Java8新特性Stream流
前言:学习之前建议先学习Lambda表达式
一、创建Stream
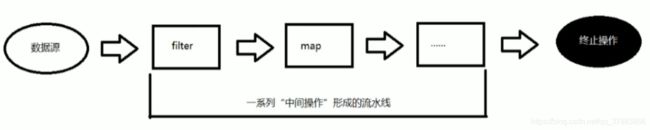
Stream的作用图解

流的概念:
流是数据渠道、用于操作数据源(集合数组等)所生成的元素序列。
集合强调的是数据; 流强调的是计算;
注意点:
Stream自己不存储数据;
Stream不会改变源对象。并且会返回一个持有新结果的Stream;
Stream是延迟执行的,即需要该数据时才执行,类似于框架的懒加载机制;
Stream操作的三个步骤
- 1、创建Stream
一个数据源(集合、数组),获取一个流 - 2、中间操作
一个中间操作链,对数据进行处理 - 3、终止操作
一个终止操作,执行中间操作链,并产生结果
代码演示:
创建流的四种方式
import org.junit.Test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.stream.Stream;
/**
* Stream的三个操作步骤
* 1、创建Stream
* 2、中间操作
* 3、终止操作
*/
public class TestStream01 {
/**
* 创建Stream
*/
@Test
public void test1() {
// 1、通过Collection集合提供的stream()方法或parallelStream()获取集合流
ArrayList<String> list = new ArrayList<>();
Stream<String> stream1 = list.stream();
// 2、可以通过Arrays中的静态方法 获取数组流
Integer[] array = new Integer[10];
Stream<Integer> stream2 = Arrays.stream(array);
// 3、通过Stream类中的静态方法创建流
Stream<String> stream3 = Stream.of("aa", "bb", "cc");
Stream<Integer> stream31 = Stream.of(array);
// 4、创建无限流
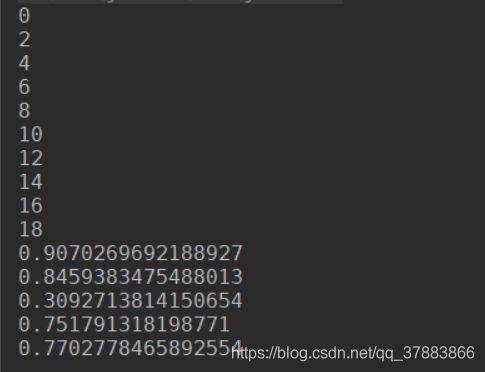
Stream<Integer> stream4 = Stream.iterate(0, (x) -> x + 2);
// 终止操作
stream4.limit(10).forEach(System.out::println);
// 创建无限流2 生成
Stream<Double> generate = Stream.generate(() -> Math.random());
generate.limit(5).forEach(System.out::println);
}
}
程序执行结果:
二、Stream筛选与切片

2.1、filter过滤操作
List<Employee> list = Arrays.asList(
new Employee("张三", 13, 5000.00),
new Employee("李四", 13, 6000.00),
new Employee("王五", 15, 7000.00),
new Employee("赵六", 16, 8000.00)
);
/**
* 操作Stream
*/
@Test
public void test1() {
// 过滤年龄大于15岁员工
Stream<Employee> stream = list.stream()
.filter((e) -> e.getAge() > 15);
stream.forEach(System.out::println);
}
输出结果:
Employee{name=‘赵六’, age=16, salary=8000.0}
2.2、distinct去重操作
List<Employee> list = Arrays.asList(
new Employee("张三", 13, 5000.00),
new Employee("李四", 13, 6000.00),
new Employee("王五", 15, 7000.00),
new Employee("赵六", 16, 8000.00),
new Employee("赵六", 16, 8000.00)
);
@Test
public void test4() {
// 过滤薪资大于5000的员工
Stream<Employee> stream = list.stream()
.filter((e) -> e.getSalary() > 5000)
// 跳过前两个
.skip(2)
// 去重
.distinct();
stream.forEach(System.out::println);
}
程序运行结果:
Employee{name=‘赵六’, age=16, salary=8000.0}
注意:去重操作依赖于 equals()和hashCode()方法 所以Employee类需要重写这两个方法distinct才会生效
2.3、limit截断操作
@Test
public void test2() {
// 过滤薪资大于5000的员工
Stream<Employee> stream = list.stream()
.filter((e) -> e.getSalary() > 5000)
//取2个
.limit(2);
stream.forEach(System.out::println);
}
运行结果:
Employee{name=‘李四’, age=13, salary=6000.0}
Employee{name=‘王五’, age=15, salary=7000.0}
2.4、skip跳过操作
@Test
public void test3() {
// 过滤薪资大于5000的员工
Stream<Employee> stream = list.stream()
.filter((e) -> e.getSalary() > 5000)
// 跳过前两个
.skip(2);
stream.forEach(System.out::println);
}
运行结果:
Employee{name=‘赵六’, age=16, salary=8000.0}
三、Stream映射(在工作中常用)
映射
map----接收Lambda,将元素转换成其他形式或者提取信息。接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
下面举例说明:
@Test
public void test5() {
List<String> list = Arrays.asList("aaa", "bbb", "ccc", "ddd", "eee");
list.stream()
// 将所有集合元素转大写
.map((str)->str.toUpperCase())
.forEach(System.out::println);
List<Employee> employees = Arrays.asList(
new Employee("张三", 13, 5000.00),
new Employee("李四", 13, 6000.00),
new Employee("王五", 15, 7000.00),
new Employee("赵六", 16, 8000.00),
new Employee("赵六", 16, 8000.00)
);
// 提取所有员工的名字
employees.stream()
.map(Employee::getName)
.forEach(System.out::println);
}
运行结果:
AAA
BBB
CCC
DDD
EEE
张三
李四
王五
赵六
赵六
flatMap----接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流
举例说明map 与 flatMap区别
使用map
@Test
public void test6() {
List<String> list = Arrays.asList("aaa", "bbb", "ccc", "ddd", "eee");
Stream<Stream<Character>> stream = list.stream().map(TestStream02::filterCharacter);
// 这里需要两次forEach才能取出数据
stream.forEach((sm)->{
sm.forEach(System.out::println);
});
}
public static Stream<Character> filterCharacter(String str) {
List<Character> list = new ArrayList<>();
for (char ch : str.toCharArray()) {
list.add(ch);
}
return list.stream();
}
使用flatMap
@Test
public void test7() {
List<String> list = Arrays.asList("aaa", "bbb", "ccc", "ddd", "eee");
Stream<Character> stream = list.stream().flatMap(TestStream02::filterCharacter);
// 这里只需要一次forEach就能取出数据
stream.forEach(System.out::println);
}
public static Stream<Character> filterCharacter(String str) {
List<Character> list = new ArrayList<>();
for (char ch : str.toCharArray()) {
list.add(ch);
}
return list.stream();
}
运行结果:
a
a
a
b
b
b
c
c
c
d
d
d
e
e
e
四、排序 、查找、匹配
4.1、排序
自然排序Comparable
定制排序Comparator
@Test
public void test8() {
List<String> list = Arrays.asList("ccc", "bbb", "aaa", "ddd", "eee");
// 自然排序
list.stream().sorted().forEach(System.out::println);
List<Employee> employees = Arrays.asList(
new Employee("张三", 13, 5000.00),
new Employee("李四", 13, 6000.00),
new Employee("王五", 15, 7000.00),
new Employee("赵六", 16, 3000.00),
new Employee("赵六", 16, 8000.00)
);
// 自定义排序
employees.stream().sorted((e1,e2)->{
// 先根据年龄排序 升序
if(e1.getAge().equals(e2.getAge())){
// 年龄如果相同则根据薪水排序 升序
return e1.getSalary().compareTo(e2.getSalary());
}else {
return e1.getAge().compareTo(e2.getAge());
}
}).forEach(System.out::println);
}
运行结果
aaa
bbb
ccc
ddd
eee
Employee{name=‘张三’, age=13, salary=5000.0}
Employee{name=‘李四’, age=13, salary=6000.0}
Employee{name=‘王五’, age=15, salary=7000.0}
Employee{name=‘赵六’, age=16, salary=3000.0}
Employee{name=‘赵六’, age=16, salary=8000.0}
4.2、查找与匹配
allMatch——检查是否匹配所有元素
anyMatch——检查是否至少匹配一个元素
noneMatch——是否没有匹配所有元素
findFirst——返回第一个元素
findAny——返回当前流中的任意元素
count——返回流中元素的总个数
max——返回流中最大值
min——返回流中最小值
@Test
public void test9() {
List<Employee> employees = Arrays.asList(
new Employee("张三", 13, 5000.00, Employee.Status.BUSY),
new Employee("李四", 13, 6000.00, Employee.Status.FREE),
new Employee("王五", 15, 7000.00, Employee.Status.VOCATION),
new Employee("赵六", 16, 3000.00, Employee.Status.BUSY),
new Employee("赵六", 16, 8000.00, Employee.Status.VOCATION)
);
boolean allMatch = employees.stream()
.allMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
// 是否状态都是BUSY false
System.out.println(allMatch);
boolean anyMatch = employees.stream()
.anyMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
// 是否至少有一个状态是BUSY true
System.out.println(anyMatch);
boolean noneMatch = employees.stream()
.noneMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
// 是否没有一个状态是BUSY false
System.out.println(noneMatch);
Optional<Employee> first = employees.stream()
.sorted((e1, e2) -> {
return Double.compare(e1.getSalary(), e2.getSalary());
})
.findFirst();
// 是否没有一个状态是BUSY false
System.out.println(first.get());
// 随机找一个状态是BUSY的人
Optional<Employee> optional = employees.stream().filter(e -> e.getStatus().equals(Employee.Status.FREE))
.findAny();
System.out.println(optional.get());
// 类似于SQL函数的几个streamAPI
// 获取stream中元素个数
long count = employees.stream().count();
System.out.println(count);
// 获取stream中按照特定规则比较的最大值的元素
Optional<Employee> max = employees.stream().max((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()));
System.out.println(max.get());
// 获取员工中最低工资
Optional<Double> min = employees.stream().map(Employee::getSalary)
.min(Double::compare);
System.out.println(min.get());
}
运行结果:
false
true
false
Employee{name=‘赵六’, age=16, salary=3000.0, status=BUSY}
Employee{name=‘李四’, age=13, salary=6000.0, status=FREE}
5
Employee{name=‘赵六’, age=16, salary=8000.0, status=VOCATION}
3000.0
五、规约(reduce)、收集(重要方法)
5.1、规约(reduce)
// 归约reduce(T identity,BinaryOperator) 可以将流中元素结合起来,得到一个值
@Test
public void test10() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer sum = list.stream()
// 第一个参数是 起始值 第二个参数运算操作
.reduce(5, (x, y) -> x + y);
// 运算的是 5+1+2+3+...+10 =60
System.out.println(sum);
List<Employee> employees = Arrays.asList(
new Employee("张三", 13, 5000.00, Employee.Status.BUSY),
new Employee("李四", 13, 6000.00, Employee.Status.FREE),
new Employee("王五", 15, 7000.00, Employee.Status.VOCATION),
new Employee("赵六", 16, 3000.00, Employee.Status.BUSY),
new Employee("赵六", 16, 8000.00, Employee.Status.VOCATION)
);
// 计算工资总和
Optional<Double> doubleOptional = employees.stream()
.map(Employee::getSalary)
.reduce(Double::sum);
System.out.println(doubleOptional.get());
}
运行结果:
60
29000.0
5.2、收集(常用重要方法list转list或者set,list转map)

//收集 collect 将流转换为其他形式。
// 接收一个collector接口的实现,用于给Stream中元素汇总的方法
@Test
public void test11() {
List<Employee> employees = Arrays.asList(
new Employee("张三", 13, 5000.00, Employee.Status.BUSY),
new Employee("李四", 13, 6000.00, Employee.Status.FREE),
new Employee("王五", 15, 7000.00, Employee.Status.VOCATION),
new Employee("赵六", 16, 3000.00, Employee.Status.BUSY),
new Employee("赵六", 16, 8000.00, Employee.Status.VOCATION)
);
// 收集集合中的名字到list中
List<String> names = employees.stream()
.map(Employee::getName)
.collect(Collectors.toList());
names.forEach(System.out::println);
System.out.println("--------------------");
// 收集集合中的名字到set中 去重
Set<String> set = employees.stream()
.map(Employee::getName)
.collect(Collectors.toSet());
set.forEach(System.out::println);
System.out.println("--------------------");
// 也可以收集到一些特殊的集合中
// 收集到HashSet中
HashSet<String> hashSet = employees.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(HashSet::new));
hashSet.forEach(System.out::println);
// 收集到LinkedHashSet中
LinkedHashSet<String> linkedHashSet = employees.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(LinkedHashSet::new));
// 收集到LinkedList中
LinkedList<String> linkedList = employees.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(LinkedList::new));
System.out.println("------------------------");
// 收集计算总数
Long count = employees.stream()
.collect(Collectors.counting());
System.out.println(count);
// 工资平均值
Double avg = employees.stream()
.collect(Collectors.averagingDouble(Employee::getSalary));
System.out.println(avg);
// 工资总和
DoubleSummaryStatistics salSum = employees.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary));
System.out.println(salSum);
// 最大值
Optional<Employee> employeeOptional = employees.stream()
.collect(Collectors.maxBy((e1, e2) -> {
return Double.compare(e1.getSalary(), e2.getSalary());
}));
System.out.println(employeeOptional.get());
// 最小值
Optional<Employee> minEmployee = employees.stream()
.collect(Collectors.minBy((e1, e2) -> {
return Double.compare(e1.getSalary(), e2.getSalary());
}));
System.out.println(minEmployee.get());
}
List转Map
- 一、利用Collectors.toMap方法进行转换
public Map
return accounts.stream().collect(Collectors.toMap(Account::getId, Account::getUsername));
}
其中第一个参数就是key,第二个参数就是value的值。
- 二、 收集对象实体本身
在开发过程中我们也需要有时候对自己的list中的实体按照其中的一个字段进行分组(比如 id ->List),这时候要设置map的value值是实体本身。
public Map
return accounts.stream().collect(Collectors.toMap(Account::getId, account -> account));
}
account -> account是一个返回本身的lambda表达式,其实还可以使用Function接口中的一个默认方法 Function.identity(),这个方法返回自身对象,更加简洁
重复key的情况。
在list转为map时,作为key的值有可能重复,这时候流的处理会抛出个异常:Java.lang.IllegalStateException:Duplicate key。这时候就要在toMap方法中指定当key冲突时key的选择。(这里是选择第二个key覆盖第一个key)
public Map
return accounts.stream().collect(Collectors.toMap(Account::getUsername, Function.identity(), (key1, key2) -> key2));
}
5.3、分组(常用)
// 分组
@Test
public void test12(){
// 按照状态分组
List<Employee> employees = Arrays.asList(
new Employee("张三", 13, 5000.00, Employee.Status.BUSY),
new Employee("李四", 13, 6000.00, Employee.Status.FREE),
new Employee("秀逗", 13, 6000.00, Employee.Status.FREE),
new Employee("王五", 15, 7000.00, Employee.Status.VOCATION),
new Employee("赵六", 16, 3000.00, Employee.Status.BUSY),
new Employee("赵六", 16, 8000.00, Employee.Status.VOCATION)
);
Map<Employee.Status, List<Employee>> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getStatus));
Set<Map.Entry<Employee.Status, List<Employee>>> entries = map.entrySet();
for (Map.Entry<Employee.Status, List<Employee>> entry : entries) {
System.out.println(entry.getKey()+"->"+entry.getValue());
}
System.out.println("--------------------------");
// 多条件分组(多级分组) 先状态 再年龄 再薪资
Map<Employee.Status, Map<Integer, Map<Double, List<Employee>>>> map1 = employees.stream()
.collect(Collectors.groupingBy(Employee::getStatus,
Collectors.groupingBy(Employee::getAge,
Collectors.groupingBy(Employee::getSalary))));
Set<Map.Entry<Employee.Status, Map<Integer, Map<Double, List<Employee>>>>> entries1 = map1.entrySet();
for (Map.Entry<Employee.Status, Map<Integer, Map<Double, List<Employee>>>> statusMapEntry : entries1) {
System.out.println(statusMapEntry.getKey()+"->"+statusMapEntry.getValue());
}
}
运行结果
FREE->[Employee{name='李四', age=13, salary=6000.0, status=FREE}, Employee{name='秀逗', age=13, salary=6000.0, status=FREE}]
BUSY->[Employee{name='张三', age=13, salary=5000.0, status=BUSY}, Employee{name='赵六', age=16, salary=3000.0, status=BUSY}]
VOCATION->[Employee{name='王五', age=15, salary=7000.0, status=VOCATION}, Employee{name='赵六', age=16, salary=8000.0, status=VOCATION}]
--------------------------
FREE->{13={6000.0=[Employee{name='李四', age=13, salary=6000.0, status=FREE}, Employee{name='秀逗', age=13, salary=6000.0, status=FREE}]}}
BUSY->{16={3000.0=[Employee{name='赵六', age=16, salary=3000.0, status=BUSY}]}, 13={5000.0=[Employee{name='张三', age=13, salary=5000.0, status=BUSY}]}}
VOCATION->{16={8000.0=[Employee{name='赵六', age=16, salary=8000.0, status=VOCATION}]}, 15={7000.0=[Employee{name='王五', age=15, salary=7000.0, status=VOCATION}]}}
也可以这样将多个条件拼成一个进行分组
List<Employee> employees = Arrays.asList(
new Employee("张三", 13, 5000.00, Employee.Status.BUSY),
new Employee("李四", 13, 6000.00, Employee.Status.FREE),
new Employee("秀逗", 13, 6000.00, Employee.Status.FREE),
new Employee("王五", 15, 7000.00, Employee.Status.VOCATION),
new Employee("赵六", 16, 3000.00, Employee.Status.BUSY),
new Employee("赵六", 16, 8000.00, Employee.Status.VOCATION)
);
// 根据 状态 年龄 薪资 分组
Map<String, List<Employee>> collect = employees.stream().collect(Collectors.groupingBy(v -> v.getStatus() + "_" + v.getAge() + "_" + v.getSalary()));
Set<Map.Entry<String, List<Employee>>> entries = collect.entrySet();
for (Map.Entry<String, List<Employee>> entry : entries) {
System.out.println(entry.getKey()+"-------->"+entry.getValue());
}
运行结果:
VOCATION_15_7000.0-------->[Employee{name=‘王五’, age=15, salary=7000.0, status=VOCATION}]
BUSY_16_3000.0-------->[Employee{name=‘赵六’, age=16, salary=3000.0, status=BUSY}]
VOCATION_16_8000.0-------->[Employee{name=‘赵六’, age=16, salary=8000.0, status=VOCATION}]
FREE_13_6000.0-------->[Employee{name=‘李四’, age=13, salary=6000.0, status=FREE}, Employee{name=‘秀逗’, age=13, salary=6000.0, status=FREE}]
BUSY_13_5000.0-------->[Employee{name=‘张三’, age=13, salary=5000.0, status=BUSY}]
5.4、分区
// 按工资分组
@Test
public void test13(){
List<Employee> employees = Arrays.asList(
new Employee("张三", 13, 5000.00, Employee.Status.BUSY),
new Employee("李四", 13, 6000.00, Employee.Status.FREE),
new Employee("秀逗", 13, 6000.00, Employee.Status.FREE),
new Employee("王五", 15, 7000.00, Employee.Status.VOCATION),
new Employee("赵六", 16, 3000.00, Employee.Status.BUSY),
new Employee("赵六", 16, 8000.00, Employee.Status.VOCATION)
);
Map<Boolean, List<Employee>> map = employees.stream()
.collect(Collectors.partitioningBy((e) -> e.getSalary() > 5000));
Set<Map.Entry<Boolean, List<Employee>>> entries = map.entrySet();
for (Map.Entry<Boolean, List<Employee>> entry : entries) {
System.out.println(entry.getKey()+"->"+entry.getValue());
}
System.out.println("----------------------");
DoubleSummaryStatistics statistics = employees.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary));
System.out.println(statistics.getSum());
System.out.println(statistics.getAverage());
System.out.println(statistics.getMax());
System.out.println(statistics.getMin());
System.out.println(statistics.getCount());
}
运行结果

false->[Employee{name='张三', age=13, salary=5000.0, status=BUSY}, Employee{name='赵六', age=16, salary=3000.0, status=BUSY}]
true->[Employee{name='李四', age=13, salary=6000.0, status=FREE}, Employee{name='秀逗', age=13, salary=6000.0, status=FREE}, Employee{name='王五', age=15, salary=7000.0, status=VOCATION}, Employee{name='赵六', age=16, salary=8000.0, status=VOCATION}]
----------------------
35000.0
%5.2d5833.333333333333
8000.0
3000.0
6
5.5、连接
// 连接
@Test
public void test14(){
List<Employee> employees = Arrays.asList(
new Employee("张三", 13, 5000.00, Employee.Status.BUSY),
new Employee("李四", 13, 6000.00, Employee.Status.FREE),
new Employee("秀逗", 13, 6000.00, Employee.Status.FREE),
new Employee("王五", 15, 7000.00, Employee.Status.VOCATION),
new Employee("赵六", 16, 3000.00, Employee.Status.BUSY),
new Employee("赵六", 16, 8000.00, Employee.Status.VOCATION)
);
String s = employees.stream()
.map(Employee::getName)
.collect(Collectors.joining(",","首===","===尾"));
System.out.println(s);
}
运行结果
首===张三,李四,秀逗,王五,赵六,赵六===尾