AdaBoost算法(附代码且代码超完整)
- 首先,阅读我写的这篇文章,需要先学习Adaboost算法相关原理
个人推荐刘建平Pinard整理的下面两篇文章(因为代码编写根据这两篇文章来的)
- 集成学习之Adaboost算法原理小结
- scikit-learn Adaboost类库使用小结
- 理论上任何学习器都可以用于Adaboost。但一般来说,使用最广泛的Adaboost弱学习器是
决策树和神经网络。对于决策树,Adaboost分类用了CART分类树,而Adaboost回归用了CART回归树。 - Adaboost的优缺点
- Adaboost的主要优点有:
- Adaboost作为分类器时,分类精度很高
- 在Adaboost的框架下,可以使用各种回归分类模型来构建弱学习器,非常灵活。
- 作为简单的二元分类器时,构造简单,结果可理解。
- 不容易发生过拟合
- Adaboost的主要缺点有:
- 训练时间过长。
- 执行效果依赖于弱分类器的选择。
- 对样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
- Sklearn实现Adaboost算法(demo),来源于scikit-learn Adaboost类库使用小结
- AdaBoostClassifier(base_estimator=None, n_estimators=50,
learning_rate=1.0, algorithm=‘SAMME.R’, random_state=None)- AdaBoostRegressor(base_estimator=None, n_estimators=50,
learning_rate=1.0, loss=‘linear’, random_state=None)
- base_estimator:用于指定提升算法所应用的基础分类器,
默认为分类决策树(CART),也可以是其他基础分类器,但分类器必须支持带样本权重的学习,如神经网络。- n_estimators:用于指定
基础分类器的数量,默认为50个,当模型在训练数据集中得到完美的拟合后,可以提前结束算法,不一定非得构建完指定个数的基础分类器。- learning_rate:用于指定模型迭代的学习率或步长,即对应的提升模型 F ( x ) F(x) F(x)可以表示为 F ( x ) = F m − 1 ( x ) + v α m f m ( x ) F(x) = F_{m−1}( x) +v\alpha_mf_m(x) F(x)=Fm−1(x)+vαmfm(x) ,其中的就是该参数的指定值,默认值为1;
对于较小的学习率而言,则需要迭代更多次的基础分类器,通常情况下需要利用交叉验证法确定合理的基础分类器个数和学习率。- algorithm:用于指定AdaBoostClassifier分类器的算法,默认为’SAMME.R’,也可以使用’SAMME’;
使用'SAMME.R'时,基础模型必须能够计算类别的概率值;一般而言,'SAMME.R'算法相比于'SAMME'算法,收敛更快、误差更小、迭代数量更少。- loss:用于指定AdaBoostRegressor回归提升树的损失函数,可以是’linear’,表示使用线性损失函数;也可以是’square’,表示使用平方损失函数;还可以是’exponential’,表示使用指数损失函数;该参数的默认值为’linear’。
- random_state:用于指定随机数生成器的种子。
代码1:
# 读入数据
default = pd.read_excel(r'default of credit card.xls')
# 排除数据集中的ID变量和因变量,剩余的数据用作自变量X
X = default.drop(['ID','y'], axis = 1)
y = default.y
# 数据拆分
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,y,test_size = 0.25,
random_state = 1234)
# 构建AdaBoost算法的类
AdaBoost1 = ensemble.AdaBoostClassifier()
# 算法在训练数据集上的拟合
AdaBoost1.fit(X_train,y_train)
# 算法在测试数据集上的预测
pred1 = AdaBoost1.predict(X_test)
# 返回模型的预测效果
print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred1))
print('模型的评估报告:\n',metrics.classification_report(y_test, pred1))
out:
模型的准确率为:
0.812533333333
模型的评估报告:
precision recall f1-score support
0 0.83 0.96 0.89 5800
1 0.68 0.32 0.44 1700
avg / total 0.80 0.81 0.79 7500
# 取出重要性比较高的自变量建模
predictors = list(importance[importance>0.02].index)
Predictors
# 通过网格搜索法选择基础模型所对应的合理参数组合
max_depth = [3,4,5,6]
params1 = {'base_estimator__max_depth':max_depth}
base_model = GridSearchCV(estimator = ensemble.AdaBoostClassifier(base_estimator =
DecisionTreeClassifier()),param_grid= params1,
scoring = 'roc_auc', cv = 5, n_jobs = 4, verbose = 1)
base_model.fit(X_train[predictors],y_train)
# 返回参数的最佳组合和对应AUC值
base_model.best_params_, base_model.best_score
out:
{'base_estimator__max_depth': 3}, 0.74425046797936145
# 通过网格搜索法选择合理的Adaboost算法参数
n_estimators = [100,200,300]
learning_rate = [0.01,0.05,0.1,0.2]
params2 = {'n_estimators':n_estimators,'learning_rate':learning_rate}
adaboost = GridSearchCV(estimator = ensemble.AdaBoostClassifier(base_estimator =
DecisionTreeClassifier(max_depth = 3)),param_grid= params2,
scoring = 'roc_auc', cv = 5, n_jobs = 4, verbose = 1)
adaboost.fit(X_train[predictors] ,y_train)
# 返回参数的最佳组合和对应AUC值
adaboost.best_params_, adaboost.best_score_
out:
{'learning_rate': 0.01, 'n_estimators': 300}, 0.76866547085583281
# 使用最佳的参数组合构建AdaBoost模型
AdaBoost2 = ensemble.AdaBoostClassifier(base_estimator = DecisionTreeClassifier(max_depth =
3),n_estimators = 300, learning_rate = 0.01)
# 算法在训练数据集上的拟合
AdaBoost2.fit(X_train[predictors],y_train)
# 算法在测试数据集上的预测
pred2 = AdaBoost2.predict(X_test[predictors])
# 返回模型的预测效果
print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred2))
print('模型的评估报告:\n',metrics.classification_report(y_test, pred2))
out:
模型的准确率为:
0.816
模型的评估报告:
precision recall f1-score support
0 0.83 0.96 0.89 5800
1 0.69 0.34 0.45 1700
avg / total 0.80 0.82 0.79 7500
代码2:
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
#生成二维正态分布,生成的数据分为两类,500个样本,2个样本特征,协方差系数为2
X1,y1 = make_gaussian_quantiles(cov=2.0,n_samples=600,
n_features=2,n_classes=2,
random_state=1)
#生成二维正态分布,生成的数据分为两类,400个样本,2个样本特征,协方差系数为1.5
X2,y2 = make_gaussian_quantiles(mean=(3,3),cov=1.5,
n_samples=400,n_features=2,
n_classes=2,random_state=1)
#将两组数据合为一组
X = np.concatenate((X1,X2))
y = np.concatenate((y1,-y2+1))
#通过可视化看看我们的分类数据,它有两个特征,两个输出类别,用颜色区别
plt.figure(figsize=(8,6))
plt.scatter(X[:,0],X[:,1],marker='o',c=y)
plt.show()
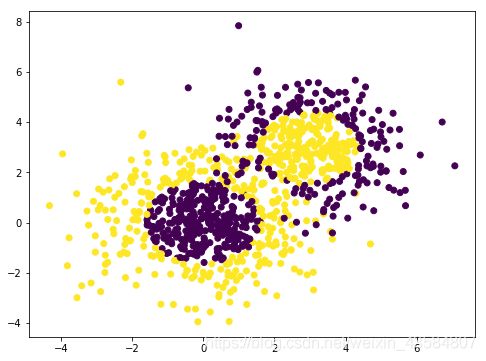
可以看到数据有些混杂,我们现在用基于决策树的Adaboost来做分类拟合。
# 训练数据
#选择SAMME算法,最多200个弱分类器,步长0.8
clf=AdaBoostClassifier(DecisionTreeClassifier(
max_depth=2,min_samples_split=20, #决策树最大深度为2,内部节点再划分所需最小样本数是20,叶子节点最少样本数
min_samples_leaf=5),algorithm="SAMME", #采用"SAMME":用对样本集分类效果作为弱学习器权重
n_estimators=200,learning_rate=0.8) #最大迭代次数为8,步长是0.8
#n_estimators和learning_rate要一起调参来决定算法的拟合效果
clf.fit(X,y)
#将训练结果绘画出来
plt.figure(figsize=(8,6))
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
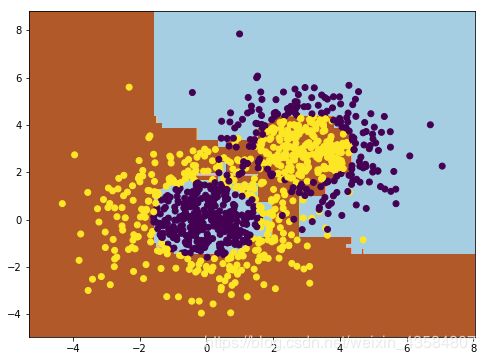
从图中可以看出,Adaboost的拟合效果还是不错的,现在我们看看拟合分数:
#训练模型的得分
print(clf.score(X,y))
#0.962
也就是说拟合训练集数据的分数还不错。当然分数高并不一定好,因为可能过拟合。
- 对策,不断的更改n_estimators和learning_rate的值做实验
- 可以将最大弱分离器个数从200增加到300(n_estimators=300)。再来看看拟合分数
- (拟合分数Score=0.962),这印证了我们前面讲的,
弱分离器个数越多,则拟合程度越好,当然也越容易过拟合。
- (拟合分数Score=0.962),这印证了我们前面讲的,
- 降低步长,将步长从上面的0.8减少到0.5(learning_rate=0.5),看看拟合分数。
- (拟合分数Score=0.894),可见在同样的弱分类器的个数情况下,如果减少步长,拟合效果会下降。
- 最后我们看看当弱分类器个数为700,步长为0.7(n_estimators=700, learning_rate=0.7时候的情况
- (拟合分数Score=0.961)此时的拟合分数和我们最初的300弱分类器,0.8步长的拟合程度相当。也就是说,
- 在我们这个例子中,如果步长从0.8降到0.7,则弱分类器个数要从300增加到700才能达到类似的拟合效果。
- AdaBoost的一般流程
- 收集数据:可以使用任意方法。
- 准备数据:依赖于所使用的弱分类器类型,接下来使用的是单层决策树,这种分类器可以处理任何数据类型。当然也可以使用任意分类器作为弱分类器,第2章到第6章的任一分类器都可以充当弱分类器。作为弱分类器,简单分类器的效果最好。
- 分析数据:可以使用任意方法
- 训练算法:AdaBoost的大部分时间都用在训练上,分类器将多次在同一数据集上训练弱分类器。
- 测试算法:计算分类的错误率。
- 使用算法:观察该例子上的错误率
- 运用分类效果评价指标进行评价
- 下文会用到难数据集应用AdaBoost的过程,对此先在这做出说明:
- 收集数据:提供的文本文件。
- 准备数据:确保类别标签是+1和-1而非1和0。
- 分析数据:手工检查数据。
- 训练算法:在数据上,利用adaBoostTrainDS()函数训练出一系列的分类器。
- 测试算法:我们拥有两个数据集。在不采用随机抽样的方法下,就会对 AdaBoost和Logistic回归的结果进行完全对等的比较。
- 使用算法:观察该例子上的错误率。
- 运用分类效果评价指标(受试者工作特征曲线 (ROC)曲线))进行评价
- 完整代码附上:
#coding=utf-8
from numpy import *
import matplotlib.pyplot as plt
# 简单数据
def loadSimpData():
datMat = matrix([[ 1. , 2.1],
[ 2. , 1.1],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
#在难数据集上应用
#自适应数据加载函数
def loadDataSet(fileName):
'''
这个函数用来加载训练数据集
输入:存储数据的文件名
输出:数据集列表 以及 类别标签列表
'''
numFeat = len(open(fileName).readline().split('\t')) #get number of fields
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
#对数据进行分类(用于测试是否有某个值小于或者大于测试的阀值)
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq): #仅用于分类数据
'''
dataMatrix: (特征数据转化成的)特征矩阵
dimen: dimen=range(shape(dataMatrix)[1])
threshVal: 阈值
threshIneq: 小于/大于阈值的选择
'''
retArray = ones((shape(dataMatrix)[0],1))
#将小于或者大于阀值的数值设为-1
if threshIneq == 'less_than':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
#找到最佳决策树(最佳指加权错误率最低)
def buildStump(dataArr,classLabels,D):
'''
dataArr: 特征数据
classLabels: 标签数据
D: 基于数据的权重向量
'''
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf #最小错误率,开始初始化为无穷大
for i in range(n): #遍历数据集所有特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps #考虑数据特征,计算步长
for j in range(-1, int(numSteps) + 1): #遍历不同步长时的情况
for inequal in ['less_than', 'greater_than']: #小于/大于阈值 切换遍历
threshVal = (rangeMin + float(j) * stepSize) #设置阈值
predictedVals = stumpClassify(dataMatrix, i, threshVal,inequal) #分类预测
errArr = mat(ones((m, 1))) #初始化全部为1 (初始化全部错误)
errArr[predictedVals == labelMat] = 0 #预测正确分类为0,错误则为1
# 分类器与adaBoost交互
# 权重向量×错误向量=计算权重误差(加权错误率)
weightedError = D.T * errArr
if weightedError < minError:
minError = weightedError #保存当前最小的错误率
bestClasEst = predictedVals.copy() #预测类别
#保存该单层决策树
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst #返回字典,返回错误率最小情况下的决策树,错误率和类别估计值。
#完整adaboost算法
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
'''
dataArr: 特征数据
classLabels: 标签数据
numIt: 迭代次数
'''
weakClassArr = [] #迭代分类器的信息(决策树字典添加alpha键值后形成嵌套字典的列表)
m = shape(dataArr)[0] #m表示数组行数
D = mat(ones((m,1))/m) #初始化每个数据点的权重为1/m
aggClassEst = mat(zeros((m,1))) #记录每个数据点的类别估计累计值
for i in range(numIt):
# 建立一个单层决策树,输入初始权重D
bestStump,error,classEst = buildStump(dataArr,classLabels,D) #classEst:弱分类器估计值
#print ("D:",D.T)
# alpha表示本次输出结果权重
alpha = float(0.5*log((1.0-error)/max(error,1e-16))) #1e-16防止零溢出
bestStump['alpha'] = alpha #alpha加入字典
weakClassArr.append(bestStump) #保存该次迭代分类器的信息
#print ("classEst: ",classEst.T) #该次迭代分类器对样本的估计值
# 计算下次迭代的新权重D
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D,exp(expon)) #第k个弱分类器规范化因子
D = D/D.sum() #k+1个弱分类器的样本集权重系数(D.sum():规范化因子)
# 计算累加错误率(集合策略:加权表决法)
aggClassEst += alpha*classEst
#print ("aggClassEst: ",aggClassEst.T)
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print ("total error: ",errorRate)
if errorRate == 0.0: break #错误率为0时 停止迭代
return weakClassArr,aggClassEst
#测试adaboost(利用训练出的多个弱分类器进行分类),用于预测
def adaClassify(datToClass,classifierArr):
'''
datToClass: 待分类样例
classifierArr: 多个弱分类器
'''
dataMatrix = mat(datToClass) #待分类样例 转换成numpy矩阵
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)): #遍历所有弱分类器
classEst = stumpClassify(dataMatrix,\
classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha']*classEst #由各个分类器加权确定
#print (aggClassEst) #输出每次迭代侯变化的结果
return sign(aggClassEst) #返回符号,大于0返回1,小于0返回-1
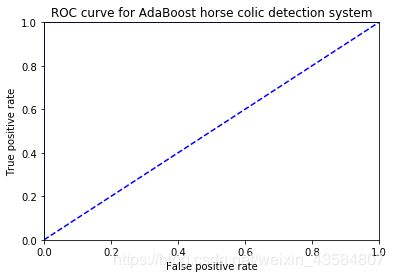
def plotROC(predStrengths, classLabels):
cur = (1.0,1.0) #cursor
ySum = 0.0 #variable to calculate AUC
numPosClas = sum(array(classLabels)==1.0)
yStep = 1/float(numPosClas); xStep = 1/float(len(classLabels)-numPosClas)
sortedIndicies = predStrengths.argsort()#get sorted index, it's reverse
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
#loop through all the values, drawing a line segment at each point
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0; delY = yStep;
else:
delX = xStep; delY = 0;
ySum += cur[1]
#draw line from cur to (cur[0]-delX,cur[1]-delY)
ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b')
cur = (cur[0]-delX,cur[1]-delY)
ax.plot([0,1],[0,1],'b--')
plt.xlabel('False positive rate'); plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
ax.axis([0,1,0,1])
plt.show()
print ("the Area Under the Curve is: ",ySum*xStep)
if __name__ == '__main__':
# 简单数据
print('='*10 + '简单数据集的应用' + '='*10)
d,c = loadSimpData() #收集数据
weakClassArr1,aggClassEst1 = adaBoostTrainDS(d,c) #训练算法
testArr1 = [0,0]
prediction1 = adaClassify(testArr1,weakClassArr1) #测试算法(假设测试数据为[0,0])
plotROC(aggClassEst1.T,c)
print()
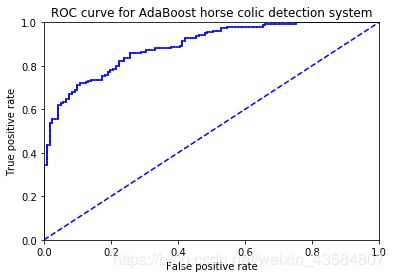
#难数据集的应用
print('='*10 + '难数据集的应用(加载训练数据和测试)' + '='*10)
datArr,labelArr = loadDataSet('horseColicTraining2.txt')
testArr,testLabelArr = loadDataSet('horseColicTest2.txt')
weakClassArr,aggClassEst = adaBoostTrainDS(datArr,labelArr) #训练算法
prediction = adaClassify(testArr,weakClassArr) #测试(预测)算法
errArr = multiply(prediction != mat(testLabelArr).T,ones((len(testArr),1))).sum()#错误个数
errorRate = errArr / len(testArr) #平均错误率为
print('测试后的平均错误率为',errorRate)
plotROC(aggClassEst.T,labelArr)
代码输出:
==========简单数据集的应用==========
total error: 0.2
total error: 0.2
total error: 0.0
the Area Under the Curve is: 1.0
==========难数据集的应用(加载训练数据和测试)==========
total error: 0.2842809364548495
total error: 0.2842809364548495
total error: 0.24749163879598662
total error: 0.24749163879598662
total error: 0.25418060200668896
total error: 0.2408026755852843
total error: 0.2408026755852843
total error: 0.22073578595317725
total error: 0.24749163879598662
total error: 0.23076923076923078
total error: 0.2408026755852843
total error: 0.2140468227424749
total error: 0.22742474916387959
total error: 0.21739130434782608
total error: 0.22073578595317725
total error: 0.21739130434782608
total error: 0.22408026755852842
total error: 0.22408026755852842
total error: 0.23076923076923078
total error: 0.22408026755852842
total error: 0.2140468227424749
total error: 0.20735785953177258
total error: 0.22408026755852842
total error: 0.22408026755852842
total error: 0.2140468227424749
total error: 0.22073578595317725
total error: 0.2040133779264214
total error: 0.20735785953177258
total error: 0.21070234113712374
total error: 0.21739130434782608
total error: 0.21070234113712374
total error: 0.21739130434782608
total error: 0.20735785953177258
total error: 0.21070234113712374
total error: 0.20735785953177258
total error: 0.20735785953177258
total error: 0.19732441471571907
total error: 0.19063545150501673
total error: 0.20066889632107024
total error: 0.19732441471571907
测试后的平均错误率为 0.19402985074626866
the Area Under the Curve is: 0.8918191104095092
参考文献:
-
集成学习之Adaboost算法原理小结
-
scikit-learn Adaboost类库使用小结
-
赵卫东老师的Adaboost Python源程序
-
机器学习实战第七章学习笔记(AdaBoost算法)
-
AdaBoost (Python 3)
-
机器学习算法( 七、AdaBoost元算法)