Linux中CPU与内存性能监测
在系统维护的过程中,随时可能有需要查看 CPU 使用率内存使用情况的需要,尤其是涉及到JVM,程序调优的情况,并根据相应信息分析系统状况的需要。
top命令
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。运行 top 命令后,CPU 使用状态会以全屏的方式显示,并且会处在对话的模式 -- 用基于 top 的命令,可以控制显示方式等等。退出 top 的命令为 q (在 top 运行中敲 q 键一次)。
可以直接使用top命令后,查看%MEM的内容。可以选择按进程查看或者按用户查看,如想查看oracle用户的进程内存使用情况的话可以使用top -u oracle,以下为在CentOS中top命令的截图:
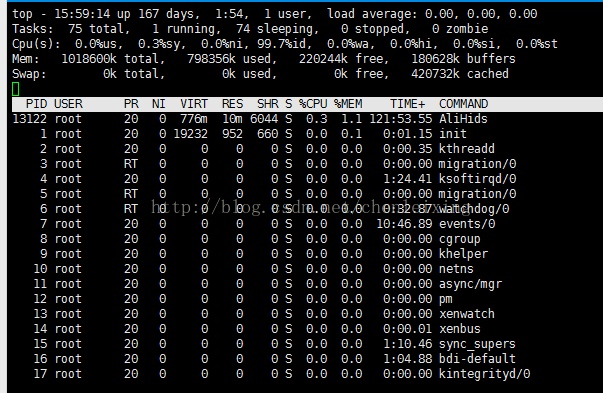
内容解释:
第一行(top):
15:59:14 系统当前时刻
167 days 系统启动后到现在的运作时间
1 user 当前登录到系统的用户,更确切的说是登录到用户的终端数 -- 同一个用户同一时间对系统多个终端的连接将被视为多个用户连接到系统,这里的用户数也将表现为终端的数目
load average 当前系统负载的平均值,后面的三个值分别为1分钟前、5分钟前、15分钟前进程的平均数,一般的可以认为这个数值超过 CPU 数目时,CPU 将比较吃力的负载当前系统所包含的进程
第二行(Tasks):
75 total 当前系统进程总数
1 running 当前运行中的进程数
74 sleeping 当前处于等待状态中的进程数
0 stoped 被停止的系统进程数
0 zombie 僵尸进程数
第三行(Cpus):
0.0% us 用户空间占用CPU百分比
0.3% sy 内核空间占用CPU百分比
0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比
99.7% id 空闲CPU百分比
0.0% wa 等待输入输出的CPU时间百分比
0.0% hi
0.0% si
0.0% st
第四行(Mem):
1018600k total 物理内存总量
798356k used 使用的物理内存总量
220244k free 空闲内存总量
180628k buffers 用作内核缓存的内存量
Swap: 192772k total 交换区总量
0k used 使用的交换区总量
192772k free 空闲交换区总量
123988k cached 缓冲的交换区总量
第五行(Swap):
表示类别同第四行(Mem),但此处反映着交换分区(Swap)的使用情况。通常,交换分区(Swap)被频繁使用的情况,将被视作物理内存不足而造成的。
0k total 交换区总量
0k used 使用的交换区总量
0k free 空闲交换区总量
420732k cached 缓冲的交换区总量
最下部分的进程列表栏:
以 PID 区分的进程列表将根据所设定的画面更新时间定期的更新。通过 top 内部命令可以控制此处的显示方式:
PID:进程的ID
USER:进程所有者
PR:进程的优先级别,越小越优先被执行
NInice:值
VIRT:进程占用的虚拟内存
RES:进程占用的物理内存
SHR:进程使用的共享内存
S:进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数
%CPU:进程占用CPU的使用率
%MEM:进程使用的物理内存和总内存的百分比
TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。
COMMAND:进程启动命令名称
top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下表:
s- 改变画面更新频率
l - 关闭或开启第一部分第一行 top 信息的表示
t - 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示
m - 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示
N - 以 PID 的大小的顺序排列表示进程列表(第三部分后述)
P - 以 CPU 占用率大小的顺序排列进程列表 (第三部分后述)
M - 以内存占用率大小的顺序排列进程列表 (第三部分后述)
h - 显示帮助
n - 设置在进程列表所显示进程的数量
q - 退出 top
s -改变画面更新周期
sar命令
sar命令也是Linux系统中重要的性能监测工具之一,它可以周期性地对内存和CPU使用情况进行采样。
基本语法如下:
sar [options] [-A] [-o file] t [n]
在命令行中,n 和t 两个参数组合起来定义采样间隔和次数,t为采样间隔,是必须有
的参数,n为采样次数,是可选的,默认值是1,-o file表示将命令结果以二进制格式
存放在文件中,file 在此处不是关键字,是文件名。options 为命令行选项,sar命令
的 选项很多,下面只列出常用选项:
-A:所有报告的总和
-u:CPU利用率
-v:进程、I节点、文件和锁表状态
-d:硬盘使用报告
-r:没有使用的内存页面和硬盘块
-g:串口I/O的情况
-b:缓冲区使用情况
-a:文件读写情况
-c:系统调用情况
-R:进程的活动情况
-y:终端设备活动情况
-w:系统交换活动
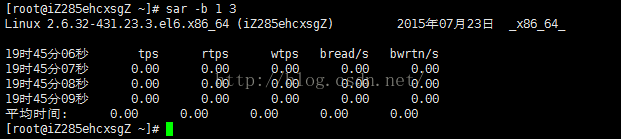
例一:
获取I/O信息,每秒钟采样一次,共计采样3次:
例二:使用命行sar -v t n
例如,每30秒采样一次,连续采样5次,观察核心 表的状态,需键入如下命令:
# sar -v 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
10:33:23 proc-sz ov inod-sz ov file-sz ov lock-sz (-v)
10:33:53 305/ 321 0 1337/2764 0 1561/1706 0 40/ 128
10:34:23 308/ 321 0 1340/2764 0 1587/1706 0 37/ 128
10:34:53 305/ 321 0 1332/2764 0 1565/1706 0 36/ 128
10:35:23 308/ 321 0 1338/2764 0 1592/1706 0 37/ 128
10:35:53 308/ 321 0 1335/2764 0 1591/1706 0 37/ 128 显示内容包括:
proc-sz:目前核心中正在使用或分配的进程表的表 项数,由核心参数MAX-PROC控制。
inod-sz:目前核心中正在使用或分配的i节点表的表项数,由核心参数 MAX- INODE控制。
file-sz: 目前核心中正在使用或分配的文件表的表项数,由核心参数MAX-FILE控 制。
ov:溢出出现的次数。
Lock-sz:目前核心中正在使用或分配的记录加锁的表项数,由核心参数MAX-FLCKRE控 制。
显示格式为
实际使用表项/可以使用的表项数显示内容表示,核心使用完全正常,三个表没有出现 溢出现象,核心参数不需调整,如果出现溢出时,要调整相应的核心参数,将对应的表项数加大。
例三:使用命行sar -d t n
例如,每30秒采样一次,连续采样5次,报告设备使用情况,需键入如下命令:
# sar -d 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
11:06:43 device %busy avque r+w/s blks/s avwait avserv (-d)
11:07:13 wd-0 1.47 2.75 4.67 14.73 5.50 3.14
11:07:43 wd-0 0.43 18.77 3.07 8.66 25.11 1.41
11:08:13 wd-0 0.77 2.78 2.77 7.26 4.94 2.77
11:08:43 wd-0 1.10 11.18 4.10 11.26 27.32 2.68
11:09:13 wd-0 1.97 21.78 5.86 34.06 69.66 3.35
Average wd-0 1.15 12.11 4.09 15.19 31.12 2.80
显示内容包括:
device: sar命令正在监视的块设备的名字。
%busy: 设备忙时,传送请求所占时间的百分比。
avque: 队列站满时,未完成请求数量的平均值。
r+w/s: 每秒传送到设备或从设备传出的数据量。
blks/s: 每秒传送的块数,每块512字节。
avwait: 队列占满时传送请求等待队列空闲的平均时间。
avserv: 完成传送请求所需平均时间(毫秒)。
在显示的内容中,wd-0是硬盘的名字,%busy的值比较小,说明用于处理传送请求的有 效 时间太少,文件系统效率不高,一般来讲,%busy值高些,avque值低些,文件系统 的效率比较高,如果%busy和avque值相对比较 高,说明硬盘传输速度太慢,需调整。
例四:使用命行sar -b t n
例如,每30秒采样一次,连续采样5次,报告缓冲区的使用情 况,需键入如下命令:
# sar -b 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
14:54:59 bread/s lread/s %rcache bwrit/s lwrit/s %wcache pread/s pwrit/s (-b)
14:55:29 0 147 100 5 21 78 0 0
14:55:59 0 186 100 5 25 79 0 0
14:56:29 4 232 98 8 58 86 0 0
14:56:59 0 125 100 5 23 76 0 0
14:57:29 0 89 100 4 12 66 0 0
Average 1 156 99 5 28 80 0 0
显示内容包括:
bread/s: 每秒从硬盘读入系统缓冲区buffer的物理块数。
lread/s: 平均每秒从系统buffer读出的逻辑块数。
%rcache: 在buffer cache中进行逻辑读的百分比。
bwrit/s: 平均每秒从系统buffer向磁盘所写的物理块数。
lwrit/s: 平均每秒写到系统buffer逻辑块数。
%wcache: 在buffer cache中进行逻辑读的百分比。
pread/s: 平均每秒请求物理读的次数。
pwrit/s: 平均每秒请求物理写的次数。
在显示的内容中,最重要的是%cache 和%wcache两列,它们的值体现着buffer的使用效 率,%rcache的值小于90或者%wcache的值低于65,应适当增加系统 buffer的数量,buffer 数量由核心参数NBUF控制,使%rcache达到90左右,%wcache达到80左右。但buffer参 数值的多少影响I/O效率,增加buffer,应在较大内存的情况下,否则系统效率反而得不到提高。
例五:使用命行sar -g t n
例 如,每30秒采样一次,连续采样5次,报告串口I/O的操作情况,需键入如下命令:
# sar -g 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 11/22/2001
17:07:03 ovsiohw/s ovsiodma/s ovclist/s (-g)
17:07:33 0.00 0.00 0.00
17:08:03 0.00 0.00 0.00
17:08:33 0.00 0.00 0.00
17:09:03 0.00 0.00 0.00
17:09:33 0.00 0.00 0.00
Average 0.00 0.00 0.00 显示内容包括:
ovsiohw/s:每秒在串口I/O硬件出现的溢出。
ovsiodma/s: 每秒在串口I/O的直接输入输出通道高速缓存出现的溢出。
ovclist/s :每秒字符队列出现的溢出。
在显示的内容中,每一列的 值都是零,表明在采样时间内,系统中没有发生串口I/O溢 出现象。
sar命令的用法很多,有时判断一个问题,需要几个sar 命令结合起来使用,比如,怀疑 CPU存在瓶颈,可用sar -u 和sar -q来看,怀疑I/O存在瓶颈,可用sar -b、sar -u和 sar-d来看。
vmstat命令
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:

3表示每个三秒采集一次服务器状态,2表示只采集两次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想直接结束vmstat监控,那么就直接把后边的表示采集次数的去掉即可,如:
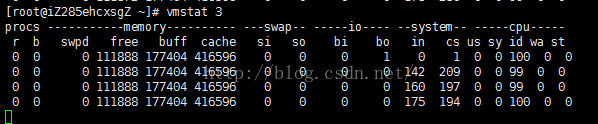
其中,各个参数的意义如下:
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
iostat命令
iostat命令主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
语法:
iostat [ -c ] [ -d ] [ -h ] [ -N ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ -z ] [ device [...] | ALL ] [ -p [ device [,...] | ALL ] ] [ interval [ count ] ]如 iostat -d -k 1
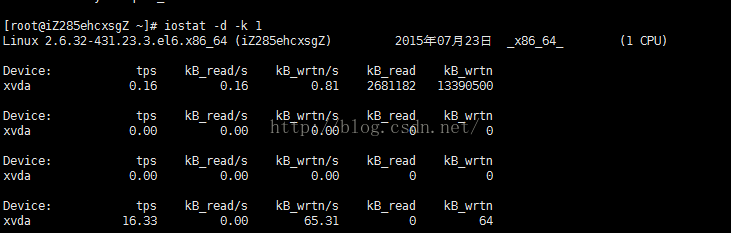
参数 -d 表示,显示设备(磁盘)使用状态;-k某些使用block为单位的列强制使用Kilobytes为单位;1表示,数据显示每隔1秒刷新一次。
详细内容,请参考博文:Linux IO实时监控iostat命令详解
pidstat命令
pidstat命令用来监控被Linux内核管理的独立任务(进程)。它输出每个受内核管理的任务的相关信息。pidstat命令也可以用来监控特定进程的子进程。间隔参数用于指定每次报告间的时间间隔。它的值为0(或者没有参数)说明进程的统计数据的时间是从系统启动开始计算的。
pidstat 是sysstat软件套件的一部分,sysstat包含很多监控linux系统状态的工具,它能够从大多数linux发行版的软件源中获得。
在Debian/Ubuntu系统中可以使用下面的命令来安装:
# apt-get install sysstat
CentOS/Fedora/RHEL版本的linux中则使用下面的命令:
# yum install sysstat
默认参数
执行pidstat,将输出系统启动后所有活动进程的cpu统计信息:
linux:~ # pidstat
Linux 2.6.32.12-0.7-default (linux) 06/18/12 _x86_64_
11:37:19 PID %usr %system %guest %CPU CPU Command
……
11:37:19 11452 0.00 0.00 0.00 0.00 2 bash
11:37:19 11509 0.00 0.00 0.00 0.00 3 dd指定采样周期和采样次数
pidstat命令指定采样周期和采样次数,命令形式为”pidstat [option] interval [count]”,以下pidstat输出以2秒为采样周期,输出10次cpu使用统计信息:
pidstat 2 10cpu使用情况统计(-u)
使用-u选项,pidstat将显示各活动进程的cpu使用统计,执行”pidstat -u”与单独执行”pidstat”的效果一样。
内存使用情况统计(-r)
使用-r选项,pidstat将显示各活动进程的内存使用统计:
以上各列输出的含义如下:
IO情况统计(-d)
使用-d选项,我们可以查看进程IO的统计信息:
输出信息含义
kB_rd/s: 每秒进程从磁盘读取的数据量(以kB为单位)
kB_wr/s: 每秒进程向磁盘写的数据量(以kB为单位)
Command: 拉起进程对应的命令针对特定进程统计(-p)
使用-p选项,我们可以查看特定进程的系统资源使用情况:
pidstat常用命令
使用pidstat进行问题定位时,以下命令常被用到:
pidstat -u 1
pidstat -r 1
pidstat -d 1以上命令以1秒为信息采集周期,分别获取cpu、内存和磁盘IO的统计信息。
pmap命令
可以根据进程查看进程相关信息占用的内存情况。
用法
pmap [ -x | -d ] [ -q ] pids...
pmap -V
选项含义
-x extended Show the extended format. 显示扩展格式
-d device Show the device format. 显示设备格式
-q quiet Do not display some header/footer lines. 不显示头尾行
-V show version Displays version of program. 显示版本
扩展格式和设备格式域:
Address: start address of map 映像起始地址
Kbytes: size of map in kilobytes 映像大小
RSS: resident set size in kilobytes 驻留集大小
Dirty: dirty pages (both shared and private) in kilobytes 脏页大小
Mode: permissions on map 映像权限: r=read, w=write, x=execute, s=shared, p=private (copy on write)
Mapping: file backing the map , or '[ anon ]' for allocated memory, or '[ stack ]' for the program stack. 映像支持文件,[anon]为已分配内存 [stack]为程序堆栈
Offset: offset into the file 文件偏移
Device: device name (major:minor) 设备名
如:
pmap -d 6292
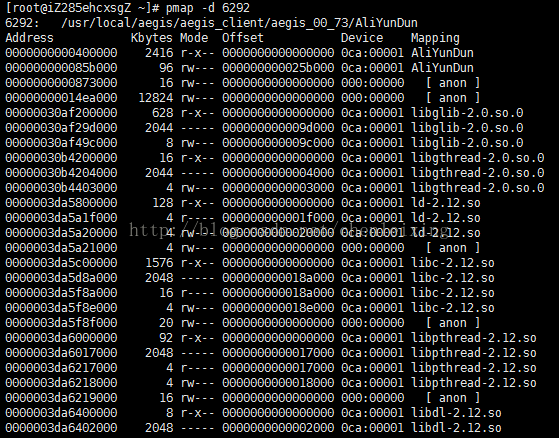
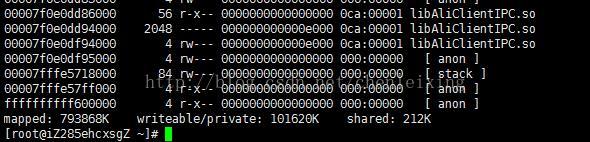
最后一行的值
mapped 表示该进程映射的虚拟地址空间大小,也就是该进程预先分配的虚拟内存大小,即ps出的vsz
writeable/private 表示进程所占用的私有地址空间大小,也就是该进程实际使用的内存大小
shared 表示进程和其他进程共享的内存大小
ps命令
以下来源《鸟哥的linux私房菜》
ps:将某个时间点的程序运作情况撷取下来
[root@linux ~]# ps aux
[root@linux ~]# ps -lA
[root@linux ~]# ps axjf
参数:
-A :所有的 process 均显示出来,与 -e 具有同样的效用;
-a :不与 terminal 有关的所有 process ;
-u :有效使用者 (effective user) 相关的 process ;
-x :通常与 a 这个参数一起使用,可列出较完整信息。
输出格式规划:
-l :较长、较详细的将该 PID 的的信息列出;
-j :工作的格式 (jobs format)
-f :做一个更为完整的输出。
特别说明:
由于 ps 能够支持的 OS 类型相当的多,所以他的参数多的离谱!
而且有没有加上 - 差很多!详细的用法应该要参考 man ps 喔!
范例1:将目前属于您自己这次登入的 PID 与相关信息列示出来
[root@linux ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 0 5881 5654 0 76 0 - 1303 wait pts/0 00:00:00 su
4 S 0 5882 5881 0 75 0 - 1349 wait pts/0 00:00:00 bash
4 R 0 6037 5882 0 76 0 - 1111 - pts/0 00:00:00 ps
# 上面这个信息其实很多喔!各相关信息的意义为:
# F 代表这个程序的旗标 (flag), 4 代表使用者为 super user;
# S 代表这个程序的状态 (STAT),关于各 STAT 的意义将在内文介绍;
# PID 没问题吧!?就是这个程序的 ID 啊!底下的 PPID 则上父程序的 ID;
# C CPU 使用的资源百分比
# PRI 这个是 Priority (优先执行序) 的缩写,详细后面介绍;
# NI 这个是 Nice 值,在下一小节我们会持续介绍。
# ADDR 这个是 kernel function,指出该程序在内存的那个部分。如果是个 running
# 的程序,一般就是『 - 』的啦!
# SZ 使用掉的内存大小;
# WCHAN 目前这个程序是否正在运作当中,若为 - 表示正在运作;
# TTY 登入者的终端机位置啰;
# TIME 使用掉的 CPU 时间。
# CMD 所下达的指令为何!?
# 仔细看到每一个程序的 PID 与 PPID 的相关性为何喔!上头列出的三个程序中,
# 彼此间可是有相关性的吶!
范例2:列出目前所有的正在内存当中的程序
[root@linux ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 1740 540 ? S Jul25 0:01 init [3]
root 2 0.0 0.0 0 0 ? SN Jul25 0:00 [ksoftirqd/0]
root 3 0.0 0.0 0 0 ? S< Jul25 0:00 [events/0]
.....中间省略.....
root 5881 0.0 0.3 5212 1204 pts/0 S 10:22 0:00 su
root 5882 0.0 0.3 5396 1524 pts/0 S 10:22 0:00 bash
root 6142 0.0 0.2 4488 916 pts/0 R+ 11:45 0:00 ps aux
• USER:该 process 属于那个使用者账号的?
• PID :该 process 的号码。
• %CPU:该 process 使用掉的 CPU 资源百分比;
• %MEM:该 process 所占用的物理内存百分比;
• VSZ :该 process 使用掉的虚拟内存量 (Kbytes)
• RSS :该 process 占用的固定的内存量 (Kbytes)
• TTY :该 process 是在那个终端机上面运作,若与终端机无关,则显示 ?,另外, tty1-tty6 是本机上面的登入者程序,若为 pts/0 等等的,则表示为由网络连接进主机的程序。
• STAT:该程序目前的状态,主要的状态有:
o R :该程序目前正在运作,或者是可被运作;
o S :该程序目前正在睡眠当中 (可说是 idle 状态啦!),但可被某些讯号 (signal) 唤醒。
o T :该程序目前正在侦测或者是停止了;
o Z :该程序应该已经终止,但是其父程序却无法正常的终止他,造成 zombie (疆尸) 程序的状态
• START:该 process 被触发启动的时间;
• TIME :该 process 实际使用 CPU 运作的时间。
• COMMAND:该程序的实际指令为何?
范例3:以范例一的显示内容,显示出所有的程序
[root@linux ~]# ps -lA
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 1 0 0 76 0 - 435 - ? 00:00:01 init
1 S 0 2 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/0
1 S 0 3 1 0 70 -5 - 0 worker ? 00:00:00 events/0
.....以下省略.....
范例4:列出类似程序树的程序显示
[root@linux ~]# ps -axjf
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
0 1 0 0 ? -1 S 0 0:01 init [3]
1 2 0 0 ? -1 SN 0 0:00 [ksoftirqd/0]
.....中间省略.....
1 5281 5281 5281 ? -1 Ss 0 0:00 /usr/sbin/sshd
5281 5651 5651 5651 ? -1 Ss 0 0:00 \_ sshd: dmtsai [priv]
5651 5653 5651 5651 ? -1 S 500 0:00 \_ sshd: dmtsai@pts/0
5653 5654 5654 5654 pts/0 6151 Ss 500 0:00 \_ -bash
5654 5881 5881 5654 pts/0 6151 S 0 0:00 \_ su
5881 5882 5882 5654 pts/0 6151 S 0 0:00 \_ bash
5882 6151 6151 5654 pts/0 6151 R+ 0 0:00 \_ ps -axjf
范例5:找出与 cron 与 syslog 这两个服务有关的 PID 号码
[root@linux ~]# ps aux | egrep '(cron|syslog)'
root 1539 0.0 0.1 1616 616 ? Ss Jul25 0:03 syslogd -m 0
root 1676 0.0 0.2 4544 1128 ? Ss Jul25 0:00 crond
root 6157 0.0 0.1 3764 664 pts/0 R+ 12:10 0:00 egrep (cron|syslog)
在预设的情况下, ps 仅会列出与目前所在的 bash shell 有关的 PID 而已,所以, 当我使用 ps -l 的时候,只有三个 PID (范例一)。
free命令
在Linux下查看内存我们一般用free命令:
[root@scs-2 tmp]# free
total used free shared buffers cached
Mem: 3266180 3250004 16176 0 110652 2668236
-/+ buffers/cache: 471116 2795064
Swap: 2048276 80160 1968116 下面是对这些数值的解释:
total:总计物理内存的大小
used:已使用多大
free:可用有多少
Shared:多个进程共享的内存总额
Buffers/cached:磁盘缓存的大小
第三行(-/+ buffers/cached):
used:已使用多大。
free:可用有多少。
第四行就不多解释了。
区别:第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。 这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是16176KB,已用内存是3250004KB,其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached。
如上例:
2795064=16176+110652+2668236
接下来解释什么时候内存会被交换,以及按什么方交换。 当可用内存少于额定值的时候,就会开会进行交换。
如何看额定值:
cat /proc/meminfo
[root@scs-2 tmp]# cat /proc/meminfo
MemTotal: 3266180 kB
MemFree: 17456 kB
Buffers: 111328 kB
Cached: 2664024 kB
SwapCached: 0 kB
Active: 467236 kB
Inactive: 2644928 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 3266180 kB
LowFree: 17456 kB
SwapTotal: 2048276 kB
SwapFree: 1968116 kB
Dirty: 8 kB
Writeback: 0 kB
Mapped: 345360 kB
Slab: 112344 kB
Committed_AS: 535292 kB
PageTables: 2340 kB
VmallocTotal: 536870911 kB
VmallocUsed: 272696 kB
VmallocChunk: 536598175 kB
HugePages_Total: 0
HugePages_Free: 0
Hugepagesize: 2048 kB
用free -m查看的结果:
[root@scs-2 tmp]# free -m
total used free shared buffers cached
Mem: 3189 3173 16 0 107 2605
-/+ buffers/cache: 460 2729
Swap: 2000 78 1921查看/proc/kcore文件的大小(内存镜像):
[root@scs-2 tmp]# ll -h /proc/kcore
-r-------- 1 root root 4.1G Jun 12 12:04 /proc/kcore备注:
占用内存的测量
测量一个进程占用了多少内存,linux为我们提供了一个很方便的方法,/proc目录为我们提供了所有的信息,实际上top等工具也通过这里来获取相应的信息。
/proc/meminfo 机器的内存使用信息
/proc/pid/maps pid为进程号,显示当前进程所占用的虚拟地址。
/proc/pid/statm 进程所占用的内存
[root@localhost~]# cat /proc/self/statm
654 57 44 0 0 334 0
输出解释
CPU 以及CPU0。。。的每行的每个参数意思(以第一行为例)为:
参数 解释 /proc//status
Size (pages) 任务虚拟地址空间的大小 VmSize/4
Resident(pages) 应用程序正在使用的物理内存的大小 VmRSS/4
Shared(pages) 共享页数 0
Trs(pages) 程序所拥有的可执行虚拟内存的大小 VmExe/4
Lrs(pages) 被映像到任务的虚拟内存空间的库的大小 VmLib/4
Drs(pages) 程序数据段和用户态的栈的大小 (VmData+ VmStk )4
dt(pages) 04
查看机器可用内存
/proc/28248/>free
total used free shared buffers cached
Mem: 1023788 926400 97388 0 134668 503688
-/+ buffers/cache: 288044 735744
Swap: 1959920 89608 1870312
我们通过free命令查看机器空闲内存时,会发现free的值很小。这主要是因为,在linux中有这么一种思想,内存不用白不用,因此它尽可能的cache和buffer一些数据,以方便下次使用。但实际上这些内存也是可以立刻拿来使用的。所以 空闲内存=free+buffers+cached=total-used
ctop命令
以下是摘自码农网。
ctop是一个新的基于命令行的工具,它可用于在容器层级监控进程。容器通过利用控制器组(cgroup)的资源管理功能,提供了操作系统层级的虚拟化环境。该工具从cgroup收集与内存、CPU、块输入输出的相关数据,以及拥有者、开机时间等元数据,并以人性化的格式呈现给用户,这样就可以快速对系统健康状况进行评估。基于所获得的数据,它可以尝试推测下层的容器技术。ctop也有助于在低内存环境中检测出谁在消耗大量的内存。
功能
ctop的一些功能如下:
- 收集CPU、内存和块输入输出的度量值
- 收集与拥有者、容器技术和任务统计相关的信息
- 通过任意栏对信息排序
- 以树状视图显示信息
- 折叠/展开cgroup树
- 选择并跟踪cgroup/容器
- 选择显示数据刷新的时间窗口
- 暂停刷新数据
- 检测基于systemd、Docker和LXC的容器
- 基于Docker和LXC的容器的高级特性
- 打开/连接shell以进行深度诊断
- 停止/杀死容器类型
安装
ctop是由Python写成的,因此,除了需要Python 2.6或其更高版本外(带有内建的光标支持),别无其它外部依赖。推荐使用Python的pip进行安装,如果还没有安装pip,请先安装,然后使用pip安装ctop。
注意:本文样例来自Ubuntu(14.10)系统
$ sudo apt-get install python-pip
使用pip安装ctop:
poornima@poornima-Lenovo:~$ sudo pip install ctop
[sudo] password for poornima:
Downloading/unpacking ctop
Downloading ctop-0.4.0.tar.gz
Running setup.py (path:/tmp/pip_build_root/ctop/setup.py) egg_info for package ctop
Installing collected packages: ctop
Running setup.py install for ctop
changing mode of build/scripts-2.7/ctop from 644 to 755
changing mode of /usr/local/bin/ctop to 755
Successfully installed ctop
Cleaning up...
如果不选择使用pip安装,你也可以使用wget直接从github安装:
poornima@poornima-Lenovo:~$ wget https://raw.githubusercontent.com/yadutaf/ctop/master/cgroup_top.py -O ctop
--2015-04-29 19:32:53-- https://raw.githubusercontent.com/yadutaf/ctop/master/cgroup_top.py
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 199.27.78.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|199.27.78.133|:443... connected.
HTTP request sent, awaiting response... 200 OK Length: 27314 (27K) [text/plain]
Saving to: ctop
100%[======================================>] 27,314 --.-K/s in 0s
2015-04-29 19:32:59 (61.0 MB/s) - ctop saved [27314/27314]
poornima@poornima-Lenovo:~$ chmod +x ctop
如果cgroup-bin包没有安装,你可能会碰到一个错误消息,你可以通过安装需要的包来解决。
poornima@poornima-Lenovo:~$ ./ctop
[ERROR] Failed to locate cgroup mountpoints.
poornima@poornima-Lenovo:~$ sudo apt-get install cgroup-bin
下面是ctop的输出样例:
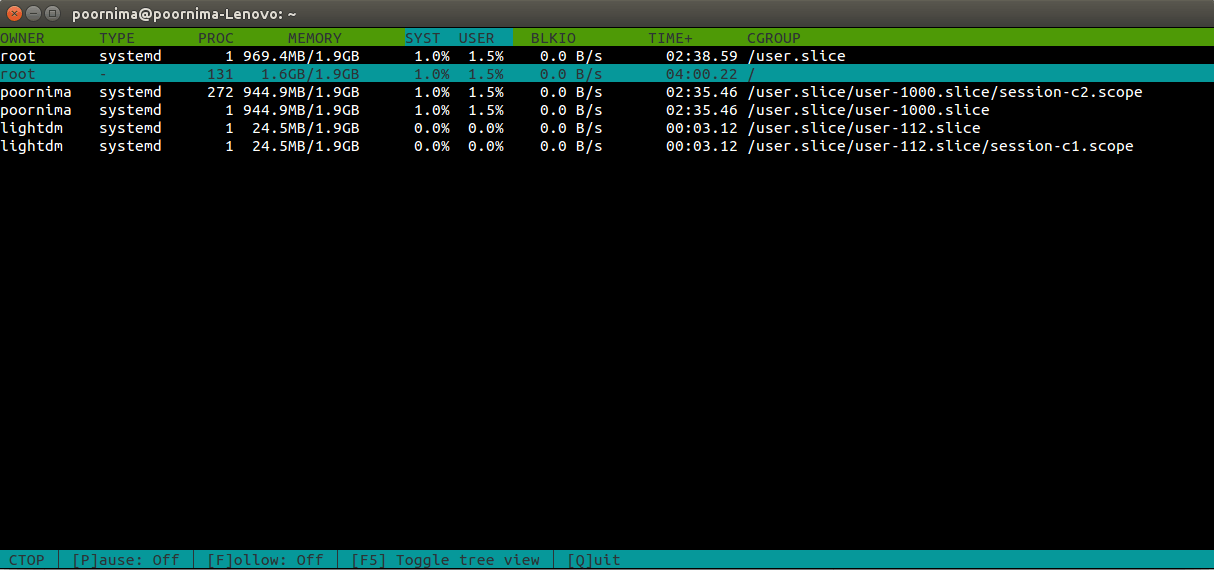
ctop屏幕
用法选项
ctop [--tree] [--refresh=] [--columns=] [--sort-col=] [--follow=] [--fold=, ...] ctop (-h | --help)
当你进入ctop屏幕,可使用上(↑)和下(↓)箭头键在容器间导航。点击某个容器就选定了该容器,按q或Ctrl+C退出该容器。
现在,让我们来看看上面列出的那一堆选项究竟是怎么用的吧。
-h / –help – 显示帮助信息
poornima@poornima-Lenovo:~$ ctop -h
Usage: ctop [options]
Options:
-h, --help show this help message and exit
--tree show tree view by default
--refresh=REFRESH Refresh display every
--follow=FOLLOW Follow cgroup path
--columns=COLUMNS List of optional columns to display. Always includes
'name'
--sort-col=SORT_COL Select column to sort by initially. Can be changed
dynamically.
–tree – 显示容器的树形视图
默认情况下,会显示列表视图
当你进入ctop窗口,你可以使用F5按钮在树状/列表视图间切换。
–fold= – 在树形视图中折叠名为
该选项需要与 –tree 选项组合使用。
例子: ctop –tree –fold=/user.slice
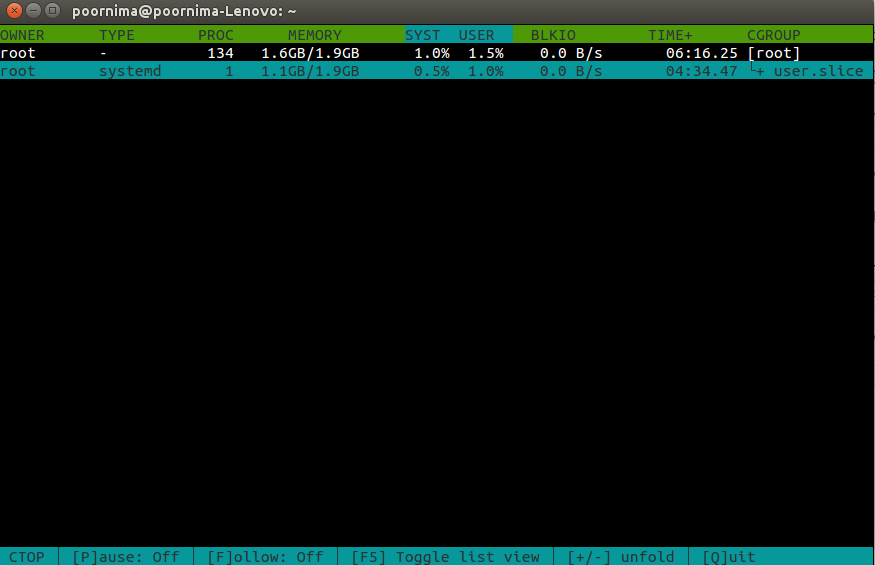
‘ctop –fold’的输出
在ctop窗口中,使用+/-键来展开或折叠子cgroup。
注意:在写本文时,pip仓库中还没有最新版的ctop,还不支持命令行的‘–fold’选项
–follow= – 跟踪/高亮 cgroup 路径
例子: ctop –follow=/user.slice/user-1000.slice
正如你在下面屏幕中所见到的那样,带有“/user.slice/user-1000.slice”路径的cgroup被高亮显示,这让用户易于跟踪,就算显示位置变了也一样。
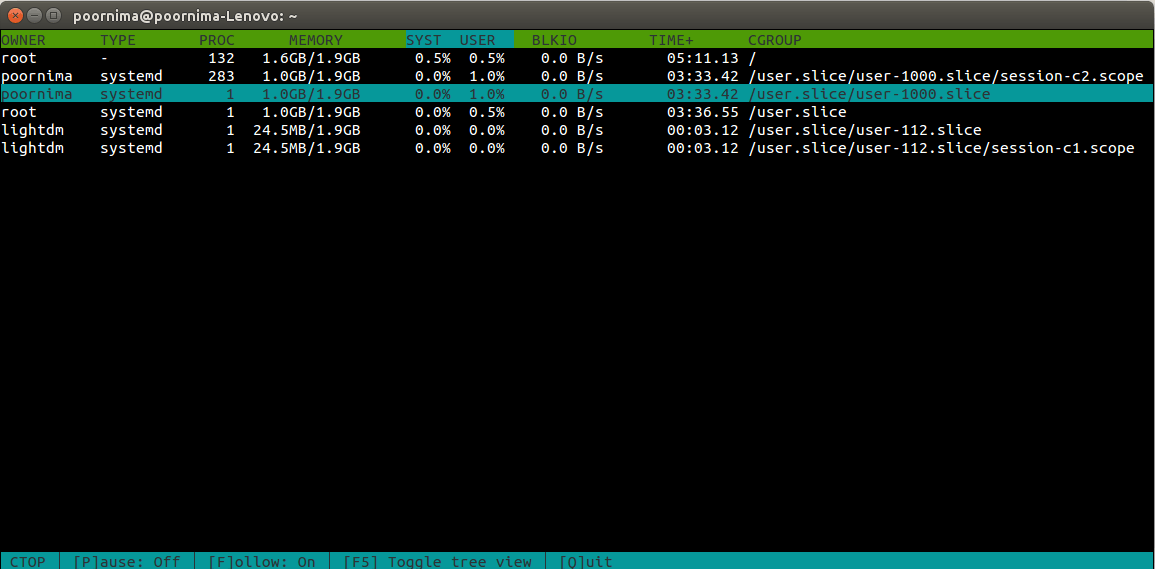
‘ctop –follow’的输出
你也可以使用‘f’按钮来让高亮的行跟踪选定的容器。默认情况下,跟踪是关闭的。
–refresh= – 按指定频率刷新显示,默认1秒
这对于按每用户需求来显示改变刷新率时很有用。使用‘p’按钮可以暂停刷新并选择文本。
–columns= – 限定只显示选定的列。’name’ 需要是第一个字段,其后跟着其它字段。默认情况下,字段包括:owner, processes,memory, cpu-sys, cpu-user, blkio, cpu-time
例子: ctop –columns=name,owner,type,memory
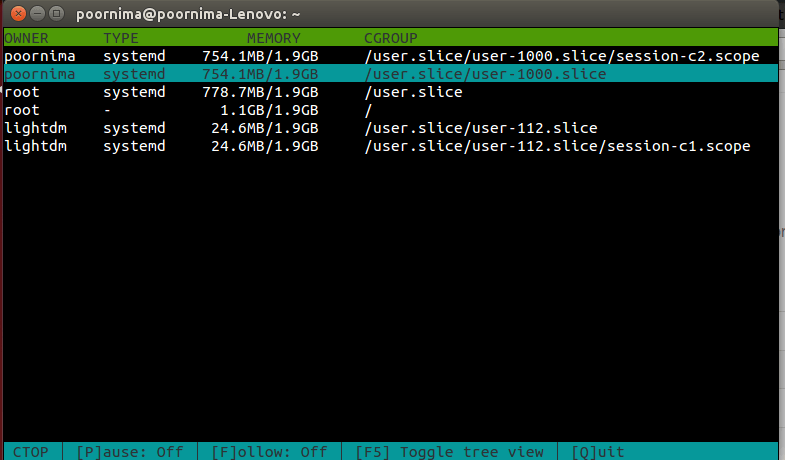
‘ctop –column’的输出
-sort-col= – 按指定的列排序。默认使用 cpu-user 排序
例子: ctop –sort-col=blkio
如果有Docker和LXC支持的额外容器,跟踪选项也是可用的:
press 'a' - 接驳到终端输出
press 'e' - 打开容器中的一个 shell
press 's' - 停止容器 (SIGTERM)
press 'k' - 杀死容器 (SIGKILL)
目前 Jean-Tiare Le Bigot 还在积极开发 ctop 中,希望我们能在该工具中见到像本地 top 命令一样的特性。
附:ulimit命令改善系统性能
Linux查看HotSopt虚拟机GC线程的CPU占用率