Kafka(消息队列原理,kafka定义,Kafka架构原理,kafka架构的工作流程)秒懂的kafka
目录
什么是Kafka?
消息队列原理:
为什么要用Kafka?
kafka的架构
kafka工作流程详解:
什么是Kafka?
kafka是一个分布式消息队列
这个定义意味深长,记住容易,理解不易。首先我们得先知道什么是消息系统,他的原理是什么。
消息队列原理:
关于分布式,我在下面的这篇文章中有所探讨:
https://blog.csdn.net/qq_31807385/article/details/84975720
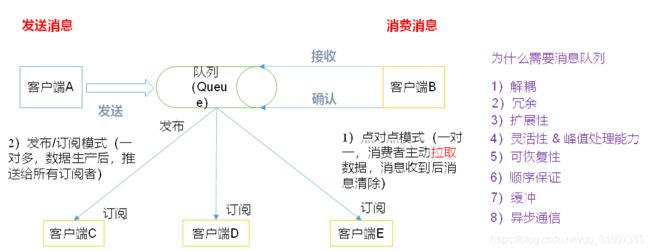
这里客户端A负责生产数据,也被称作是生产者,生产完数据之后,放入到消息队列中,然后客户端B作为消费者去消费数据,之类消费者和生产者之间并不是直接通信的,就好像你不是直接去肥皂工厂买肥皂一样。这里的消息队列有两种模式:点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)发布/订阅模式(一对多)。上图中对比了直接通信和使用消息对列通信之后的优点,下面做出简单的解释:
解耦:消息队列将生产和消费,和数据的存储,分解开来,这样消费者和生产者没有直接关联,耦合性低,扩展性就越好,可以随时增减消费者或者是生产者;
峰值处理:比如kafka设计的是客户取数据,这样消费者可以根据自己的速率来进行调整,而不是消息队列推送,这样还可以避免数据的丢失,同时并发量巨大的时候,直接增加服务器就OK;
顺序保证:如果数据在同一个分区中,那么kafka一定保证数据是顺序的,但是如果不是在一个分区中,不能保证是顺序的,所以如果业务需求要保证消费者消费的数据是有序的,需要在数据输入的时候,就保证这些数据是去往一个分区
异步通信:生产生产了数据,可以存放在消息队列汇中,然后自己继续生产,消费者消费与否,并不影响生产。比如ajax,ajax是浏览器的一个线程,UI也是浏览器的一个线程,UI线程是用来渲染页面的,如果是异步,那么一定是多个线程,UI负责渲染页面,ajax负责和服务器交互,但是ajax在和服务器交互的时候,页面还在显示,这就是异步操作;如果是UI告诉服务器,此时要使用ajax和数据库交互,自己挂起,然后数据返回了,在渲染页面,这个是同步。发一条消息,需要等待结果,发一条消息需要等待结果这就是同步,不需要等待返回结果,就可以干别的事情,就是异步。这里面,生产者生产数据之后,就干别的事情了,消费者什么时候消费和生产者没有任何的关系。打电话的时候,就是同步通信,发短信的时候,就是异步通信。
为什么要用Kafka?
如果不使用kafka进行数据的传输,那么就得使用flume,flume的在进行数据传输的时候,无法较长时间的保存数据,即flume只负责传输数据,而kafka能够较长时间的保存数据。Flume的数据都保存在内存中,数据容易丢失;增加消费者不容易;数据无法较长时间的保留;
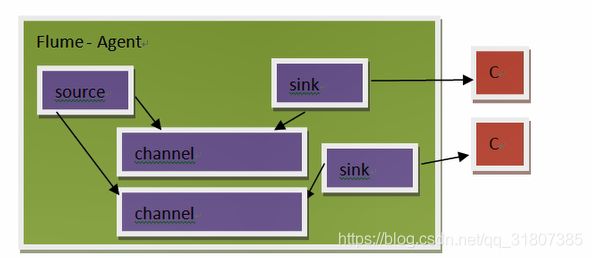
第二个缺点:如果增加一个消费者,就要增加一个sink,不同的数据从同一个channel拉取的数据是不一致的,因此也要相应的增加channel,由此可以看出如果要增加一个Consumer,要增加这么多的东西,(耦合度太高),有些得不偿失。
kafka的架构
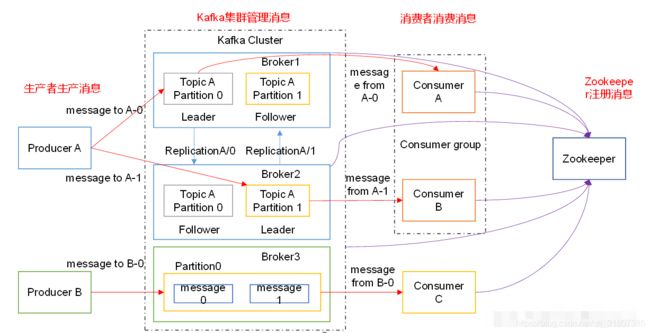
向kafka broker发消息的客户端就是producer; 从kafka broker 取消息的客户端就是 Consumer; 一个toptic可以分布到多个broker上,一个 topic可以分为多个partition,所以topic是以分区的形式分布到了多个broker上的,每个partition是一个有序的队列,单个消费者去消费分区中的队列,以此保证有序,一个分区能够然让两个消费者消费,但是一个消费者不能消费两个分区kafka能够保证一个partition中的消息是顺序的;
kafka是依赖于zookeeper的,kafka在启动时候会写入broker的id的信息,分区的信息,主题等信息到zookeeper Consumer会将消费的偏移量offset记录在zookeeper中,这样能够做到记录当前消费者消费到第几条数据了,下次消费的时候,从消费记录开始 2181是zookeeper的服务端和客户端的通信的端口号。
kafka工作流程详解:
以上图的为例:多台机器构成kafka消息队列的集群,主要是为了负载,每一台服务器叫做broker,就是代理服务器的意思,多个服务broker在一起,就形成了一个集群,为什么这么设计?
①生产者生产数据的时候,理论上说一台机器来接收数据就OK了,但是如果生产者的产能很大,大量的数据涌向一台机器,这台,能干嘛?只能崩溃,就像情绪,小情绪反差出幸福,大情绪,让我们抑郁,所以我们这样做:增加多台机器,然后将大量的数据分区,将数据按照分区放到不同的机器上去,这样单台机制承担的数据压力就小了。这就是所谓的提高负载。
②如上图,生产者生产的消息,一部分分到了1分区,另外一部分分到了 0分区,如此一来,信息没有放在一块,数据量就少了,性能就会提升,当数据到达broker之后 ,可是发过来的数据到底是谁在关心呢?因为消费者不可能消费所有的消息,所以我们将消息划分逻辑主Topic,对不同的消息做一些分类,有了topic的概念,定义了主题之后,将相关的消息放进来就OK了,这样消费者消费的时候,就可以只是消费他关心的数据;这里分区是和主题相关的,比如订单(TopticA),订单的主题中有两个分区,所有就有Topic-A,partition-0,另外一个就是Topic-A,partition-1,这是两个不同的分区,但是从属于一个topic;
③将数据按照分区发送到不同的分区是没有任何的问题的,但是如果某一台机器宕机了,可见数据是不安全的,所以在这种情况下,我们应该给partition分区做一个备份,所以这里有一个replication的操作,将数据做一个副本,为了安全,这个副本应该被放置在不同的机器上,这样就有了leader和follower的概念,这里的副本仅仅是为了备份,读写都只有leader才能够进行,表现在图中,就是生产者的箭头,仅仅指向了leader,同理消费者;
④生产者往集群中存放消息,这个时候消费者就可以消费了,也就是从集群中取消息,这个时候涉及到一个组的概念,在kafka中,消费数据都是按照组为单位来消费的,这就意味着,TopicA中的所有数据都是组拿到的,组内的单个成员去消费不同的分区,这样得到的数据是不一样的,而整个组拿到TopicA的所有数据;对于本图而言,如果有A B C 三个消费者,A会读取p0,B会读取p1 ,C怎么办?这个C什么都不做,一般情况下,消费者中的消费者和分区的个数是保持一致的,这样不会浪费消费者,所以如何来增加消费能力呢?最基本的条件是增加分区。消费者个数和分区个数保持一致。图中的ConsumerC是一个消费者,但是也是一个消费者组;
⑤这里有分区0 和分区1,对于消费者组来说,他无法保证他是先读取到分区0中的数据,还是先读到分区1 中的数据,这里影响的主要因素是网络的原因,但是消费者能够保证的是:同一个分区中数据是有序的,因为消息的内部的实现方式是队列。所以在实际的业务中,如果有排序,就哟啊考虑往一个分区里面放,这里注意,往一个分区里面放,并不是说整个topic有一个分区,一个Topic可以有多个分区。
推荐阅读:
分布式架构下的消息队列:https://blog.csdn.net/qq_31807385/article/details/84975720