如何在window下使用darknet-yolov4动态库进行目标检测?
0 环境
系统:win 10, 64位
GPU版本:2080Ti
CUDA:10.0
cuDNN:7.4.15
OpenCV:3.0.0
最近一个星期正在研究如何在win10下,使用darkent进行目标检测,为了展示好看,就打算将其做成一个界面(使用QT5)。这个项目我之前是在ubuntu环境下,使用pyqt进行封装成exe文件,但是检测速度不是很快,就使用tensorrt对其进行加速,但是放在windows环境下,发现无法使用tensorrt,最后才发现,原来不支持windows下tensorrt只能使用c++语言,我跪了。最后,无可奈何,又花了一个星期左右时间,从学习QT5,到使用darknet的动态链接库,再到调bug,来来回回花了整整一个星期的时间。tensorrt现在还没有头绪,唉,路漫漫其修远兮,吾将上下而求索。
这一个星期走了不少弯路,除了不少bug,头发也没少掉。趁着刚做完界面,在这里介绍一下如何使用yolov4的动态链接库,一方面方便以后自己可以查看,另一方面,如果有需要的朋友,希望能够给与借鉴,少走弯路,少掉头发。哈哈哈
1 我们需要哪些东西?
我们需要使用darknet的哪些东西?首先,你要去下载darknet,传送门在这。然后可以参考我的上一篇博客,对darknet进行编译。
- yolo_v2_class.hpp
- yolo_cpp_dll.lib
- pthreadGC2.dll
- pthreadVC2.dll
- opencv_world300.dll
- yolo_cpp_dll.dll
(1) 一个头文件
我们需要使用一个头文件 (yolo_v2_class.hpp),这里面存放着darknet用于检测的Detector类,以及它的方法。我们使用darknet进行推理,无非就是实例化一个Detector类,然后调用Detector的detect方法进行推理。所以,我们需要使用yolo_v2_class.hpp头文件,然后将其include在你需要的c++程序中。
这个头文件放在了darnet / include目录下了。

(2) 一个lib文件
在编译器进行链接的时候,需要使用到静态库,将其作为hpp文件和动态库的桥梁。因为hpp文件中一般只有方法的定义,而动态库中有这些方法的实现,我们使用lib文件,告诉编译器hpp文件中的实现方法在哪个动态库中。如果有不理解的,请跳转到这位老哥的博客,可以仔细研究一下。
因为我使用的是GPU版本的,所以我们就需要GPU版本的yolo_cpp_dll.lib。如果你是使用CPU,你可能就需要yolo_cpp_dll_no_gpu.lib了,这里我就不赘述了。yolo_cpp_dll.lib放在darknet / build / darknet / x64目录下。

(3) 四个dll文件
dll文件就是动态链接库。动态链接库中存放着函数的实现,如果没有动态链接库,很多函数就没法使用。动态链接库是在程序运行的时候进行加载的,静态链接库是在程序编译的时候就加载的。如果使用动态链接库,那么打包的exe文件比较小;如果使用静态链接库,打包的exe文件就要大很多。
这四个dll文件的位置就比较分散了。
step1 --> pthreadGC2.dll和pthreadVC2.dll 这两个文件在darknet / 3rdparty / pthreads / bin目录下面。

step2 --> yolo_cpp_dll.dll 这个文件需要你在VS下生成文件才能得到,你可以参考我上篇博客。我的文件位置在这里
C:\Users\Administrator\Desktop\darknet\build\darknet\x64

step3 --> opencv_world300.dll 这个文件和你安装opencv的位置有关。你可以参考我的安装位置,进行查找,我的安装位置是D:\opencv\opencv\build\x64\vc12\bin

2. 如何使用这些东西?
假设我的项目目录是这样的:
---- darknet (项目名称)
---- data (使用的数据)
---- x64 (使用64位系统)
---- Debug
---- Release
--- main.cpp (主程序入口)
(1) yolo_v2_class.hpp
先将这个头文件放置在main.cpp同目录结构下,这样是方便在main.cpp中进行include。这样,在main目录下,我们就可以这样include这个头文件。
// main.cpp文件下
#include "yolo_v2_class.hpp"
(2) yolo_cpp_dll.lib
yolo_cpp_dll.lib文件也放置在main.cpp同目录结构下。我是使用VS 2015编写的QT5界面代码,因此,我们需要手动链接一下静态库。
点击项目,然后右键,选择属性
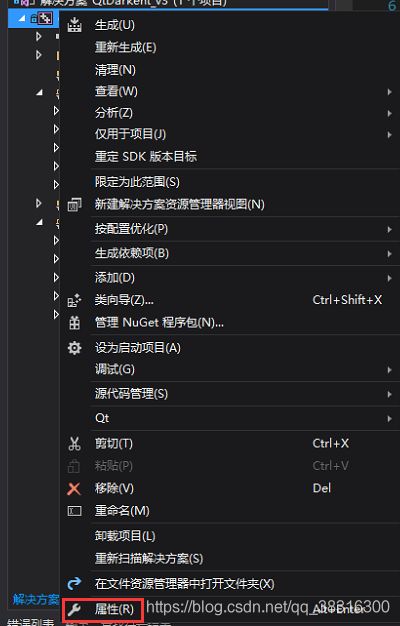
选择链接库 ---> 输入 ---> 附加依赖项,然后在其中输入yolo_cpp_dll.lib

这一步是告诉vs的链接器,我们需要的静态链接库就在同目录下,你要找的静态链接库就是yolo_cpp_dll.lib文件。
(3) 四个dll文件
我们只需要将这四个dll文件放在darnet/x64/Release目录下就行。如果你设置的Debug x64,你就放在darnet/x64/Debug目录下。我使用的是Release x64
![]()
3 在程序中使用darknet进行推理
(1) 在yourDemo.h文件中
.h文件我们一般只放置一些成员变量和方法的声明。在头文件中,我们需要导入yolo_v2_class.hpp文件,然后实例化Detector,并且绘制检测结果。具体内容可以看看下面的代码
// yourDemo.h文件
// 使用opencv进行图片的读取
#include
// 使用yolo_v2_class.hpp文件
#include "yolo_v2_class.hpp"
// 这里面存放着绘制bbox的方法
#include "util.h"
private:
std::string names_file_ = "./data/obj.names";
std::string cfg_file_ = "./cfg/yolov4-obj.cfg";
std::string weights_file_ = "./backup/yolov4-obj_best.weights";
// 检测物体的标签值
std::vector obj_names;
// 实例化检测器
Detector* detector;
public:
// 进行推理并绘制bbox
cv::Mat inference(const cv::Mat);
// 从文件中读取标签值
std::vector objects_names_from_file(std::string);
我将绘制边界框的方法放在了uitls.h文件中了,方法的实现放置在utils.cpp文件中了
// utils.h
#pragma once
#include
#include
#include
#include "yolo_v2_class.hpp"
// 绘制边界框,将绘制的结果保存在mat_img上
void draw_boxes(cv::Mat mat_img, std::vector result_vec, std::vector obj_names, double spendTime, int current_det_fps = -1, int current_cap_fps = -1);
(2) 在cpp文件中
cpp文件主要包括实例化变量,实现相关方法。
// yourDemo.cpp文件
// 下面这两段段码放在构造函数中
detector = new Detector(cfg_file_, weights_file_);
obj_names = objects_names_from_file(names_file_);
// darknet ---> obtain objects names
std::vector objects_names_from_file(std::string const filename) {
std::ifstream file(filename);
std::vector file_lines;
if (!file.is_open()) return file_lines;
for (std::string line; getline(file, line);) file_lines.push_back(line);
std::cout << "object names loaded \n";
return file_lines;
}
// darknet ---> inference --> draw bbox
cv::Mat inference(const cv::Mat img) {
/*
qDebug() << "inference current thread ---> " << QThread::currentThread();
auto start = std::chrono::steady_clock::now();
std::vector result_vec = this->detector->detect(img);
auto end = std::chrono::steady_clock::now();
std::chrono::duration spent = end - start;
qDebug() << " Time: " << spent.count() << " sec \n";
int inference_time = 1 / spent.count();
qDebug() << " FPS: " << inference_time << " \n";
draw_boxes(img, result_vec, obj_names, spent.count(), inference_time, cv::CAP_PROP_FPS);
return img;
*/
qDebug() << "inference current thread ---> " << QThread::currentThread();
// preprocessing
auto det_image = this->detector->mat_to_image_resize(img);
// detect(不包括mat2img数据转换的时间)
auto start = std::chrono::steady_clock::now();
std::vector result_vec = this->detector->detect_resized(*det_image, img.size().width, img.size().height);
auto end = std::chrono::steady_clock::now();
std::chrono::duration spent = end - start;
qDebug() << " Time: " << spent.count() << " sec \n";
int inference_time = 1 / spent.count();
qDebug() << " FPS: " << inference_time << " \n";
draw_boxes(img, result_vec, obj_names, spent.count(), inference_time, cv::CAP_PROP_FPS);
return img;
} 下面是utils.cpp文件内容:
// utils.cpp文件
#include "util.h"
// 方法的实现
void draw_boxes(cv::Mat mat_img, std::vector result_vec, std::vector obj_names, double spendTime, int current_det_fps, int current_cap_fps) {
int const colors[6][3] = { { 1,0,1 },{ 0,0,1 },{ 0,1,1 },{ 0,1,0 },{ 1,1,0 },{ 1,0,0 } };
cv::Scalar color(0, 255, 0);
for (auto &i : result_vec) {
color = cv::Scalar(0, 255, 0);
std::string obj_name = obj_names[i.obj_id];
if (obj_name == "person")
color = cv::Scalar(255, 0, 255);
cv::rectangle(mat_img, cv::Rect(i.x, i.y, i.w, i.h), color, 2);
cv::Size const text_size = getTextSize(obj_name, cv::FONT_HERSHEY_COMPLEX_SMALL, 1.2, 2, 0);
int const max_width = (text_size.width > i.w + 2) ? text_size.width - 5 : (i.w + 2);
cv::rectangle(mat_img, cv::Point2f(std::max((int)i.x - 1, 0), std::max((int)i.y - 30, 0)),
cv::Point2f(std::min((int)i.x + max_width, mat_img.cols - 1), std::min((int)i.y, mat_img.rows - 1)),
color, CV_FILLED, 8, 0);
putText(mat_img, obj_name, cv::Point2f(i.x, i.y - 10), cv::FONT_HERSHEY_COMPLEX_SMALL, 1.2, cv::Scalar(0, 0, 0), 2);
}
if (current_det_fps >= 0 && current_cap_fps >= 0) {
std::string fps_str = "FPS detection: " + std::to_string(current_det_fps);
putText(mat_img, fps_str, cv::Point2f(10, 20), cv::FONT_HERSHEY_COMPLEX_SMALL, 1.2, cv::Scalar(0, 0, 255), 2);
}
}
最后,我们只需要将得到的结果通过opencv进行打印就行了。
下面是cpp文件中的部分代码,方便进行理解
// yourDemo.cpp关键代码
// step1: 使用opencv进行图片的读取
cv::Mat frame = cv::imread("./data/rabbit.jpg");
// step2: 进行推理并绘制边界框
frame = inference(frame);
// step3: 使用opencv打印结果
cv::imread("rst",frame);
cv::waitKey(20);
4 最终的目录结果
最终的目录结构可能是这样的
---- darknet (项目名称)
---- data (使用的数据)
---- x64 (使用64位系统)
---- Debug
---- Release
---- pthreadGC2.dll (++下面是新增的四个动态库)
---- pthreadVC2.dll
---- opencv_world300.dll
---- yolo_cpp_dll.dll
--- main.cpp (主程序入口)
---- yolo_v2_class.hpp (++新增的头文件)
---- yolo_cpp_dll.lib (++新增的静态库)
---- utils.h (++下面是新增的.h文件和.cpp文件)
---- utils.cpp
5 运行结果
我将darknet封装在了QT界面中了,这样显得更高大尚?哈哈哈哈
