基于Docker的Hadoop集群的搭建和使用
一、安装Docker
安装Docker——点击这里
二、在docker中安装ubuntu系统
首先从docker hub上面拉取一个ubuntu镜像
$ docker pull ubuntu:latest验证是否安装成功
$ docker images安装成功如下图:

在启动镜像时,需要一个文件夹向镜像内部进行文件传输,所以在家目录下面新建一个文件用于文件传输
$ mkdir docker-ubuntu然后在docker上运行ubuntu
$ docker run -it -v ~/docker-ubuntu:/root/docker-ubuntu --name ubuntu ubuntu三、ubuntu系统初始化
由于刚刚安装好之后的系统是纯净系统,很多软件都没有装,所以需要刷新一下软件源以及安装一些必要的软件。
(一)刷新源
由于在docker 上面运行的Ubuntu默认登录的为root用户,所以运行命令不需要sudo
root@11e9379d2a29:/# apt update(二)安装一些必要的软件
1、安装vim
终端中用到的文本编辑器有vim、emacs、nano等,上课老师都让用vim,这里也安装vim
root@11e9379d2a29:/# apt install vim2、安装sshd
由于分布式需要用ssh连接到docker内的镜像
root@11e9379d2a29:/# apt install ssh然后在~/.bashrc内加入/etc/init.d/ssh start,保证每次启动镜像时都会自动启动ssh服务,也可以使用service或者systemctl设置ssh服务自动启动
然后就是配置ssh免密登录
root@11e9379d2a29:~# ssh-keygen -t rsa #一直按回车键即可root@11e9379d2a29:~/.ssh# cat id_rsa.pub >> authorized_keys3、安装jdk
由于Hadoop需要Java,因此还需要安装jdk,由于默认的jdk为Java10,所以需要改成java8
root@11e9379d2a29:~# apt install openjdk-8-jdk接下来设置JAVA_HOME于PATH变量,只需要在~/.bashrc最后加入
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
然后使~/.bashrc生效
root@11e9379d2a29:~# source ~/.bashrc(三)保存镜像文件
由于容器内的修改不会自动保存,所以需要对容器进行一个保存。使用docker ps -a 查看容器id并使用docker commit 保存镜像。在此之前先退出容器,再查看容器id
root@11e9379d2a29:~# exit
exit
root@cecilia-virtual-machine:~/# docker ps -a保存镜像
docker commit b59d716dbb4d ubuntu/jdkinstalled四、安装Hadoop
首先利用刚刚保存的镜像启动已安装JAVA的容器
$docker run -it -v ~/docker-ubuntu:/root/docker-ubuntu --name ubuntu-jdkinstalled ubuntu/jdkinstalled下载Hadoop文件
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz开启之后把下载的Hadoop文件放到新建的文件夹内,再解压
root@bd62eafa76b3:/# cp /hadoop-2.9.2.tar.gz /root/docker-ubuntu
root@bd62eafa76b3:/# cd /root/docker-ubuntu
root@bd62eafa76b3:/# tar -zxvf hadoop-2.9.2.tar.gz -C /usr/local测试Hadoop是否安装成功,是否输出对应的Hadoop版本号
root@bd62eafa76b3:/# cd /usr/local/hadoop-2.9.2/
root@bd62eafa76b3:/usr/local/hadoop-2.9.2# ./bin/hadoop version五、配置Hadoop集群
首先需要修改hadoop-env.sh中的JAVA_HOME
root@bd62eafa76b3:/usr/local/hadoop-2.9.2# vim etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/接下来修改core-site.xml
root@bd62eafa76b3:/usr/local/hadoop-2.9.2# vim etc/hadoop/core-site.xml
hadoop.tmp.dir
file:/usr/local/hadoop-2.9.2/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://master:9000
然后修改hdfs-site.xml
root@bd62eafa76b3:/usr/local/hadoop-2.9.2# vim etc/hadoop/hdfs-site.xml
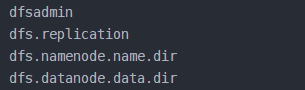
dfs.namenode.name.dir
file:/usr/local/hadoop-2.9.2/namenode_dir
dfs.datanode.data.dir
file:/usr/local/hadoop-2.9.2/datanode_dir
dfs.replication
3
然后将mapred-site.xml.template复制为mapred.xml,然后进行修改
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
最后修改yarn-site.xml
vim etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
现在集群配置的已经差不多了,将现有的镜像保存一下
root@cecilia-virtual-machine:~# docker commit 2ecf3c0dba0e ubuntu/hadoopinstalled然后在三个终端上面开启三个容器镜像,分别代表集群中的master、slave01、slave02
# 第一个终端
$ docker run -it -h master --name master ubuntu/hadoopinstalled#第二个终端
$ docker run -it -h slave01 --name slave01 ubuntu/hadoopinstalled#第三个终端
$ docker run -it -h slave02 --name slave02 ubuntu/hadoopinstalled然后分别查看他们的/etc/hosts文件,查看名字和ip
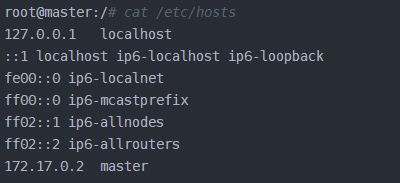
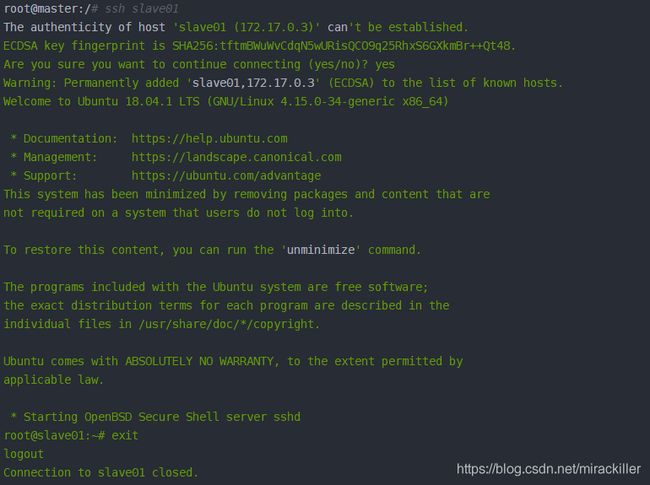
最后把上述三个地址信息分别复制到master,slave01和slave02的/etc/hosts即可,可以用如下命令来分别检查是否master是否可以连上slave01和slave02
接下来是配置集群的最后一步,打开master上面的slaves文件,输入slave0和slave02
root@master:/usr/local/hadoop-2.9.2# vim etc/hadoop/slavesslave01
slave02这样集群就配置完成了,接下来是启动
在master上面,进入/usr/local/hadoop-2.9.2,然后运行如下命令
root@master:/usr/local/hadoop-2.9.2# bin/hdfs namenode -formatroot@master:/usr/local/hadoop-2.9.2# sbin/start-all.sh这个时候集群已经启动了,然后在master,slave01和slave02上分别运行命令jps查看运行结果
root@master:/usr/local/hadoop-2.9.2# bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input output 'dfs[a-z.]+' 等这个程序运行结束之后,就可以在hdfs上的output目录下查看到运行结果:
root@master:/usr/local/hadoop-2.9.2# bin/hdfs dfs -cat output/*