VMware中配置Hadoop环境
P.S.
完成毕业设计时,虚拟机hadoop101及其IP地址已被占用,撰写本文时,重新创建了Hadoop100 并按照步骤进行,但是后文对应的完全分布式还是要用hadoop101 下拷贝文件,所以读者自己配置时能 区分一下hadoop100 和hadoop101。直接配置hadoop101即可。
目录
1.虚拟机环境准备:
1.1 克隆虚拟机
1.1.1 创建hadoop_clean
1.1.2 克隆虚拟机hadoop100
1.2 连接XShell 工具
1.3 安装JDK
1.3.1 卸载现有JDK
1.3.2 将JDK 导入opt/software
1.3.3 在Linux系统下的opt目录中查看软件包是否导入成功
1.3.4 解压JDK到/opt/modules 目录下
1.3.5 配置JDK环境变量
1.3.6 测试 JDK 是否安装成功
1.3.7 重启虚拟机。
1.4 安装Hadoop
1.4.1 下载安装包,并将其放入到 /opt/software中
1.4.2 进入到Hadoop安装包路径下并解压安装文件到/opt/modules 下
1.4.3 查看是否解压成功
1.4.4 将 Hadoop 添加到环境变量
1.5 Hadoop目录结构
1.5.1 查看Hadoop目录结构
1.5.2 重要目录
前期准备:
1.VMare WorkStation Pro
2.CentOS-6.10
3.Hadoop-2.9.2
4.Xshell
1.虚拟机环境准备:
1.1 克隆虚拟机
1.1.1 创建hadoop_clean
为了方便克隆,我们首先配置一台模板机。命名为 hadoop_clean。按照正常的流程走下去就可以。
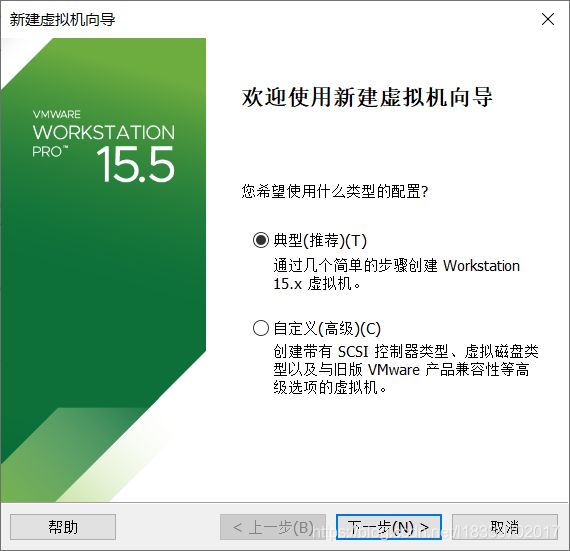

这里要选择CentOS-6.10的映像文件
 将之命名为hadoop_clean。
将之命名为hadoop_clean。
接下来按需分配资源即可。安装完成后启动。
启动完成后关机。需要改两个设置:
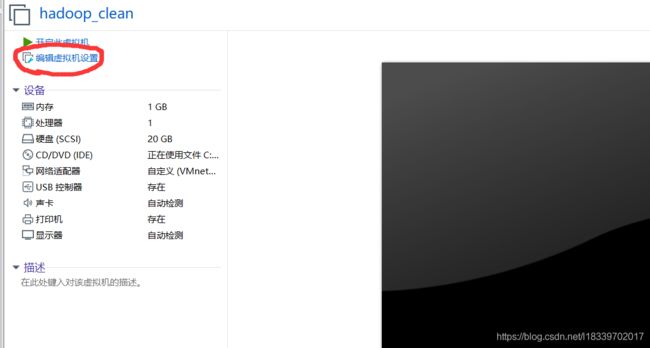
(1). 更改网络模式

(2). 更改映像文件
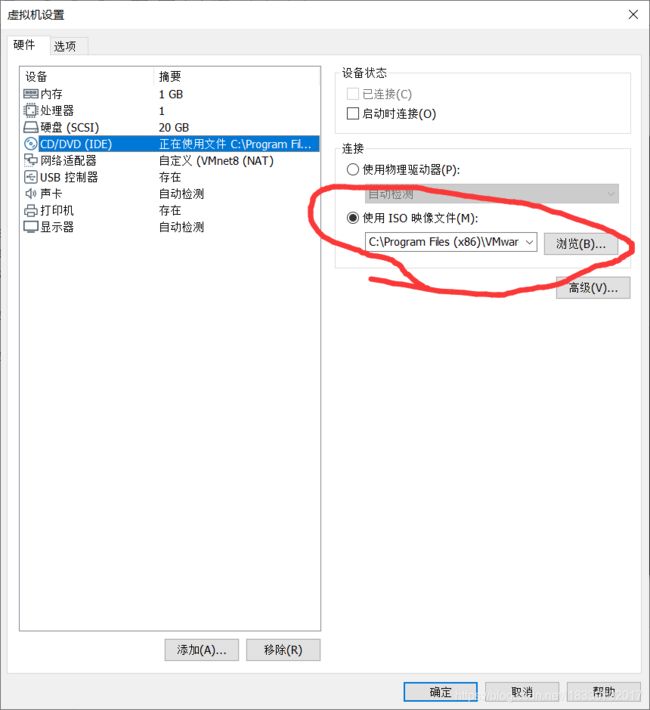
hadoop_clean的安装大功告成。
1.1.2 克隆虚拟机hadoop100
利用hadoop_clean克隆一台虚拟机: hadoop100,再次完成上述两个设置,并启动。
打开终端进行下述配置:
切换至root用户:
![]()
1.1.2.1 修改网络属性
vim /etc/udev/rules.d/70-persistent-net.rules 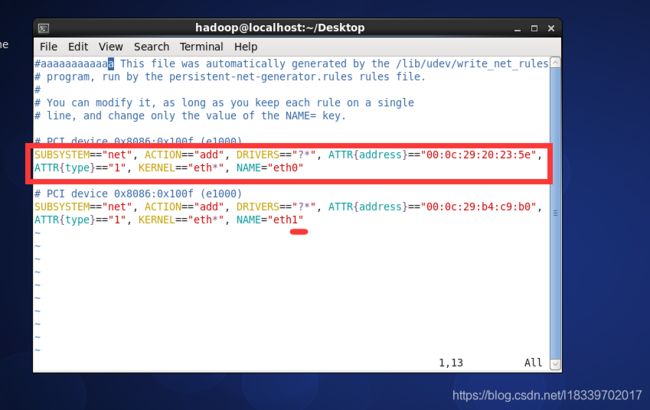
(1). 删除红框部分
(2). 把最后的eth1改成eth0
(3). 复制下ATTR{address}的内容,如上图的“00:0c:29:b4:c9:b0”
1.1.2.2.修改克隆机的静态ip
vim /etc/sysconfig/network-scripts/ifcfg-eth0
(1). 把红线上的物理地址修改成我们上一步操作中复制下来的物理地址
(2). 加上ip地址网关dns。具体对应自己的本机ip地址要查看Vmware中 (编辑-虚拟网络编辑器)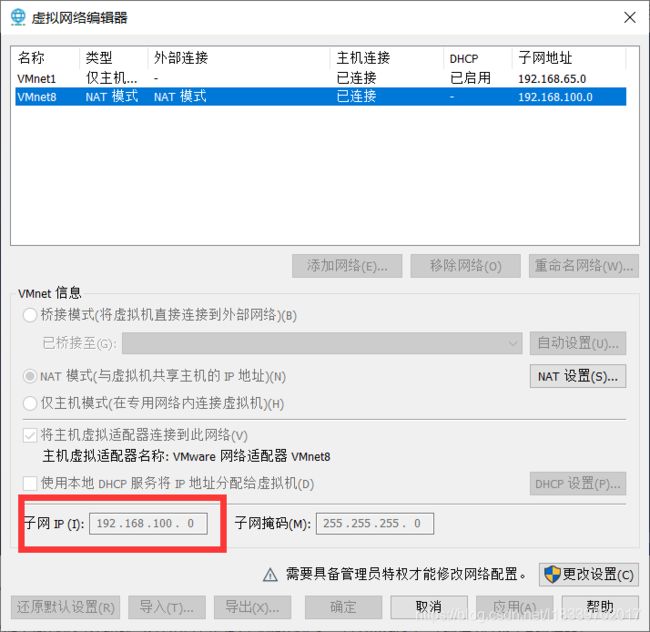
1.1.2.2*.修改克隆机的静态ip
在1.1.2.2 中,我与参考教程中的步骤不同,我是手动配置的IP地址。



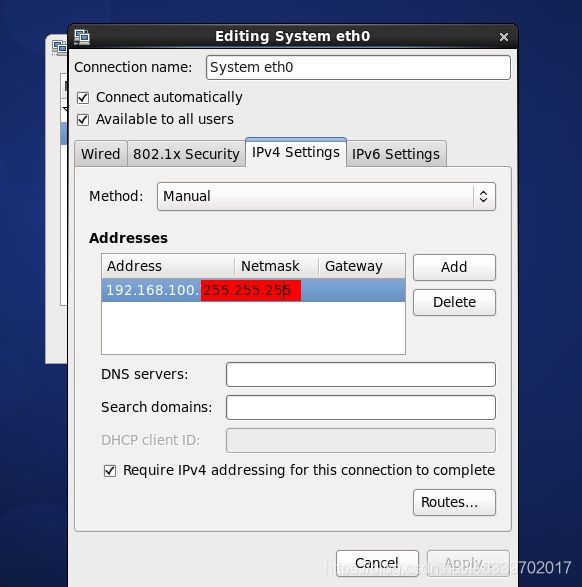
然后手动配置IP地址。
1.1.2.3.修改主机名
vim /etc/sysconfig/network修改主机名为hadoop100
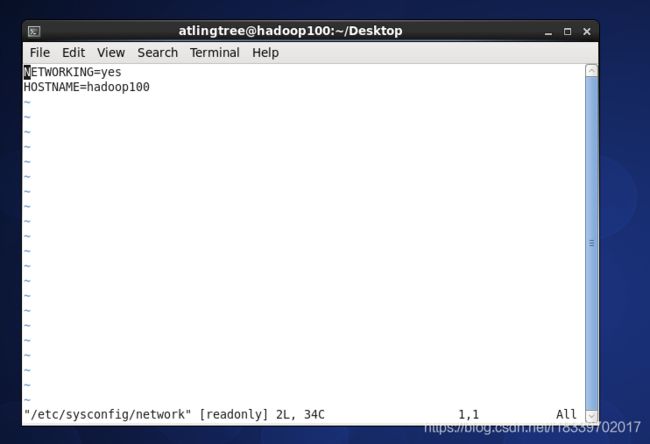
1.1.2.4.添加hadoop用户:
useradd atlingtree
passwd atlingtree1.1.2.5 为hadoop用户配置root权限
并为用户atlingtree加上权限:
vim /etc/sudoers输入set nu 可以查看行号,在第92行加入代码:
atlingtree ALL=(ALL) NOPASSWD:ALL

1.1.2.6. 修改hosts文件:
vim /etc/hosts在末尾添加:
192.168.100.10 hadoop100
192.168.100.11 hadoop101
192.168.100.12 hadoop102
192.168.100.13 hadoop103
192.168.100.14 hadoop1041.1.2.7 关闭防火墙
chkconfig iptables off完毕,重启虚拟机。
这里要用atlingtree 用户登录
可以看到网络已经连接,
 尝试ping一下自己的主机与百度,都可以ping通。
尝试ping一下自己的主机与百度,都可以ping通。
1.1.2.8 在/opt目录下创建文件夹
(1) 在/opt目录下创建module、software文件夹
[atlingtree@hadoop ~]$ cd /opt
[atlingtree@hadoop100 opt]$ sudo mkdir modules
[atlingtree@hadoop100 opt]$ sudo mkdir software
[atlingtree@hadoop opt]$ ls
modules rh software
(2). 修改 modules、software 文件夹的所有者cd
[atlingtree@hadoop100 opt]$ sudo chown atlingtree:atlingtree modules/ software/
重新启动。
1.2 连接XShell 工具
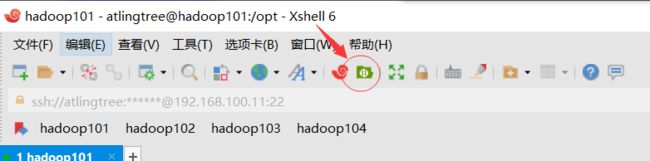
打开XShell,新建链接
进行配对之后成功。
1.3 安装JDK
1.3.1 卸载现有JDK
1.3.1.1 查询是否安装Java软件:
[atlingtree@hadoop100 opt]$ rpm -qa | grep java1.3.1.2 如果安装的版本低于1.7,卸载该JDK:
[atlingtree@hadoop100 opt]$ sudo rpm -e 软件包1.3.1.2 查看JKD安装路径:
[atlingtree@hadoop100 opt]$ which java1.3.2 将JDK 导入opt/software
将JDK和Hadoop的安装包直接拖到右边框中 的对应文件夹下。
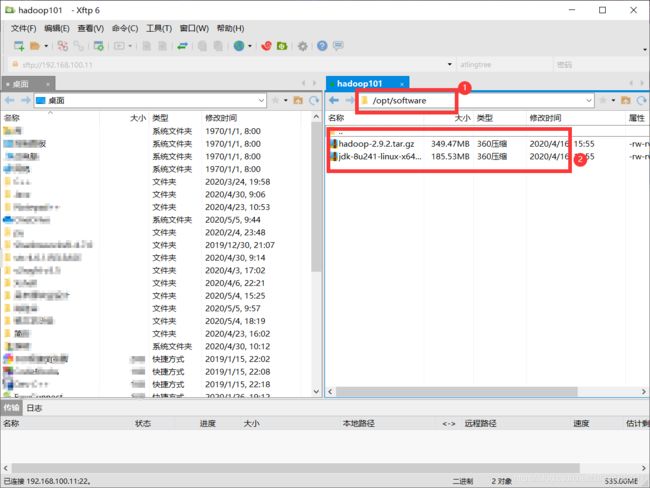
1.3.3 在Linux系统下的opt目录中查看软件包是否导入成功
[atlingtree@hadoop100 ~]$ cd /opt/software/
[atlingtree@hadoop100 software]$ ls
hadoop-2.9.2.tar.gz jdk-8u241-linux-x64.tar.gz1.3.4 解压JDK到/opt/modules 目录下
[atlingtree@hadoop100 software]$ tar -zxvf jdk-8u241-linux-x64.tar.gz -C /opt/modules/1.3.5 配置JDK环境变量
1.3.5.1 获取JDK路径
[atlingtree@hadoop software]$ cd /opt/modules/jdk1.8.0_241/
[atlingtree@hadoop100 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_1441.3.5.2 打开 并修改 /etc/profile 文件
[atlingtree@hadoop100 ~]$ sudo vim /etc/profile
在profile 文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
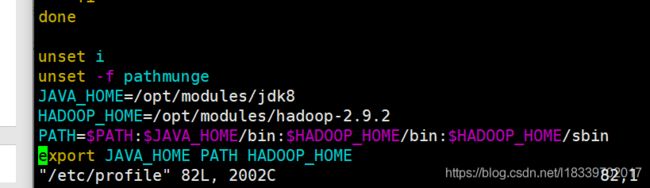 (上图中得jkd8是因为我更改了jdk的名字,按照正常获取的JDK路径配置即可)
(上图中得jkd8是因为我更改了jdk的名字,按照正常获取的JDK路径配置即可)
1.3.5.3 保存后退出
vim 编辑器模式下,退出的操作: 先按 冒号 “ : ” , 然后发现光标跳到了最下方。 输入wq即可退出
1.3.5.4 刷新文件,让修改后的文件生效
[atlingtree@hadoop100 ~]$ source /etc/profile1.3.6 测试 JDK 是否安装成功
[atlingtree@hadoop100 ~]# java -version
java version "1.8.0_144"
1.3.7 重启虚拟机。
[atlingtree@hadoop101 jdk1.8.0_144]$ sync
[atlingtree@hadoop101 jdk1.8.0_144]$ sudo reboot
1.4 安装Hadoop
1.4.1 下载安装包,并将其放入到 /opt/software中
在安装JDK时已经顺手将Hadoop的安装包放进去了。
1.4.2 进入到Hadoop安装包路径下并解压安装文件到/opt/modules 下
[atlingtree@hadoop100 ~]$ cd /opt/software/
[atlingtree@hadoop100 software]$ tar -zxvf hadoop-2.9.2.tar.gz -C /opt/modules/1.4.3 查看是否解压成功
[atlingtree@hadoop100 software]$ ls /opt/modules/
hadoop-2.9.2
1.4.4 将 Hadoop 添加到环境变量
1.4.4.1 获取 Hadoop 安装路径
[atlingtree@hadoop100 software]$ cd /opt/modules/hadoop-2.9.2
[atlingtree@hadoop100 hadoop-2.9.2]$ pwd
/opt/module/hadoop-2.9.2
1.4.4.2 打开 并修改 /etc/profile 文件
[atlingtree@hadoop100 hadoop-2.9.2]$ sudo vim /etc/profile在profile文件末尾添加JDK路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin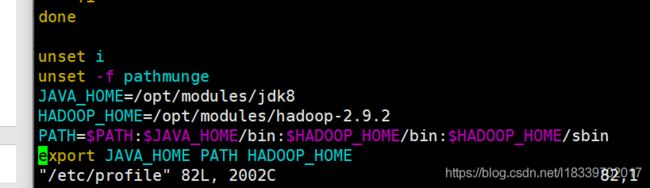
1.4.4.3 保存后退出
:wq
1.4.4.4 刷新文件,让修改后的文件生效
[atlingtree@ hadoop100 hadoop-2.9.2]$ source /etc/profile1.4.4.5 测试是否安装成功
[atlingtree@hadoop100 hadoop-2.9.2]$ hadoop version
Hadoop 2.9.2
1.4.4.6 重启虚拟机
[atlingtree@ hadoop100 hadoop-2.9.2]$ sync
[atlingtree@ hadoop100 hadoop-2.9.2]$ sudo reboot1.5 Hadoop目录结构
1.5.1 查看Hadoop目录结构
[atlingtree@hadoop101 hadoop-2.9.2]$ ll
总用量 52
drwxr-xr-x. 2 atlingtree atlingtree 4096 5月 22 2017 bin
drwxr-xr-x. 3 atlingtree atlingtree 4096 5月 22 2017 etc
drwxr-xr-x. 2 atlingtree atlingtree 4096 5月 22 2017 include
drwxr-xr-x. 3 atlingtree atlingtree 4096 5月 22 2017 lib
drwxr-xr-x. 2 atlingtree atlingtree 4096 5月 22 2017 libexec
-rw-r--r--. 1 atlingtree atlingtree 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 atlingtree atlingtree 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 atlingtree atlingtree 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 atlingtree atlingtree 4096 5月 22 2017 sbin
drwxr-xr-x. 4 atlingtree atlingtree 4096 5月 22 2017 share1.5.2 重要目录
bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
sbin目录:存放启动或停止Hadoop相关服务的脚本
share目录:存放Hadoop的依赖jar包、文档、和官方案例
环境搭建就完成了。