MNIST手写数字体识别(全连接神经网络)
编程环境:win10,python3.6,Anaconda搭建tensorflow(CPU版),Pycharm添加anaconda中的tensorflow环境书写代码。环境安装搭建的话,参考网上资源。
Anaconda各版本安装包:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/,安装的是Anaconda3-5.2.0版本(python3.6)
Pycharm用的是社区版:https://www.jetbrains.com/pycharm/download/#section=windows
Anaconda搭建tensorflow:https://blog.csdn.net/u010858605/article/details/64128466/
参考书籍:《TensorFlow实战Google深度学习框架(第2版)》
mnist数字识别博客推荐参考:https://blog.csdn.net/briblue/article/details/80398369
- MNIST.py程序代码
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# mnist数据集相关的常数
INPUT_NODE = 784 # 输入节点,等于图片的像素
OUTPUT_NODE = 10 # 输出节点
# 配置神经网络的参数
LAYER1_NODE = 500 # 隐藏层节点数
BATCH_SIZE = 100 # 一个训练batch中的训练数据个数
LEARNING_RATE_BASE = 0.8 # 基础的学习率
LEARNING_RATE_DECAY = 0.99 # 学习率的衰减率
REGULARIZATION_RATE = 0.0001 # 描述模型复杂度的正则化项在损失函数中的系数
TRAINING_STEPS = 3000 # 训练轮数
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均衰减率
# 设计一个辅助函数,给定神经网络的输入和所有参数,计算神经网络的前向传播结果
# 使用tf.nn.relu激活函数实现去线性化
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
# 不使用滑动平均类
if avg_class == None:
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
else:
# 使用滑动平均类
layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1))
return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2)
# 训练模型
def train(mnist):
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input')
# 生成隐藏层的参数。
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
# 生成输出层的参数。
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
# 计算不含滑动平均类的前向传播结果
y = inference(x, None, weights1, biases1, weights2, biases2)
# 定义训练轮数及相关的滑动平均类
global_step = tf.Variable(0, trainable=False)
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2)
# 计算交叉熵及其平均值
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 损失函数的计算
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
regularization = regularizer(weights1) + regularizer(weights2)
loss = cross_entropy_mean + regularization
# 设置指数衰减的学习率。
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True)
# 优化损失函数,loss损失作为梯度下降算法的输入,minimize方法将loss一步步减小
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 训练数据时,每过一遍数都需要通过反向传播更新神经网络中的参数和更新每一个参数的滑动平均值
# tensoflow提供了tf.control_dependencies和tf.group机制来完成操作
# train_op = tf.group(train_step, variables_averages_op)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
# 计算正确率
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 初始化会话,并开始训练过程。
with tf.Session() as sess:
tf.global_variables_initializer().run()
validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels}
test_feed = {x: mnist.test.images, y_: mnist.test.labels}
# 循环的训练神经网络。
for i in range(TRAINING_STEPS):
if i % 100 == 0:
validate_acc, learn_loss = sess.run([accuracy, loss], feed_dict=validate_feed)
print("After %d training step(s), validation accuracy using average model is %g " % (i, validate_acc))
print("After %d training step(s), learn loss is %g " % (i, learn_loss))
# print(sess.run(weights1))
xs, ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_op, feed_dict={x: xs, y_: ys})
test_acc = sess.run(accuracy, feed_dict=test_feed)
print(("After %d training step(s), test accuracy using average model is %g" % (TRAINING_STEPS, test_acc)))
def main(argv=None):
# 声明处理MNIST数据集的类,这个类在初始化时会自动下载数据,"MNIST_data"文件夹存放mnist数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()


2.重构mnist书写数字体识别,将代码拆分为3个程序,分别为mnist_inference.py,定义了前向传播的过程以及神经网络中的参数;mnist_train.py,定义了神经网络的训练过程,在训练过程中每隔一段时间保存一次模型训练的中间结果;mnist_eval.py,定义了测试过程,每次运行都是读取最新保存的模型,并在MNIST验证数据集上计算模型的正确率。
- mnist_inference.py
import tensorflow as tf
# 定义神经网络结构相关的参数
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
# 通过tf.get_variable函数来获取变量
def get_weight_variable(shape, regularizer):
weights = tf.get_variable("weights", shape, initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(weights))
return weights
# 定义神经网络的前向传播过程
def inference(input_tensor, regularizer):
# 声明第一层神经网络的变量并完成前向传播过程
with tf.variable_scope('layer1'):
weights = get_weight_variable([INPUT_NODE, LAYER1_NODE], regularizer)
biases = tf.get_variable("biases", [LAYER1_NODE], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights) + biases)
# 类似的声明第二层神经网络的变量并完成前向传播过程
with tf.variable_scope('layer2'):
weights = get_weight_variable([LAYER1_NODE, OUTPUT_NODE], regularizer)
biases = tf.get_variable("biases", [OUTPUT_NODE], initializer=tf.constant_initializer(0.0))
layer2 = tf.matmul(layer1, weights) + biases
# 返回最后前向传播的结果
return layer2- mnist_train.py
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference # 加载定义的常量和前向传播的函数
import os
# 配置神经网络的参数
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径和文件名
MODEL_SAVE_PATH = "MNIST_model/"
MODEL_NAME = "mnist_model"
def train(mnist):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
# 初始化Tensorflow持久化类
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
# 每1000轮保存一次模型
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
def main(argv=None):
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()

- mnist_eval.py
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
import mnist_train
# 每五秒加载一次最新的模型,并在测试数据上测试最新模型的准确率
EVAL_INTERVAL_SECS = 5
def evaluate(mnist):
with tf.Graph().as_default() as g:
# 定义输入输出的格式
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels}
y = mnist_inference.inference(x, None)
predict = tf.argmax(y, 1)[0:10]
# 真实值
real = tf.argmax(y_, 1)[0:10]
# 使用前向传播的结果计算正确率。如果需要对未知的样例进行分类,那么使用tf.argmax(y, 1)就可以得到输入样例的预测类别
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 通过变量重命名的方式来加载模型
variable_average = tf.train.ExponentialMovingAverage(mnist_train.MOVING_AVERAGE_DECAY)
variable_to_restore = variable_average.variables_to_restore()
saver = tf.train.Saver(variable_to_restore)
# 每隔EVAL_INTERVAL_SECS秒调用一次计算正确率的过程以检测训练过程中正确率的变化
while True:
with tf.Session() as sess:
# 函数通过checkpoint文件自动找到目录中最新模型的文件名
ckpt = tf.train.get_checkpoint_state(mnist_train.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
# 加载模型
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy, feed_dict=validate_feed)
print("After %s training step(s), validation accuracy = %g" % (global_step, accuracy_score))
prediction = sess.run(predict, feed_dict=validate_feed)
real_value = sess.run(real, feed_dict=validate_feed)
# 输出前十个预测值和真实值
print('after %s training step(s), validation prediction is ' % (global_step), prediction)
print('after %s training step(s), real value is ' % (global_step), real_value)
else:
print('No checkpoint file found')
return
time.sleep(EVAL_INTERVAL_SECS)
def main(argv=None):
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
evaluate(mnist)
if __name__ == "__main__":
tf.app.run()

3.Tensorboard可视化mnist数据集
- 改进后的mnist_train.py(将功能放到tf.name.scope函数生成的上下文管理器中,同时生成日志文件):
# 展示可视化一个真实的神经网络结构图
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference # 加载定义的常量和前向传播的函数
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 3000
MOVING_AVERAGE_DECAY = 0.99
def train(mnist):
# 输入数据的命名空间。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 处理滑动平均的命名空间。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算损失函数的命名空间。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 定义学习率、优化方法及每一轮执行训练的操作的命名空间。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
writer = tf.summary.FileWriter("log", tf.get_default_graph())
# 训练模型。
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
if i % 100 == 0:
# 配置运行时需要记录的信息。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
_, loss_value, step = sess.run(
[train_op, loss, global_step], feed_dict={x: xs, y_: ys},
options=run_options, run_metadata=run_metadata)
writer.add_run_metadata(run_metadata=run_metadata, tag=("tag%d" % i), global_step=i)
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
writer.close()
def main(argv=None):
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
main()


在浏览器中输入:localhost:6006

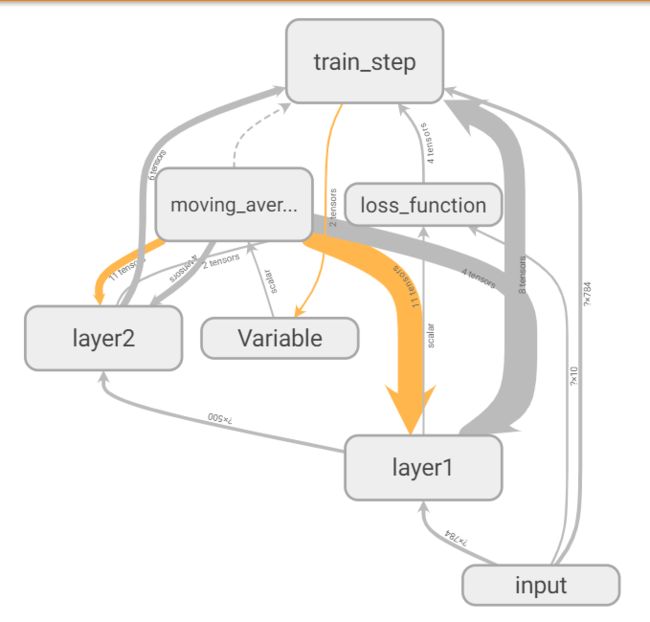
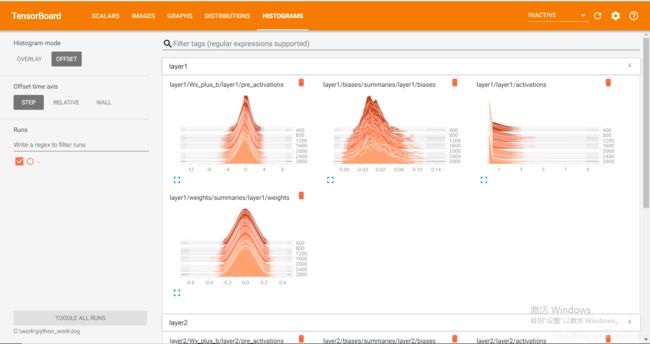
4.监控指标可视化:
Tensorflow除了可以可视化Tensorflow的计算图,还可以可视化Tensorflow程序运行过程中各种有助于了解程序运行状态的监控指标。
监控指标可视化.py
"""可视化TensorFlow程序,了解程序运行状态的监控指标"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
SUMMARY_DIR = "log"
BATCH_SIZE = 100
TRAIN_STEPS = 3000
def variable_summaries(var, name):
with tf.name_scope('summaries'):
tf.summary.histogram(name, var)
mean = tf.reduce_mean(var)
tf.summary.scalar('mean/' + name, mean)
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev/' + name, stddev)
# 生成一层全链接层神经网络
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
with tf.name_scope(layer_name):
with tf.name_scope('weights'):
weights = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
variable_summaries(weights, layer_name + '/weights')
with tf.name_scope('biases'):
biases = tf.Variable(tf.constant(0.0, shape=[output_dim]))
variable_summaries(biases, layer_name + '/biases')
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram(layer_name + '/pre_activations', preactivate)
activations = act(preactivate, name='activation')
# 记录神经网络节点输出在经过激活函数之后的分布。
tf.summary.histogram(layer_name + '/activations', activations)
return activations
def main():
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
hidden1 = nn_layer(x, 784, 500, 'layer1')
y = nn_layer(hidden1, 500, 10, 'layer2', act=tf.identity)
with tf.name_scope('cross_entropy'):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
tf.summary.scalar('cross_entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
with tf.Session() as sess:
summary_writer = tf.summary.FileWriter(SUMMARY_DIR, sess.graph)
tf.global_variables_initializer().run()
for i in range(TRAIN_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 运行训练步骤以及所有的日志生成操作,得到这次运行的日志。
summary, _ = sess.run([merged, train_step], feed_dict={x: xs, y_: ys})
# 将得到的所有日志写入日志文件,这样TensorBoard程序就可以拿到这次运行所对应的
# 运行信息。
summary_writer.add_summary(summary, i)
summary_writer.close()
if __name__ == '__main__':
main()



5.高位向量可视化:
mnist_prepare_projector_data.py
"""使用MNIST测试数据生成PROJECTOR所需要的两个文件:sprite图像和一个tsv文件给出每张图片对应的真实标签"""
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import os
from tensorflow.examples.tutorials.mnist import input_data
# PROJECT需要额日志文件名和地址相关参数
LOG_DIR = 'log'
SPRITE_FILE = 'mnist_sprite'
META_FILE = "mnist_meta.tsv"
# 使用给出的MNIST图片列表生成sprite图像
def create_sprite_image(images):
if isinstance(images, list):
images = np.array(images)
img_h = images.shape[1]
img_w = images.shape[2]
m = int(np.ceil(np.sqrt(images.shape[0])))
# 使用全1来初始化最终的大图片
sprite_image = np.ones((img_h*m, img_w*m))
for i in range(m):
for j in range(m):
# 计算当前图片的编号
cur = i * m + j
if cur < images.shape[0]:
sprite_image[i*img_h:(i+1)*img_h, j*img_w:(j+1)*img_w] = images[cur]
return sprite_image
# 加载MNIST数据
mnist = input_data.read_data_sets("MNIST_data",one_hot=False)
# 生成sprite图像
to_visualise = 1 - np.reshape(mnist.test.images, (-1, 28, 28))
sprite_image = create_sprite_image(to_visualise)
# 将生成sprite图像放到相应的日志目录下
path_for_mnist_sprites = os.path.join(LOG_DIR, SPRITE_FILE)
plt.imsave(path_for_mnist_sprites, sprite_image, cmap='gray')
# 生成每张图片对应的标签文件并写到相应的日志目录下
path_for_mnist_metadata = os.path.join(LOG_DIR, META_FILE)
with open(path_for_mnist_metadata, 'w') as f:
f.write("Index\tLable\n")
for index, label in enumerate(mnist.test.labels):
f.write("%d\t%d\n" % (index, label))mnist_projector.py:
"""使用TensorFlow代码生成PROJECTOR所需要的日志文件来可视化MNIST测试数据在最后的输出层向量"""
import tensorflow as tf
import mnist_inference
import os
# 加载用于生成projector日志的帮助函数
from tensorflow.contrib.tensorboard.plugins import projector
from tensorflow.examples.tutorials.mnist import input_data
# 定义训练模型需要的参数
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 10000 # 可以通过调整这个参数来控制训练迭代轮数
MOVING_AVERAGE_DECAY = 0.99
# 和日志文件相关的文件名和目录地址
LOG_DIR = 'log'
SPRITE_FILE = 'mnist_sprite.png'
META_FILE = "mnist_meta.tsv"
TENSOR_NAME = "FINAL_LOGITS"
def train(mnist):
# 输入数据的命名空间
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 将处理滑动平均相关的计算都放在moving_average的命名空间下
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
# 训练模型。
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run(
[train_op, loss, global_step], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (i, loss_value))
# 计算MNIST测试数据对应的输出层矩阵
final_result = sess.run(y, feed_dict={x: mnist.test.images})
# 返回输出层矩阵的值
return final_result
# 生成可视化最终输出层向量所需要的日志文件
def visualisation(final_result):
# 使用一个新的变量来保存最终输出层向量的结果
y = tf.Variable(final_result, name=TENSOR_NAME)
summary_writer = tf.summary.FileWriter(LOG_DIR)
# 通过projector.ProjectorConfig类来帮助生成日志文件
config = projector.ProjectorConfig()
# 增加一个需要可视化的embedding结果
embedding = config.embeddings.add()
# 制定这个embedding结果对应的TensorFlow变量名称
embedding.tensor_name = y.name
# 指定embedding结果所对应的原始数据信息
embedding.metadata_path = META_FILE
# 指定sprite图像
embedding.sprite.image_path = SPRITE_FILE
# 指定单张图片的大小,用于从sprite图像中截取正确的原始图片
embedding.sprite.single_image_dim.extend([28, 28])
# 将PROJECTOR所需要的内容写入日志文件
projector.visualize_embeddings(summary_writer, config)
# 生成会话,初始化新声明的变量并将需要的日志信息写入文件
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.save(sess, os.path.join(LOG_DIR, "model"), TRAINING_STEPS)
summary_writer.close()
# 主函数先调用模型训练的过程,再使用训练好的模型来处理MNIST测试数据,最后将得到的输出层矩阵输出到PROJRCTOR需要的日志文件中
def main(argv_None):
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
final_result = train(mnist)
visualisation(final_result)
if __name__ == '__main__':
tf.app.run()


