Transformer的七十二变

©PaperWeekly 原创 · 作者|李明晓
学校|鲁汶大学博士生
研究方向|自然语言处理
自 2017 年 Google 提出 Transformer 后,其在各项 NLP 任务中都取得了 SOTA 的表现。然而其自身的结构缺陷导致了两个问题:
1)由于自注意力机制每次都要计算所有词之间的注意力,其所需计算复杂度为输入长度的平方;2)Transformer 需要事先设定输入长度,这导致了其对于长程关系的捕捉有了一定限制,并且由于需要对输入文档进行分割会导致语意上的碎片化。
近年来许多工作通过对 Transformer 结构的调整优化来缓解以上两个问题。
本文分为两部分,第一部分介绍和比较的三个模型(Star-Transformer 和 BP-Transformer)试图在时间复杂度和空间复杂度上优化 Transformer。第二部分介绍和比较的两个模型(Transformer-XL 和 Compressivetransformer)试图解决上面提出的第二个问题。
对 Transformer 不了解的可先阅读该博客:
https://jalammar.github.io/illustrated-transformer/

更高效的Transformer
1. Star-Transformer

论文标题:Star-Transformer
论文来源:NAACL 2019
论文链接:https://arxiv.org/abs/1902.09113
代码链接:https://github.com/fastnlp/fastNLP
原始的 Transformer 在计算注意力的时候,序列中每个元素要和所有元素进行计算,也是这样的计算方式导致了其复杂度为序列长度的平方。
同时 Transformer 这样所有元素直接相互作用的计算方式没能够很好地使用我们所知道的一些语言序列上的特性,比如语言序列中相邻的词往往本身就会有较强的相关性。
对于这个问题,Star-Transformer 在注意力机制的计算上进行了优化,构建了一个星状的结构,所有序列中直接相邻的元素可以直接相互作用,而非直接相邻的元素则通过中心元素实现间接得信息传递。
具体结构比较如下图所示,左边为正常的 Transformer,右边为 Star-Transformer。

下图为 Star-Transformer 的参数更新算法。在初始化阶段,卫星节点 的初始值为相应的词向量,而中心节点 的初始值为所有卫星节点词向量的平均值。
算法中参数更新分为两步:第一步为卫星节点的更新,第二步为中心节点的更新。两步的更新都是基于多头注意力机制。
对于卫星节点,计算多头注意力机制时只需考虑该节点状态与直接相邻节点,中心节点,该节点词向量和本节点上一时刻状态的信息交互(如下图中 )。
因为中心节点担负着所有卫星节点之间的信息交互,因此中心节点在更新时须与自己上一时刻的信息和所有卫星节点进行信息交互。同时为了表示位置信息,在卫星节点中还必须拼接上表示位置信息的可学习的向量。
该模型在使用中,针对序列的下游任务使用卫星节点的输出,而针对语言推理文本分类这种需要整个句子的任务则可以使用中心节点的输出。
作者的实验中表明,该非直接的联系方式同样能够学习到长程联系,同时在一些任务上的也取得了比 Transformer 更好的表现。

2. BP-Transformer

论文标题:BP-Transformer: Modelling Long-Range Context via Binary Partitioning
论文来源:NAACL 2019
论文链接:https://arxiv.org/abs/1911.04070
代码链接:https://github.com/yzh119/BPT
BP-Transformer 采用一个层级(从细粒度到粗粒度)的注意力计算机制来改进原始的 Transformer。其能够将 Transformer 在计算注意力时的时间复杂度从 降低到 。
名字中 BP 指的是 Binary partitioning,即二分。在 BP-Transformer 中首先将一整个序列通过二分手段构建为一颗二叉树,二叉树的叶子节点即为序列中的元素值,而中间节点则是序列中的片段。
整个结构可以看为图神经网络,序列元素和序列片段为图中的节点,而节点间的联系为图的边。边分为两种:第一种为 Affiliated Edges 连接片段与组成该片段的叶子节点,另一种为 Contextual Edges 连接叶子节点和与其相关的叶子节点或片段节点。
整个结构如下图所示, 为可学习的相对位置表示, 的下标记第一个数字表示该节点在二叉树中的层级,第二个数据表示为在该层级与叶子节点连接的第几个节点。
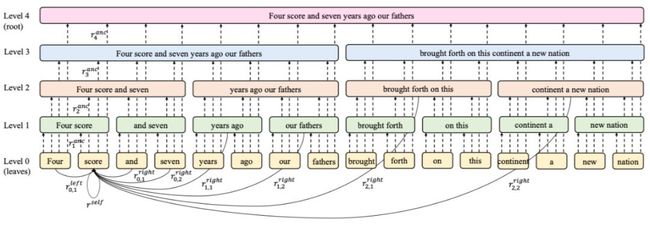
叶子节点的 Contextual Edges 可通过往上递归求得。例如位置为 的元素与其相连构成 Contexttual Edges 的节点为以下节点,不同行代表的是在二叉树上不同层的节点,其中 。
如果 为奇数则 。 为超参数,表示二叉树中每个层级由多少个节点与叶子节点连接。

构建完整个图后,该模型可通过以下算法更新参数:

其中 GSA (Graph Self-Attention) 为:
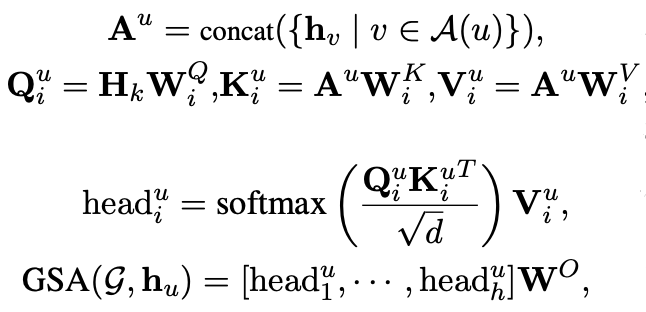
加入相对位置后,注意力的计算可修正为以下公式:

A(u) 为所有与 u 节点想连的节点,由上面公式可见 GSA 其实就是多头注意力机制,只是相比原始 Transformer 计算一个节点与所有节点的注意力,这里只计算节点与其相邻节点的注意力,而因为在二叉树中有跨层次的节点连接即有自节点元素和中间节点元素(片段)的连接,就实现在计算不同粒度下的注意力。
该模型在初始化时,叶子节点初始化为相应的词向量,而片段节点则初始化为零。在针对像语言模型这种序列型的下游任务中,可使用叶子节点的输出,而针对像文本分类等需要用的整个句子的则使用二叉树根节点的输出。
作者在多个任务中测试,结果表明相比原始的注意力计算方式,该模型在长文本任务中取得了更好的表现。

学习更长语义联系的Transformer
1. Transformer-XL

论文标题:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
论文来源:ACL 2019
论文链接:https://arxiv.org/abs/1901.02860
代码链接:https://github.com/kimiyoung/transformer-xl
相比原始 Transformer,Transformer-XL 有以下两个变化:1)引入循环机制,使得新模型能够学习到更长的语义联系;2)抛弃绝对位置表示,采用相对位置表示。
1.1 循环机制
在原始 Transformer 中,每个序列的计算相互独立,因此也导致了其只能够学习到同个序列内的语义联系。而在 Transformer-XL 中,每个序列计算后的隐状态会参与到下一个序列的计算当中,使得模型能够学习到跨序列的语义联系。
如下图所示,左边为原始 Transformer,右边为 Transformer-XL。

相比原始 Transformer,Transformer-XL 模型的计算当中加入绿色连线,使得当层的输入取决于本序列和上一个序列前一层的输出。具体计算公式如下:
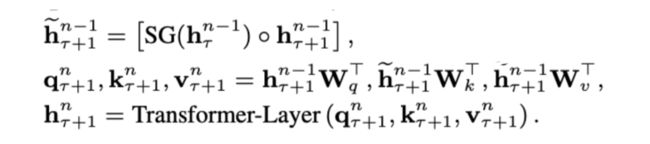
其中 h 为隐藏层,n 为层数, τ 表示序列数,W 为模型参数,° 表示矩阵拼接。SG 意为 stop-gradient,即停止梯度计算,这样虽然在计算中运用了前一个序列的计算结果,但是在反向传播中并不对其进行梯度的更新。
式子一:将上一序列上一层隐状态与本序列上一层隐状态进行矩阵拼接,这也是 Transformer-XL 实现循环机制的关键。
式子二:计算注意力机制所需的 q,k,v。与原始 Transformer 不同的是 k,v 的计算是取决于由式一得到的隐状态,而 q 则是只含有本序列的信息。在注意力的计算中,q 与 k,v 的相互作用让模型实现了跨序列的语义学习。
式子三:常规的 Transformer 层计算。
Transformer-XL 通过引入跨层的循环机制,使得模型能够学习到跨序列的语义信息。这样跨层的方式也使得其能够学习到的语义长度受限于网络深度,具体依赖关系为 N*(L-1) 用大 O 表示可近似为 O(N*L),N 为网络深度,L 为序列长度。如下图所示,序列长度为 4,网络深度为 3。

1.2 相对位置编码
由于注意力机制忽视了位置信息,因此在 Transformer 中需要加入位置编码。原始 Transformer 采用了正弦/余弦函数来编码绝对位置信息。然而在 Transformer-XL 中,若采用和 Transformer 一样的绝对位置编码,那么不同序列间同个位置会得到同样的编码。
因此这种方法在 Transformer-XL 中行不通,为了解决这个问题 Transformer-XL 采用了相对位置编码。
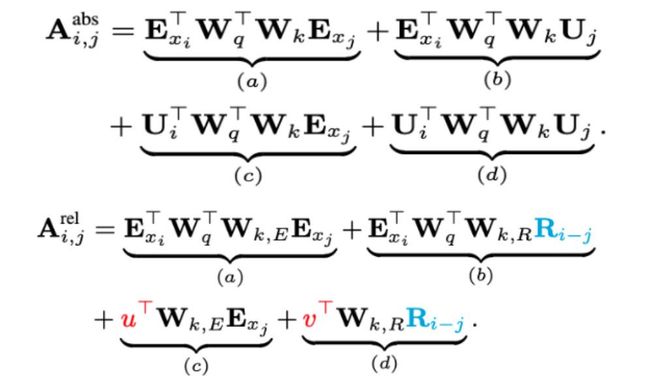
以下公式和分别为原始 Transformer 和 Transformer-XL 中注意力的计算公式。在其中 E 表示词的 Embedding,而 U 表示绝对位置编码。在中 R 为相对位置表示,该相对位置表示也是一个正弦函数表示。
相比,除了用相对位置表示 R 替代了绝对位置表示 U 后,还用两个可学习参数 u 和 v 替代了中的 query 位置的映射,同时将原本对 key 的映射矩阵分成两组矩阵和,分别生成基于内容的 key 向量和基于位置的 key 向量。
替换后中四项分别代表:(a) 基于内容的寻址;(b) 基于内容的位置偏差;(c) 全部内容偏差;(d) 全局位置偏差。
采用相对位置编码后,Transformer-XL 具体的计算公式如下:

2. Compressive Transformer

论文标题:Compressive Transformers for Long-Range Sequence Modelling
论文来源:ICLR 2020
论文链接:https://arxiv.org/abs/1911.05507
为了增加 Transformer 可以学习到的语义长度,Compressiv Transformer 在原 Transformer 的结构上增加了一个记忆模块和一个压缩记忆模块。
每一个序列计算后其隐状态会被放入记忆模块中,然后记忆模块中的部分原有记忆会被压缩然后放入压缩记忆模块中,这时压缩记忆模块中的部分记忆则会被抛弃掉。
如下图所示,压缩记忆模块和记忆模块维度皆为 6,而序列长度为 3。箭头和f表示对记忆模块中的记忆进行压缩并放入压缩记忆模块中。

Compressive Transformer 具体的算法细节如下,其中m表示记忆模块,cm 表示压缩记忆模块,h 为隐状态,d 为 Embedding 维度,为压缩记忆模块长度,为记忆模块长度,c 为压缩常数,l 为层数。
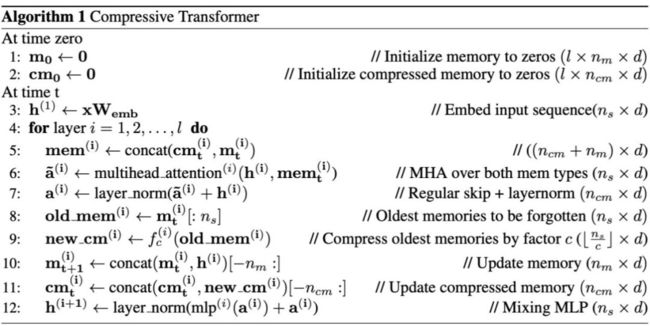
下图为一个简易示意图,红色表示计算注意力,蓝色表示将计算过的序列存入记忆模块和压缩记忆模块过程。

在论文中作者尝试了如下几个不同的压缩函数:1)max/mean pooling;2)1Dconvolution;3)dialated convolutions;4)most-used。实验表明在 WIKITEXT-103 数据集中 1D convolution 表现最好。
同时为了更好的学习压缩函数的参数,模型训练时使用了一个辅助的损失函数(因为若是依赖模型的损失函数,则梯度需要经过很长的时序才能传到存贮的老的记忆,类似于 RNN 里梯队消失问题)。
该损失函数为注意力重建损失函数,旨在测量通过更新后的记忆计算的注意力和使用原本记忆计算的注意力之间的差距。通过最小化该差距来确保有效的压缩信息。

通过引入记忆模块后,Compressive Transformer 能够捕捉的语义长度为 O(L*(+c) 其中为压缩记忆模块长度,为记忆模块长度,c 为压缩常数。
相比较 Transformer-XL 的 O(LN),Compressive Transformer 通过将计算后的序列保存在记忆模块中有效的提高了模型捕捉长程语义的能力。

Reference
BP-Transformer: Modelling Long-Range Context via Binary Partitioning.Zihao Ye, Qipeng Guo, Quan Gan, Xipeng Qiu, Zheng Zhang
Star-Transformer.Qipeng Guo, Xipeng Qiu, Pengfei Liu, Yunfan Shao, Xiangyang Xue, Zheng Zhang
COMPRESSIVE TRANSFORMERS FOR LONG-RANGE SEQUENCE MODELLING, Jack W. Rae Anna Potapenko Siddhant M. Jayakumar Chloe Hillier Timothy P. Lillicrap
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai∗12, Zhilin Yang∗12, Yiming Yang1, Jaime Carbonell1, Quoc V. Le2, Ruslan Salakhutdinov1

点击以下标题查看更多往期内容:
BERT在多模态领域中的应用
浅谈Knowledge-Injected BERTs
从Word2Vec到BERT
后 BERT 时代的那些 NLP 预训练模型
两行代码玩转 Google BERT 句向量词向量
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
