【推荐实践】58招聘推荐排序算法实战与探索
背景
58同城作为中国最大的分类信息网站,为用户提供招聘、租房、二手车及黄页等多种信息服务,其中招聘业务是公司的主要业务之一。招聘平台有千万级的求职者用户,每天有百万级的新增职位发布,如何提高招聘方与求职者的双边匹配效率和用户体验,是招聘数据策略团队一直致力于解决的核心问题。此外,58招聘求职者用户的需求在多个维度都具有个性化的特点,具体表现为
▪ 行业个性化:销售、工人、餐饮、家政、互联网。
▪ 季节个性化:寒暑假、毕业季、春季后返工潮、秋收农忙季。
▪ 地域个性化:一线城市、二线城市、三线城市、农村、南北差异。
▪ 人群个性化:性别差异、年龄差异、学历差异、技能差异、经验差异。
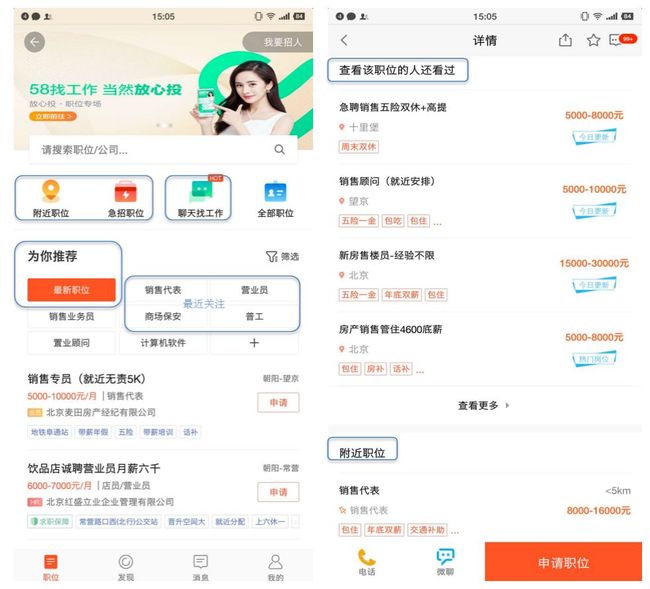
图1 典型招聘推荐场景
为解决招聘平台匹配效率低和缺乏个性化元素的问题,我们开始搭建招聘推荐系统,推荐系统可以帮助用户发现自己需要什么或者让需要的信息主动找到用户,做到“千人千面”。目前招聘业务有几种典型的推荐场景,如图1所示,主要有招聘首页为你推荐、细分标签推荐(最近关注、底部标签)、专区推荐(附近职位、急招职位)、详情页推荐(看了又看、附近在招、同类热门)、聊天找工作等。
招聘推荐中的排序
招聘业务的本质是优化人力资源市场中求职者和企业/HR的双边供求关系。图2展示了58招聘业务链条中双边供给与需求的状态流转,求职者与企业/HR既是供给方又是需求方。
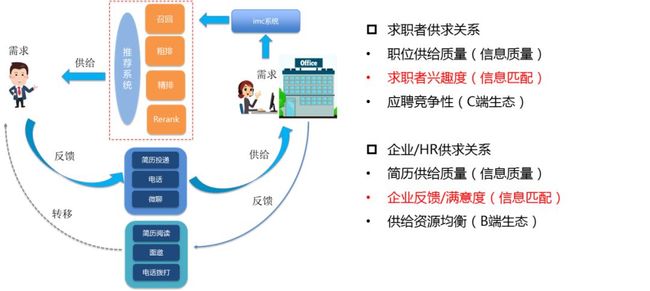
图2 招聘双边供求关系
优化双边供求关系依赖于推荐系统引擎,召回和排序是其中两个核心模块。召回主要负责从海量的职位中筛选出与当前推荐场景匹配的候选集,排序又分为粗排、精排、重排三个部分。
•推荐排序框架
图3展示了招聘推荐的排序框架,粗排基于职位时效性、B端活跃度、职位质量因子等设计规则筛选topK候选集;精排采用机器学习算法对求职者兴趣与企业/HR满意度进行精细化建模、优化双边连接;重排通过实现供给资源均衡、同用户打散、商业因子等策略支持对招聘整体流量的调控。

图3 招聘推荐排序框架
•排序优化目标
图4展示了招聘求职业务中的5个重要环节:流量、展现、单向转化、双边连接、入职履约。目前在入职履约环节无法实现完全闭环(即求职者与招聘方产生双边连接后,求职链条发生中断,求职者是否入职履约也很难追踪),因此算法优化更多聚焦在前4个环节。在不同的业务阶段想要实现的目标是不一样的。业务成长初期,优化各推荐场景的点击率、单向转化率(投递、电话、im);当求职者发起单向转化之后,需进一步考虑提升双边撮合效率,优化双边连接率。此外,从平台内容治理角度需考虑信息质量度,从平台流量合理分配角度需考虑资源分配因子。

图4 排序优化目标
推荐排序算法演进
如图4所示,目前排序优化的主要目标是GCV(Gross Connection Volume)最大化,我们将这个目标拆解为CTR(点击率)、CVR(投递率)、FBR(反馈率)三个预估子模型。因此,本小节重点介绍预估模型的演进。如图4所示,招聘推荐排序中的预估模型经历了5个阶段:人工规则、大规模离散LR、特征工程、非线性模型、深度学习。

图5 预估模型演进
•人工规则
人工规则阶段,通过对招聘业务的理解制定不同规则,比如用户期望类别与职位类别是否相同、职位所属企业是否名企,然后基于人工经验敲定不同规则的权重,线上进行A/B 实验。当线上效果不太满意时,再次修改因子或权重,这种迭代方式效率比较低下,同时也不够科学。主要表现为有限规则刻画匹配关系的局限性,以及不同规则权重定义的随意性。
•大规模离散LR
大规模离散LR阶段,开始考虑采用机器学习建模的方式自动刻画众多规则,并从海量数据中学习规则权重。招聘业务中的目标行为概率预估问题可表示为
![]()
其中,Target表示预估目标(点击率、投递率、反馈率),U表示用户维度、I表示职位维度、C表示上下文。目标行为概率预估模型是机器学习中典型的有监督二分类问题,假设目标行为的概率服从0,1伯努利分布,自然想到使用LogisticRegression模型,表示为
![]()
其中,y是建模目标,X表示特征向量(包含上下文、用户简历、职位+企业、用户交互行为)。LR模型具有很好的记忆能力和可解释性,在实践中会把所有连续值特征离散化,增强连续值特征在不同区间的刻画,同时保证模型对异常数据的稳定性。招聘平台的数据量是亿级别的,并且呈稀疏性,针对大规模离散稀疏特征,我们尝试了不同的优化算法。首先尝试了Spark mllib的mini-Batch SGD和LBFGS,准确性和稀疏性不太理想。然后借鉴google在2012发表的FTRL优化算法在Spark框架下进行工程实践,并行化方面参考文献[1]中提出的ParallelSGD算法,FTRL准确性和模型稀疏性达到相对理想的效果(模型稀疏性在线上serving时至关重要,直接决定线上的计算复杂度和serving的质量),并行FTRL优化的模型也因此成为我们算法迭代的Base模型。
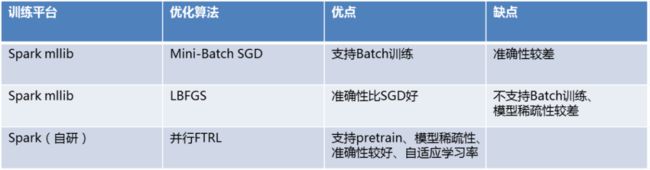
图6 优化算法对比

图7 ParallelSGD算法
LR模型阶段,在线预估服务recjobscore初具雏形,并且打通了特征引擎、离线训练、模型serving、在线打分各个环节。第一版预估模型在APP上线后,职位点击率和投递率均有20%以上的提升。
在线性模型迭代中,算法工程师大部分精力会花在特征工程相关的工作上,特征引擎对特征的迭代效率起着至关重要的作用,因此我们设计开发了自己的特征生产框架。
•特征迭代
数据和特征决定了机器学习的上限,特征工程的目的是最大限度地从原始数据中提取信息以供算法学习。基于特征生产框架,我们在特征挖掘、特征设计及特征优化花了很多精力。招聘推荐的特征体系如图8,包含用户特征、职位特征、上下文特征及组合特征,特征迭代过程中特征挖掘和优化主要从四个方面开展:
▪ 基础特征:尽可能挖掘所有与招聘效果相关的因子,并结合数据分析做特征筛选。
▪ 统计特征:用户偏好及职位/企业相关变量多窗口统计、统计置信度、统计平滑。
▪ 组合特征:基于业务理解人工交叉组合,引入非线性表达、构建用户与职位的匹配度特征(岗位、薪资、距离)。
▪ 文本标签特征:与类目体系相比,基于自然语言内容理解技术构建的招聘标签体系对用户和职位的刻画更加细致和完善,可从多个维度挖掘出更有价值的特征。
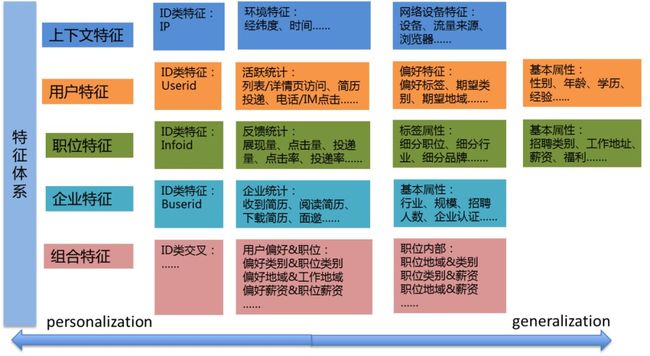
图8 特征体系
•非线性模型
公式(1)在真实的招聘场景中是非线性函数,而LR是线性模型,无法学习原始特征与拟合目标之间的非线性关系,因此在特征迭代阶段引入了大量特征交叉组合。比如男性用户更偏向于找普工/保安类工作、女性用户更偏向于找美容/保姆类工作,此时引入性别与职位类别的特征组合,就能增加LR模型的非线性表达能力。但是人工进行特征组合通常会存在诸多困难,如特征爆炸、特征难以被识别、组合特征难以设计等。业界已有不少自动特征组合的实践经验,基于业界经验,我们先后实践了FM(Factorization Machine)模型和XGoost树模型。
FM算法是由Konstanz大学的Steffen Rendle于2010年最早提出的,旨在解决离散稀疏数据下的特征组合问题,让模型自动地学习特征之间的二阶组合信息,原理上通过线性模型推广为二阶多项式,具体为
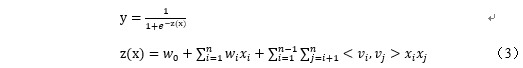
式中二次项包含了二阶特征交叉的所有组合, n是特征数量,xi 表示第i个特征取值,wi表示一阶特征权重,
另外,我们也尝试采用树模型的方式进行自动特征组合。Facebook 在2014年发表的文章中介绍通过GBDT(Gradient Boost Decision Tree)解决LR的自动特征组合问题,Boosting树模型较FM能提取更高维的组合特征。XGBoost树模型是GBDT的升级版,加入正则化项控制模型的复杂度,通过迭代的方式生成新树,并在迭代过程考虑了二阶梯度,性能更佳。因此,我们优先考虑采用XGBoost树进行高维特征组合,并将XGBoost模型的输出进行离散编码,输入大规模离散LR,通过Stacking的方式进行模型融合,算法框架如图8所示,具体步骤为
▪ XGBoost树模型分布式训练,生成树。
▪ XGBoost输出进行离散编码(one-hot)。
▪ 原离散特征级联XGBoost特征,训练LR模型。
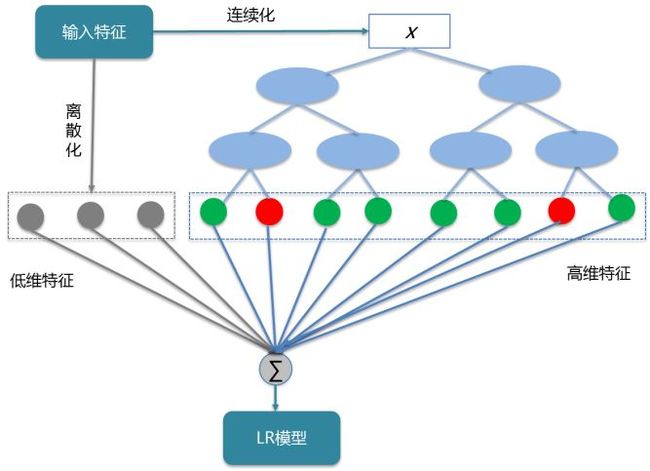
图9 LR+XGBoost融合模型
XGBoost模型训练时,特征的使用方面有一些经验,XGBoost非常适合处理连续特征,但在招聘场景中存在高维稀疏的ID类特征,如职位三级地域,直接输入会增加树的深度,导致过拟合,因此ID类特征的类别数目过大时(>100),会考虑ID类特征连续化。由于招聘推荐中样本数量较大,模型训练需考虑分布式架构,我们使用DMLC(分布式机器学习联盟)开源的XGBoost4j,它支持Spark框架,公司现有的资源能够很好地支撑。
图9给出单棵树的特征编码过程,通过训练生成树后,树中每个分裂节点使用的特征及特征值已知,编码时每条样本在每棵树中都会落入1个叶子节点,对叶子节点进行one-hot编码,最终将所有树的编码级联。最后,将原离散特征与XGBoost树编码的离散特征级联,输入LR模型,仍然采用并行FTRL优化方法学习模型参数。
LR+XGBoost融合模型在APP上线后,累计收益职位点击率提升3%,投递率提升5%。
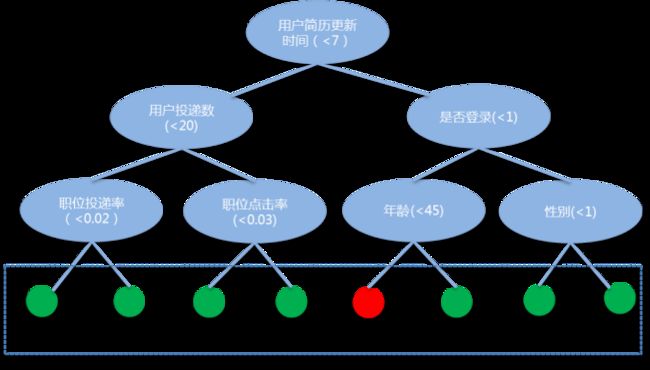
图10 XGBoost特征编码
•深度学习模型
LR模型时代,人工特征组合是效果提升的重点,但耗时耗力,而且会存在特征爆炸、组合特征难以设计的问题。FM与XGBoost虽然能够实现自动特征交叉,但仍然没有跳出特征工程框架,FM能刻画的也仅仅是二阶特征组合,尽管XGBoost能够捕捉更高维度的组合信息,但对高维稀疏ID类特征表达能力较弱,而且如果想得到更高维度的特征表达,树的结构会很复杂,模型缺乏泛化能力。
深度学习具有端对端学习(节省特征工程)、能够从数据中自动学习信息更加丰富的隐式高阶特征表达、泛化能力强的特点。随着数据量的增长、大规模计算能力的提升及深度神经网络算法研究的进展,深度学习在人脸识别、自动驾驶、语音识别及对话系统应用中。目前在业界各公司的推荐、广告业务中也陆续落地,Google 2016年提出wide & deep模型,并应用到Appstore 的下载推荐中,该模型结合LR模型的记忆能力和Deep模型的泛化能力,取得较好的效果。后续Wide&Deep作为基础框架,演化出DeepFM、DeepCross、XdeepFM等一系列模型,这些模型的区别只是在宽度模型中设计不同的特征交叉结构。
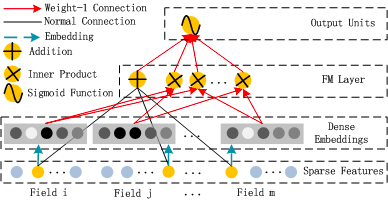
图11 DeepFM算法框架
招聘推荐排序中,为学习更高维、更丰富的特征表达,我们目前已对DeepFM模型进行了探索和验证。DeepFM的算法框架如图11,首先对离散稀疏特征做Embedding;然后分别输入FM层(一阶特征、二阶组合特征)和DNN模型的全连接隐层,两个模块共享Embedding;最后将二者输出级联作为sigmoid函数的输入。实践过程几个关键点总结如下:
▪ Wide部分以帖子属性、用户属性为主,Deep部分以用户偏好、帖子反馈统计为主;
▪ FM求和项展开为隐向量维度的带weight求和,离线效果会有提升。
▪ 连续特征做归一化处理、Batch Normalization能大大加快模型收敛速度。
目前在CVR预估建模中应用DeepFM模型,分别实现了单机版和分布式训练。离线效果与LR+XGBoost模型相比,AUC提升1个百分点;模型部署与在线服务正在进行性能测试。
总结与展望
优化求职者与企业/HR的双边连接效率是58招聘推荐排序中关键环节,为提升双边连接效果,我们将排序建模任务拆解为三个子预估模型:点击率、投递率、反馈率。预估模型的演进经历了人工规则、LR模型、特征挖掘与迭代、非线性模型,以及目前正在实践的深度学习模型。
基于现有工作基础,未来招聘推荐排序建模将围绕以下几个方面开展:
▪ 模型实时性,流式学习实现模型分钟级更新。
▪ Mutitask-learning(多任务学习),多业务目标协同优化。
▪ 深度模型结合attention机制对用户序列行为进行兴趣建模。
▪ 探索Listwise方法,推荐列表排列组合优化。
参考文献
[1] Martin A. Zinkevich, Markus Weimer, Alex Smola & Lihong Li. Parallelized Stochastic Gradient Descent. In NIPS 2010.
[2] 冯扬.在线最优化(Online Optimization)求解.
[3] Rendle S. Factorization machines[C]//Data Mining (ICDM), 2010 IEEE 10th International Conference on. IEEE, 2010: 995-1000.
[4] https://wormhole.readthedocs.io/en/latest/learn/difacto.html
[5] He X, Pan J, Jin O, et al. Practical lessons from predicting clicks on ads at facebook[C]//Proceedings of the Eighth International Workshop on Data Mining for Online Advertising. ACM, 2014: 1-9.
[6] https://XGBoost.readthedocs.io/en/latest/jvm/XGBoost4j_Spark_tutorial.html
[7] Chen T, Guestrin C. XGBoost: A scalable tree boosting system[C]//Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. ACM, 2016: 785-794.
[8] Cheng H T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM, 2016: 7-10.
[9] Wang R, Fu B, Fu G, et al. Deep & cross network for ad click predictions[C]//Proceedings of the ADKDD'17. ACM, 2017: 12.
[10] Lian J, Zhou X, Zhang F, et al. xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems[J]. arXiv preprint arXiv:1803.05170, 2018.
[11] https://www.zhihu.com/people/lambdaji
[12] https://github.com/ChenglongChen/tensorflow-DeepFM
「 更多干货,更多收获 」
知识图谱辅助的个性化推荐系统
【报告分享】2020年中国知识图谱行业研究报告.pdf个性化推荐从入门到精通
【电子书分享】美团机器学习实践.pdf
【白岩松大学演讲】:为什么读书?强烈建议静下心来认真看完
关注我们
智能推荐 个性化推荐技术与产品社区 |
长按并识别关注
|

一个「在看」,一段时光????