学习数据挖掘的过程中,想试着实现一个文本分类的应用,对新闻进行分类,于是自己抓取数据,用不同分类模型试试效果如何。
目的很简单,就是根据新闻标题对新闻分类
大致思路:
1.抓取数据
抓取某个新闻网站的新闻标题和新闻分类写入本地,存放为CSV文件
2.数据清洗
因为要对中文文本进行分类,首先去重并删除每条标题的数字和英文字母
使用jieba分词库把每条标题分为数个中文词语,切词后构造一个词条矩阵,行为新闻类别,列为切词后的词语,得到清洗后的样本
3.数据建模
使用多项式贝叶斯分类器模型,然后用其他分类模型对比结果。
4.结果分析
查看分类准确率,分析影响模型准确率的因素,优化方法。
以下是具体过程。
1.抓取数据
爬虫数据来源:腾讯新闻
用chrome开发者工具找到腾讯新闻各分类下的网址,找到后发现可以直接得到json文件,很容易提取出标题,省去了解析html文本的麻烦。具体代码如下:


1 #!/usr/local/python3/bin/python3 2 #coding=utf-8 3 4 ''' 5 抓取腾讯新闻各个分类新闻保存在本地,用作分类训练 6 爬虫线路: requests 7 Python版本: 3.6 8 OS: ubuntu 16.04 9 ''' 10 11 import sys, os, threading, multiprocessing 12 import requests, json, pymongo 13 import time, re, random 14 #使用本地文件中保存的用户代理和ip代理 15 import useragent_pool, ip_pool 16 17 OUTPUT_FILE = 'tencentnews.csv' 18 19 #获取新闻各个分类的地址 20 def get_news_url(category, page): 21 return news_dict[category][:-1] + str(page) 22 23 #请求网页信息,返回json数据 24 def get_html_json(url): 25 header = { 26 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0", 27 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", 28 "Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3", 29 "Accept-Encoding": "gzip, deflate", 30 "Referer": "https://news.qq.com/", 31 "Connection": "keep-alive", 32 "Upgrade-Insecure-Requests": "1" 33 } 34 #随机选取用户代理和ip代理 35 header['User-Agent'] = random.choice(useragent_pool.user_agents) 36 ip = random.choice(ip_pool.http_ip_pool) 37 proxy = {'http': ip} 38 r = requests.get(url = url, proxies = proxy, headers = header, timeout=5) 39 r.raise_for_status() 40 r.encoding = 'utf-8' 41 return r.json() 42 43 def get_news(start_page, end_page): 44 global count 45 for category, url in news_dict.items(): 46 for page in range(start_page, end_page): 47 try: 48 json = get_html_json(get_news_url(category, page)) 49 data = json['result']['data'] if 'result' in json else json['data'] 50 if type(data) == dict: 51 data = data['docs'] 52 with open(OUTPUT_FILE, 'a') as f: 53 for i in data: 54 try: 55 f.write(category + '|' + i['title'].replace('|', '') + '\n') 56 except: 57 pass 58 except: 59 print('%s page%s failed.' %(category, page)) 60 61 #多进程执行 62 def multi_process_execute(start=1, end=41): 63 offset = (end - start) // 4 64 single_num = offset // 5 65 p = multiprocessing.Pool() 66 for i in range(4): 67 p.apply_async(multi_threading_execute, args=(start, offset*i, single_num,)) 68 p.close() 69 p.join() 70 print('All processes done.') 71 72 #多线程执行 73 def multi_threading_execute(start, offset, single_num): 74 threads = [threading.Thread(target=get_news, args=(start+offset+x*single_num, start+offset+(x+1)*single_num)) for x in range(5)] 75 for i in range(5): 76 threads[i].start() 77 for i in range(5): 78 threads[i].join() 79 80 def main(): 81 with open(OUTPUT_FILE, 'w') as f: 82 f.write('#grab time: %s\n' %time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) 83 f.write('category|title\n') 84 #get_news(1, 15) 85 multi_process_execute(1, 201) 86 87 news_dict = { 88 '时尚': 'https://pacaio.match.qq.com/irs/rcd?cid=146&token=49cbb2154853ef1a74ff4e53723372ce&ext=fashion&page=1', 89 '财经': 'https://pacaio.match.qq.com/irs/rcd?cid=146&token=49cbb2154853ef1a74ff4e53723372ce&ext=finance&page=1', 90 '娱乐': 'https://pacaio.match.qq.com/irs/rcd?cid=146&token=49cbb2154853ef1a74ff4e53723372ce&ext=ent&page=1', 91 '科技': 'https://pacaio.match.qq.com/irs/rcd?cid=146&token=49cbb2154853ef1a74ff4e53723372ce&ext=tech&page=1', 92 '汽车': 'https://pacaio.match.qq.com/irs/rcd?cid=146&token=49cbb2154853ef1a74ff4e53723372ce&ext=auto&page=1', 93 '游戏': 'https://pacaio.match.qq.com/irs/rcd?cid=146&token=49cbb2154853ef1a74ff4e53723372ce&ext=games&page=1' 94 } 95 96 if __name__ == '__main__': 97 print("**********execute time: " + time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) + "**********") 98 time_start = time.time() 99 main() 100 time_end = time.time() 101 print("time consuming: %.2fs." %(time_end-time_start)) 102 print("tencent news crawl successful: %s" % OUTPUT_FILE) 103 print("***************end-line***************")
运行程序:
root@c:test$ python tencentnews_spider.py
**********execute time: 2019-03-15 11:38:47**********
All processes done.
time consuming: 14.77s.
tencent news crawl successful: tencentnews.csv
***************end-line***************
使用了多进程与多线程,可以看到,只用了15s,非常暴力。
查看一下得到的文件:
root@c:test$ sed -n '1,5=;1,5p;$=;$p' tencentnews.csv | sed 'N;s/\n/\t/'
1 #grab time: 2019-03-15 11:38:47
2 category|title
3 时尚|美妆博主颜九:王俊凯弟弟挑的口红颜色,日常又不落俗!
4 时尚|贵到买不起的香奈儿包包,制作过程曝光,看完终于明白为啥买不起了
5 时尚|小巧柔美的小女人穿搭,身材高挑的妹子学会穿搭真是时尚有品位
6381 游戏|DNF:附魔师还能够失败?15属性强化心脏卡片就这样没了!
数据抓取完成。
2.数据清洗
import pandas as pd
tencentnews = pd.read_csv('tencentnews.csv', sep='|', comment='#')
#去重
news = tencentnews.drop_duplicates().astype(str)
#重置目录
news.index = range(len(news))
#去掉数字和字母
news['title'] = news['title'].str.replace('[0-9a-zA-Z]', '')
#查看各分类新闻数量
news['category'].value_counts()
汽车 1025 时尚 1015 游戏 1011 科技 1006 财经 998 娱乐 973 Name: category, dtype: int64
使用jieba把标题分割为词语,jieba分词库的使用方法可以参考:https://github.com/fxsjy/jieba
import jieba #加载自定义词库 jieba.load_userdict('all_words.txt') #导入停止词 with open('mystopwords.txt', encoding='utf-8') as words: stop_words = [ i.strip() for i in words.readlines() ] #切词时删除停止词 def cut_word(sentence): words = [ i for i in jieba.lcut(sentence) if i not in stop_words ] return ' '.join(words) #保存切词结果 words = news['title'].apply(cut_word)
接下来构造词条矩阵,列名是切词后的词语,每一行代表一条新闻,某个词语在某个新闻中的权值作为矩阵的值。
构造词条矩阵有两种方法:1.直接把词语的出现次数作为权值,2.使用tf-idf值作为权值。
使用tf-idf的目的是削弱在整体文本出现次数较多的词语的权值,具体说明可以参考:https://blog.csdn.net/eastmount/article/details/50323063
下面分别用两种方法,对比结果。
from sklearn.feature_extraction.text import CountVectorizer #统计各个词的出现次数,过滤出现频率过低的词,min_df根据样本量适当调整。 counts = CountVectorizer(min_df = 0.0005) #词条矩阵 counts_mat = counts.fit_transform(words).toarray() #矩阵列名 columns = counts.get_feature_names() #得到数据清洗完成后的样本 X = pd.DataFrame(counts_mat, columns=columns) y = news['category'] #使用TF-IDF构造词条矩阵 from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.2, min_df=0.0005) tfidf_mat = vectorizer.fit_transform(words).toarray() columns = vectorizer.get_feature_names() X_1 = pd.DataFrame(tfidf_mat, columns=columns) y_1 = news['category']
得到两种样本,X的值是词语的出现次数,X_1的值是tf-idf值。
3.数据建模
以3:1的比例划分训练集和测试集,分类器建模,拟合训练集。
查看分类结果的准确率和混淆矩阵。
from sklearn import model_selection, metrics, naive_bayes #把数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.25) #构造多项式贝叶斯分类器 mnb = naive_bayes.MultinomialNB() #拟合训练集 mnb.fit(X_train, y_train) #预测测试集 mnb_pred = mnb.predict(X_test) #混淆矩阵 cm = pd.crosstab(mnb_pred, y_test) #查看准确率 metrics.accuracy_score(y_test, mnb_pred)
0.8221632382216324
然后用tf-idf处理的样本训练:
X_train, X_test, y_train, y_test = model_selection.train_test_split(X_1, y_1, test_size=0.25, random_state=11) mnb = naive_bayes.MultinomialNB() mnb.fit(X_train, y_train) mnb_pred = mnb.predict(X_test) cm = pd.crosstab(mnb_pred, y_test) metrics.accuracy_score(y_test, mnb_pred)
0.8301260783012607
从结果来看,使用tf-idf值处理的样本准确率比没做处理要高0.8%左右,提升的幅度一般,可能的原因是新闻标题都较短,单个词语在整体文本中出现频率普遍较低,导致效果不明显。
使用多项式贝叶斯分类器对新闻分类的准确率83%,效果还算不错。
接下来用其他分类模型
随机森林:
from sklearn import ensemble X_train, X_test, y_train, y_test = model_selection.train_test_split(X_1, y_1, test_size=0.25, random_state=11) RF = ensemble.RandomForestClassifier(n_estimators=100,) RF.fit(X_train, y_train) RF_pred = RF.predict(X_test) metrics.accuracy_score(y_test, RF_pred)
0.7723954877239548
准确率为77%,比多项式贝叶斯分类器低了不少,原因可能是自变量过多,很多自变量对因变量的影响相差不大,导致分支中判断错误概率较高。
梯度下降法:
from sklearn.linear_model import SGDClassifier svm_clf = SGDClassifier(loss='hinge', penalty='l2', alpha=1e-3, max_iter=5) svm_clf.fit(X_train, y_train) pred = svm_clf.predict(X_test) cm = pd.crosstab(pred, y_test) metrics.accuracy_score(y_test,pred)
0.8254810882548109
准确率为82.5%,效果也不错,与多项式贝叶斯分类器接近。SGD适合应用在大规模稀疏数据问题上,效率很高。
4.结果分析
以多项式贝叶斯分类器的结果为例进行分析。
查看混淆矩阵:
cm
col_0 娱乐 时尚 汽车 游戏 科技 财经 category 娱乐 198 16 6 1 7 9 时尚 23 208 10 3 9 3 汽车 5 4 217 4 17 4 游戏 5 2 14 231 6 4 科技 5 1 15 3 184 27 财经 5 3 18 4 24 212
绘制热力图:
import matplotlib.pyplot as plt import seaborn as sns #配置中文字题,使中文正常显示 plt.rcParams['font.sans-serif'] = ['SimHei'] #绘制热力图 sns.heatmap(cm, annot=True, cmap='GnBu', fmt='d') plt.xlabel('predict') plt.ylabel('real') plt.show()
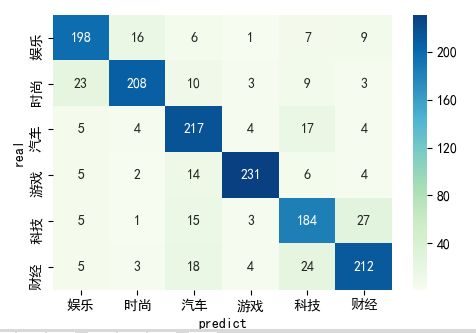
根据混淆矩阵,可以看出时尚-娱乐、汽车-科技、科技-财经,这几个组合相互错误分类的概率较高。
写一个函数来查看分类错误的新闻标题有哪些:
def show_diff(real, predict): df = pd.DataFrame({'real': y_test, 'predict': mnb_pred}) a = df[df['real']==real] b = a[a['predict']==predict] b.reset_index(inplace=True) print('实际分类:%s, 预测分类:%s\n' % (real, predict), news.iloc[b['index']]) show_diff('时尚','娱乐') show_diff('科技','汽车') show_diff('科技','财经')
1 实际分类:时尚, 预测分类:娱乐 2 category title 3 553 时尚 张艺兴工作拍摄花絮色彩张扬的少年模样 4 365 时尚 周洁琼现身机场,穿深色小西装配分牛仔裤,戴报童帽可爱极了 5 103 时尚 朱正廷机场现身,戴眼镜显书生气,衣品获网友点赞 6 82 时尚 杨幂穿卫衣现身机场,细如竹杆的腿超抢镜,岁的年龄岁脸 7 110 时尚 张柏芝依旧身材爆表美得惊艳,钟欣潼的“幸福肥”却越来越严重 8 102 时尚 佘诗曼与温碧霞一同出席活动,都穿大红裙,她却赢在发型上? 9 431 时尚 生完二胎照样恢复到无可挑剔,韩国女神保持美丽的背后对自己超狠 10 1303 时尚 她竟拥有连都自叹不如的手工艺 11 353 时尚 网友吐槽易烊千玺将卫衣帽子当围脖 其实抽绳是这样用的 12 111 时尚 杨颖登美版封面,比肩寡姐,杂志称“中国金·卡戴珊” 13 91 时尚 小哥哥的称呼已经过时了?听到杨超越对王源的称呼,网友:就服你 14 286 时尚 千万别踩雷!这件千多的花衣服谁穿谁土,江疏影穿了都像村姑 15 769 时尚 我所见过最难的坎儿,是苏明玉的原生家庭大逃杀 16 755 时尚 三月想桃花运旺盛,白色针织衫来帮忙,让你的真命天子提早降临 17 366 时尚 孙红雷谈“唯成绩论”教育问题,女儿虽小但已经感觉到压力 18 77 时尚 杨超越用两句歌词证明自己,谁注意到金瀚的反应,网友:太真实了 19 98 时尚 张柏芝广告大片再出新造型,樱花粉衬衫搭羽毛裙,美得温柔动人 20 290 时尚 明明是高仿版张予曦,却靠模仿小龙女和张柏芝走红 21 207 时尚 俗气!岁林志玲皮裙豹纹全上身,芭比粉嘟嘴卖萌,妈妈辈审美 22 192 时尚 宋祖儿小雀斑妆新鲜出炉,颜值新高度,网友:不就是苍蝇屎吗 23 210 时尚 谢娜晒海边度假美照,手臂上的几个字亮了,被赞绝对是个好妈妈 24 276 时尚 新“四小花旦”登封面,花式比美拼时尚 25 768 时尚 超杀女减肥减掉半个自己,却一点不开心
1 实际分类:科技, 预测分类:汽车 2 category title 3 3739 科技 度的金属溶液液态氮,结果有点出乎意料! 4 3765 科技 当汽车从玩具鸡身上碾压过去,玩具鸡的反应太搞笑了,网友:你真惨! 5 3295 科技 家庭版的私人健身房,不仔细看你都不会发现,看完充满购买欲望 6 3115 科技 进口的钻头贵是有它的道理的,能钻开钢板 7 3606 科技 废物利用,香港推出豪华水管房,用平米打造一个家!你想住吗? 8 3558 科技 汽车从密密麻麻的钉子上碾过去,轮胎会被扎爆吗?结果尴尬了! 9 3236 科技 饮料瓶底下的凹槽是干什么用的?里面科技含量可大了 10 3383 科技 将抗压球放摩托车下碾过,能扛住吗? 11 4216 科技 国产大飞机安全吗?总设计师:我们不怕大雁撞 12 3238 科技 把跑步机安装在浴缸里!能健身能能泡澡的浴缸了解一下 13 4815 科技 特斯拉新超跑罕见亮相 基本版售价万美元 14 5229 科技 特斯拉即将发布跨界,它能一炮而红吗? 15 3883 科技 大货车差速器的工作原理,怪不得大货车动力那么猛 16 4519 科技 曝光:拥有和兰博基尼版 最贵卖万元 17 2778 科技 风扇还可以这样简单,自带风力没有扇叶,度全方位吹风
1 实际分类:科技, 预测分类:财经 2 category title 3 2983 科技 华为起诉美国,真的是一步好棋,不管输赢,华为都是大赢家! 4 4807 科技 又到一年“” 看看往年都有哪些大公司被“锤” 5 3071 科技 美国与昔日盟友决裂,只因拒绝其无理要求,公然支持“华为” 6 4640 科技 中国最恐怖工厂:养亿只蟑螂,每天喂吨饭,政府还补贴 7 4937 科技 第一财季净利润.亿美元 同比增长.% 8 5560 科技 新零售这一年风起云涌 线下消费新模式含苞待放 9 5458 科技 以“激进行动应对美国压力”,任正非对披露原因 10 2961 科技 万吨巨轮也要定期洗澡?洗澡要花天,为了让船晚退休也是拼了! 11 3415 科技 华为真铁粉!筹集亿巨资,欲与华为联手,实现升级 12 4936 科技 韩国检方就三星生物财务造假案搜查其办公室 13 3752 科技 一年净亏亿,趣头条:这只是刚刚开始 14 4152 科技 智慧养老:裸奔的老年“数据人” 15 2853 科技 波音客机坠毁后!中国竟是全球第一个这么做的国家 16 4156 科技 贾跃亭出新招:拟出售北拉斯韦加斯多亩土地 17 5511 科技 拼多多最新财报解谜:指数级高速增长,超过京东成第二大电商 18 3430 科技 牙刷中的刷毛,是怎么弄进去的?一起去寻找答案吧 19 3539 科技 容声冰箱能否重新定义养鲜标准 ? 20 5063 科技 翡翠是怎么制作出来的?看完之后,明白翡翠为什么这么贵! 21 3283 科技 支付宝还款开始收费?同时三月又撒红包福利!准备抢 22 4648 科技 传拟月份启动 自我估值亿美元 23 2957 科技 中国再次出手!个阶段解决余国的不解难题,美国:不可能吧! 24 3073 科技 一个南瓜够你吃一个月,美国农场种植出超级大南瓜,粉碎做肥料 25 3428 科技 最新动态,西方航发巨头提议在中国建厂,网友却表示拒绝 26 3641 科技 英伟达创立 年最大规模收购,和它想要的增长和计算未来 27 3124 科技 秦岭深处突现一声巨响,美国惊呼:中国居然真的做到了 28 5215 科技 雷军:建议加快推动航天立法 29 4011 科技 快递过度包装浪费严重 谭平川代表:推行绿色统一可循环包装
从错误分类的新闻标题来看,时尚新闻和娱乐新闻标题相似度很高,错误分类概率高也比较正常;科技错误分类为汽车的新闻标题大部分出现了与车有关的词语;科技错误分类为财经的新闻标题里出现了较多公司,资金等相关词语。
有一部分新闻的分类界限较模糊,例如:
5511 科技 拼多多最新财报解谜:指数级高速增长,超过京东成第二大电商
分类到科技或财经都是合理的。
优化分析:可以优化的地方是词条矩阵的构造,可以通过调整max_df和min_df的阈值改变词条矩阵的合理性。调整max_df的值过滤整体词频过高的词语,调整min_df的值过滤整体词频过低的词语。可以根据样本自变量数量和词频分布来选择合适的值。理论上min_df越小,自变量数量越多,分类越准确,但是会大量增加计算量,所以要根据具体情况来考量。
把min_df调整到0.0002后,自变量增加了2.5倍,结果为0.8460517584605176,准确度确实提高了,不过耗时也明显增加了。
参考书本:《从零开始学Python--数据分析与挖掘》
jieba分词中自定义词库和停止词来源:https://github.com/SnakeLiu/Python-Data-Aanalysis-and-Miner