游戏数据分析报告--<野蛮时代>
游戏数据分析报告
数据来源:DC游戏玩家付费金额预测大赛
数据包含近229万条记录和109个字段。
比赛任务是用前7天数据预测前45天付费金额,
本篇博客主要关注在数据探索分析。
一些重要字段:
bd_stronghold_level:要塞等级,相当于游戏账号等级
register_time: 注册时间
pay_price: 付费金额
avg_online_minutes: 在线时长
pvp_battle_count: 人人对战次数
pvp_win_count: 人人对战胜利次数
pve_battle_count: 人机对战次数
wood_reduce_value: 木头消耗量
本文主要从以下方面探索数据;
-
注册时间分布
-
付费情况分析
-
等级分布
-
营销活动效果探索
-
游戏平衡度探索
-
付费预测
注册时间分布
部分代码
time = pd.DataFrame()
time['register_t'] =train_data['register_time'].map(lambda x:x[5:10])
data_plot = time.groupby('register_t').size() # 返回不同分组和每组数量
data_plot.columns = ['date', 'register_counts']
plt.subplots(figsize=(18, 6))
plt.plot(data_plot)
plt.grid(True)
plt.xticks(rotation=90)
plt.title('user register distribution')
plt.show()
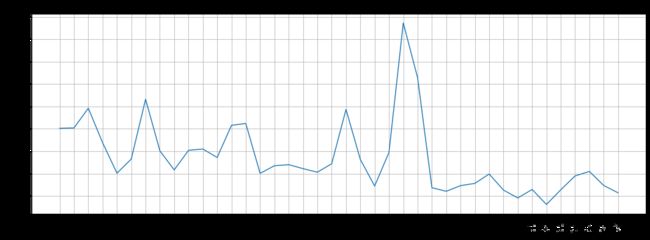
数据时间跨度:2018年 (1-26 ~ 3-6)
在2月15号到2月22号之间有两个用户增长的小高潮
这个期间是2018年农历新年假期
运营方在游戏中开展了一系列活动,包括舞狮活动、酋长参战、跨服战、爆竹活动等,这些活动和春节效应叠加,带来了注册人数的增加,出现峰值
付费情况分析
定义活跃用户为: 前7天平均在线时长大于30min
activate_user = train_data[train_data['avg_online_minutes']>30]
#付费率(付费人数/活跃人数) 付费率
df_pay_user=train_data[(train_data['pay_price']>0)]
pay_rate=df_pay_user['user_id'].count()/activate_user.shape[0]
print('付费率:%.2f'%(pay_rate*100),'%')
#ARPU(总付费金额/活跃人数) 人均付费金额
arpu=df_pay_user['pay_price'].sum()/activate_user.shape[0]
print('ARPU:%.2f'%(arpu))
#ARPPU(总付费金额/付费人数) 付费用户人均付费金额
arppu=df_pay_user['pay_price'].sum()/df_pay_user['user_id'].count()
print('ARPPU:%.2f'%(arppu))
活跃用户总体付费率为29%, 人均付费金额为8.58元, 付费用户人均付费金额29.52元
付费率:29.06 %
ARPU:8.58
ARPPU:29.52
分布情况: 75%的人付费金额在20.98元以下, 50%的人充值金额在3.97元以下
pay_user = train_data[train_data['prediction_pay_price']!=0]
pay_user['prediction_pay_price'].describe()
count 45988.000000
mean 89.213058
std 617.702040
min 0.990000
25% 0.990000
50% 3.970000
75% 20.980000
max 32977.810000
Name: prediction_pay_price, dtype: float64
等级与付费关系
df_user=train_data[['user_id','bd_stronghold_level','pay_price','pay_count']]
df_table=pd.pivot_table(df_user,index=['bd_stronghold_level'],
values=['user_id','pay_price','pay_count'],
aggfunc={'user_id':'count','pay_price':'sum','pay_count':'sum'})
df_stronghold_pay=pd.DataFrame(df_table.to_records())
#各等级付费人数
df_stronghold_pay['pay_people_num']=df_user[(train_data['pay_price']>0)].groupby('bd_stronghold_level').user_id.count()
#各等级付费转化率
df_stronghold_pay['pay_rate']=df_stronghold_pay['pay_people_num']/df_stronghold_pay['user_id']
#各等级平均付费金额
df_stronghold_pay['avg_pay_price']=df_stronghold_pay['pay_price']/df_stronghold_pay['user_id']
lt.figure(figsize=(16,4))
plt.subplot(131)
x=df_stronghold_pay['bd_stronghold_level']
y=df_stronghold_pay['pay_rate']
plt.xticks(x,range(0,len(x),1))
plt.plot(x,y)
plt.grid(False)
plt.xlabel('level')
plt.ylabel('pay rate')
plt.title('pay rate by level')
付费率在用户达到10级时显著提升, 付费金额付费次数也在10级后开始提升。
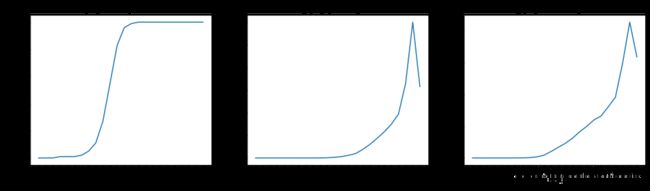
等级分布
small = df_stronghold_pay[df_stronghold_pay['bd_stronghold_level']<=7].user_id.sum() #10级一下总用户数
mid = df_stronghold_pay[(df_stronghold_pay['bd_stronghold_level']>7) & (df_stronghold_pay['bd_stronghold_level']<=20)].user_id.sum() #10-20级总用户数
large = df_stronghold_pay[df_stronghold_pay['bd_stronghold_level']>20].user_id.sum()
plt.subplots(figsize=(5, 5))
data_pie = [small, mid, large]
lables = ['junior', 'advanced', 'master']
explode = (0.2, 0, 0)
plt.pie(data_pie,labels = lables, explode = explode, shadow=True,colors = sns.color_palette('Blues', 3),autopct= '%1.4f%%',pctdistance = 0.5) # pctdistance 距离圆心距离
plt.title('user number distribution by level')
plt.show()
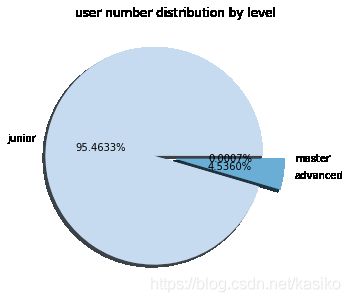
看用户等级分布图我们可以发现,绝大部分用户都处于7级以下
用户付费率等指标是从10级开始提升的,运营用户达到10级非常必要
春节营销活动效果探索
new_year = train_data
new_year['register_t'] =new_year['register_time'].map(lambda x:x[5:10])
new_year_plan = new_year[(new_year['register_t']>='02-15') & (new_year['register_t']<='02-22')]
##在线时间对比
new_user_avgTime = new_year_plan['avg_online_minutes'].mean()
all_user_avgTime = new_year['avg_online_minutes'].mean()
#活跃用户比例对比(在线时长大于30的用户比例)
activate_user_newYear = new_year_plan[new_year_plan['avg_online_minutes']>=30]
newYear_activate_rate = activate_user_newYear.shape[0] / new_year_plan.shape[0]
activate_user_all = new_year[new_year['avg_online_minutes']>=30]
activate_user_rate = activate_user_all.shape[0] / new_year.shape[0]
活动期间虽然日增用户数量高于总体, 但是活动拉新的用户活跃用户比率(平均在线大于30min)和付费用户比率,付费用户人均消费金额三项指标均低于总体水平。

游戏平衡度探索
muti_battel = new_year[(new_year['pvp_battle_count']>1) & (new_year['pve_battle_count']>1)]
muti_battel['win_rate'] = muti_battel['pvp_win_count'] / muti_battel['pvp_battle_count']
muti_battel['win_rate_pve'] = muti_battel['pve_win_count'] / muti_battel['pve_battle_count']
pay = muti_battel[muti_battel['pay_price']>0]
pay_win_rate = pay['pvp_win_count'].sum()/pay['pvp_battle_count'].sum()
unpay = muti_battel[muti_battel['pay_price']==0]
unpay_win_rate = unpay['pvp_win_count'].sum()/unpay['pvp_battle_count'].sum()
print(pay_win_rate, '\n',unpay_win_rate)
充值用户pvp对战胜率:73%
普通用户pvp对战胜率: 39%
pay_pve = muti_battel[muti_battel['pay_price']>0]
pay_win_rate_pve = pay['pve_win_count'].sum()/pay['pve_battle_count'].sum()
unpay_pve = muti_battel[muti_battel['pay_price']==0]
unpay_win_rate_pve = unpay['pve_win_count'].sum()/unpay['pve_battle_count'].sum()
print(pay_win_rate_pve, '\n',unpay_win_rate_pve
充值用户pve对战胜率:91%
普通用户pve对战胜率: 89%
x = muti_battel['pay_price'].values
y = muti_battel['win_rate'].values
fig = plt.figure(figsize=(11, 4))
ax1 = fig.add_subplot(121)
ax1.set_title('relation between pay and win pvp')
plt.xlabel('pay price')
plt.ylabel('pvp win rate')
ax1.scatter(x,y,c = 'g',marker = 'o')
plt.legend('user', loc='best')
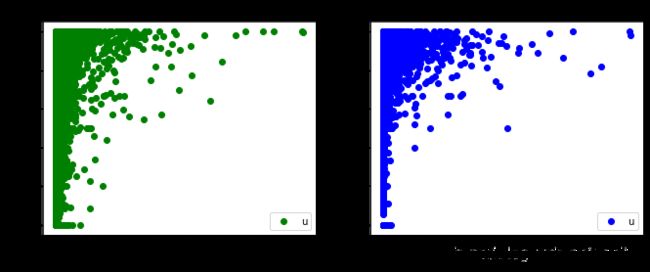
虽然总体充值用户的pvp对战胜率要远高于普通用户
但是pvp对战 和pve 对战 胜率和充值金额并没有强烈的正相关
充值金额预测
step1 :分类,判断用户在7天后会不会继续充值,如果分类器判定不会,则45天充值金额就为前7天充值金额,通常二分类问题准确率较高,所以能保证最终结果不会太差。
step2: 回归预测, 对于判定为会继续充值的样本,继续用回归树预测具体充值金额。
# 假想1, 付费玩家大概率在7天内已经付费
# 只有9.89%的 用户的首充在7天之后
# 45 天内金额 大于 7天内金额, 证明在 7天后充值了
# 28%的人, 前七天没充值, 但是后边充值了
# 72%的人, 前七天充值了,后边还充值了
after7pay = train_data[train_data['prediction_pay_price'] > train_data['pay_price']] # 7天后有充值行为的人
day7_no_pay = after7pay[after7pay['pay_price']==0] #前7天没有充值的人
rate = day7_no_pay.shape[0]/after7pay.shape[0]
print(round(rate*100,2), '%')
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
from sklearn.utils import shuffle
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
new_year = train_data
new_year = new_year.drop(columns='register_t',axis=0)
#new_year['pay continue'] = new_year.pay_price.apply(lambda x: 1 if x>0 else 0) #新建列赋值(根据其他列条件)
new_year['pay continue']=0
new_year.loc[new_year['prediction_pay_price']> new_year['pay_price'], 'pay continue']=1
train_df = new_year
train_df.drop(columns=['user_id', 'register_time'], inplace=True)
X1 = train_df[train_df['pay continue']==1]
X2 = train_df[train_df['pay continue']==0]
X2 = X2.sample(16000)
X = pd.concat([X1,X2], axis=0)
X = shuffle(X)
Y = X.loc[:, 'pay continue']
X = X.drop(columns='pay continue',axis=0)
X_train, X_test, y_train, y_test = train_test_split(X, Y, train_size=0.75, random_state=0)
clf = make_pipeline(StandardScaler(), SVC(gamma='auto'))
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
0.93
第一步的准确率可以达到0.93
回归预测:
Regre_Y = X.loc[:, 'prediction_pay_price']
Regre_X = X.drop(columns='prediction_pay_price', axis=0)
RX_train, RX_test, Ry_train, Ry_test = train_test_split(Regre_X, Regre_Y, train_size=0.75, random_state=0)
#特征选择
from sklearn.feature_selection import VarianceThreshold
sel = VarianceThreshold(threshold=(0.5))
RX_train_selected = sel.fit_transform(RX_train)
RX_test_selected = sel.fit_transform(RX_test)
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=40, max_depth=4, random_state=0, n_jobs=1)
model.fit(RX_train_selected, Ry_train)
model.score(RX_test_selected, Ry_test)