SDN学习之路——第二天
在上面短暂了解了SDN和OpenFlow的一些介绍性的知识之后,因为可能要在具体的工作中使用,而因为要延续学长们的工作,所以使用了KVM+OVS+Ryu的组合,按照我之前的习惯肯定是先安装这些软件然后直接做一些实验学习如何使用即可,但因为在学习OVS指令的过程中始终对于它的各种架构不是十分了解,而时间又还算比较充裕(应该是比较充裕吧?),所以打算详细的学习一下OVS。
ovs的基本架构
OVS顾名思义就是开放的虚拟交换机,它相对于物理交换机来说,可以有更多的端口,支持多种协议。而OVS有很多模块,只是单纯的知道这些模块的名字好像没什么帮助,所以结合OVS的基本架构了解一下这些模块之间的关系:
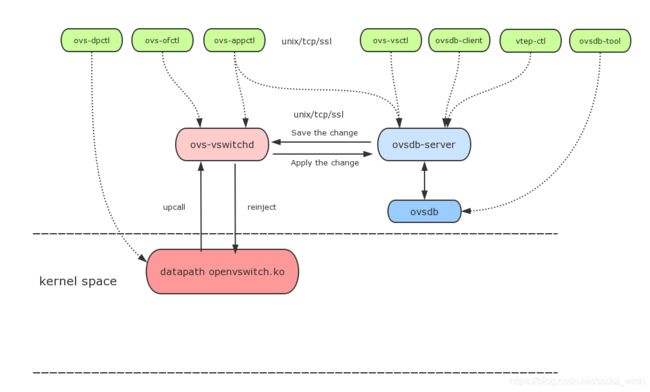
ovs-vswithchd:主要模块
ovsdb-server: ovs的数据库服务程序,保存ovs交换机的配置信息
ovs-dpctl: 配置内核模块
ovs-vsctl:配置交换机,创建br、port等
ovs-appctl: 发送命令消息,运行ovs的deamon程序
代码解析
在了解了这些架构之后,我对于ovs具体是如何工作的还是一知半解,尤其对于内核里的datapath openvswitch.ko感到十分困惑。所以就决定希望可以找到对于代码的解析。幸运的是,我确实找到了一个大佬的博客,也随着他的主页的解析过程对于ovs的具体工作内容学习到了更多,大佬的主页我会贴在后面,虽然之后又有了更新,但还是可以通过这些博客了解到ovs的工作流程。
数据结构

处理过程
因为ovs-vsctl add-port br eth,把eth与br绑定,所以从eth接受的数据会直接发送给br,由ovs-vport-received函数来处理,而在这个函数里又交给了ovs_dp_process_received_packet函数来处理,在这个函数里数据报skb会首先被交给ovs_flow_extract提取出一个key值,根据key值和skb包对比流表中的流表项(ovs-flow-lookup),如果没有匹配项,则通过netLink发送到用户空间,这部分内容可能要到明天才能继续学习了;如果找到了匹配项,则执行匹配项中的action。
- 这里的key值的提取函数是根据skb更新ovs-flow-key结构体的值,并返回key值。
- 在其中关于parts中指向sw-flow的代码我并没有在博客的贴出来的代码中看到,可能要自己开一下代码看一下吧
- 不过其中有个很精妙的设计点可能如果不是这位大佬指出来,我之后自己看代码也不会发现:就是如何数据的大小比较小,就不创建一个parts来存储数据,而是直接在buckets这里存储
数据的接收
flow的查找过程
补充说明:
1. 如果skb没有hash值,则mask_index = 0,在ma中从头遍历 32位的hash值被分成4段,每段8字节,作为cache的索引
2. 如果index的值无效,且找不到mask,则在ma中从头遍历
代码解析
ovs_flow_tbl_lookup_stats
struct sw_flow ovs_flow_tbl_lookup_stats(struct flow_table *tbl,
const struct sw_flow_key *key,
u32 skb_hash,
u32 *n_mask_hit)
{
struct mask_array *ma = rcu_dereference(tbl->mask_array);
struct table_instance *ti = rcu_dereference(tbl->ti);
struct mask_cache_entry *entries, *ce;
struct sw_flow *flow;
u32 hash;
int seg;
*n_mask_hit = 0;
/* if skb_hash!=0 */
if (unlikely(!skb_hash)) { //如果报文没有hash值,则mask_index为0,全遍历所有的mask
u32 mask_index = 0;
return flow_lookup(tbl, ti, ma, key, n_mask_hit, &mask_index);
}
/* Pre and post recirulation flows usually have the same skb_hash
* value. To avoid hash collisions, rehash the 'skb_hash' with
* 'recirc_id'. */
if (key->recirc_id)
skb_hash = jhash_1word(skb_hash, key->recirc_id);
ce = NULL;
hash = skb_hash;
entries = this_cpu_ptr(tbl->mask_cache);
/* Find the cache entry 'ce' to operate on. */
for (seg = 0; seg < MC_HASH_SEGS; seg++) { //32位的hash值被分成4段,每段8字节,作为cache的索引
int index = hash & (MC_HASH_ENTRIES - 1); //根据hash计算cache的index
struct mask_cache_entry *e;
e = &entries[index]; //entry最大为256项
if (e->skb_hash == skb_hash) { //如果在cache entry找到报文hash相同项,则根据该entry指定的mask查询tb
flow = flow_lookup(tbl, ti, ma, key, n_mask_hit,
&e->mask_index);
if (!flow)
e->skb_hash = 0;
return flow;
}
if (!ce || e->skb_hash < ce->skb_hash) //why little?
ce = e; /* A better replacement cache candidate. */
hash >>= MC_HASH_SHIFT; //下一段hash
}
/* Cache miss, do full lookup. */
flow = flow_lookup(tbl, ti, ma, key, n_mask_hit, &ce->mask_index);
if (flow)
ce->skb_hash = skb_hash;
return flow;
}
flow_lookup
static struct sw_flow *flow_lookup(struct flow_table *tbl,
struct table_instance *ti,
const struct mask_array *ma,
const struct sw_flow_key *key,
u32 *n_mask_hit,
u32 *index)
{
struct sw_flow_mask *mask;
struct sw_flow *flow;
int i;
//如果index的值小于mask的最大entry数量,说明index是有效值,基于该值获取sw_flow_mask值
if (*index < ma->max) {
mask = rcu_dereference_ovsl(ma->masks[*index]); //根据index获取mask
if (mask) {
flow = masked_flow_lookup(ti, key, mask, n_mask_hit);
if (flow)
return flow;
}
}
for (i = 0; i < ma->max; i++) { //如果没有找到,则遍历整个ma
if (i == *index)
continue;
mask = rcu_dereference_ovsl(ma->masks[i]);
if (!mask)
continue;
flow = masked_flow_lookup(ti, key, mask, n_mask_hit);
if (flow) { /* Found */
*index = i; //更新index
return flow;
}
}
return NULL;
}
masked_flow_lookup
static struct sw_flow *masked_flow_lookup(struct table_instance *ti,
const struct sw_flow_key *unmasked,
const struct sw_flow_mask *mask,
u32 *n_mask_hit)
{
struct sw_flow *flow;
struct hlist_head *head;
u32 hash;
struct sw_flow_key masked_key;
ovs_flow_mask_key(&masked_key, unmasked, false, mask); //根据mask,计算masked后的key,用以支持通配符
hash = flow_hash(&masked_key, &mask->range); //根据masked key和mask.range 计算hash值
head = find_bucket(ti, hash); //根据hash值,找到链表头(桶)
(*n_mask_hit)++;
hlist_for_each_entry_rcu(flow, head, flow_table.node[ti->node_ver]) { //遍历桶中的parts
if (flow->mask == mask && flow->flow_table.hash == hash &&
flow_cmp_masked_key(flow, &masked_key, &mask->range))
return flow;
}
return NULL;
}
处理数据
如果可以在流表中找到匹配的流表项,则执行action;否则,则通过netlink传递给userspace来处理:
udpif_start_threads创建udpif_upcall_handler这个线程来处理所有的upcall
udpif_upcall_handler
static void *
udpif_upcall_handler(void *arg)
{
struct handler *handler = arg;
struct udpif *udpif = handler->udpif;
while (!latch_is_set(&handler->udpif->exit_latch)) {
if (recv_upcalls(handler)) { //判断是否阻塞
poll_immediate_wake();
} else {
dpif_recv_wait(udpif->dpif, handler->handler_id);
latch_wait(&udpif->exit_latch);
}
poll_block();
}
return NULL;
}
recv_upcalls
static size_t
recv_upcalls(struct handler *handler)
{
struct udpif *udpif = handler->udpif;
uint64_t recv_stubs[UPCALL_MAX_BATCH][512 / 8];
struct ofpbuf recv_bufs[UPCALL_MAX_BATCH];
struct dpif_upcall dupcalls[UPCALL_MAX_BATCH]; //创建dpif_upcalls消息
struct upcall upcalls[UPCALL_MAX_BATCH];
struct flow flows[UPCALL_MAX_BATCH];
size_t n_upcalls, i;
n_upcalls = 0;
while (n_upcalls < UPCALL_MAX_BATCH) {
struct ofpbuf *recv_buf = &recv_bufs[n_upcalls];
struct dpif_upcall *dupcall = &dupcalls[n_upcalls];
struct upcall *upcall = &upcalls[n_upcalls];
struct flow *flow = &flows[n_upcalls];
unsigned int mru;
int error;
ofpbuf_use_stub(recv_buf, recv_stubs[n_upcalls],
sizeof recv_stubs[n_upcalls]);
if (dpif_recv(udpif->dpif, handler->handler_id, dupcall, recv_buf)) { //从sock中获取消息并转化为upcall格式并存入dupcall中
ofpbuf_uninit(recv_buf);
break;
}
upcall->fitness = odp_flow_key_to_flow(dupcall->key, dupcall->key_len,
flow);//把key转化为flow,fitness表示key与我们期待的flow的fitness
if (upcall->fitness == ODP_FIT_ERROR) {
goto free_dupcall;
}
if (dupcall->mru) {
mru = nl_attr_get_u16(dupcall->mru);
} else {
mru = 0;
}
error = upcall_receive(upcall, udpif->backer, &dupcall->packet,
dupcall->type, dupcall->userdata, flow, mru,
&dupcall->ufid, PMD_ID_NULL);
if (error) {
if (error == ENODEV) {
/* Received packet on datapath port for which we couldn't
* associate an ofproto. This can happen if a port is removed
* while traffic is being received. Print a rate-limited
* message in case it happens frequently. */
dpif_flow_put(udpif->dpif, DPIF_FP_CREATE, dupcall->key,
dupcall->key_len, NULL, 0, NULL, 0,
&dupcall->ufid, PMD_ID_NULL, NULL);
VLOG_INFO_RL(&rl, "received packet on unassociated datapath "
"port %"PRIu32, flow->in_port.odp_port);
}
goto free_dupcall;
}
upcall->key = dupcall->key;
upcall->key_len = dupcall->key_len;
upcall->ufid = &dupcall->ufid;
upcall->out_tun_key = dupcall->out_tun_key;
upcall->actions = dupcall->actions;
pkt_metadata_from_flow(&dupcall->packet.md, flow);
flow_extract(&dupcall->packet, flow);
error = process_upcall(udpif, upcall,
&upcall->odp_actions, &upcall->wc);
if (error) {
goto cleanup;
}
n_upcalls++;
continue;
cleanup:
upcall_uninit(upcall);
free_dupcall:
dp_packet_uninit(&dupcall->packet);
ofpbuf_uninit(recv_buf);
}
if (n_upcalls) {
handle_upcalls(handler->udpif, upcalls, n_upcalls); //调用handle_upcalls用于向datapath下发flow,handle_upcalls最终调用的是dpif_operate来下发flow,后者调用的是dpif_class->operate,该接口针对不同的dpif实现,可以是dpif_netdev_operate或者dpif_netlink_operate
for (i = 0; i < n_upcalls; i++) {
dp_packet_uninit(&dupcalls[i].packet);
ofpbuf_uninit(&recv_bufs[i]);
upcall_uninit(&upcalls[i]);
}
}
return n_upcalls;
}
dpif_recv
int
dpif_recv(struct dpif *dpif, uint32_t handler_id, struct dpif_upcall *upcall,
struct ofpbuf *buf)
{
int error = EAGAIN;
if (dpif->dpif_class->recv) {
error = dpif->dpif_class->recv(dpif, handler_id, upcall, buf); //实际调用dpif_netlink_recv函数
if (!error) {
dpif_print_packet(dpif, upcall);
} else if (error != EAGAIN) {
log_operation(dpif, "recv", error);
}
}
return error;
}
dpif_netlink_recv
static int
dpif_netlink_recv(struct dpif *dpif_, uint32_t handler_id,
struct dpif_upcall *upcall, struct ofpbuf *buf)
{
struct dpif_netlink *dpif = dpif_netlink_cast(dpif_);
int error;
fat_rwlock_rdlock(&dpif->upcall_lock);
#ifdef _WIN32
error = dpif_netlink_recv_windows(dpif, handler_id, upcall, buf);
#else
error = dpif_netlink_recv__(dpif, handler_id, upcall, buf);
#endif
fat_rwlock_unlock(&dpif->upcall_lock);
return error;
}
static int
dpif_netlink_recv__(struct dpif_netlink *dpif, uint32_t handler_id,
struct dpif_upcall *upcall, struct ofpbuf *buf)
OVS_REQ_RDLOCK(dpif->upcall_lock)
{
struct dpif_handler *handler;
int read_tries = 0;
if (!dpif->handlers || handler_id >= dpif->n_handlers) {
return EAGAIN;
}
handler = &dpif->handlers[handler_id];
if (handler->event_offset >= handler->n_events) {
int retval;
handler->event_offset = handler->n_events = 0;
do {
retval = epoll_wait(handler->epoll_fd, handler->epoll_events,
dpif->uc_array_size, 0);
} while (retval < 0 && errno == EINTR);
if (retval < 0) {
static struct vlog_rate_limit rl = VLOG_RATE_LIMIT_INIT(1, 1);
VLOG_WARN_RL(&rl, "epoll_wait failed (%s)", ovs_strerror(errno));
} else if (retval > 0) {
handler->n_events = retval;
}
}
while (handler->event_offset < handler->n_events) {
int idx = handler->epoll_events[handler->event_offset].data.u32;
struct dpif_channel *ch = &dpif->channels[idx]; //通道
handler->event_offset++;
for (;;) {
int dp_ifindex;
int error;
if (++read_tries > 50) {
return EAGAIN;
}
error = nl_sock_recv(ch->sock, buf, NULL, false); //读取sock中的消息到buf
if (error == ENOBUFS) {
/* ENOBUFS typically means that we've received so many
* packets that the buffer overflowed. Try again
* immediately because there's almost certainly a packet
* waiting for us. */
report_loss(dpif, ch, idx, handler_id);
continue;
}
ch->last_poll = time_msec();
if (error) {
if (error == EAGAIN) {
break;
}
return error;
}
error = parse_odp_packet(dpif, buf, upcall, &dp_ifindex); //把从sock中获取的buf转化为dpif_upcall
if (!error && dp_ifindex == dpif->dp_ifindex) {
return 0;
} else if (error) {
return error;
}
}
}
return EAGAIN;
}
process_upcall
//根据upcall的类型处理upcall
static int
process_upcall(struct udpif *udpif, struct upcall *upcall,
struct ofpbuf *odp_actions, struct flow_wildcards *wc)
{
const struct dp_packet *packet = upcall->packet;
const struct flow *flow = upcall->flow;
size_t actions_len = 0;
switch (upcall->type) {
case MISS_UPCALL:
--case SLOW_PATH_UPCALL:--
upcall_xlate(udpif, upcall, odp_actions, wc);
return 0;
case SFLOW_UPCALL:
if (upcall->sflow) {
struct dpif_sflow_actions sflow_actions;
memset(&sflow_actions, 0, sizeof sflow_actions);
actions_len = dpif_read_actions(udpif, upcall, flow,
upcall->type, &sflow_actions);
dpif_sflow_received(upcall->sflow, packet, flow,
flow->in_port.odp_port, &upcall->cookie,
actions_len > 0 ? &sflow_actions : NULL);
}
break;
case IPFIX_UPCALL:
case FLOW_SAMPLE_UPCALL:
if (upcall->ipfix) {
struct flow_tnl output_tunnel_key;
struct dpif_ipfix_actions ipfix_actions;
memset(&ipfix_actions, 0, sizeof ipfix_actions);
if (upcall->out_tun_key) {
odp_tun_key_from_attr(upcall->out_tun_key, &output_tunnel_key);
}
actions_len = dpif_read_actions(udpif, upcall, flow,
upcall->type, &ipfix_actions);
if (upcall->type == IPFIX_UPCALL) {
dpif_ipfix_bridge_sample(upcall->ipfix, packet, flow,
flow->in_port.odp_port,
upcall->cookie.ipfix.output_odp_port,
upcall->out_tun_key ?
&output_tunnel_key : NULL,
actions_len > 0 ?
&ipfix_actions: NULL);
} else {
/* The flow reflects exactly the contents of the packet.
* Sample the packet using it. */
dpif_ipfix_flow_sample(upcall->ipfix, packet, flow,
&upcall->cookie, flow->in_port.odp_port,
upcall->out_tun_key ?
&output_tunnel_key : NULL,
actions_len > 0 ? &ipfix_actions: NULL);
}
}
break;
case CONTROLLER_UPCALL:
{
struct user_action_cookie *cookie = &upcall->cookie;
if (cookie->controller.dont_send) {
return 0;
}
uint32_t recirc_id = cookie->controller.recirc_id;
if (!recirc_id) {
break;
}
const struct recirc_id_node *recirc_node
= recirc_id_node_find(recirc_id);
if (!recirc_node) {
break;
}
const struct frozen_state *state = &recirc_node->state;
struct ofproto_async_msg *am = xmalloc(sizeof *am);
*am = (struct ofproto_async_msg) {
.controller_id = cookie->controller.controller_id,
.oam = OAM_PACKET_IN,
.pin = {
.up = {
.base = {
.packet = xmemdup(dp_packet_data(packet),
dp_packet_size(packet)),
.packet_len = dp_packet_size(packet),
.reason = cookie->controller.reason,
.table_id = state->table_id,
.cookie = get_32aligned_be64(
&cookie->controller.rule_cookie),
.userdata = (recirc_node->state.userdata_len
? xmemdup(recirc_node->state.userdata,
recirc_node->state.userdata_len)
: NULL),
.userdata_len = recirc_node->state.userdata_len,
},
},
.max_len = cookie->controller.max_len,
},
};
if (cookie->controller.continuation) {
am->pin.up.stack = (state->stack_size
? xmemdup(state->stack, state->stack_size)
: NULL),
am->pin.up.stack_size = state->stack_size,
am->pin.up.mirrors = state->mirrors,
am->pin.up.conntracked = state->conntracked,
am->pin.up.actions = (state->ofpacts_len
? xmemdup(state->ofpacts,
state->ofpacts_len) : NULL),
am->pin.up.actions_len = state->ofpacts_len,
am->pin.up.action_set = (state->action_set_len
? xmemdup(state->action_set,
state->action_set_len)
: NULL),
am->pin.up.action_set_len = state->action_set_len,
am->pin.up.bridge = upcall->ofproto->uuid;
}
/* We don't want to use the upcall 'flow', since it may be
* more specific than the point at which the "controller"
* action was specified. */
struct flow frozen_flow;
frozen_flow = *flow;
if (!state->conntracked) {
flow_clear_conntrack(&frozen_flow);
}
frozen_metadata_to_flow(&state->metadata, &frozen_flow);
flow_get_metadata(&frozen_flow, &am->pin.up.base.flow_metadata);
ofproto_dpif_send_async_msg(upcall->ofproto, am);
}
break;
case BAD_UPCALL:
break;
}
return EAGAIN;
}
upcall_xlate
这里重点关注一下miss和slow path类型,xlate_actions函数比较复杂,其中最重要的调用是通过rule_dpif_lookup_from_table查找到匹配的流表规则,进而生成actions
rule_dpif_lookup_from_table又会通过流表的级联一个个顺序查找,每单个流表都会调用rule_dpif_lookup_in_table
xlate_actions最终调用do_xlate_actions针对每种ACTION_ATTR对flow执行不同操作[^3]
参考1
参考2 ovs-vsctl add-port br0 eth1 实际做了什么?
参考3 ovsde upcall和ofproto