基于Hadoop的数据仓库Hive基础知识
Hive是基于Hadoop的数据仓库工具,可对存储在HDFS上的文件中的数据集进行数据整理、特殊查询和分析处理,提供了类似于SQL语言的查询语言–HiveQL,可通过HQL语句实现简单的MR统计,Hive将HQL语句转换成MR任务进行执行。
一、概述
1-1 数据仓库概念
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反应历史变化(Time Variant)的数据集合,用于支持管理决策。
数据仓库体系结构通常含四个层次:数据源、数据存储和管理、数据服务、数据应用。
数据源:是数据仓库的数据来源,含外部数据、现有业务系统和文档资料等;
数据集成:完成数据的抽取、清洗、转换和加载任务,数据源中的数据采用ETL(Extract-Transform-Load)工具以固定的周期加载到数据仓库中。
数据存储和管理:此层次主要涉及对数据的存储和管理,含数据仓库、数据集市、数据仓库检测、运行与维护工具和元数据管理等。
数据服务:为前端和应用提供数据服务,可直接从数据仓库中获取数据供前端应用使用,也可通过OLAP(OnLine Analytical Processing,联机分析处理)服务器为前端应用提供负责的数据服务。
数据应用:此层次直接面向用户,含数据查询工具、自由报表工具、数据分析工具、数据挖掘工具和各类应用系统。
1-2 传统数据仓库的问题
无法满足快速增长的海量数据存储需求,传统数据仓库基于关系型数据库,横向扩展性较差,纵向扩展有限。
无法处理不同类型的数据,传统数据仓库只能存储结构化数据,企业业务发展,数据源的格式越来越丰富。
传统数据仓库建立在关系型数据仓库之上,计算和处理能力不足,当数据量达到TB级后基本无法获得好的性能。
1-3 Hive
Hive是建立在Hadoop之上的数据仓库,由Facebook开发,在某种程度上可以看成是用户编程接口,本身并不存储和处理数据,依赖于HDFS存储数据,依赖MR处理数据。有类SQL语言HiveQL,不完全支持SQL标准,如,不支持更新操作、索引和事务,其子查询和连接操作也存在很多限制。
Hive把HQL语句转换成MR任务后,采用批处理的方式对海量数据进行处理。数据仓库存储的是静态数据,很适合采用MR进行批处理。Hive还提供了一系列对数据进行提取、转换、加载的工具,可以存储、查询和分析存储在HDFS上的数据。
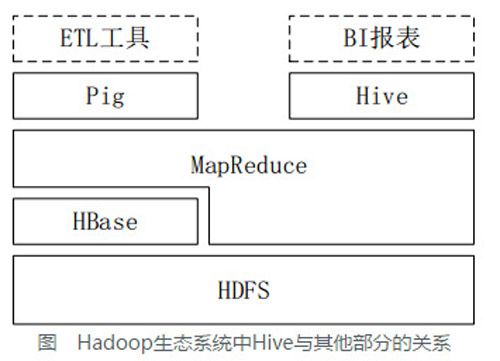
1-4 Hive与Hadoop生态系统中其他组件的关系
Hive依赖于HDFS存储数据,依赖MR处理数据;
Pig可作为Hive的替代工具,是一种数据流语言和运行环境,适合用于在Hadoop平台上查询半结构化数据集,用于与ETL过程的一部分,即将外部数据装载到Hadoop集群中,转换为用户需要的数据格式;
HBase是一个面向列的、分布式可伸缩的数据库,可提供数据的实时访问功能,而Hive只能处理静态数据,主要是BI报表数据,Hive的初衷是为减少复杂MR应用程序的编写工作,HBase则是为了实现对数据的实时访问。
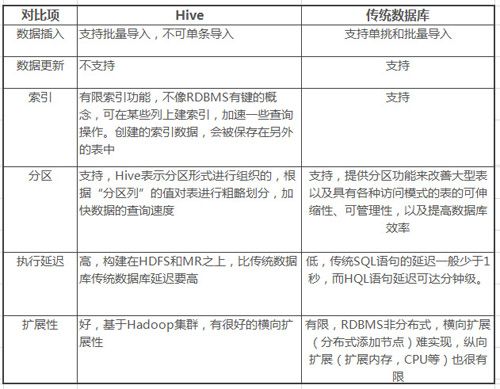
1-5 Hive与传统数据库的对比
1-6 Hive的部署和应用
1-6-1 Hive在企业大数据分析平台中的应用
当前企业中部署的大数据分析平台,除Hadoop的基本组件HDFS和MR外,还结合使用Hive、Pig、HBase、Mahout,从而满足不同业务场景需求。

上图是企业中一种常见的大数据分析平台部署框架 ,在这种部署架构中:
Hive和Pig用于报表中心,Hive用于分析报表,Pig用于报表中数据的转换工作。
HBase用于在线业务,HDFS不支持随机读写操作,而HBase正是为此开发,可较好地支持实时访问数据。
Mahout提供一些可扩展的机器学习领域的经典算法实现,用于创建商务智能(BI)应用程序。
二、Hive系统架构
下图显示Hive的主要组成模块、Hive如何与Hadoop交互工作、以及从外部访问Hive的几种典型方式。

Hive主要由以下三个模块组成:
- 用户接口模块,含CLI、HWI、JDBC、Thrift Server等,用来实现对Hive的访问。CLI是Hive自带的命令行界面;HWI是Hive的一个简单网页界面;JDBC、ODBC以及Thrift Server可向用户提供进行编程的接口,其中Thrift Server是基于Thrift软件框架开发的,提供Hive的RPC通信接口。
- 驱动模块(Driver),含编译器、优化器、执行器等,负责把HiveQL语句转换成一系列MR作业,所有命令和查询都会进入驱动模块,通过该模块的解析变异,对计算过程进行优化,然后按照指定的步骤执行。
- 元数据存储模块(Metastore),是一个独立的关系型数据库,通常与MySQL数据库连接后创建的一个MySQL实例,也可以是Hive自带的Derby数据库实例。此模块主要保存表模式和其他系统元数据,如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等。
喜欢图形界面的用户,可采用几种典型的外部访问工具:Karmasphere、Hue、Qubole等。
三、Hive工作原理
3-1 SQL语句转换成MapReduce作业的基本原理
3-1-1 用MapReduce实现连接操作
假设连接(join)的两个表分别是用户表User(uid,name)和订单表Order(uid,orderid),具体的SQL命令:
- SELECT name, orderid FROM User u JOIN Order o ON u.uid=o.uid;

上图描述了连接操作转换为MapReduce操作任务的具体执行过程。
首先,在Map阶段,
User表以uid为key,以name和表的标记位(这里User的标记位记为1)为value,进行Map操作,把表中记录转换生成一系列KV对的形式。比如,User表中记录(1,Lily)转换为键值对(1,<1,Lily>),其中第一个“1”是uid的值,第二个“1”是表User的标记位,用来标示这个键值对来自User表;
同样,Order表以uid为key,以orderid和表的标记位(这里表Order的标记位记为2)为值进行Map操作,把表中的记录转换生成一系列KV对的形式;
接着,在Shuffle阶段,把User表和Order表生成的KV对按键值进行Hash,然后传送给对应的Reduce机器执行。比如KV对(1,<1,Lily>)、(1,<2,101>)、(1,<2,102>)传送到同一台Reduce机器上。当Reduce机器接收到这些KV对时,还需按表的标记位对这些键值对进行排序,以优化连接操作;
最后,在Reduce阶段,对同一台Reduce机器上的键值对,根据“值”(value)中的表标记位,对来自表User和Order的数据进行笛卡尔积连接操作,以生成最终的结果。比如键值对(1,<1,Lily>)与键值对(1,<2,101>)、(1,<2,102>)的连接结果是(Lily,101)、(Lily,102)。
3-1-2 用MR实现分组操作
假设分数表Score(rank, level),具有rank(排名)和level(级别)两个属性,需要进行一个分组(Group By)操作,功能是把表Score的不同片段按照rank和level的组合值进行合并,并计算不同的组合值有几条记录。SQL语句命令如下:
- SELECT rank,level,count(*) as value FROM score GROUP BY rank,level;
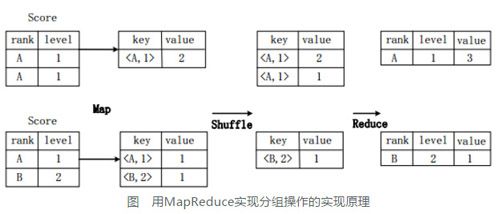
上图描述分组操作转化为MapReduce任务的具体执行过程。
首先,在Map阶段,对表Score进行Map操作,生成一系列KV对,其键为
接着在Shuffle阶段,对Score表生成的键值对,按照“键”的值进行Hash,然后根据Hash结果传送给对应的Reduce机器去执行。比如,键值对(
在Reduce阶段,把具有相同键的所有键值对的“值”进行累加,生成分组的最终结果。比如,在同一台Reduce机器上的键值对(
3-2 Hive中SQL查询转换成MR作业的过程
当Hive接收到一条HQL语句后,需要与Hadoop交互工作来完成该操作。HQL首先进入驱动模块,由驱动模块中的编译器解析编译,并由优化器对该操作进行优化计算,然后交给执行器去执行。执行器通常启动一个或多个MR任务,有时也不启动(如SELECT * FROM tb1,全表扫描,不存在投影和选择操作)

上图是Hive把HQL语句转化成MR任务进行执行的详细过程。
由驱动模块中的编译器–Antlr语言识别工具,对用户输入的SQL语句进行词法和语法解析,将HQL语句转换成抽象语法树(AST Tree)的形式;
遍历抽象语法树,转化成QueryBlock查询单元。因为AST结构复杂,不方便直接翻译成MR算法程序。其中QueryBlock是一条最基本的SQL语法组成单元,包括输入源、计算过程、和输入三个部分;
遍历QueryBlock,生成OperatorTree(操作树),OperatorTree由很多逻辑操作符组成,如TableScanOperator、SelectOperator、FilterOperator、JoinOperator、GroupByOperator和ReduceSinkOperator等。这些逻辑操作符可在Map、Reduce阶段完成某一特定操作;
Hive驱动模块中的逻辑优化器对OperatorTree进行优化,变换OperatorTree的形式,合并多余的操作符,减少MR任务数、以及Shuffle阶段的数据量;
遍历优化后的OperatorTree,根据OperatorTree中的逻辑操作符生成需要执行的MR任务;
启动Hive驱动模块中的物理优化器,对生成的MR任务进行优化,生成最终的MR任务执行计划;
最后,有Hive驱动模块中的执行器,对最终的MR任务执行输出。
Hive驱动模块中的执行器执行最终的MR任务时,Hive本身不会生成MR算法程序。它通过一个表示“Job执行计划”的XML文件,来驱动内置的、原生的Mapper和Reducer模块。Hive通过和JobTracker通信来初始化MR任务,而不需直接部署在JobTracker所在管理节点上执行。通常在大型集群中,会有专门的网关机来部署Hive工具,这些网关机的作用主要是远程操作和管理节点上的JobTracker通信来执行任务。Hive要处理的数据文件常存储在HDFS上,HDFS由名称节点(NameNode)来管理。
- JobTracker/TaskTracker
- NameNode/DataNode
四、Hive HA基本原理
在实际应用中,Hive也暴露出不稳定的问题,在极少数情况下,会出现端口不响应或进程丢失问题。Hive HA(High Availablity)可以解决这类问题。

在Hive HA中,在Hadoop集群上构建的数据仓库是由多个Hive实例进行管理的,这些Hive实例被纳入到一个资源池中,由HAProxy提供统一的对外接口。客户端的查询请求,首先访问HAProxy,由HAProxy对访问请求进行转发。HAProxy收到请求后,会轮询资源池中可用的Hive实例,执行逻辑可用性测试。
如果某个Hive实例逻辑可用,就会把客户端的访问请求转发到Hive实例上;
如果某个实例不可用,就把它放入黑名单,并继续从资源池中取出下一个Hive实例进行逻辑可用性测试。
对于黑名单中的Hive,Hive HA会每隔一段时间进行统一处理,首先尝试重启该Hive实例,如果重启成功,就再次把它放入资源池中。
由于HAProxy提供统一的对外访问接口,因此,对于程序开发人员来说,可把它看成一台超强“Hive”。
五、Impala
5-1 Impala简介
Impala由Cloudera公司开发,提供SQL语义,可查询存储在Hadoop和HBase上的PB级海量数据。Hive也提供SQL语义,但底层执行任务仍借助于MR,实时性不好,查询延迟较高。
Impala作为新一代开源大数据分析引擎,最初参照Dremel(由Google开发的交互式数据分析系统),支持实时计算,提供与Hive类似的功能,在性能上高出Hive3~30倍。Impala可能会超过Hive的使用率能成为Hadoop上最流行的实时计算平台。Impala采用与商用并行关系数据库类似的分布式查询引擎,可直接从HDFS、HBase中用SQL语句查询数据,不需把SQL语句转换成MR任务,降低延迟,可很好地满足实时查询需求。
Impala不能替换Hive,可提供一个统一的平台用于实时查询。Impala的运行依赖于Hive的元数据(Metastore)。Impala和Hive采用相同的SQL语法、ODBC驱动程序和用户接口,可统一部署Hive和Impala等分析工具,同时支持批处理和实时查询。
5-2 Impala系统架构

上图是Impala系统结构图,虚线模块数据Impala组件。Impala和Hive、HDFS、HBase统一部署在Hadoop平台上。Impala由Impalad、State Store和CLI三部分组成。
Implalad:是Impala的一个进程,负责协调客户端提供的查询执行,给其他Impalad分配任务,以及收集其他Impalad的执行结果进行汇总。Impalad也会执行其他Impalad给其分配的任务,主要是对本地HDFS和HBase里的部分数据进行操作。Impalad进程主要含Query Planner、Query Coordinator和Query Exec Engine三个模块,与HDFS的数据节点(HDFS DataNode)运行在同一节点上,且完全分布运行在MPP(大规模并行处理系统)架构上。
State Store:收集分布在集群上各个Impalad进程的资源信息,用于查询的调度,它会创建一个statestored进程,来跟踪集群中的Impalad的健康状态及位置信息。statestored进程通过创建多个线程来处理Impalad的注册订阅以及与多个Impalad保持心跳连接,此外,各Impalad都会缓存一份State Store中的信息。当State Store离线后,Impalad一旦发现State Store处于离线状态时,就会进入恢复模式,并进行返回注册。当State Store重新加入集群后,自动恢复正常,更新缓存数据。
CLI:CLI给用户提供了执行查询的命令行工具。Impala还提供了Hue、JDBC及ODBC使用接口。
5-3 Impala查询执行过程
注册和订阅。当用户提交查询前,Impala先创建一个Impalad进程来负责协调客户端提交的查询,该进程会向State Store提交注册订阅信息,State Store会创建一个statestored进程,statestored进程通过创建多个线程来处理Impalad的注册订阅信息。
提交查询。通过CLI提交一个查询到Impalad进程,Impalad的Query Planner对SQL语句解析,生成解析树;Planner将解析树变成若干PlanFragment,发送到Query Coordinator。其中PlanFragment由PlanNode组成,能被分发到单独的节点上执行,每个PlanNode表示一个关系操作和对其执行优化需要的信息。
获取元数据与数据地址。Query Coordinator从MySQL元数据库中获取元数据(即查询需要用到哪些数据),从HDFS的名称节点中获取数据地址(即数据被保存到哪个数据节点上),从而得到存储这个查询相关数据的所有数据节点。
分发查询任务。Query Coordinator初始化相应的Impalad上的任务,即把查询任务分配给所有存储这个查询相关数据的数据节点。
汇聚结果。Query Executor通过流式交换中间输出,并由Query Coordinator汇聚来自各个Impalad的结果。
返回结果。Query Coordinator把汇总后的结果返回给CLI客户端。
5-4 Impala与Hive
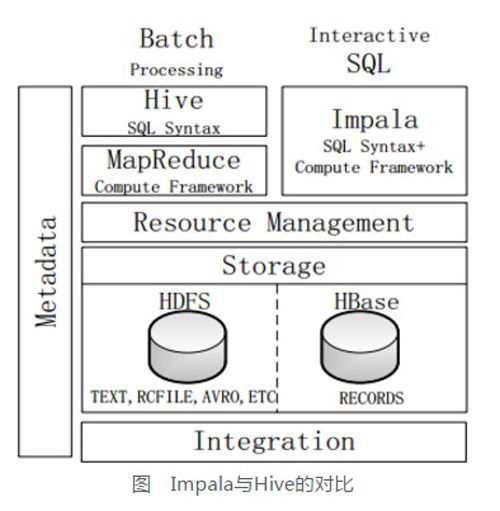
不同点:
Hive适合长时间批处理查询分析;而Impala适合进行交互式SQL查询。
Hive依赖于MR计算框架,执行计划组合成管道型MR任务模型进行执行;而Impala则把执行计划表现为一棵完整的执行计划树,可更自然地分发执行计划到各个Impalad执行查询。
Hive在执行过程中,若内存放不下所有数据,则会使用外存,以保证查询能够顺利执行完成;而Impala在遇到内存放不下数据时,不会利用外存,所以Impala处理查询时会受到一定的限制。
相同点:
使用相同的存储数据池,都支持把数据存储在HDFS和HBase中,其中HDFS支持存储TEXT、RCFILE、PARQUET、AVRO、ETC等格式的数据,HBase存储表中记录。
使用相同的元数据。
对SQL的解析处理比较类似,都是通过词法分析生成执行计划。