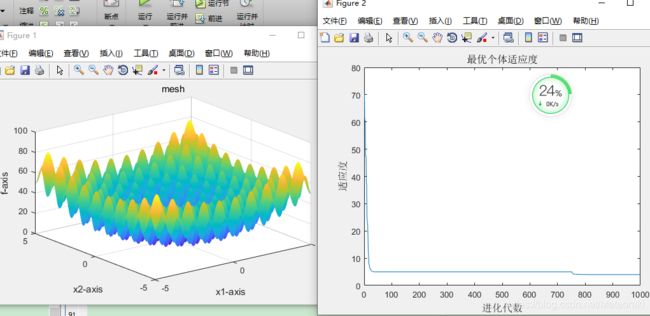
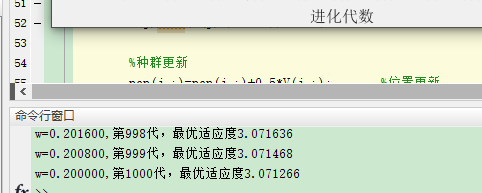
每一次的最适应度通过连续运行十次取平均值来看:
3.979836+3.979836+3.979836+0.000000+2.984877+2.984877+5.969754+0.000000+3.979836+4.320690=3.2179538
3.2源代码(改变惯性权重参数)
这里的w根据迭代次数的改变而改变呈线性减少,从1下降到0.2
最终最优适应度的平均值为:
2.050777+3.071266+0.000000+5.969754+0.000000+0.995640+0.994959+0.000000+0.000000+0.000000=1.3082396
3.3源代码(改变加速因子和惯性权重参数)
进行组合调试的结果如下
最终最优适应度的平均值为:
0.000000+4.122656+3.015954+1.070628+3.979836+2.984877+0.009834+1.989918+1.989918+0.000000=1.916317
可想这个三个组合调试的效果并没有之前的好。
3.3源代码(只改变加速因子参数)
只改变c1和c2
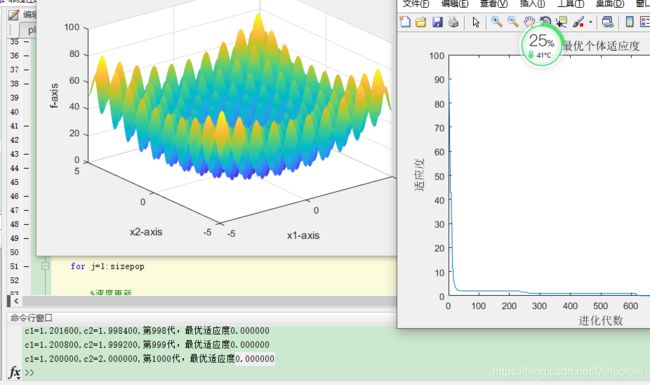
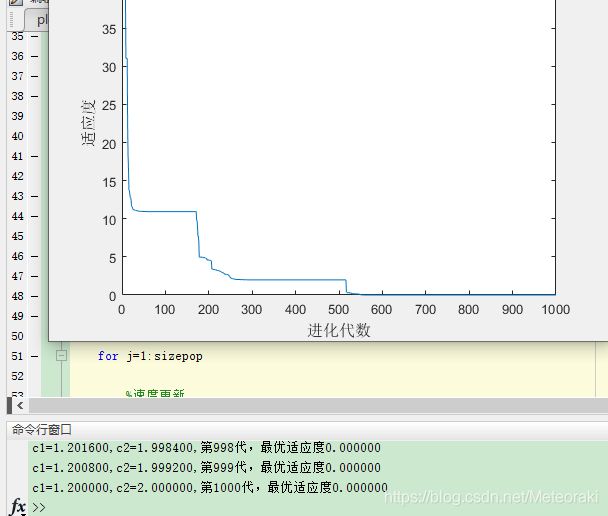
4.974795+0.000000+0.000000+3.979836+6.964713+3.979836+1.989918+3.979836+1.989918+5.969754=3.3828606
可见这样的迭代效率也不是很高。
c1 c2 交换参数变化也差不多。
以上的这里都按照线性的变化来迭代。
3.4源代码(将sizepop改为50)
2.984877+2.984877+4.974795+2.515301+2.984877+2.984877+0.994959+5.969754+4.974795+13.929417=4.5298529
效果不是很好!
3.3源代码(将适应度函数维数改变不同的值)
将适应度函数维度改为5
的适应度值:
0.000000+0.000000+0.000000+0.000000+0.000000+0.000000+0.000000+0.000000+0.000000=0
!!!!!!!!!!!!!!
将适应度函数维度改为20
的适应度值:
9.949591+10.944550+5.969754+6.964713+7.959672+12.934468+3.983015+6.964713+3.072335=非常大!!!!!!!!!!!!!!!
总是合适的参数设置有利于适应值的取到。
维度越小越容易也越快得到最正确的适应值。