Python3爬虫(三):用requests一行实现有道翻译的代码和添加User-Agent和和Cookie请求头访问网址
运行平台:Windows
Python版本:Python3.7.4
IDE:PyCharm2019.3.3
转载请注明作者和出处: https://blog.csdn.net/hjj19991111/article/details/104614042
一、requests的运用
1.安装requests
requests是Python的第三方库,所以要先安装,这里提供两种安装方式
1) 使用命令行通过pip安装:
$ pip install requests
2) 使用Pycharm来安装,点击文件-设置,搜索Project Interpreter,得到这个界面:

点击右侧的+号,搜索requests,并点击左下角的install package,就可以安装了

2.运用requests
requests发送GET请求用的是requests.get()函数,同理发送POST请求用的是requests.post()函数,下面我们直接来看代码实现:
- 用urllib.request.urlopen()来实现POST请求并返回json数据
form_data = {} #{}内为字典定义的数据
#对form_data进行转换
data = parse.urlencode(form_data).encode('utf-8')
res = request.urlopen(url,data)
html = res.read.decode('utf-8')
html_js = json.load(html)
translate = html_js['translateResult'][0][0]['tgt']
- 用requests.post()来实现POST请求并返回json数据
form_data = {} #{}内为字典定义的数据
html = requests.post(url,form_data)
html_js =html.json()
translate = html_js['translateResult'][0][0]['tgt']
通过对两种方式的比较,我们可以发现最大区别是,requests不需要对数据进行解码,这个解码包括对于bytes类型到string类型的解码,也包括了对json数据的解码
接下来就是我们的一行代码时刻:
translate = requests.post(url,form_data).json()['translateResult'][0][0]['tgt']
我们最终代码就可以简化为:
# -*- codeing: UTF-8 -*-
import requests #导入requests库
def youdao(t):
# 创建request_url来放置请求链接
request_url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
# 创建字典form_data存储上图中的数据Form Data数据,将键'i'提取出来单独放
form_data = {
'form': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15831261181564',
'sign': '4bc0cb26b46ed67f51b3992af153d40b',
'ts': '1583126118156',
'bv': '35242348db4225f3512aa00c2f3e7826',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
}
# 存储键'i'的数据
form_data['i'] = t
# 对form_data进行转换
translate = requests.post(request_url,form_data).json()['translateResult'][0][0]['tgt']
return translate
if __name__ == '__main__':
t = input('请输入想要翻译的内容:')
translate = youdao(t)
print('翻译的结果是: ' + translate)
以上就是requests包的利用
二、UserAgent和请求头Headers
1.为什么要设置User-Agent
因为网站呢,当然不喜欢被爬虫爬,就像人也不喜欢被爬虫上身吧,于是就有一系列的反爬手段,比如有道翻译的在真实接口的后面加了_o就是一种反爬手段
而识别User-Agent就是一种最最基础的反爬手段,User-Agent中文名为用户代理。User-Agent存放于请求的Headers中,当我们不设置User-Agent时,Python就会用默认值去访问,这个时候网站识别了你是爬虫程序就会禁止访问。
但幸运的是,Python允许我们去修改这个User-Agent,这个时候我们可以用自己浏览器的User-Agent,如何查看自己浏览器的User-Aent呢,同样要请出我们的开发者工具:
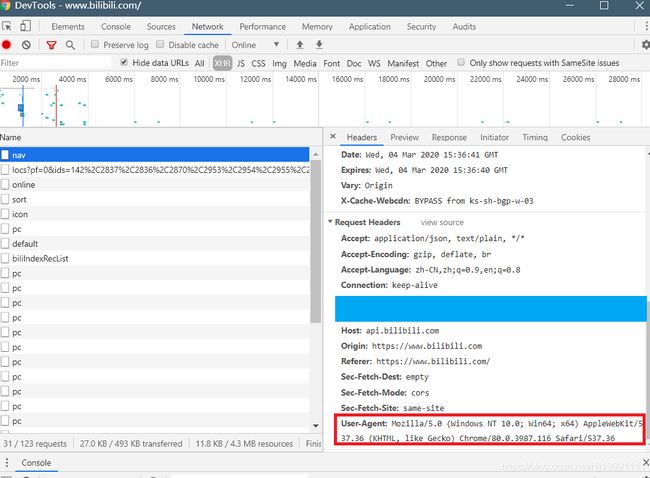
我这里访问的哔哩哔哩的界面,我们打开哔哩哔哩,按下F12调出开发者工具到network,然后刷新页面,就可以看到好多的请求,我们选中其中一条nav,然后找到Request Heasers,就可以找到User-Agent了
2.User-Agent的使用
当我们不带User-Agent去访问哔哩哔哩时:
from urllib import request
html = request.urlopen('https://www.bilibili.com/').read().decode('utf-8')
print(html)
会发现有如下报错:
urllib.error.HTTPError: HTTP Error 403: Forbidden
当我们带上User-Agent时,注意这里通过request.Request()函数来添加请求头:
from urllib import request
#定义请求头
header = {'UserAgent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
#添加请求头生成request对象
request_url = request.Request('https://www.bilibili.com',headers=header)
html = request.urlopen(request_url).read().decode('utf-8')
print(html)
结果还是无法访问???这就奇怪了,为啥不能访问呢,原来是我们的请求头Headers只有一个User-Agent,对于哔哩哔哩这种比较大的网站来说,他还检查你的Headers的其他元素,其中最为主要的就是浏览器的Cookie
3.使用带Cookie访问
当我们把信息中的Cookie也保存再请求头Headers中时:
from urllib import request
#定义请求头
header = {'UserAgent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Cookie':'_uuid=3F560247-758E-4132-0513-C9C42652B9DE43563infoc; buvid3=8579DF65-F00E-4A17-ADC1-24278C3960AE155827infoc; INTVER=1'}
#添加请求头生成request对象
request_url = request.Request('https://www.bilibili.com',headers=header)
html = request.urlopen(request_url).read().decode('utf-8')
print(html)
这个时候我们的哔哩哔哩就可以被访问了
其实假如使用requests包,他可以更大限度的去用默认请求头去访问,当我们不带请求头去访问哔哩哔哩时,会神奇的发现,竟然能成功:
import requests
html = requests.get('https://www.bilibili.com/').text
print(html)
当然我们也可以给requests的请求添加请求头,只需要简单的加上header就好了:
import requests
header = {'UserAgent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Cookie':'_uuid=3F560247-758E-4132-0513-C9C42652B9DE43563infoc; buvid3=8579DF65-F00E-4A17-ADC1-24278C3960AE155827infoc; INTVER=1'}
html = requests.get('https://www.bilibili.com/',header).text
print(html)
可以试验出我们也能得到哔哩哔哩的网页信息,由此也可见requests的强大