计算机视觉——全景图像拼接
计算机视觉——全景图像拼接
- 原理
- 全景图像
- APAP
- 具体实现过程
- 代码
- 运行结果
- 室外场景
- 成功
- 失败
- 室内场景
- 成功
- 失败
- 总结
原理
全景图像
在同一位置(即图像的照相机位置相同)拍摄的两幅或者多幅图像是单应性相关的。我们经常使用该约束将很多图像缝补起来,拼成一个大的图像来创建全景图像。
APAP
在图像拼接融合的过程中,受客观因素的影响,拼接融合后的图像可能会存在“鬼影现象”以及图像间过度不连续等问题。解决鬼影现象可以采用APAP算法。
算法流程:
1.提取两张图片的sift特征点
2.对两张图片的特征点进行匹配
3.匹配后,使用RANSAC算法进行特征点对的筛选,排除错误点。筛选后的特征点基本能够一一对应。
4.使用DLT算法,将剩下的特征点对进行透视变换矩阵的估计。
5.因为得到的透视变换矩阵是基于全局特征点对进行的,即一个刚性的单应性矩阵完成配准。为提高配准的精度,Apap将图像切割成无数多个小方块,对每个小方块进行单应性矩阵变换。
具体实现过程
实际上,SIFT 是具有很强稳健性的描述子,能够比其他描述子,例如图像块相关的 Harris 角点,产生更少的错误的匹配。但是该方法仍然远非完美。因此,需要配合使用ransac算法消除sift算法的错误匹配点。简要回顾ransac算法(具体的在上篇博客中):选择的4个对应点对然后拟合一个单应性矩阵。记住,4个点对是计算单应性矩阵所需的最少数目。对每个对应点对使用该单应性矩阵,然后返回相应的平方距离之和,因此 RANSAC 算法能够判定哪些点对是正确的,哪些是错误的。在实际中,我们需要在距离上使用一个阈值来决定哪些单应性矩阵是合理的。
选取一个图像 作为中心图像,也是我们希望将其他图像变成的图像。分别找到从右边扭曲和从左边扭曲的图像。在每个图像对中,由于匹配是从最右边的图像计算出来的,所以我们将对应的顺序进行颠倒,使其从左边图像开始扭曲。
通常,这里的公共平面为中心图像平面(否则,需要进行大量变形)。一种方法是创建一个很大的图像,比如图像中全部填充 0,使其和中心图像平行,然后将所有的图像扭曲到上面。由于我们所有的图像是由照相机水平旋转拍摄的,因此我们可以使用一个较简单的步骤:将中心图像左边或者右边的区域填充0,以便为扭曲的图像腾出空间。
但是由于每张图片的图像曝光不同,在单个图像的边界上存在边缘效应。
代码
from pylab import *
from numpy import *
from PIL import Image
# If you have PCV installed, these imports should work
from PCV.geometry import homography, warp
import sift
"""
This is the panorama example from section 3.3.
"""
# set paths to data folder
featname = ['../road'+str(i+1)+'.sift' for i in range(4)]
imname = ['../road'+str(i+1)+'.jpg' for i in range(4)]
# extract features and match
l = {}
d = {}
for i in range(4):
sift.process_image(imname[i],featname[i])
l[i],d[i] = sift.read_features_from_file(featname[i])
matches = {}
for i in range(3):
matches[i] = sift.match(d[i+1],d[i])
# visualize the matches (Figure 3-11 in the book)
for i in range(3):
im1 = array(Image.open(imname[i]))
im2 = array(Image.open(imname[i+1]))
figure()
sift.plot_matches(im2,im1,l[i+1],l[i],matches[i],show_below=True)
# function to convert the matches to hom. points
def convert_points(j):
ndx = matches[j].nonzero()[0]
fp = homography.make_homog(l[j+1][ndx,:2].T)
ndx2 = [int(matches[j][i]) for i in ndx]
tp = homography.make_homog(l[j][ndx2,:2].T)
# switch x and y - TODO this should move elsewhere
fp = vstack([fp[1],fp[0],fp[2]])
tp = vstack([tp[1],tp[0],tp[2]])
return fp,tp
# estimate the homographies
model = homography.RansacModel()
fp,tp = convert_points(1)
H_12 = homography.H_from_ransac(fp,tp,model)[0] #im 1 to 2
fp,tp = convert_points(0)
H_01 = homography.H_from_ransac(fp,tp,model)[0] #im 0 to 1
tp,fp = convert_points(2) #NB: reverse order
H_32 = homography.H_from_ransac(fp,tp,model)[0] #im 3 to 2
#tp,fp = convert_points(3) #NB: reverse order
#H_43 = homography.H_from_ransac(fp,tp,model)[0] #im 4 to 3
# warp the images
delta = 700 # for padding and translation
im1 = array(Image.open(imname[1]), "uint8")
im2 = array(Image.open(imname[2]), "uint8")
im_12 = warp.panorama(H_12,im1,im2,delta,delta)
im1 = array(Image.open(imname[0]), "f")
im_02 = warp.panorama(dot(H_12,H_01),im1,im_12,delta,delta)
im1 = array(Image.open(imname[3]), "f")
im_32 = warp.panorama(H_32,im1,im_02,delta,delta)
figure()
imshow(array(im_32, "uint8"))
axis('off')
show()
运行结果
室外场景
成功




小结:这是室外场景,由于拍摄时每次移动的幅度不大,因此拼接出的照片与原图大小相差不大(大部分重叠),图像也没有很明显的扭曲,只是在拼接的图像中间部分有较为明显的拼接线,有可能是转镜头时导致照片曝光程度不同的结果。
失败




小结:可以看出这是个十分失败的拼接。相邻图像之间填充了很多0像素(黑色像素),平移量也很大,导致相邻图像之间间隔很大。
改进:逐渐下调填充的像素数和平移量delta

中心图像两侧拼接痕迹比较明显,再次调整平移量,试图改进使拼接痕迹不明显
进一步下调delta:


小结:可以看出当像素填充量和平移量delta设置的相当小的时候,拼接后的图像基本上就是之前找的中心图像,拼接的效果就不明显,拼接就相当于无用了。推测可能是因为拍摄幅度太小,图像之间绝大部分都是相同的,匹配点很多(由sift匹配结果就可以看出)。
室内场景
成功




小结:由于镜头移动幅度适中,拍摄的图像之间的正确匹配点也比较多,因此计算出的单应性矩阵结果比较好,就可以拼接出一个比较好的全景图像,没有明显扭曲。因为是在室内拍摄,光照相对均衡,因此曝光的问题在室内显现的也不是很严重,就没有出现明显的拼接缝。
失败
![]()
拍摄室内场景会出现找不到合适的单应性矩阵匹配的错误。单独执行sift匹配时发现每个图像匹配出的匹配点比较少:

图像之间匹配点在经过ransac去除错误之后剩下的匹配点太少了,例如:
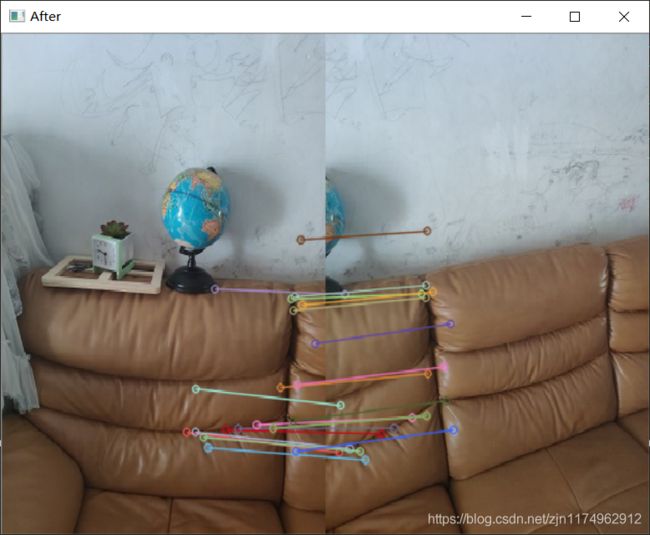
有可能因此就找不到合适的单应性变换矩阵。
总结
拍摄测试图像的注意点:为了拼接出效果比较好的图像,在保证有相同匹配点的情况下,拍摄图像的间隔尽可能不要太小,如果太小会导致拼接出来的结果与原图没有太大差别,丧失拼接图像的意义。但如果间隔太大可能会导致匹配点较少而拼接失败。且一定要站在同一点,水平移动手机进行拍摄,就像拍摄全景图那样。若人拍摄的位置发生移动的话,算法可能就会因为找不到正确的点对而报错。
在给图像编号进行测试时,一定要从右往左进行编号,因为我们的算法的匹配是从最右边的图像计算出来的,代码中有一步骤是将对应的顺序进行颠倒,使其从左边图像开始进行扭曲。如果要使用从左往右编号的方式要记得更改代码中的相应的求单应性变换矩阵的计算部分。