数据结构与算法总结笔记 及其 Python代码实现
常用tips
常用的数据结构: 数组,链表,栈、队列、散列表、二叉树、堆、跳表、图、Trie 树;
常用的算法: 递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
ps: 以下的笔记摘抄整理自极客时间,侵删
常见的时间复杂度:

常见的空间复杂度: O(1)、O(n)、O(n2) (表示算法的存储空间与数据规模之间的增长关系)
数据结构相关
1 数组:
组用一块连续的内存空间,来存储相同类型的一组数据,最大的特点就是支持随机访问,但插入、删除操作也因此变得比较低效,平均情况时间复杂度为 O(n)
2 链表
链表不同于数组,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用。
缓存淘汰策略
常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)
三种最常见的链表结构,它们分别是:单链表、双向链表和循环链表。
单链表: 头结点用来记录链表的基地址,可以根据头结点来遍历得到整条链表。而尾结点特殊的地方是:指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点。
循环链表: 循环链表是一种特殊的单链表。跟单链表唯一的区别就在尾结点。单链表的尾结点指针指向空地址,表示这就是最后的结点了。而循环链表的尾结点指针是指向链表的头结点。
双向链表: 支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。
3
栈
后进者先出,先进者后出
队列
先进者先出
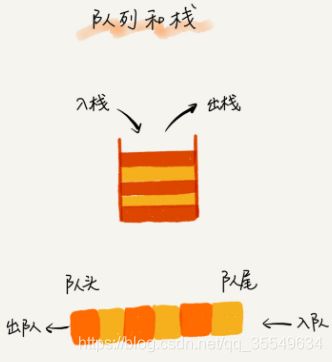
数组实现的栈叫作顺序栈,用链表实现的栈叫作链式栈。
同样,用数组实现的队列叫作顺序队列,用链表实现的队列叫作链式队列。
在数组实现队列的时候,会有数据搬移操作,要想解决数据搬移的问题,我们就需要像环一样的循环队列。
4
字典树:
Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。
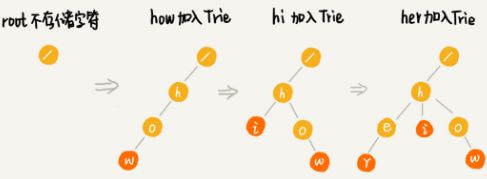
Trie 树主要有两个操作,一个是将字符串集合构造成 Trie 树。这个过程分解开来的话,就是一个将字符串插入到 Trie 树的过程。另一个是在 Trie 树中查询一个字符串。
算法相关
排序算法(冒泡排序,插入排序,选择排序,归并排序,快速排序,桶排序)
时间复杂度

排序

基于比较的排序算法的执行过程,会涉及两种操作,一种是元素比较大小,另一种是元素交换或移动。所以,如果我们在分析排序算法的执行效率的时候,应该把比较次数和交换(或移动)次数也考虑进去。
1 冒泡排序
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。

Python代码实现如下:
def bubble(arr):
# 遍历所有的元素
for i in range(len(arr)):
# 比对还未排好序的相邻元素(注意要减i,i为橙红色排好序的元素)
for j in range(len(arr)-i -1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
2 插入排序
取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序

Python代码实现如下:
def insertionSort(arr):
# 第一轮比较后,最小值在最左侧,左侧为排序好的数字
for i in range(1, len(arr)):
# 记录当前比较数字的位置,之后与这个数字之前的数字(左边的数字)进行比较
key = arr[i]
# 与当前的前一位数字进行比较
j = i - 1
#
while j >= 0 and key < arr[j]: # 初始key为a[j+1]的值
arr[j + 1] = arr[j] # 左侧的值依次比较
j -= 1
arr[j + 1] = key
return arr
3 选择排序
选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
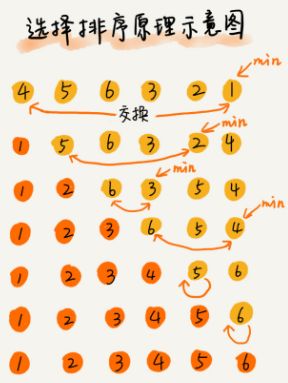
Python代码实现:
def slect_sort(A):
for i in range(len(A)):
# 保存最小值的位置
min_idx = i
for j in range(i + 1, len(A)):
# 找到最小值的位置
if A[min_idx] > A[j]:
min_idx = j
A[i], A[min_idx] = A[min_idx], A[i]
return A
插入排序与冒泡排序的区别:
假如均为从小到大排序,插入排序在第一轮比较结束后,最小值排在最左边。而冒泡排序在第一轮比较结束后,最大值排在最右边。都是比较相邻元素,交换相邻位置的元素。
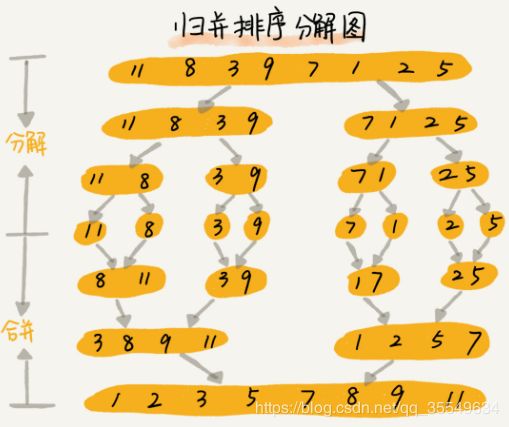
4 归并排序
如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了
伪代码实现:
// 归并排序算法, A是数组,n表示数组大小
merge_sort(A, n) {
merge_sort_c(A, 0, n-1)
}
// 递归调用函数
merge_sort_c(A, p, r) {
// 递归终止条件
if p >= r then return
// 取p到r之间的中间位置q
q = (p+r) / 2
// 分治递归
merge_sort_c(A, p, q)
merge_sort_c(A, q+1, r)
// 将A[p...q]和A[q+1...r]合并为A[p...r]
merge(A[p...r], A[p...q], A[q+1...r])
}
伪代码的解释:
merge_sort(p…r) 表示,给下标从 p 到 r 之间的数组排序。我们将这个排序问题转化为了两个子问题,merge_sort(p…q) 和 merge_sort(q+1…r),其中下标 q 等于 p 和 r 的中间位置,也就是 (p+r)/2。当下标从 p 到 q 和从 q+1 到 r 这两个子数组都排好序之后,我们再将两个有序的子数组合并在一起,这样下标从 p 到 r 之间的数据就也排好序了。
merge(A[p…r], A[p…q], A[q+1…r]) 这个函数的作用就是,将已经有序的 A[p…q]和 A[q+1…r]合并成一个有序的数组,并且放入 A[p…r]
对merge方法,如图所示,我们申请一个临时数组 tmp,大小与 A[p…r]相同。我们用两个游标 i 和 j,分别指向 A[p…q]和 A[q+1…r]的第一个元素。比较这两个元素 A[i]和 A[j],如果 A[i]<=A[j],我们就把 A[i]放入到临时数组 tmp,并且 i 后移一位,否则将 A[j]放入到数组 tmp,j 后移一位。
继续上述比较过程,直到其中一个子数组中的所有数据都放入临时数组中,再把另一个数组中的数据依次加入到临时数组的末尾,这个时候,临时数组中存储的就是两个子数组合并之后的结果了。最后再把临时数组 tmp 中的数据拷贝到原数组 A[p…r]中。
对应的图解分析如下:

Python代码实现
def merge(arr, l, m, r):
n1 = m - l + 1
n2 = r - m
# 创建临时数组
L = [0] * (n1)
R = [0] * (n2)
# 拷贝数据到临时数组 arrays L[] 和 R[]
for i in range(0, n1):
L[i] = arr[l + i]
for j in range(0, n2):
R[j] = arr[m + 1 + j]
# 归并临时数组到 arr[l..r]
i = 0 # 初始化第一个子数组的索引
j = 0 # 初始化第二个子数组的索引
k = l # 初始归并子数组的索引
while i < n1 and j < n2:
if L[i] <= R[j]:
arr[k] = L[i]
i += 1
else:
arr[k] = R[j]
j += 1
k += 1
# 拷贝 L[] 的保留元素
while i < n1:
arr[k] = L[i]
i += 1
k += 1
# 拷贝 R[] 的保留元素
while j < n2:
arr[k] = R[j]
j += 1
k += 1
def mergeSort(arr, l, r):
if l < r:
m = int((l + (r - 1)) / 2)
mergeSort(arr, l, m)
mergeSort(arr, m + 1, r)
merge(arr, l, m, r)
print(arr)
if __name__ == "__main__":
arr = [4, 3, 6, 1, 2]
mergeSort(arr, 0, len(arr)-1)
5 快排
如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。

归并排序中有一个 merge() 合并函数,我们这里有一个 partition() 分区函数
partition() 分区函数可以写得非常简单。我们申请两个临时数组 X 和 Y,遍历 A[p…r],将小于 pivot 的元素都拷贝到临时数组 X,将大于 pivot 的元素都拷贝到临时数组 Y,最后再将数组 X 和数组 Y 中数据顺序拷贝到 A[p…r]
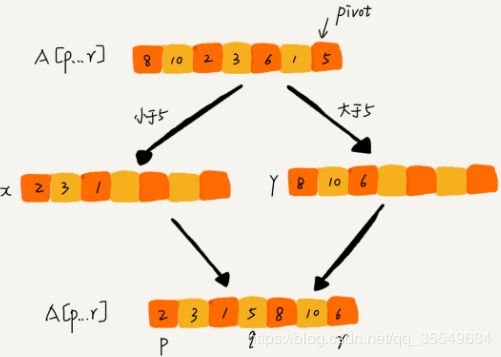
归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。

Python代码实现
def partition(arr, low, high):
i = (low - 1) # 最小元素索引
pivot = arr[high]
for j in range(low, high):
# 当前元素小于或等于 pivot
if arr[j] <= pivot:
i = i + 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return (i + 1)
# arr[] --> 排序数组
# low --> 起始索引
# high --> 结束索引
# 快速排序函数
def quickSort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quickSort(arr, low, pi - 1)
quickSort(arr, pi + 1, high)
arr = [10, 7, 8, 9, 1, 5]
n = len(arr)
quickSort(arr, 0, n - 1)
print("排序后的数组:")
6 桶排序
核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

常见算法面试题
归并排序和快速排序都用到了分治思想,非常巧妙。
我们可以借鉴这个思想,来解决非排序的问题,比如:
(1)如何在 O(n) 的时间复杂度内查找一个无序数组中的第 K 大元素?(快排,归并)
(2)快速找到最大的K个元素?(堆排序)
(3)两个大数相乘(转换为两个字符串相乘,按位相乘)