Transformer详解
Transformer是Google团队在17年提出的,在目前NLP的领域应用非常的广泛,是由Ashish Vaswani等人在论文《Attention is all your need》中提出的。最近看了李宏毅教授的视频讲解,对Transformer也有了小小的理解。Transformer 在机器翻译任务上的表现超过了 RNN,CNN,只用 encoder-decoder 和 attention 机制就能达到很好的效果,最大的优点是可以高效地并行化。那么为什么Transformer可以高效地并行化呢?这就要从Transformer的架构开始说起。
其实,Transformer就是一个带有 self-attention 机制的 seq2seq 模型,seq2seq 模型大家可能比较熟悉,就是输入是一个 sequence,输出也是一个 sequence 的模型。如图就是一个Transformer的架构:

我们来试想一下,如果我们把 self-attention 替换成 RNN,那么在输出b2的时候,那么一定会读取前一个序列的输出 b1,输出b3 的时候一定会先读取之前序列的输出 b1 和 b2,同理在输出当前序列的时候,都要将之前序列的输出作为输入,所以在 seq2seq 模型中使用RNN,那么输出序列就不能高效的平行化。有的朋友会说使用 CNN 就可以平行化输出序列了,使用 CNN 确实是可以将序列平行化,但是 CNN 的感受野有限,不能很好地兼顾序列前后的上下文关系,或者说是要很多层才能看到前后序列的关系,所以 CNN 也是有一定缺陷的。好了,做了这么多的铺垫,我们可以开始详细介绍 self-attention 的架构了。
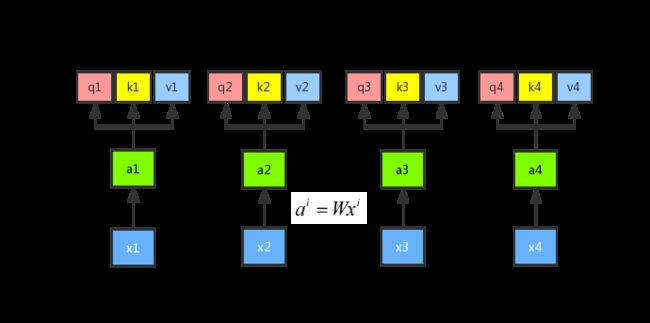
首先假设我们有序列 x1、x2、x3 和 x4 这四个序列,首先我们进行一次权重的乘法 a i = W x i {a^i} = W{x^i} ai=Wxi,得到新的序列 a1、a2、a3 和 a4。示意图如下所示:

然后我们将输入 a 分别乘以三个不同的权重矩阵 W 分别得到 q、k、 v 三个向量,公式分别是 q i = W q a i {q^i} = {W^q}{a^i} qi=Wqai、 k i = W k a i {k^i} = {W^k}{a^i} ki=Wkai、 v i = W v a i {v^i} = {W^v}{a^i} vi=Wvai,这里面 q 表示的是 query,是需要 match 其他的向量的;k 表示的是 key,是需要被 q 来match的,v 表示 value,表示需要被抽取出来的信息。示意图如下所示:
接下来我们需要做的就是将每一个query q 对每一个key k 做 attention 操作,那么 attention 操作是如何做呢,目的是输入两个向量,输出一个数,那么我们可以将这两个向量做内积:q1 和 k1 做attention 得到 α 1 , 1 {\alpha _{1,1}} α1,1 ,q1 和 k2 做attention 得到 α 1 , 2 {\alpha _{1,2}} α1,2,q1 和 k3 做attention 得到 α 1 , 3 {\alpha _{1,3}} α1,3,q1 和 k4 做attention 得到 α 1 , 4 {\alpha _{1,4}} α1,4。其中,attention 的操作可以用很多方法来做,这里我们可以用到一种叫做 scaled 点积,公式是 α 1 , i = q 1 ⋅ k i / d {\alpha _{1,i}} = q1 \cdot ki/\sqrt d α1,i=q1⋅ki/d,这里的 d 表示 q 和 v 的维度。做 attention 的流程如下图所示:

最后我们将 α 1 , 1 {\alpha _{1,1}} α1,1, α 1 , 2 {\alpha _{1,2}} α1,2, α 1 , 3 {\alpha _{1,3}} α1,3, α 1 , 4 {\alpha _{1,4}} α1,4 这四个值进行一个 softmax 操作,得到 α ^ 1 , 1 {\hat \alpha _{1,1}} α^1,1, α ^ 1 , 2 {\hat \alpha _{1,2}} α^1,2, α ^ 1 , 3 {\hat \alpha _{1,3}} α^1,3, α ^ 1 , 4 {\hat \alpha _{1,4}} α^1,4,如图所示:

有了 softmax 的输出之后,我们再通过公式 b 1 = ∑ i α ^ 1 , i ⋅ v i b1 = \sum\limits_i {{{\hat \alpha }_{1,i}} \cdot vi} b1=i∑α^1,i⋅vi 将 α ^ 1 , i {{{\hat \alpha }_{1,i}}} α^1,i 分别和 v i vi vi 进行点乘之后再求和可以得到 b 1 b1 b1。整个流程如图所示:

由上图可以知道,我们求得 b1 的时候,已经看到了a2、a3 和 a4 的输入。所以这个时候的输出,有机会浏览到整个序列。但是每一个输出的序列都有自己重点关注的地方,这个就是 attention 机制的精髓所在,我们可以通过控制 α ^ 1 , 1 {\hat \alpha _{1,1}} α^1,1, α ^ 1 , 2 {\hat \alpha _{1,2}} α^1,2, α ^ 1 , 3 {\hat \alpha _{1,3}} α^1,3, α ^ 1 , 4 {\hat \alpha _{1,4}} α^1,4 来控制我们当前输出所关注的序列权重,如果某一块序列需要被关注,那么就赋予对应 α \alpha α 值的高权重,反之则相反。这是用 q1 做attention 可以求得 整个的输出 b1,同理我们可以用 q2、q3 和 q4 分别做 attention 求得 b2、b3 和 b4。而且b1、b2、b3 和 b4 是平行被计算出来的,互相是没有先后顺序的影响的。所以整个中间的计算过程可以看做是一个 self-attention layer,输入 x1、x2、x3 和 x4,输出是 b1、b2、b3 和 b4。示意图如图所示:

由上面的这些流程图我们可以清楚的知道整个 self-attention 的流程是如何进行的。下面这张图可以更加清晰地告诉我们整个流程的操作是如何进行的:
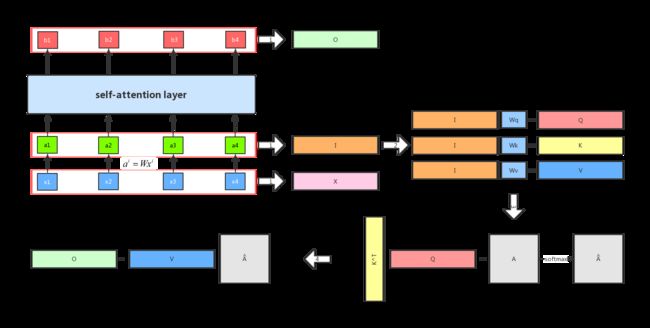
看完了整个的流程我们再来看这个简化的 self-attention 过程是否就很清楚了。那么我们清楚了 self-attention 的操作之后,我们可以将这个机制运用到 seq2seq 里面去,我们都知道 seq2seq 模型都有 encoder 和 decoder,那么我们将原来的中间层替换成 self-attention layer 就可以了。接下来我们来看看整个 transformer 的架构是啥样子的:
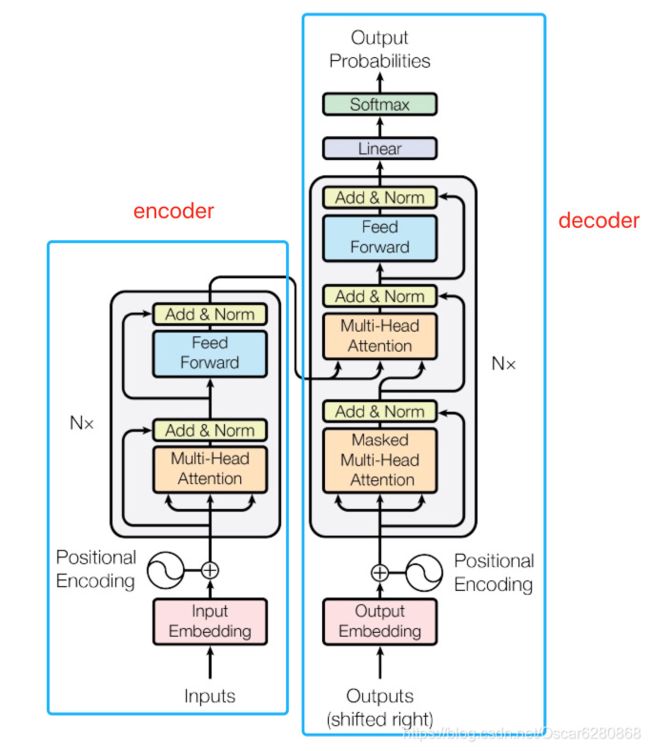
如图所示,整个的 transformer 架构可以分成左右两个部分,左边的部分是 encoder,右边的部分是 decoder。首先我们一起来看 encoder 部分,首先 input 从下方进来了之后,进行 embedding 操作,然后 embedding 之后我们再将嵌入之后的 positional encoding,那么什么是 positional encoding 呢?实际上就是给 ai 加上一个相同维度的向量 ei,示意图如下所示:

如图所示,在生成 q、k、v 的时候,我我们需要给 ai 加上一个相同维度的向量 ei,这个 ei 是我们手动进行设置的,给每一个不同的 ai 加上不同的 ei 值,这个 ei 表示了位置的信息,每一个位置都有着不同的 ei。进行了 positional encoding 之后,再进行一个 muti-head attention 和 add & norm 操作,所谓的 muti-head attention 就是可以同时生成多个 q、k、v 分别进行 attention,这样做的好处是可以获取更多的上下文信息,每个 head 可以关注各自所注意的重点所在。
然后 add & norm 操作就是将 muti-head attention 的 input 和 output 进行相加,然后进行 layer normalization 操作,这里可能问题来了,啥子是 layer normalization?其实 layer normalization 和 batch normalization 刚好相反,batch normalization 表示在一个 batch 里面的数据相同的维度进行 normalization,而 layer normalization 表示在对每一个数据所有的维度进行 normalization 操作。
然后进行一个 feed forward 和 add & norm 操作,feed forward 会对每一个输入的序列进行操作,然后同样会进行一个 add & norm 操作,到这里 encoder 的操作就完成了。
接着我们来看 decoder 的操作,我们将上一个序列的输出作为输入给到 decoder 中去,首先还是进行一个 positional encoding,然后进行的操作是 masked muti-head attention 操作,所谓的 masked muti-head attention 就是对之前产生的序列进行 attention,之后再进行 add & norm 操作,之后再将 encoder 的输出和上一轮 add & norm 的操作进行 muti-head attention 和 add & norm操作,最后再进行一个 feed forward 和 add & norm 操作,这整个的过程可以重复 N 次。
输出的时候经过一个线性层和一个 softmax 层,就输出最终的结果了。这就是完整的 Transformer 架构,整体看起来这个架构非常的复杂,但是我们通过对每一个部分的理解,从局部到整体,就可以很清晰地理解 Transformer 的架构了,希望这篇文章能够帮助大家理解 Transformer 能够有所帮助,文中如有纰漏,也望大家不吝指教,谢谢。