深度学习笔记三:反向传播(backpropagation)算法
接上一篇的最后,我们要训练多层网络的时候,最后关键的部分就是求梯度啦。纯数学方法几乎是不可能的,那么反向传播算法就是用来求梯度的,用了一个很巧妙的方法。
反向传播算法应该是神经网络最基本最需要弄懂的方法了,要是反向传播方法不懂,后面基本上进行不下去。
非常推荐的是How the backpropagation algorithm works
在最开始的博客中提过,这本书是这篇笔记用到的教材之一,这节反向传播也是以上面那个链接中的内容作为笔记的,因为反向传播部分写的很好。
首先,需要记住两点:
1.反向传播算法告诉我们当我们改变权值(weights)和偏置(biases)的时候,损失函数改变的速度。
2.反向传播也告诉我们如何改变权值和偏置以改变神经网络的整体表现。
一.表达形式复习
这里的表示形式指的是,我们怎么用数学的方式来表示整个神经网络中的各个权值偏置激活函数等等,以及其矩阵形式,算是对于后面推导过程的约定。详细的之前写过了:神经网络(一):概念
这里稍微复习一下。
对于权值来说:
我们用![]() 来表示从
来表示从![]() 层的第k个神经元到第
层的第k个神经元到第![]() 层第j个神经元之间的权重。
层第j个神经元之间的权重。
比如下面这幅图就是第2层的第4个元素到第三层的第二个元素之间的权重。

对于偏置来说:
我们用![]() 来表示第
来表示第![]() 层第j个神经元上的偏置。
层第j个神经元上的偏置。
对于激活值来说:
我们用![]() 来表示第
来表示第![]() 层第j个神经元上的激活值。
层第j个神经元上的激活值。

比如上面的第二层的第三个神经元的偏置和第三层第一个神经元的激活值。其实很容易理解。这里要注意,因为是多层结构,如果这层不是输出层,那么这个激活值作为下一层的一个输入。
那么激活值,偏置和权重之前有什么关系呢?
之前假设过我们现在只有sigmoid函数作为激活函数,参考神经网络(一):概念,可以知道:

解释一下这个公式,假如上一层有k个神经元,产生k和激活值,那么这些激活值在这层就被用作输入,这些输入作用在这层的的第j个神经元上,是不是就能够写成上面的表达式了。。很容易理解。
然后写成矩阵形式为:
![]()
矩阵形式在神经网络(一):概念中有详细解释,这里就不浪费篇幅了。
我们把中间量![]() 计算出来,单独命名为
计算出来,单独命名为![]() ,我们把这个叫做加权输入。那么
,我们把这个叫做加权输入。那么![]() 可以写为
可以写为![]() ,后面会证明,这个中间量是非常的重要的。
,后面会证明,这个中间量是非常的重要的。
二.反向传播的四个基本方程
在最开始,定义![]() 层第j个神经元上面的误差(error)
层第j个神经元上面的误差(error)![]() 为
为
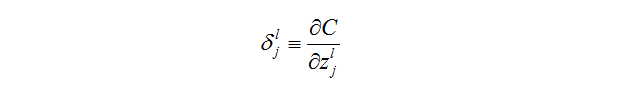
其中的![]() 就是上面提到过得加权输入了。
就是上面提到过得加权输入了。
这么定义的原因,可以看How the backpropagation algorithm works这里恶魔的小故事,很有趣。我们使用![]() 向量化,表示一层上面所有神经元的误差。加入这个误差项的定义,可以让讨论变得简单。
向量化,表示一层上面所有神经元的误差。加入这个误差项的定义,可以让讨论变得简单。
接下来就是一个个推导反向传播的方程了,首先把这几个公式先列出来。

别晕,下面慢慢解释。
Ⅰ.输出层误差(error)
我们用大写的L表示神经网络最后一层(输出层),![]() 就表示输出层的误差了,且由以下方程给出:
就表示输出层的误差了,且由以下方程给出:
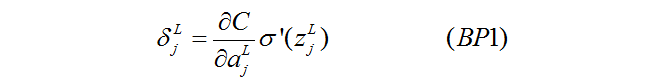
证明:
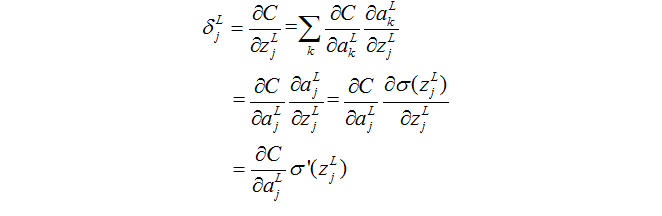
解释:
首先看上面证明的第一行,我们知道损失函数的形式,输出层的每一个输出都能够看作是损失函数的一个变量。
要是不理解的话,假设我们这里的损失函数为之前提到过的二次函数:

在神经网络里面可以写为上面的形式,因为一个网络的输出就是最后一层的输出嘛。这下能不能够明显的理解上面的那句话了呢?
那么证明第一行就是通过链式法则得到的。
然后只有![]() 和
和![]() 是有依赖关系的,其他的没有依赖关系的求导为0不见了,因此,只剩下第二行。第二行出来了,又因为
是有依赖关系的,其他的没有依赖关系的求导为0不见了,因此,只剩下第二行。第二行出来了,又因为![]() ,那么后面的也就都容易推出来了。
,那么后面的也就都容易推出来了。
怎么理解:
我们怎么形象来理解BP1这个公式呢?
![]() :
:
度量了损失函数作为第j个激活输出的函数的变化程度。
![]() :
:
度量了激活函数在某个加权输入处的变化程度.
向量化:
BP1是以某个神经元为单位的,写成向量化也很容易:
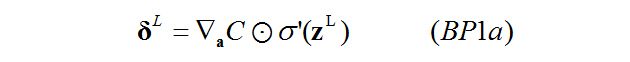
这里的误差表示的是输出层一整层的误差向量(每一个神经元误差的向量):
不理解的看下面的细节:
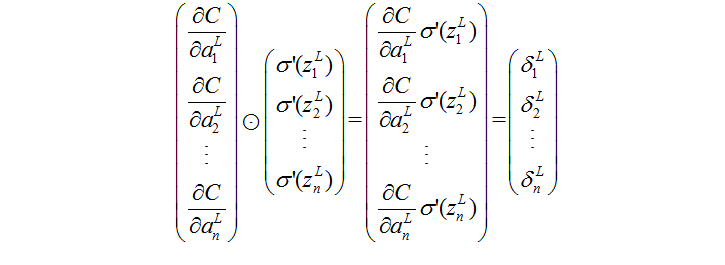
或者写为下面的形式:
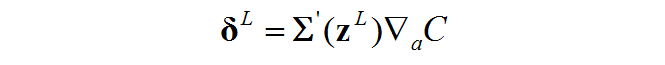
细节如下:

Ⅱ.非输出层的误差依赖于其下一层误差
怎么理解这句话呢?先丢一个公式:
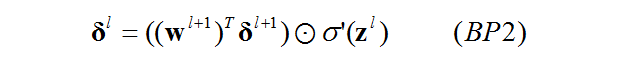
证明:

解释:
首先看(I)式,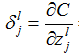 就是误差(error)的定义,这个简单。
就是误差(error)的定义,这个简单。
 这个就是链式法则啦,我们知道前一层的输出可以作为后一层的输入,也就是说,可以认为前一层的z算式后一层z的变量(别晕)。应用复合函数链式法则,就能够得到这个式子了。
这个就是链式法则啦,我们知道前一层的输出可以作为后一层的输入,也就是说,可以认为前一层的z算式后一层z的变量(别晕)。应用复合函数链式法则,就能够得到这个式子了。
![]() 相当于l+1层的误差啦,所以可以简化为
相当于l+1层的误差啦,所以可以简化为![]() 。
。
再来看(II)式,这个公式就是计算z的,更加简单。不解释了。然后(II)式求偏导之后得到![]() 代入(I)的最终结果,就得到上面的结果了
代入(I)的最终结果,就得到上面的结果了
BP2是上面这个式子的向量形式。在之前链接的博客中有权值矩阵的详细说明。可以看一下,这里不浪费篇幅了。
理解:
通过这个公式,只要我知道l+1层的误差,那么我就能够知道l层的误差,由此,我就能够倒退直到第1层的误差。
这个式子就体现了误差的反向传播的特点。
然后BP1和BP2结合起来,我们就能够求出神经网络中任何一层,任何一个神经元上面的误差。
矩阵形式:
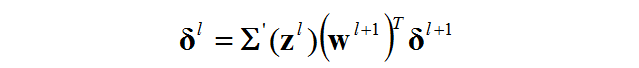
其中
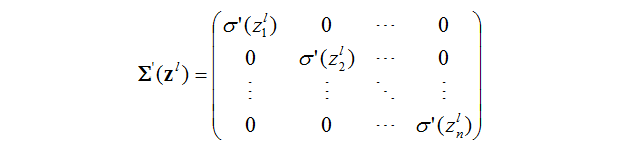
Ⅲ.损失函数关于任意偏置的偏导数

证明:
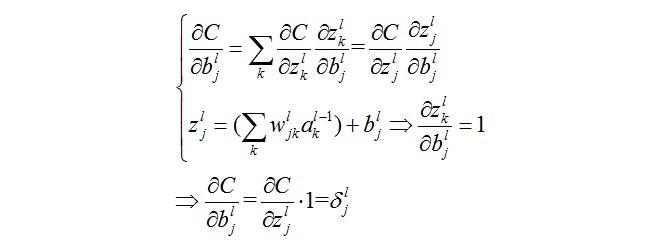
还是链式法则的老套路,很简单,就不解释啦。
理解:
这个公式告诉我们,某个神经元上面误差对于偏置的偏导要等于在这个神经元上面的误差。
而我们之前已经说过了,我们要求梯度的话就需要求出这些偏导,现在通过误差间接得到了偏导。很巧妙。
Ⅳ.损失函数关于任意权值的偏导数

证明:

同样也是链式求导老套路,不解释啦。
理解:
如果还记得之前讲过的下标的意义的话,可以知道这个公式链接了第l层第j个神经元的误差,以及上一层第k个神经元的输出。不影响含义的情况下可以写为:

可以用下图形象表示:
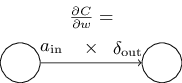
从这个式子可以知道,当输入的激活值(activation)
很小的时候,比如:
,那么相应的梯度
也会变得很小。要是梯度变得很小的话,那么依赖于梯度下降算法来更新权重将会变得很慢。也就是说,某个权重连接的上一个输入激活值很小的话,那么这个权重的学习就会很慢。
至此,四个基本的公式就介绍完成了,再贴一次加深印象。
这里要说明一下,其实很多的深度学习框架已经帮你把求导,梯度等等工作都完成了,使用框架的时候可以很轻松的不去想底层的东西。但是这并不意味着不需要了解原理了。这些公式可以不用记下来。但是要知道他们是怎么推出来的,背后的思想是什么。
然后再来深入回顾一下这几个公式:
BP1:假如我们这里的输出层用的是sigmoid(以后会讨论不同的激活函数),这个函数的形状你应该很熟悉了。他的值域为(0,1),而且函数值趋向于0和趋向于1的时候,函数都变得平坦,意味着这个函数的导数越来越趋向于0。![]() 。那么根据BP1你可以知道最后一层的误差也会变得很小,根据BP3和BP4,权值和偏置学习的速度也会变得很小。所以,对于sigmoid激活函数来说,当输出层的激活值过大或者过小的时候,学习速度都会变小,我们称输出函数已经饱和(saturated)
。那么根据BP1你可以知道最后一层的误差也会变得很小,根据BP3和BP4,权值和偏置学习的速度也会变得很小。所以,对于sigmoid激活函数来说,当输出层的激活值过大或者过小的时候,学习速度都会变小,我们称输出函数已经饱和(saturated)
BP2:因为非输出层的误差受到其下一层的误差决定(具体看公式),也就是说,要是输出层“饱和”,那么输出层的误差变小,那么非输出层的误差也将变得小(这里可能要思考一下)。而误差变小,根据BP3和BP4,直接导致学习速度的变小。
前面说的总结起来就是:当输入的神经元的激活值很低,或者输出层神经元饱和了(过高激活或者过低激活),都将导致学习速度的降低。
上面的结论也启发我们设计一些激活函数:比如说避免激活函数的导数等于0(原因见上面),这里不讨论过多了,后面的笔记再说。
三.反向传播过程总结
Ⅰ.输入
对于输入x,为输入层设置合适的激活函数
Ⅱ.前向传播
对于各层:l=2,3,…,L 前向的计算一遍结果
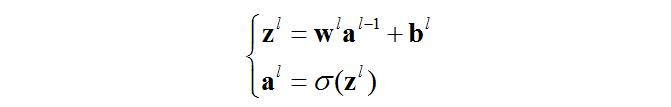
Ⅲ.计算输出层的误差
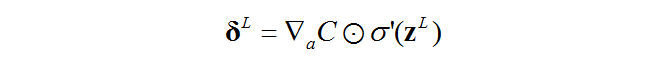
Ⅳ.反向传播误差.
对于各层: l=L−1,L−2,…,2
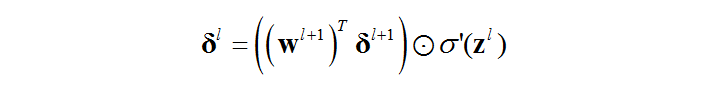
Ⅴ.计算并且更新权重和偏置
