Flume学习文档(2){Flume安装部署、Flume配置文件}
Flume学习文档(2)
【有问题或错误,请私信我将及时改正;借鉴文章标明出处,谢谢】
接我上一篇文章,Flume学习文档(1)
3.Flume的安装配置
(1)下载并解压
到官网进行下载

(2)修改flume配置文件flume-env.sh.template

4.Flume配置文件
(1)案例一
使用Flume监听一个端口,收集该端口数据,并打印到控制台
1>安装netcat工具
yum install -y nc
{
在用yum安装前虚拟机光盘需要连接,并创建挂载目录及挂载上光盘
(1)选择centos安装光盘,连接cdrom
(2)mkdir -p /media/cdrom #创建光盘挂载
(3)mount /dev/cdrom /media/cdrom #挂载光盘
上面3个步骤就完成挂载了

}
2>判断44444端口是否被占用
netstat -tunlp | grep 44444
3>在flume/job下创建配置文件名为:flume-netcat-logger.conf
# example.conf: A single-node Flume configuration
# Name the components on this agent #变量的声明操作
a1:表示agent的名称
a1.sources = r1 #r1:表示a1的Source的名称
a1.sinks = k1 #k1:表示a1的Sink的名称
a1.channels = c1 #c1:表示a1的Channel的名称
# Describe/configure the source
a1.sources.r1.type = netcat #表示a1的输入源类型为netcat端口类型
a1.sources.r1.bind = localhost #表示a1的监听的主机a1.sources.r1.port = 44444 #表示a1的监听的端口号
# Describe the sink
a1.sinks.k1.type = logger #表示a1的输出目的地是控制台logger类型
# Use a channel which buffers events in memory
a1.channels.c1.type = memory #表示a1的channel类型是memory内存型
a1.channels.c1.capacity = 1000 #容量,1000个事件。表示a1的channel总容量1000个event
a1.channels.c1.transactionCapacity = 100 #一次传输多少事件,比容量小表示a1的channel传输时收集到了100条event以后再去提交事务
# Bind the source and sink to the channel #绑定
a1.sources.r1.channels = c1 #表示将r1和c1连接起来
a1.sinks.k1.channel = c1 #表示将k1和c1连接起来
#sink只能绑定一个channel,channel可以绑定多个sink 。如: 添加a1.sinks.k2.channel = c1
4>先开启flume监听端口
第一种写法:
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
第二种写法:
bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
参数说明:
bin/:flume安装目录下
flume-ng agent:可执行文件
agent:启动agent
–conf/-c:表示配置文件存储在conf/目录
–name/-n:表示给agent起名为a1
–conf-file/-f:flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。
-Dflume.root.logger=INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。console输出到控制台
5>使用netcat工具向本机的44444端口发送内容
nc localhost 44444 #下面大括号内为自己打的内容
{
hello
}
6>在Flume监听页面观察接收数据情况
此案例flume是服务端,nc是客户端
(2)案例二(从案例二开始只有配置文件信息及解释)
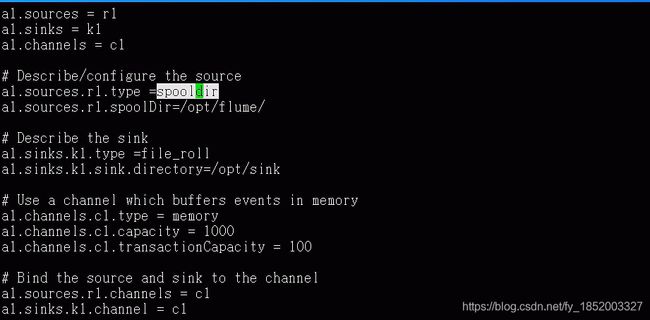
spooldir directory Source :监听一个文件夹下新产生的文件,并读取内容,发至channel
type: 组件的类型名称,必须为:spooldir
spoolDir:源的地址(从哪个地方读取文件)
File Roll Sink:将事件存储在本地文件系统上
type:组件的类型名称,必须为:file_roll
sink.directory:文件存储目录(输出的文件到哪里)
Memory Channel:事件存储在内存队列中,该队列具有可配置的最大大小。对于需要更高吞吐量并准备在代理发生故障时丢失分段数据的流而言,它是理想的选择
type:组件的类型名称,必须为:memory
capacity:存储的最大事件数,默认100
transactionCapacity:每次从源或汇给接收器的最大事件数,默认100
(3)案例三
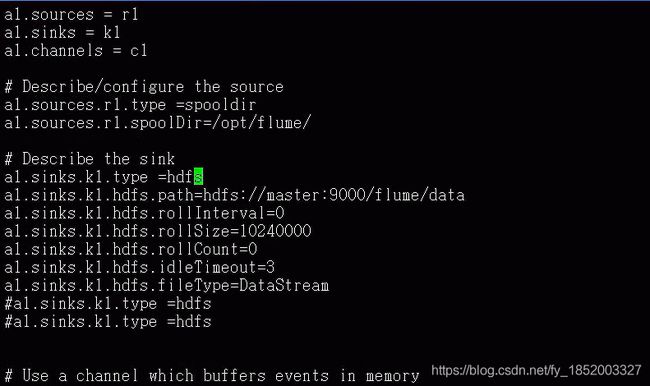
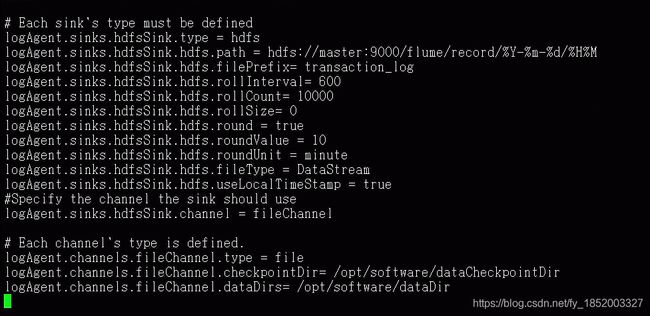
HDFS Sink:该接收器将事件写入Hadoop分布式文件系统(HDFS)。当前,它支持创建文本和序列文件。它支持两种文件类型的压缩。可以根据经过的时间或数据大小或事件数定期滚动文件(关闭当前文件并创建一个新文件)。它还按时间戳或事件发生的机器之类的属性对数据进行存储/分区。HDFS目录路径可能包含格式化转义序列,这些序列将由HDFS接收器取代,以生成用于存储事件的目录/文件名。使用此接收器需要安装hadoop,以便Flume可以使用Hadoop jar与HDFS群集进行通信。请注意,需要支持sync()调用的Hadoop版本
type:组件类型名称,必须为hdfs
hdfs.path:HDFS目录路径
hdfs.filePrefix:flume在hdfs目录中创建的文件加上 前缀的名称
hdfs.rollInterval:滚动当前文件之前需要等待的秒数。,默认30秒,如果是0,则从不根据时间间隔滚动
hdfs.rollSize:触发滚动的文件大小,以字节为单位。默认1024个字节,如果是0,从不根据文件大小滚动
hdfs.rollCount:滚动之前写入文件的事件数。默认10个,如果是0,则从不根据事件数滚动
hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount配合使用
hdfs.idelTimeout:超时不活动的文件将关闭。默认0,则禁用自动关闭空闲文件
hdfs.fileType:DataStream不会压缩出文档
启动flume:
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf
#不需要写-Dflume.root.logger=INFO,console,因为用的是hdfs sink
(4)案例四
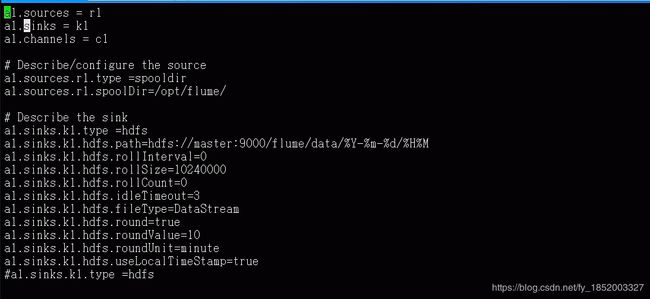
%Y :年(eg:2020)
%y :年份后两位(eg:00)
round:时间戳是否应该四舍五入(如果为true,则将影响所有基于时间的转义序列,但%t除外)。默认false。若设置为true需要配合roundValue、roundUnit
roundValue:四舍五入到小于当前世间安得最高倍数(使用hdfs.roundUnit配置的单位)。默认为1
roundUnit:舍入值的单位,秒,分钟或小时。默认为秒
userLocalTimeStamp:替换转义序列时,请使用本地时间(而不是时间标头中的时间戳)。默认为false
(5)案例五
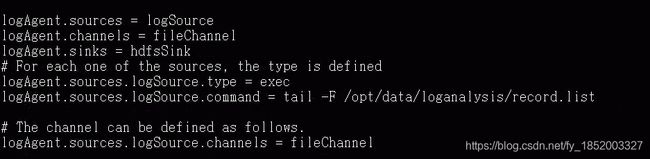
Exec Source:Exec源代码在启动时运行给定的Unix命令,并期望该过程在标准输出上连续产生数据(除非将属性logStdErr设置为true,否则将直接丢弃stderr)。如果该过程由于某种原因退出,则源也将退出,并且将不再产生任何数据。这意味着诸如cat [named pipe]或tail -F [file]之类的配置将产生期望的结果,而日期可能不会产生这种结果-前两个命令产生数据流,而后者则产生单个事件并退出。
tail -F 实时的获取文件的尾部的变换数据
tail -f 小f监控获取任务失败就失败了,大f会自动重试
type:组件类型名称,必须为exec
command:要执行的命令
File Channel:Memory可能会数据丢失,File不会数据丢失
type:组件类型名称,必须为file
checkpointDir:将存储检查点文件的目录
dataDirs:用逗号分隔的目录列表,用于存储日志文件。在单独的磁盘上使用多个目录可以提高文件通道性能
【有问题或错误,请私信我将及时改正;借鉴文章标明出处,谢谢】