1 GPU简介
图形处理单元GPU英文全称Graphic Processing Unit,GPU是相对于CPU的一个概念,NVIDIA公司在1999年发布GeForce256图形处理芯片时首先提出GPU的概念。GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作(主要是并行计算部分)。GPU具有强大的浮点数编程和计算能力,在计算吞吐量和内存带宽上,现代的GPU远远超过CPU。
目前NVIDIA最新的CUDA图形计算架构主要是Fermi架构和Kepler架构。
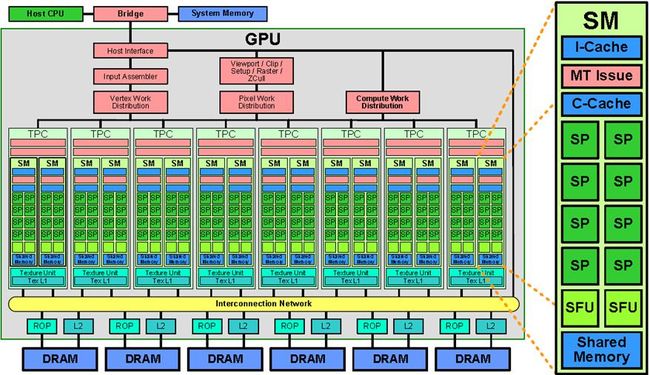
2 Fermi架构概述
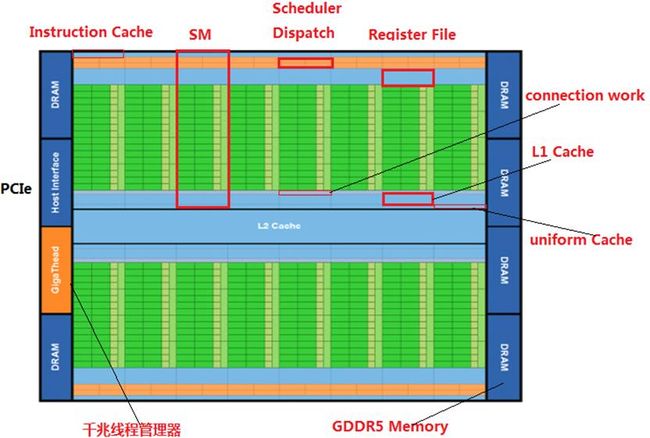
上图是Fermi架构的GPU的核心架构图。基于GPU的第一代Fermi 架构拥有30亿个晶体管,512个CUDA Core。一个CUDA Core在一个时钟周期内执行一个线程(或kernel)中的一个浮点数或整数指令。512个CUDA Core是按照16个含有32个Core的SM(流式多处理器,也叫Scalar Processor,标量处理器)进行组织的。GPU拥有6个64-bit的显存分区(DRAM),因此支持384-bit的显存接口。最大支持6GB的GDDR5类型的显存容量,GPU和CPU之间通过PCI-e总线连接,千兆线程管理器负责将线程块分发到SM(流式多处理器)中。
3 Kepler架构概述
Kepler GK110由71亿个晶体管组成,速度最快,是有史以来架构最复杂的微处理器,GK110新加了许多注重计算性能的创新功能。GK110提供超过每秒 1 万亿次双精度浮点计算的吞吐量,性能效率明显高于之前的 Fermi 架构。除大大提高的性能之外,Kepler 架构在电源效率方面有 3 次巨大的飞跃,使 Fermi 的性能/功率比提高了 3 倍。

完整Kepler GK110架构包括15个SMX单元和六个64位内存控制器。每个SMX单元包含192个单精度CUDA Core、64个双精度单元(DP Unit)、32个特殊功能单元(SFU)和32个加载/存储单元(LD/ST),4 warp调度单元,8个指令分发单元。不同的产品将使用 GK110 不同的配置。例如,某些产品可能部署 13 或 14 个 SMX。

KeplerGK110的以下新功能提高GPU的利用率,简化了并行程序设计,并有助于GPU在各种计算环境中部署:
(1) Dynamic Parallelism——动态并行化
能够让 GPU 在无需 CPU 介入的情况下,通过专用加速硬件路径为自己创建新的线程,对结果同步,并控制这些线程的调度。
(2) Hyper-Q
Hyper - Q 允许多个CPU核同时在单一GPU上启动线程,从而大大提高了GPU的利用率并削减了CPU空闲时间。Hyper‐Q 增加了主机和 Kepler GK110 GPU 之间的连接总数(工作队列),允许32个并发、硬件管理的连接(与Fermi相比,Fermi 只允许单个连接)。Hyper - Q 是一种灵活的解决方案,允许来自多个 CUDA 流、多个消息传递接口(MPI)进程,甚至是进程内多个线程的单独连接。
(3) Grid Management Unit
使Dynamic Parallelism能够使用先进、灵活的GRID管理和调度控制系统。新 GK110 Grid Management Unit (GMU) 管理按优先顺序在 GPU上执行的Grid。GMU 可以暂停新 GRID 和等待队列的调度,并能中止 GRID,直到其能够执行时为止,为 Dynamic Parallelism 的运行提供了灵活性。GMU 确保CPU和GPU产生的工作负载得到妥善的管理和调度。
(4) 英伟达GPUDirect
英伟达GPUDirect能够使单个计算机内的GPU或位于网络内不同服务器内的GPU直接交换数据,无需进入CPU系统内存。GPUDirect 中的 RDMA 功能允许第三方设备,例如 SSD、NIC 和 IB 适配器,直接访问相同系统内多个 GPU 上的内存,大大降低 MPI 从 GPU 内存发送/接收信息的延迟。还降低了系统内存带宽的要求并释放其他 CUDA 任务使用的 GPU DMA 引擎。Kepler GK110还支持其他的GPUDirect功能,包括Peer-to-Peer和GPUDirect for Video。