【聚类模型②】系统聚类算法——解决k均值聚类的遗留问题
上一篇博客我们提到,k均值聚类虽然可以对多个样本进行k分类,但即使是改进以后的k-means++聚类方法也存在一个问题:聚类结果很大程度上依赖于用户给定的类数k。
那么有没有方法解决这个问题呢?在清风老师的教程中介绍了系统聚类算法↓(本文图片来自辽宁石油化工大学的于晶贤老师)
文章目录
- 系统聚类的步骤
- 整体描述
- 聚类谱系图
- 计算类间距离的5个方法
- 系统聚类做出的改进
系统聚类的步骤
整体描述
- 将每个样本算作一类
- 用特定方法计算类与类两两间距离,将距离较近的类分为一大类
- 将新的大类作为子类,重复第2步并绘制聚类谱系图,直到所有样本都归为一类为止
- 根据得到的聚类谱系图和选取的类数量k,得到k分类结果
聚类谱系图
根据每一次分类结果,绘制出类似下图的树状谱系图:
以改图为例,分类过程如下:
第一次分类将学生1和5分为一类,2和4分为一类,3自成一类。第二次将学生1524分为一类,3自成一类。最后一次将所有学生归为一类(学生类,所有样本的全集)

最后在上图中根据不同的k来选取分类:

可以看出,取k=2时的二分类方法是将学生3分成一类,1、2、4、5分成一类。
取k=3时的三分类将学生1、5分成一类,2、4分成一类、3自成一类。以此类推
计算类间距离的5个方法
在分类刚刚开始的时候,每个样本自成一类。故样本点之间的距离就是类间距离
此后,类间距离的计算有以下5种常见方法:
-
最短距离法(Nearest Neighbor)
取两个类内点的最短距离作为两个类的距离 D ( G p , G q ) D(G_p,G_q) D(Gp,Gq)即下图红线的长度:
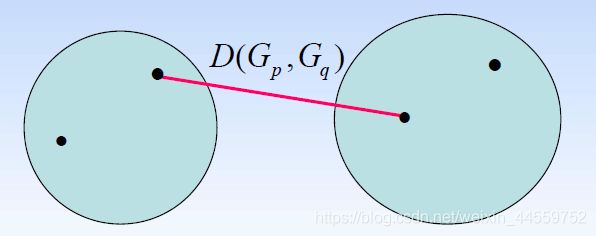
-
最长距离法(Furthest Neighbor)
取两类内点间最长距离作为两类的距离 D ( G p , G q ) D(G_p,G_q) D(Gp,Gq)即下图红线
-
组间平均距离法
计算两个类中点两两间距离(下图红线),取所有距离的平均值作为两个类的距离
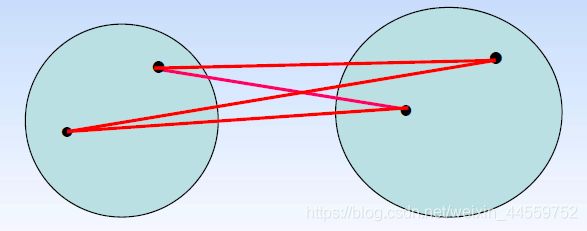
-
组内平均
计算两个类包含所有点两两间距离(下图红线),取其平均值作为两个类的距离

-
重心法
取类中点的重心作为该类的中心,两个类的中心点距离作为类间距离 D ( G p , G q ) D(G_p,G_q) D(Gp,Gq)

系统聚类做出的改进
我们知道k均值聚类分类的方法是先选出k个类,然后选择初始聚类中心,再以此为依据进一步分类。
与k均值聚类算法不同的是,系统聚类使用的分类方法并不是先选择“分为几类”,相反,而是直接根据样本的特征先进行分类,最后根据实际需要划分的k类在刚刚的分类结果中查找。
如果说k均值聚类是一种从前往后的分类方法,系统聚类就是一种从后往前的分法。由于它的分类过程并不直接依赖我们需要的k类,就比较有效地解决了k均值聚类的遗留问题√
最后推荐一下清风老师的数模课程,试听课入口