pytorch(四)神经网络部分详解
解决方案的构成:
- 一、数据导入
- 1、torchvision提供的数据集
- 2、torchvision中的通用数据集ImageFolder来完成加载。
- 3、本地数据
- 二、构建网络模型
- 三、损失函数和优化器
- 四、开始训练模型
- 五、对训练的模型预测结果进行评估
一、数据导入
数据导入的三种方式
1、torchvision提供的数据集
https://www.cnblogs.com/CATHY-MU/p/7760992.html
2、torchvision中的通用数据集ImageFolder来完成加载。
- 数据满足下列形式
root/ants/xxy.jpeg
root/ants/xxz.png
.
.
.
root/bees/123.jpg
root/bees/nsdf3.png
root/bees/asd932_.png
- 加载方法
import torch
from torchvision import transforms, datasets
data_transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
hymenoptera_dataset = datasets.ImageFolder(root='hymenoptera_data/train',
transform=data_transform)
dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset,
batch_size=4, shuffle=True,
num_workers=4)
3、本地数据
本地数据集加载实例
参数详解
源码解析
- Dataset
Dataset类是Pytorch中图像数据集中最为重要的一个类,也是Pytorch中所有数据集加载类中应该继承的父类。其中父类中的两个私有成员函数必须被重载,否则将会触发错误提示:
def getitem(self, index):
def len(self):
其中__len__应该返回数据集的大小,而__getitem__应该编写支持数据集索引的函数,例如通过dataset[i]可以得到数据集中的第i+1个数据。
# 假设下面这个类是读取船只的数据类
class ShipDataset(Dataset):
"""
root:图像存放地址根路径
augment:是否需要图像增强
"""
def __init__(self, root, augment=None):
# 这个list存放所有图像的地址
self.image_files = np.array([x.path for x in os.scandir(root) if
x.name.endswith(".jpg") or x.name.endswith(".png") or x.name.endswith(".JPG")]
self.augment = augment # 是否需要图像增强
def __getitem__(self, index):
# 读取图像数据并返回
# 这里的open_image是读取图像函数,可以用PIL、opencv等库进行读取
return open_image(self.image_files[index])
def __len__(self):
# 返回图像的数量
return len(self.image_files)
- DataLoader:
之前所说的Dataset类是读入数据集数据并且对读入的数据进行了索引。但是光有这个功能是不够用的,在实际的加载数据集的过程中,我们的数据量往往都很大,对此我们还需要一下几个功能:
可以分批次读取:batch-size
可以对数据进行随机读取,可以对数据进行洗牌操作(shuffling),打乱数据集内数据分布的顺序
可以并行加载数据(利用多核处理器加快载入数据的效率)
DataLoader位于torch.utils.data.DataLoader, 为我们提供了对Dataset的读取操作
dataset: 上面所实现的自定义类Dataset
batch_size: 默认为1,每次读取的batch的大小
shuffle: 默认为False, 是否对数据进行shuffle操作(简单理解成将数据集打乱)
num_works: 默认为0,表示在加载数据的时候每次使用子进程的数量,即简单的多线程预读数据的方法
DataLoader返回的是一个迭代器,我们通过这个迭代器来获取数据
# 利用之前创建好的ShipDataset类去创建数据对象
ship_train_dataset = ShipDataset(data_path, augment=transform)
# 利用dataloader读取我们的数据对象,并设定batch-size和工作现场
ship_train_loader = DataLoader(ship_train_dataset, batch_size=16, num_workers=4, shuffle=False, **kwargs)
for image in train_loader:
image = image.to(device) # 将tensor数据移动到device当中
optimizer.zero_grad()
output = model(image) # model模型处理(n,c,h,w)格式的数据,n为batch-size
完整实例
我的代码
tansform参数解析
二、构建网络模型
全连接神经网络是一种最基本的神经网络结构,英文为Full Connection,所以一般简称FC。
FC的准则很简单:神经网络中除输入层之外的每个节点都和上一层的所有节点有连接。例如下面这个网络结构就是典型的全连接:神经网络的第一层为输入层,最后一层为输出层,中间所有的层都为隐藏层。
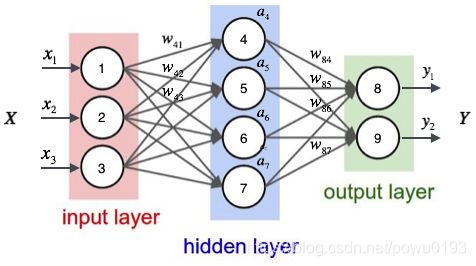
我们定义了三个不层次的神经网络模型:简单的FC,加激活函数的FC,加激活函数和批标准化的FC。
from torch import nn
class simpleNet(nn.Module):
"""
定义了一个简单的三层全连接神经网络,每一层都是线性的
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(simpleNet, self).__init__()
self.layer1 = nn.Linear(in_dim, n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1, n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
class Activation_Net(nn.Module):
"""
在上面的simpleNet的基础上,在每层的输出部分添加了激活函数
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Activation_Net, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
"""
这里的Sequential()函数的功能是将网络的层组合到一起。
"""
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
class Batch_Net(nn.Module):
"""
在上面的Activation_Net的基础上,增加了一个加快收敛速度的方法——批标准化
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Batch_Net, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.BatchNorm1d(n_hidden_1), nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.BatchNorm1d(n_hidden_2), nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
三、损失函数和优化器
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
四、开始训练模型
# 训练模型
epoch = 0
for data in train_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
print_loss = loss.data.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch+=1
if epoch%50 == 0:
print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))
五、对训练的模型预测结果进行评估
# 模型评估
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item()*label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))
))
以上代码来自:https://blog.csdn.net/out_of_memory_error/article/details/81414986
完整代码:https://github.com/viki6666/Pytorch_learn/blob/master/FCNN.ipynb
参考文献:
https://blog.csdn.net/qq_40314507/article/details/89217517
https://blog.csdn.net/qq_21905401/article/details/82627402
模型加载与保存:https://blog.csdn.net/FPGATOM/article/details/85337469