R语言︱情感分析—基于监督算法R语言实现(二)
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————
笔者寄语:本文大多内容来自未出版的《数据挖掘之道》的情感分析章节。本书中总结情感分析算法主要分为两种:词典型+监督算法型。
监督算法型主要分别以下几个步骤:
构建训练+测试集+特征提取(TFIDF指标)+算法模型+K层交叉验证。可与博客对着看:R语言︱词典型情感分析文本操作技巧汇总(打标签、词典与数据匹配等)
————————————————————————————————————————————————
基于监督算法的情感分析存在着以下几个问题:
(1)准确率而言,基于算法的方法还有待提高,而目前的算法模型准确性很难再上一个层次,所以研究者要不创造更新更强大的算法,要不转向寻求其他的解决方案以使准确率更上一个台阶;
(2)如果文本越来越多,词汇变量也会增多,矩阵会越来越稀疏,计算量越来越大,这样在挑选算法的同时我们将不得不解决另外一个问题,即特征词的提取,这里的特征词提取方法不是一般的特征词提取方法就能解决的,其目的是提取能够区分情感倾向的特征词,所以找到能够实现目的的方法也着实不易。
(3)基于算法的分析方式一般具有行业特殊性,也就是说很难训练一个可以跨行业的模型,这样就会遇到另外一个问题:挑选训练样本。比如本来是针对汽车销售行业构建的模型迁移到快消行业,准确性就有可能下降,为了保证准确性,须要挑选快消行业的训练集进行重训练,那问题来了,这种训练集一般要成千上万条文本评论,人工挑选的话也许会让人筋疲力尽,眼前发黑的。
目前以上三点是基于算法的方法需要改进和提高的关键点,至于分析情感的细腻程度、情感主体归属等等问题就不仅仅是算法这一种解决方案的问题了,其他方式同样也会遇到这类麻烦,可以另外作为一个新的课题进行研究。(摘自《数据挖掘之道》)
————————————————————————————————————————————————
一、TFIDF算法指标的简介
监督式算法需要把非结构化的文本信息转化为结构化的一些指标,这个算法提供了以下的一些指标,在这简单叙述:
TF = 某词在文章中出现的次数/文章包含的总词数(或者等于某词出现的次数)
TFIDF = TF*IDF
TF就是一篇文章中出现某个词的次数,你可能认为“中国”出现的次数最多,其实不然,“的”、“是”、“在”、”地“之类最多,这类词是停用词,在提取关键词之前必须剔除掉。
剔除停用词之后,比如“中国”、“省份”等一些常用的词的词频也会很高,这时候需要用IDF("逆文档频率"(Inverse Document Frequency,缩写为IDF))来把这些词的权重调低,如果一个词比较“常见”(指在日常所有文档中),那么它的IDF就比较低。要计算IDF,首先要有一个充实的语料库。利用IDF作为惩罚权重,就可以计算词的TFIDF。
这几个指标就会监督型算法的核心指标,用来作为以后分类的输入项。
我们有了三个指标:tf、df、tfidf,选哪个用于构建模型?由于tf受高频词影响较大,我们暂时将其排除,根据上面的统计逻辑发现正向样本中某个词语的df和负向样本的相同,因为我们并没有把正负样本分开统计,所以在这种情况下使用df建模基本上不可能将正负样本分开,只有选tfidf了。
构建随机森林模型时需要将每一个词汇作为一个变量或者维度,这样矩阵会变得异常稀疏,但我们先不讲究这些,在企业内做数据挖掘建模时,第一目标不是追求模型统计上的完美性,而是在测试集和训练集上的稳定性和准确性。
关注这部分的理论内容详情可见博客:非主流自然语言处理——遗忘算法系列(四):改进TF-IDF权重公式
————————————————————————————————————————————————
二、构建训练+测试数据集
1、构建训练数据集
市面上一些比较流行的语料库可见博客:情感分析︱网络公开的免费文本语料训练数据集汇总
构建训练集的步骤有:数据集导入、数据集一、二级清洗、分词、三级清洗(去停用)
1.1 数据集导入
train <- read.csv("./train.csv", sep = ",", header = T, stringsAsFactors = F)文本作为非结构数据,导入是一个大问题,因为其有众多的分隔符、标点符的问题需要处理。
导入的数据中有一列是:label,这个就是标准的情感定义,定义这句话的正负情感(1,-1),所以是监督式的算法。
# Warning message:
# In scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings, :
# EOF within quoted string`read.csv`函数读取文件时,可能报警:“EOF within quoted string”,一般为数据中不正常的符号所致,常见的方法是将`quote = ""`设置为空,这样做虽然避免了警告,但是仍然解决不了问题,有时数据会对不上号,所以最好从符号上着手将一些特殊符号去除,还有一些文本的正则表达式的问题,可见博客: R语言︱文本(字符串)处理与正则表达式。
1.2 数据清洗(一、二级)
文本数据清洗步骤有很多:一级清洗(去标点)、二级清洗(去内容)、三级清洗(去停用词,这个步骤一般分词之后)(具体可参考博客第二部分内容:R语言︱词典型情感分析文本操作技巧汇总(打标签、词典与数据匹配等))
#一级清洗——去标点
sentence <- as.vector(train$msg)
sentence <- gsub("[[:digit:]]*", "", sentence) #清除数字[a-zA-Z]
sentence <- gsub("[a-zA-Z]", "", sentence)
sentence <- gsub("\\.\\.", "", sentence)
#二级清洗——去内容
train <- train[!is.na(sentence), ]
sentence <- sentence[!is.na(sentence)]
train <- train[!nchar(sentence) < 2, ]
sentence <- sentence[!nchar(sentence) < 2]1.3 分词+构建数据集
一般分词可以用Rwordseg包或者jiebaR包来进行,
library(Rwordseg)
insertWords(dict)
system.time(x <- segmentCN(strwords = sentence))
temp <- lapply(x, length)
temp <- unlist(temp)
id <- rep(train[, "id"], temp)
label <- rep(train[, "label"], temp)
term <- unlist(x)
trainterm <- as.data.frame(cbind(id, term, label), stringsAsFactors = F)后续的步骤是将分词之后的每个词语,打上id+label标签,可见文本挖掘操作技巧文档第四节。
1.4 三级清洗-去停用词
stopword <- read.csv("./stopword.csv", header = T, sep = ",", stringsAsFactors = F)
stopword <- stopword[!stopword$term %in% dict,]
trainterm <- trainterm[!trainterm$term %in% stopword,]尽量去除一些非特征词汇可以有效的降低计算量和内存占用率,但是在小数据量下是可有可无的,但是如果分词的内容多,这个步骤还是很关键的。
2、测试集数据构建
测试集也跟训练集一样需要经历一、二级清洗,分词,三级清洗去停用。
最后得到了数据集testterm。同样也要跟训练集一样,进行特征提取,计算TFIDF指标,但是稍有不同,见下3.4节。
————————————————————————————————————————————————
三、特征提取——TFIDF指标
在统计TFIDF等指数之前,还要处理下数据,因为在分词的时候分出了空白符,这种空白符即不能用is.na、is.null、is.nan这些函数查出来,也不能使用常见的空白符(空格" ",制表符"\t",换行符"\n",回车符"\r",垂直制表符"\v",分页符"\f")包括空白符("\\s")等正则规则查出来。
trainterm <- trainterm[grepl("\\S", trainterm$term),]3.1 计算TF指标
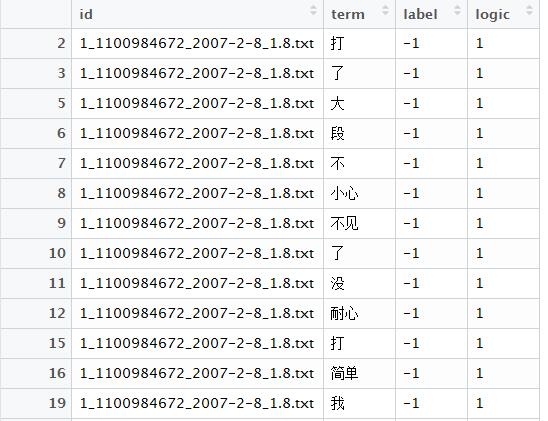
如上图1,logic就是新加的一列数字。
trainterm$logic <- rep(1, nrow(trainterm))# 添加辅助列计算TF指标,是指计算每个文档,每个词的词频数,等于计数,这时需要添加一列数字1,来方便计数。
有点像做高中应用题时候,要加入一些工具线,或者经济学中的工具变量来过渡解决问题。
library(dplyr)
traintfidf <- aggregate(logic ~ id + label + term, data = trainterm, FUN = sum) %>% rename(tf = logic)代码解读:这里的aggregate是以新数据列为计数列,以id+label+term为标签列(控制变量),
其中为啥加入label呢? 不是说,按照每个文档(id),每个词(term)就可以了吗?
答:其实加了label不影响计数结果,只是让分类更有理有据一些。aggregate相当于把每个文档的词去重了一下,不是ID去重,在不同文档中也可能存在相同的词。
书中提到,要统计tf,可以通过`table`函数、`dcast`函数(reshape2包、plyr包都有这个函数)等实现,但是尝试之后发现它们要不速度慢,要不就是占用内存太高,包括data.table里的`dcast`函数,原因在于它们的中间过程要进行矩阵的转换。这里使用`aggregate`统计每篇文章每个词的频次,2行添加了一个辅助列logic,当然不添加辅助列,设置`aggregate`里的FUN参数为`length`函数也能完成,但是数据量大时耗费时间太长,不如添加辅助列,而FUN参数调用`sum`函数速度快,这句的意思就是按照id、term、label三列分组后对logic求和。
3.2 计算DF列
total <- length(unique(traintfidf$id))#统计出参与计算的文章id数,即总文章数
temp <- data.frame(table(traintfidf$term)/total) #DF=每个词的数量(就是每个词的文本数量)/总文本数量
names(temp) <- c("term", "df")
traintfidf <- left_join(traintfidf, temp)
#不要dplyr包、plyr包同时使用,比如这里就会导致rename函数被覆盖,二者的功能相似,没必要同时加载,或者先加载plyr再加载dplyr。计算DF,是每个词文档频率,需要知道全文档数量以及每个词的文档数量,该咋办呢?
如图1,全文档数量只要统计ID就行,所以length一下去重(unique)的ID;
每个词的文档数量与词频TF是有很大区别的,TF=每个文档每个词的次数,DF=所有文档每个词的次数。所有文档每个词的次数就是计数一下即可,在这用table函数。
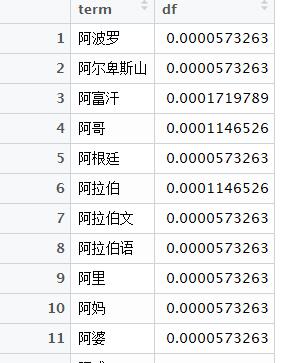
图2
现在有了每个词的文档频率,该如何匹配到原来的数据集中呢?
由于没有ID,那么匹配 就不得不用一些词库之间的匹配方式,可以用%in%做去除,但是不太好用其做打标签的过程。
所以用了dplyr包中的left-join函数,left_join(x,y,by="name") ##xy匹配到的都保留。 词库之间也可以根据词语进行匹配,这个非常棒,如图3,“阿富汗”重复的也可以直接关联上去。
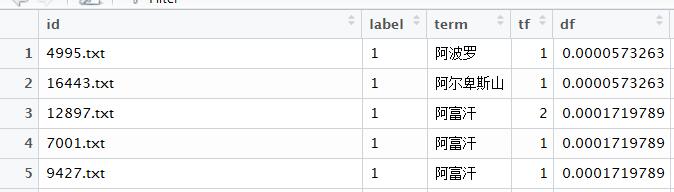
图3
3.3 计算IDF(逆文档频率)以及TFIDF指标
IDF = log((语料库的文档总数)/(包含某词的文档数+1))
IDF的起源是因为一堆无用的高频词(比如中国、政府)出现的太多,通过加权将这些词的权重下调。
temp <- data.frame(log(total/(table(traintfidf$term) + 1))) #traintfidf$term代表每个词的文档数,计算IDF
names(temp) <- c("term", "idf")
traintfidf <- left_join(traintfidf, temp)
traintfidf$tfidf <- traintfidf$tf*traintfidf$idf文档总数=ID的数量,用去重的id来计算length,就是代码中的total,
每个词的文档数,就是每个词在所有文档的数量,用table来计数,公式中很多要素都跟DF值一样。
然后通过left_join合并之后,计算TFIDF=TF*IDF,就得到了每个文档每个词的TFIDF值,即为该词的特征值。
3.4 测试集的TFIDF指标
测试集的计算过程与训练集非常不一样,测试集的指标根据训练集的数据,直接调用即可。
(1)TF值跟训练集一样,添加一个辅助列,然后aggregate一下。
testterm <- testterm[grepl("\\S", testterm$term),]
testterm$logic <- rep(1, nrow(testterm))# 添加辅助列
testtfidf <- aggregate(logic ~ id + label + term, data = testterm, FUN = sum) %>% rename(tf = logic)#TF
#%>%来自library(tidyr),rename来自reshape包(2)DF、IDF、TFIDF值
total <- length(unique(traintfidf$id)) #训练集文本总数
temp <- data.frame(table(traintfidf$term)/total) #训练集DF指标
names(temp) <- c("term", "df")
testtfidf <- left_join(testtfidf, temp) #匹配到test中
# idf来源于语料库,跟DF一样
temp <- data.frame(log(total/(table(traintfidf$term) + 1))) #来自训练集的IDF
names(temp) <- c("term", "idf")
testtfidf <- left_join(testtfidf, temp)
testtfidf$tfidf <- testtfidf$tf*testtfidf$idf #计算TFIDF 空缺值很多其中肯定存在很多问题:
训练集的DF、IDF相当于是固定的,然后根据词库匹配,跟测试集合并,那么DF、IDF就不受测试集词语数量的影响了?
答:对的,训练集相当于就是基本的语料库,作为素材源头;
测试集肯定比训练集有多的单词,这部分单词怎么处理?
答:直接删除,如果这部分单词的确有用,可以加入训练集的分词库,在做一次训练集的分词内容,当然训练集之后的步骤都要重新来一遍。
如何查看测试集中有,而训练集中没有的单词呢?可以用%in%,A[A%in%B,],可见文本挖掘操作技巧的2.3节。
left_join的过程中,为什么没用写明参照哪个变量?
答:会出现一下的错误:
Joining by: "term"
Warning message:
In left_join_impl(x, y, by$x, by$y) :
joining factor and character vector, coercing into character vector————————————————————————————————————————————————
四、算法模型
关于算法模型,书中选用了随机森林,先不考虑为啥选择这个模型,我们直接来看看如何实现这个模型。
4.1 模型数据整理
随机森林既能完成分类任务也能完成回归预测任务,训练数据标签里只有两个分类1(正向)或-1(负向),理论上属于分类任务。
`randomForest`函数要求为数据框或者矩阵,需要原来的数据框调整为以每个词作为列名称(变量)的数据框。也就是一定意义上的稀疏矩阵(同关联规则),也就是将long型数据框转化为wide型数据框。
转换可以用的包有reshape2以及data.table。其中,data.table里的`dcast`函数比reshape2包里的`dcast`好用,尽管他们的参数都一样,但是很多人还是比较喜欢老朋友reshape2包,然而这一步需要大量的内存,本书在服务器上完成的,如果你的电脑报告内存不足的错误,可以使用data.table包里的`dcast`函数试试。
(笔者游戏本ROG玩家国度,i7-6700,16g内存,69w数据量做随机森林直接崩溃。。。)
转化为稀疏矩阵,1表示访问,0表示未访问。
| Session ID | News | Finance | Entertainment | Sports |
| 1 | 1 | 1 | 0 | 0 |
| 2 | 1 | 1 | 0 | 0 |
| 3 | 1 | 1 | 0 | 1 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 1 | 1 | 0 | 1 |
| 6 | 1 | 0 | 1 | 0 |
library(data.table)
train <- dcast(data = traintfidf, id + label ~ term, sum, value.var = "tfidf") dcast是data.table中有用的函数,实现以term为横向分类依据,id+label作为纵向分类依据求和。value.var给出的是分类主要指标,这里只选择了tfidf一个指标。
如下图4,可知左边按id与label进行分类,右边是按每个单词,相当于变成了n*n个数据量,计算消耗非常大。
可参考博客:给R变个形
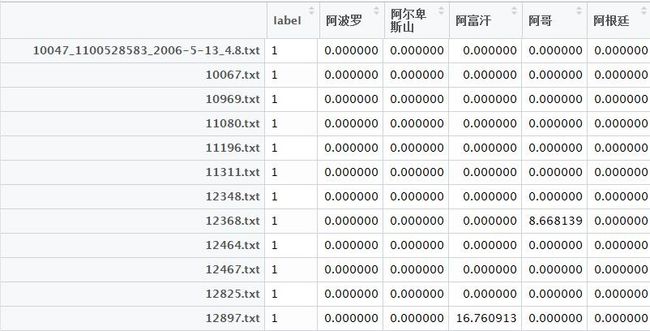
图4
4.2 训练集- 随机森林模型
随机森林模型不需要id项,通过row.names把id这一列放在R默认序号列,如图4中的第一列。
随机森林模型,分类和回归预测的操作不同之处在于判断因变量的类型,如果因变量是因子则执行分类任务,如果因变量是连续性变量,则执行回归预测任务。
library(randomForest)
row.names(train) <- train[, "id"] #row.names代表着R编号列
train <- subset(train, select = -id)
train$label <- as.factor(train$label)
system.time(Randommodel100 <- randomForest(x = subset(train, select = -label), y = train[, "label"], importance = TRUE, proximity = FALSE, ntree = 100))#构建模型
#首先判断因变量的类型,如果因变量是因子则执行分类任务,如果因变量是连续性变量,则执行回归预测任务
print(Randommodel100)
# Call:
# randomForest(x = subset(train, select = -label), y = train[, "label"], ntree = 100, importance = TRUE, proximity = FALSE)
# Type of random forest: classification
# Number of trees: 100
# No. of variables tried at each split: 157
#
# OOB estimate of error rate: 7.04%
# Confusion matrix:
# -1 1 class.error
# -1 11602 274 0.02307174
# 1 968 4808 0.16759003需要把标签列变成因子型才能做分类的随机森林模型,
randomForest中的参数,importance设定是否输出因变量在模型中的重要性,如果移除某个变量,模型方差增加的比例是它判断变量重要性的标准之一,proximity参数用于设定是否计算模型的临近矩阵,ntree用于设定随机森林的树数(后面单独讨论)。
print输出模型在训练集上的效果。
4.3 测试集-随机森林模型
(1)测试集的数据再整理
随机森林的数据规则是建立一个稀疏数据集,那么作为额外的测试集的数据,该如何处理,才能跟训练集对上,然后进行算法处理?
为了保证自变量与模型中用到的自变量保持一致,需要补齐完整的单词。
首先要删除一些新词(语料库中没有出现,测试集中出现的词);
testtfidf <- testtfidf[!is.na(testtfidf$tfidf),]# 去掉test中没有匹配到train的词语其次需要给测试集补充上一些缺失词(测试集中没出现,语料库中出现并且用于建模了)。
temp <- unique(testtfidf$term) #term测试集单词,去重
addterm <- unique(traintfidf$term)#训练集单词去重
addterm <- addterm[!addterm %in% temp]#训练集的单词去掉测试集单词addterm就是训练集中,测试集没有的单词,需要补齐。
n <- length(addterm)
temp <- rep(NA, n*length(testtfidf)) #这个在多变量数据集中表示为变量数量
temp <- data.frame(matrix(temp, nrow = n))
temp[, 3] <- addterm
names(temp) <- names(testtfidf) #把构造出的数据集名字变成更test一样
testtfidf <- rbind(testtfidf, temp)
tail(testtfidf) #检查一下是否整理正确
test <- dcast(data = testtfidf, id + label ~ term, sum, value.var = "tfidf") #整理数据,符合随机森林得到了缺失词之后,如何放到训练集的数据中呢?先构造一个n(缺失词)*length(训练集变量个数)的空矩阵,
然后将确实存在放入这个矩阵中,temp[,3]函数;
把空矩阵的变量名,改成训练集的变量名,对的上模型,names函数;
将缺失值与原值进行合并rbind函数,
然后构造随机森林识别的稀疏矩阵,dcast函数。
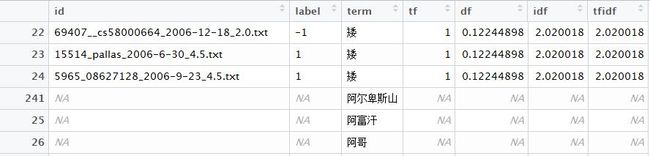
图5
形成了图5的矩阵,term中id、tf、df、idf、tfidf项为空值。之后通过dcast函数形成了随机森林所要的数据结构,来进行后续的分析。
笔者自问自答:
图4是训练集服从随机森林模型dcast之后的图,而图6是测试集dcast之后的表,为啥他们的单词顺序都是一样的呢?如何才能严格符合训练集的数据结构呢?
答:dcast重排的时候,是按照term的名称大小写的顺序来写的,所以肯定和训练集的结构是一致的!
为什么图5中,一些词语的Id为0,而dcast之后,不存在0id的个案呢?
答:还是dcast函数不理解的问题,重排之后,比如图5的“阿尔卑斯山”,就变成了图6的第四列的元素,但是因为阿尔卑斯山没有Id项目,所以都不属于测试集的id,显示的都是0(如图6)。
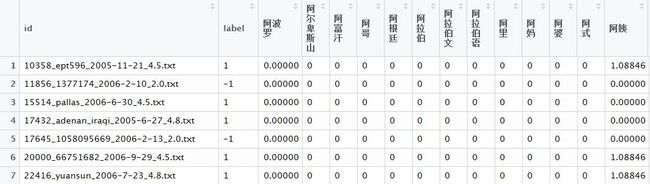
图6
(2)测试集的随机森林建模
测试集建立随机森林模型,还是需要去除缺失值,然后重命名列名,因为模型不接受id这一行作为输入变量,输入的数据集一定要干净。
test <- test[!is.na(test$id), ]
row.names(test) <- test[, "id"]
test <- subset(test, select = -id)
system.time(prediction <- predict(Randommodel100, subset(test, select = - label)))
prediction <- data.frame(cbind(subset(test, select = label),prediction, row.names(test)))随机森林的prediction,可以输出分类标签,将预测分类、实际分类、id合并data.frame成一个数据集,并且row.names跟test一样。
之后再建立混淆矩阵。
evalue <- table(prediction$label, prediction$prediction)
print(evalue)
# -1 1
# -1 1836 129
# 1 618 1324(3)随机森林模型的验证
常见的应用在监督学习算法中的是计算平均绝对误差(MAE)、平均平方差(MSE)、标准平均方差(NMSE)和均值等,这些指标计算简单、容易理解;而稍微复杂的情况下,更多地考虑的是一些高大上的指标,信息熵、复杂度和基尼值等等。可见:R语言︱机器学习模型评估方案(以随机森林算法为例)
本文大多学习之《数据挖掘之道》,还未出版,摘录自公众号:大音如霜,感谢老师的辛勤,真的是非常用心的在写代码以及服务大众。
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————