LCDet Low-Complexity Fully-Convolutional Neural Networks for Object Detection in Embedded Systems
Subarna Tripathi
UC San Diego∗
[email protected]
Byeongkeun Kang
UC San Diego
[email protected]
V asudev Bhaskaran
Qualcomm Inc.
[email protected]
Truong Nguyen
UC San Diego
[email protected]
(加州大学圣地亚哥分校)
Abstract
深卷积神经网络(CNN)是最先进的目标检测技术。众所周知,目标检测比图像分类需要更多的计算和内存。在这项工作中,我们提出了LCDet,一种用于一般目标检测的全卷积神经网络,其目的是在嵌入式系统中工作。我们设计并开发了一个基于端到端张量流(TF)的模型。这种检测是通过网络中的一个前向通道进行的。另外,我们对学习到的权重采用8位量化。作为一个例子,我们选择了人脸检测,并在包含不同数量不同大小的人脸的图像上训练所提出的模型。我们评估了公共数据集FDDB和Widerface上的人脸检测性能。实验结果表明,与现有的基于CNN的人脸检测方法相比,该方法具有较高的检测精度,同时与基于CNN的最佳实时目标检测方法YOLO[23]相比,模型尺寸减小了3倍,存储带宽减小了3-4倍。我们的8位定点TF模型在保证精度接近浮点模型的同时,还额外减少了4倍的内存,与浮点模型相比,性能提高了20倍。因此,所提出的模型适合于嵌入式实现,并且是通用的,可以扩展到任意数量的对象类别。
1. Introduction
基于深卷积神经网络(CNN)的模型是当前目标检测领域的研究热点。目标检测的最佳方法旨在*在高通公司实习期间部分完成的工作。提高标准数据集的准确性。它们运行在强大的gpu上,消耗大量的能量。另一方面,嵌入式处理器和dsp是一种很好的低功耗解决方案,其中指令集受益于定点操作。对于移动设备上的对象检测器的实际部署,我们需要能够在嵌入式处理器上运行的低复杂度的美国有线电视新闻网模型。算法需要在不影响精度的前提下利用定点运算。在本文中,我们提出了LCDet,一个低复杂度的对象检测器,以解决上述问题。受YOLO[23]的启发,我们设计并开发了一种基于端到端张量流的全卷积深神经网络用于目标检测。第3.1节描述了拟议网络与YOLO的区别。由于人脸检测在手机中有许多实际应用,我们选择它作为一个用例,尽管该算法对于任何种类都是通用的。我们基于TensorFlow Slim的网络的检测管道需要通过网络的一个前向通道。对FDDB[12]和Widerface[40]等公开数据集的人脸检测性能的评估结果表明,与基于CNN的最新人脸检测方法相比,该方法在降低模型大小3倍和内存BW 3-4倍的同时,达到了较高的精度最快的基于DCN的目标检测器。此外,我们将模型量化为8位精度,这导致额外的4倍内存减少,几乎没有检测精度损失。8位量化是在定点体系结构(如DSP或专用卷积加速器)中部署的最重要步骤之一。我们相信,我们报告了第一个研究的8位量化张量流模型的目标检测任务,大量使用回归。据了解,与为分类任务训练的模型相比,为回归任务训练1 arXiv:1705.05922v1[cs.CV]2017年5月16日的浮点模型的8位量化更容易出现精度下降。实验结果表明,与浮点模型相比,量化模型的最高检测精度下降了不到1-2%,在帧速率方面达到了浮点模型的20倍性能增益。论文的其余部分安排如下。我们在第二节讨论相关的工作。在第三节中,我们介绍了该方法,包括体系结构、训练和模型量化。在第4节中,我们报告我们的人脸检测任务的结果,并讨论相对复杂度和准确度。最后,我们在第5节结束。
2. Related Work
2.1. 基于CNN的目标检测
有几篇论文提出了使用深卷积网络检测物体的方法[7,8,26,30,30,27,38,6,1]。一些方法将提议区域[7,8]划分为对象类别,而其他一些最新的方法[26,23,16]将定位和分类阶段统一起来。关于目标探测器及其速度精度权衡的详细现有技术可在[10]中找到。准确地说,YOLO[23]的单级检测管道速度非常快。YOLO是第一个报道的基于CNN的实时目标检测模型,运行在高端gpu上。它在PASCAL VOC[5]数据集上的性能精度与最新方法相当。与YOLO不同,我们的模型是完全卷积的。因此,它具有很高的存储效率,计算效率更高,并且不受输入图像分辨率的限制。
2.2. 嵌入式系统的CNN目标检测
最准确和性能最好的基于CNN的模型需要高端gpu。人们对开发特定的硬件设计越来越感兴趣[18,3],包括用于基于CNN的节能目标检测的FPGAs、dsp、定制视觉芯片和嵌入式gpu。有关CNN算法的详细算法优势和案例研究,请参见[21,17]。基于CNN的实时目标检测方法(在高端gpu上)性能最好,但在嵌入式gpu上的性能明显不足。例如,监控摄像头市场的一家供应商发现,即使将YOLO的后端从GoogleNet更换为一个更简单的CNN(如AlexNet),它的嵌入式实现在嵌入式GPU上的运行速度也不超过每秒5帧。这促使我们研究可以在嵌入式平台上实时运行的全卷积低复杂度对象检测器。
TensorFlow是一个开源框架,许多开发人员使用它来创建自己的AI应用程序。最近,[28]宣布Snapdragon 835[22]包括TensorFlow优化的Hexagon 682数字信号处理器。这种DSP体系结构和这个系列中的其他结构旨在比CPU或GPU更快、更低功耗地处理某些功能。我们提出的基于TensorFlow的模型充分利用了相似体系结构的优点,对这些平台上的实时目标检测任务非常有用。
2.3.基于CNN的人脸检测
我们选择了人脸检测作为应用,并对LCDet进行了评估。根据FDDB评估服务器[12],最新的人脸检测方法基于卷积神经网络[39、15、41、34、13、29、20]。扬等人。提出了一种结合面部特征响应的神经网络[39]。Li等人。提出了一种神经网络与三维人脸模型相结合的方法[15]。你等。改进了VGG-16网络,并提出了联合(IoU)损失层上的交叉点[41]。最近提出的工作是基于更快的R-CNN[26,34,13,29]。我们的模型通过更快的基于RCNN的方法达到了可比的质量。另外,我们的方法满足了实时嵌入式应用的所有要求,而其他基于CNN的人脸检测方法在嵌入式平台上无法实现实时性。
3. 方法
3.1 网络体系结构
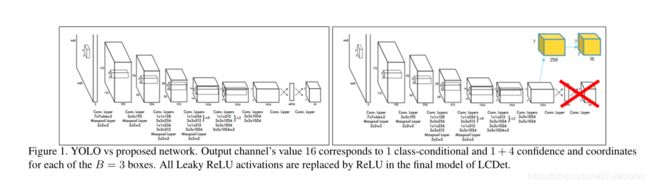
我们提出的模型受到YOLO[23]的启发,YOLO[23]采用单通道检测管道,将包围盒定位和单网络分类相结合。YOLO和LCDet之间的层连接性差异如图1所示。在该模型中,最后两个完全连通的YOLO层被完全卷积层所代替。
其他差异如下所述。与YOLO中的LeakyReLU非线性不同,我们只在最后一层应用ReLU激活。此外,对于输出的最后一层,我们对分类(softmax)输出、置信度(sigmoid)得分和定位(无激活)输出应用不同的激活。YOLO不会在最后一层应用任何非线性。从层连接性的角度来看,CNN架构的后端几乎与YOLO相似;然而,LCDet可以通过完全卷积的方式处理任何输入图像分辨率。
假设在YOLO的第一个完全连接层之前的卷积层被称为空间大小Wf×Hf的最终特征映射。这里,wf和hf表示沿水平和垂直轴的网格中心数。
从同一特征层出发,该模型连接到中输出空间的最终卷积层 网格状图案(Wf×Hf×Channels),如图1所示。每个网格中心与每个B(=3)可能的边界框的C类概率、1个置信分数和4个标量坐标值相关联。与YOLO相似,置信度得分是与地面真值边界框相交的预测因子。最后,我们采用非最大抑制(NMS)保持顶边界框。在推理过程中,检测管道由一个通过网络的前向通道组成。
3.2。培训方法
与Faster-CNN[26]不同,它采用4步交替训练策略来训练区域建议网络(RPN)和检测器网络,我们的检测器网络可以端到端地训练,类似于YOLO[23]。我们应用多部分目标检测损失,如(方程式1)所述,类似于YOLO。

其中,![]() 表示对象是否出现在单元格i中,
表示对象是否出现在单元格i中,![]() 表示单元格i中的第j个边界框预测器负责该预测。损失函数根据网格单元中对象的存在或不存在对分类和定位错误进行不同的惩罚。
表示单元格i中的第j个边界框预测器负责该预测。损失函数根据网格单元中对象的存在或不存在对分类和定位错误进行不同的惩罚。 ![]() 对应于格子单元中的地物包围盒的中心坐标、宽度和高度(如果存在)
对应于格子单元中的地物包围盒的中心坐标、宽度和高度(如果存在)![]() 代表相应的预测,
代表相应的预测,![]() 和
和![]() 表示网格单元i处的地面真实性和预测的客观度的置信分数。
表示网格单元i处的地面真实性和预测的客观度的置信分数。
![]() 和
和![]() 分别表示单元格索引i处对象类c的条件概率,用于地面真实性和预测。我们使用类似的设置来最小化YOLO的目标检测损失,并使用
分别表示单元格索引i处对象类c的条件概率,用于地面真实性和预测。我们使用类似的设置来最小化YOLO的目标检测损失,并使用![]() 和
和![]() 的值。。
的值。。
此外,我们还应用sigmoid激活预测信心得分。信心得分应该在[0,1]内,因为它是理想的IOU预测因子。我们使用softmax进行类预测。然而,对于YOLO型单类检测的特殊情况,我们对网络输出的一类预测采用了sigmoid激活。
该模型以448×448帧为输入,在每个S×S非重叠网格单元上对可能目标的类别类型和位置进行训练和回归。(该模型可以使用任何分辨率的图像作为输入)对于每个网格单元,该模型输出类条件概率以及K个边界框及其相关的置信度得分。在YOLO中,我们认为网格单元的负边界框是K盒中的一个,预测区域和地面实数区域在联合上共享最大交集。在训练过程中,我们同时优化分类和定位误差(方程1)。对于每个网格单元,仅当对象出现在该单元中时,我们才将责任边界框相对于地面真实性的定位误差最小化。
3.3条。检测特定层
在Wf×Hf×Chf尺寸的特征层中,YOLO[23]采用了两个完全连接的层。为了简单起见,我们将这两个层一起表示为YLDet。我们用ConvDet表示模型的最后两个卷积层。
YOLO的输入特征映射大小为7×7×1024。![]() 因此,YLDet中的参数数目约为269×106。ConvDet中的第一个卷积层有Chd1=256个参数。对于相同的特征映射大小和输出网格中心数,ConvDet只需要
因此,YLDet中的参数数目约为269×106。ConvDet中的第一个卷积层有Chd1=256个参数。对于相同的特征映射大小和输出网格中心数,ConvDet只需要![]() 个参数,即115× less than YOLO.
个参数,即115× less than YOLO.

表1。RPN、ConvDet和YLDet的比较。RPN代表区域建议,cls代表分类。
3.4。量化模型
通常,DSP或专用卷积加速器在定点指令集上操作。关于嵌入式系统的固定点模型(37, 9)存在分类任务的文献。众所周知,8位模型[32]的性能与用于分类的浮点模型[33]一样好。低精度模式下高精度的理由来自这样一个事实:最终激活是一个概率,即在[0,1]间隔内,可以用无符号数字表示,而无需考虑缩放。然而,我们并没有注意到许多关于目标检测任务量化研究的报道,这些研究是对所有目标的坐标进行回归的。对于LCDet的每一层,我们将32位浮点参数转换为8位fixedpointparametersvia[35,31]。整个目标检测模型在每个卷积层累积后,无需从浮点数和定点来回,即可实现8位定点检测。虽然文献存在训练低精度模式[4 ],我们只执行量化的推理。由于训练是离线进行的,因此对训练后的模型进行量化推理更为合理和实用为了量化32位浮点到8位固定点,我们首先在一层上存储最小值和最大值。然后,我们将相对值量化为[0,255]中线性分布的最接近整数。
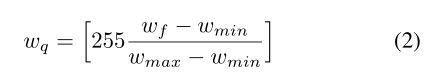
上式中![]() 表示量化变量、浮点变量、最小值和最大值。[·]表示舍入到最接近的整数。
表示量化变量、浮点变量、最小值和最大值。[·]表示舍入到最接近的整数。
虽然我们不知道为什么低精度模式在没有低精度训练的情况下可以很好地工作,但是从我们的实验结果可以看出,回归模型(比如我们的LCDet)也可以很好地进行低精度推理。对于一般的人脸检测应用,量化LCDet在检测精度上与浮点模型相当。
4. 实验结果
在本节中,我们将介绍所提出的算法在浮点模型下的性能,以及在常用的人脸数据库(如FDDB benchmark[12]和Widerface[40]验证分割)上的相关8位量化。我们还提供了该方法在速度、复杂性和内存需求方面的性能分析。虽然,人脸检测作为一个用例被研究,但是该网络不使用任何特定于人脸的处理,例如面部部分或属性。LCDet是一种通用目标探测器。
我们使用转移学习,首先将检测20类PASCAL对象的权值从DarkNet[25]库转换为TensorFlow检查点YOLO PASCAL TF。对于具有基线YOLO的人脸检测[23],我们首先从YOLO-PASCAL TF检查点恢复除最后一层之外的所有参数。然后,我们对其进行微调,以执行1类(仅限人脸)对象检测任务。对于LCDet,我们从YOLO-PASCAL TF恢复除了最后两层以外的所有层的参数。然后用随机权值初始化最后两层,训练LCDet进行单类目标检测。此外,我们在每次卷积之后都会替换所有从YOLO架构到ReLU架构的LeakyReLU激活,除了最后的输出层。有关最后一层中的激活,请参阅第3.2节
我们采用数据增强技术,如缩放和以对象为中心的裁剪,以最小化过度拟合。在我们的实验中,我们使用10-5的初始学习率、32的小批量和8K个时间段。我们使用Adam[14]优化器进行训练。我们使用NVIDIA Tesla K40 GPUs进行训练和测试实验。我们还训练了卷积层的具有批处理规范化的相似模型。训练似乎很早就收敛了,但这并没有提高检测精度。为了使参数的数目最小化,我们使用了没有批处理规范化的模型。
4.1。数据集
FDDB[12]是在无约束条件下进行人脸检测的基准数据集。它包含2845张图片,共5171张脸。数据集提供10倍的固定分区。宽脸是用于人脸检测的较大数据集[40]。它由32203张图片和393703张面孔组成。数据集按61个事件类组织。对于每个事件类,选择40%、10%和50%的数据进行培训、验证和测试。测试拆分的基本事实未披露。在我们的实验中,我们将每个图像缩放到预先确定的大小。对于灰度图像,我们将单通道图像复制三次,使之成为三通道图像。
4.2。检测精度
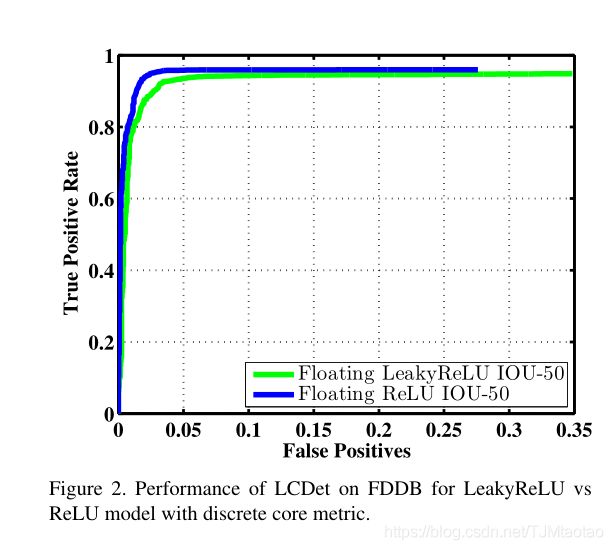
我们首先评估了两种不同非线性的LCDet,如每个卷积层的漏ReLU和ReLU。尽管该模型是由YOLO PASCAL TF初始化的,该TF是用Leaky ReLU激活训练的。通过对两种不同模型和两种不同激活方式下的人脸检测任务进行精细调整,我们发现ReLU激活比leaky-ReLU更好。使用LeakyReLU与ReLU的LCDet的性能如图2所示。接下来,我们在FDDB数据集上评估LCDet及其8位量化模型的性能。模型是在FDDB图像上训练的。这使得我们可以独立于整个系统中的其他组件来研究浮点和定点模型的性能差距。
图3显示了根据[12]采用离散分数评估方法的TP-FP曲线的浮点模型和8位量化模型的性能。实曲线表示标准检测条件下的性能,即与地面真值的联合(IoU)上的50%交集。虚线表示不太严格但实际的检测标准,即40%的IoU和地面真值框。从不动点模型回归的坐标位置与浮点模型预测的偏差较大。当我们增加IoU的检测标准时,这种影响变得更加明显。如图4所示,对于更宽松的IoU标准,如40%IoU,浮点与定点模型表现出相似的检测性能。然而,对于更严格的检测标准,如60%的IoU或更高的IoU,不动点模型的性能似乎显著下降,特别是对于TP-FP曲线上的低假阳性区域
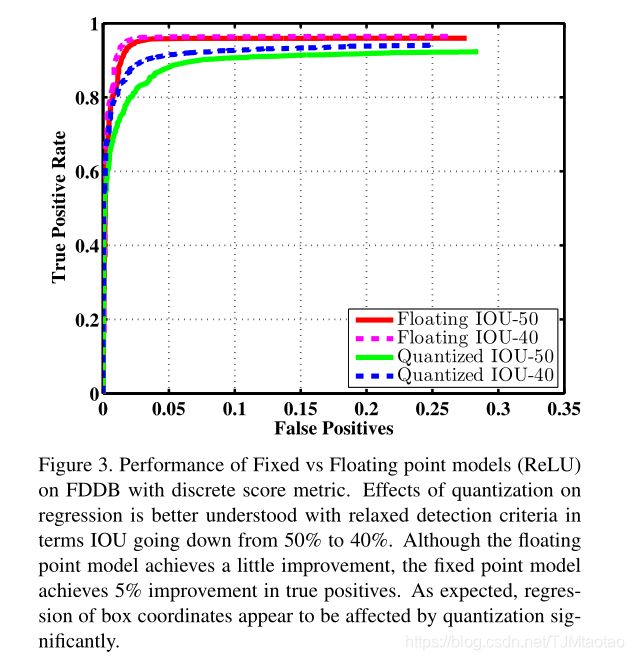
图3。具有离散分数度量的FDDB上固定与浮点模型(ReLU)的性能。量化对回归的影响在宽松的检测标准下得到了更好的理解,IOU从50%下降到40%。虽然浮点模型取得了一些改进,但不动点模型在真正数方面取得了5%的改进。如所料,盒坐标的回归似乎受到量化的显著影响。
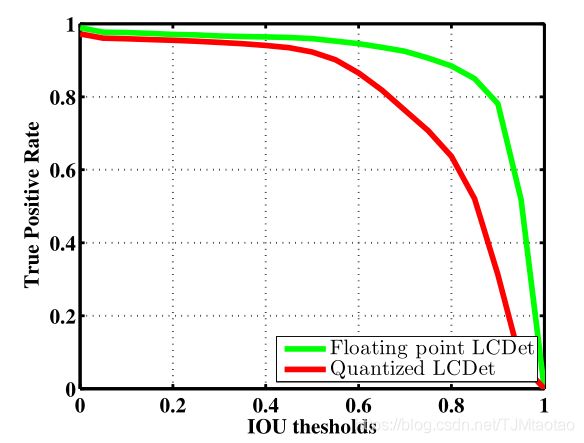
图4。FDDB上不同IoU阈值下浮点模型和固定点模型(ReLU)的性能比较。
移动设备使用人脸检测进行多个基于人脸的质量增强处理,如自动曝光或自动对焦。任何错误的检测都应该受到高度惩罚,因为它们的后果更为昂贵。另一方面,如果检测到的框与实际的面重叠不到50%,某些使用面检测边界框作为输入的最终用例仍然可以以类似的性能工作。在不太严格的IoU操作区域,LCDet不动点模型被认为是与LCDet浮点模型一样好的模型。图4显示这些操作点(高达45%IoU)的检测率与浮动和固定LCDet模型相似。
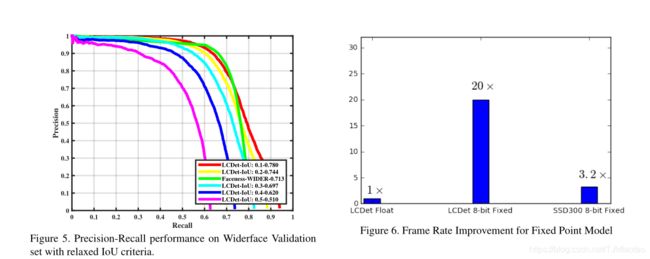
图5。基于松弛IoU准则的宽域验证集的精确召回性能。 图6。固定点模型的帧速率改进
下一步,我们将对LCDet进行宽频面训练。宽面比FDDB多20倍左右。有些脸非常小。我们使用提供的评估工具箱评估LCDet在Widerface验证拆分上的性能。YOLO式训练的一个当前限制是,它假设每个网格位置最多有一个地面真值对象,尽管它可以预测每个网格最多有k个对象。对于448×448大小的训练图像,平均7×7网格,因此只能利用49个地面真实物体。另一方面,在至少200幅训练图像中,Widerface有100多个地面真实人脸。约罗式的训练不能使用所有可用的地面真相。在这种情况下,我们使用每个网格位置具有最高面积的地面真相。相反,更快的RCNN型网络可以使用所有可能的地面真值对象。如图5所示,该模型需要改进定位精度,特别是对于存在于宽空间中的小目标。随着IoU标准的放宽,该模型比其他方法(如Faceness[39])更接近甚至更好的精度。
4.3。复杂性与内存带宽分析
我们首先将darknet[25]YOLO实现转换为基于TensorFLow Slim的实现。我们利用darknet[25]中所有24个卷积层和第一个完全连接层的权重。最终检测层的输出节点数为Wf×Hf×(C+K×5)。对于人脸检测任务,C=1,我们使用K=3进行所有实验。然后利用上述训练方法,我们对人脸检测任务的所有层进行微调。表2展示了这些模型的性能和准确性,以及在强大的GPU上的其他一些最新模型。
LCDet的检测专用模块采用两个卷积层。第一个有4096粒大小为3×3,第二个有16粒大小为1×1。。固定点模型的帧速率改进针对后端特征提取网络,与第3.3节中描述的YOLO相比,LCDet仅检测部分的参数减少了115倍。
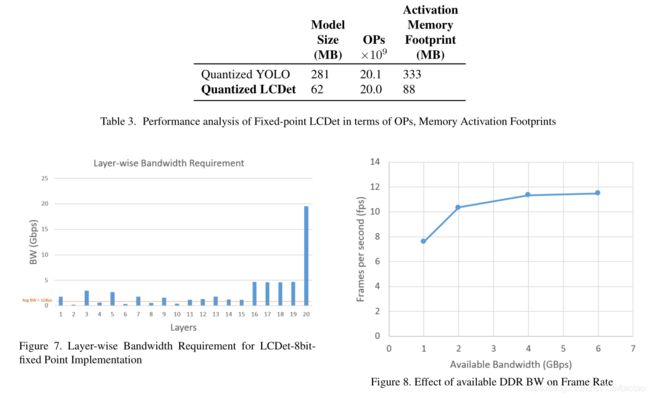
接下来,我们分析并比较了所提出的方法在市场上可买到的Snapdragon平台(如[22])上模拟的基于深度神经网络的目标检测器的性能。Hexagon-DSP包括定点向量扩展,这使得它成为计算机视觉应用的一个有吸引力的计算单元,并且与移动平台上的CPU和gpu相比,它提供了每功耗的性能。我们量化了我们的基线YOLO模型,也量化了所提出的LCDet模型,并比较了它们在相同输入分辨率大小下的相对模型大小和激活内存占用,如表3所示。在图6中,我们比较了以下方法的可实现帧速率:LCDetfloat、LCDet-8bit-fixed和SSD300-8bit-fixed。在定点实现中,激活和权重以8位实现,并映射到DSP的矢量扩展,而在浮点实现中则不使用矢量扩展。通过降低每层的模型大小和带宽(BW),相对于浮点实现,我们实现了接近20倍的帧速率增长。我们的量化模型所需的平均DDR带宽约为1 Gbps,而对于图7所示的某些层,瞬时带宽的范围更大,接近20 Gbps。通常,当多个应用程序在嵌入式系统上运行时,DDR BW会受到限制,并且由于严格的BW限制,帧速率会降低。这如图8所示,其中随着DDR BW从6 Gbps减少到1 Gbps,帧速率下降。
4.4。可视化结果
我们展示了由所提出的LCDet执行的人脸检测的视觉检测结果。检测到的面标记为蓝色矩形。图9到图11展示了FDDB数据集上的人脸检测结果。这些数字显示LCDet可以精确地检测不同大小和姿势的多个面,以适应不同的照明和比例变化。来自Widerface验证数据集的一些困难示例如图12所示。一般来说,LCDet在人脸检测方面表现良好。
该模型的当前限制是,它在紧密地定位小物体在近处挣扎。图13展示了一些例子,其中本地化可能按照严格的50%IoU标准(标记为黄色区域)失败,但是检测到的人脸对于进一步的基于人脸的处理管道来说不是误报。红色区域显示漏检。



5。结论
我们提出LCDet,一个低复杂度的卷积神经网络的对象检测适合嵌入式部署。这是一个统一的本地化和分类模型,灵感来源于[23],它绕过了对象建议瓶颈。LCDet在FDDB上的性能与目前最先进的基于CNN的人脸检测方法相当,同时也是计算效率最高的方法之一。此外,我们还对这个基于TF slim的LCDet模型进行了8位量化,并报告了第一个用于回归的量化模型分析。量化后的LCDet模型性能与浮点模型相当,内存占用减少了4倍。量化使该模型易于在dsp或专用卷积加速器中实现。虽然,这里将人脸检测作为一个用例来研究,但是网络并不是只针对特定人脸检测而优化的。它很容易扩展用于探测任何其他种类物体。
我们知道YOLO9000[24]最近的工作已经成为标准物体检测数据集的最新技术。YOLO9000是YOLO的改进版本。根据经验,LCDet的准确度介于YOLO[23]和YOLO9000[24]之间。另一方面,另一个最近的工作CuffZeDeT(36)在低复杂度的美国有线电视新闻网上实现了KITTI对象检测器的最先进的性能。由于SqueezeNet强大但较小的后端网络,SqueezeDet似乎是最小的对象检测器[11]。在编写本文时,对于同一数据集上的所有这些数据集,都没有报告性能比较。作为未来的工作,我们将评估我们提出的模型与这些方法的相对性能。探索挤压网作为后端,研究其量化性能也很有意义。
致谢
作者要感谢Vikram Gupta和Rakesh Nattoji Rajaram的广泛协助和富有洞察力的评论。
References
[1] K. Ashraf, B. Wu, F. N. Iandola, M. W. Moskewicz, and
K. Keutzer. Shallow networks for high-accuracy road object-
detection. CoRR, abs/1606.01561, 2016. 2
[2] F.-H. Chan. Faster rcnn tensorflow. https://github.
com/smallcorgi/Faster-RCNN_TF. 7
[3] Y .-H. Chen, J. Emer, and V . Sze. Eyeriss: A spatial archi-
tecture for energy-efficient dataflow for convolutional neural
networks. In Proceedings of the 43rd International Sympo-
sium on Computer Architecture, ISCA ’16, pages 367–379,
Piscataway, NJ, USA, 2016. IEEE Press. 2
[4] M. Courbariaux, Y . Bengio, and J. David. Low precision
arithmetic for deep learning. CoRR, abs/1412.7024, 2014. 4
[5] M. Everingham, L. Gool, C. K. Williams, J. Winn, and
A. Zisserman. The pascal visual object classes (voc) chal-
lenge. Int. J. Comput. Vision, 88(2):303–338, June 2010. 2,
4
[6] S. Gidaris and N. Komodakis. Object detection via a multi-
region and semantic segmentation-aware cnn model. In The
IEEE International Conference on Computer Vision (ICCV),
December 2015. 2
[7] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich fea-
ture hierarchies for accurate object detection and semantic
segmentation. CVPR, 2014. 2
[8] R. B. Girshick. Fast R-CNN. CoRR, abs/1504.08083, 2015.
2
[9] P . Gysel. Ristretto: Hardware-oriented approximation of
convolutional neural networks. CoRR, abs/1605.06402,
2016. 4
[10] J. Huang, V . Rathod, C. Sun, M. Zhu, A. Korattikara,
A. Fathi, I. Fischer, Z. Wojna, Y . Song, S. Guadarrama, and
K. Murphy. Speed/accuracy trade-offs for modern convolu-
tional object detectors. CoRR, abs/1611.10012, 2016. 2
[11] F. N. Iandola, M. W. Moskewicz, K. Ashraf, S. Han, W. J.
Dally, and K. Keutzer. Squeezenet: Alexnet-level accuracy
with 50x fewer parameters and <1mb model size. CoRR,
abs/1602.07360, 2016. 8
[12] V . Jain and E. Learned-Miller. Fddb: A benchmark for face
detection in unconstrained settings. Technical Report UM-
CS-2010-009, University of Massachusetts, Amherst, 2010.
1, 2, 4, 5
[13] H. Jiang and E. G. Learned-Miller. Face detection with the
faster R-CNN. CoRR, abs/1606.03473, 2016. 2, 7
[14] D. P . Kingma and J. Ba. Adam: A method for stochastic
optimization. CoRR, abs/1412.6980, 2014. 4
[15] Y . Li, B. Sun, T. Wu, and Y . Wang. Face detection with end-
to-end integration of a convnet and a 3d model. In ECCV,
2016. 2
[16] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. E. Reed.
SSD: single shot multibox detector. CoRR, abs/1512.02325,
2015. 2, 7
[17] H. Mao, S. Yao, T. Tang, B. Li, J. Yao, and Y . Wang.
Towards real-time object detection on embedded systems.
IEEE Transactions on Emerging Topics in Computing, 2016.
2
[18] Modivious. Miriad vpu. https://www.movidius.
com/?49b390. 2
[19] B. Paul. Ssd-tensorflow. https://github.com/
balancap/SSD-Tensorflow. 7
[20] H. Qin, J. Yan, X. Li, and X. Hu. Joint training of cascaded
cnn for face detection. In The IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), June 2016. 2
[21] J. Qiu, J. Wang, S. Yao, K. Guo, B. Li, E. Zhou, J. Y u,
T. Tang, N. Xu, S. Song, Y . Wang, and H. Yang. Going
deeper with embedded fpga platform for convolutional neu-
ral network. In Proceedings of the 2016 ACM/SIGDA Inter-
national Symposium on Field-Programmable Gate Arrays,
FPGA ’16, pages 26–35, New Y ork, NY , USA, 2016. ACM.
[22] Qualcomm. Snapdragon 835 processor, 2017.
https://www.qualcomm.com/products/
snapdragon/processors/835. 2, 6
[23] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. Y ou
only look once: Unified, real-time object detection. In The
IEEE Conference on Computer Vision and Pattern Recogni-
tion (CVPR), June 2016. 1, 2, 3, 4, 8
[24] J. Redmon and A. Farhadi. YOLO9000: better, faster,
stronger. CoRR, abs/1612.08242, 2016. 8
[25] J. C. Redmon. Darknet. 4, 6
[26] S. Ren, K. He, R. B. Girshick, and J. Sun. Faster R-CNN:
towards real-time object detection with region proposal net-
works. In NIPS, pages 91–99, 2015. 2, 3
[27] P . Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus,
and Y . LeCun. Overfeat: Integrated recognition, localiza-
tion and detection using convolutional networks. CoRR,
abs/1312.6229, 2013. 2
[28] Snapdragon-blog. Tensorflow machine learning now opti-
mized for the snapdragon 835 and hexagon 682 dsp, 2017.
https://www.qualcomm.com/news/snapdragon/2017/01/09/
tensorflow-machine-learning-now-optimized-snapdragon-
835-and-hexagon-682. 2
[29] X. Sun, P . Wu, and S. C. H. Hoi. Face detection using
deep learning: An improved faster RCNN approach. CoRR,
abs/1701.08289, 2017. 2
[30] C. Szegedy, S. E. Reed, D. Erhan, and D. Anguelov. Scal-
able, high-quality object detection. CoRR, abs/1412.1441,
2014. 2
[31] TensorFlow. Quantization. https://www.
tensorflow.org/performance/quantization.
4
[32] TensorFlow. Tensorflow for poets.
https://petewarden.com/2015/05/23/why-are-eight-bits-
enough-for-deep-neural-networks/ . 4
[33] V . V anhoucke, A. Senior, and M. Z. Mao. Improving the
speed of neural networks on cpus. In Deep Learning and Un-
supervised Feature Learning Workshop, NIPS 2011, 2011. 4
[34] S. Wan, Z. Chen, T. Zhang, B. Zhang, and K. Wong. Boot-
strapping face detection with hard negative examples. CoRR,
abs/1608.02236, 2016. 2
[35] P . Warden. Pete warden’s blog.
https://petewarden.com/2016/05/03/how-to-quantize-
neural-networks-with-tensorflow/ . 4
[36] B. Wu, F. N. Iandola, P . H. Jin, and K. Keutzer. Squeezedet:
Unified, small, low power fully convolutional neural net-
works for real-time object detection for autonomous driving.
CoRR, abs/1612.01051, 2016. 8
[37] J. Wu, C. Leng, Y . Wang, Q. Hu, and J. Cheng. Quantized
convolutional neural networks for mobile devices. CoRR,
abs/1512.06473, 2015. 4
[38] B. Yang, J. Yan, Z. Lei, and S. Z. Li. Craft objects from
images. CVPR, 2016. 2
[39] S. Yang, P . Luo, C. C. Loy, and X. Tang. From facial parts re-
sponses to face detection: A deep learning approach. In 2015
IEEE International Conference on Computer Vision (ICCV),
pages 3676–3684, Dec 2015. 2, 6
[40] S. Yang, P . Luo, C. C. Loy, and X. Tang. Wider face: A
face detection benchmark. In IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), 2016. 1, 4
[41] J. Y u, Y . Jiang, Z. Wang, Z. Cao, and T. Huang. Unitbox:
An advanced object detection network. In Proceedings of
the 2016 ACM on Multimedia Conference, MM ’16, pages
516–520, New Y ork, NY , USA, 2016. ACM. 2