数据集处理篇
python实现cifar10数据集的可视化
(1)CIFAR-10数据集介绍
① CIFAR-10数据集包含60000个3232的彩色图像,共有10类。有50000个训练图像和10000个测试图像。
数据集分为5个训练块和1个测试块,每个块有10000个图像。测试块包含从每类随机选择的1000个图像。训练块以随机的顺序包含这些图像,但一些训练块可能比其它类包含更多的图像。训练块每类包含5000个图像。
②data——1个100003072大小的uint8s数组。数组的每行存储1张32*32的图像。第1个1024包含红色通道值,下1个包含绿色,最后的1024包含蓝色。图像存储以行顺序为主,所以数组的前32列为图像第1行的红色通道值。
labels——1个10000数的范围为0~9的列表。索引i的数值表示数组data中第i个图像的标签。
③数据集中包含另外1个叫batches.meta的文件。它也包含1个Python字典对象。有如下列元素:
label_names——1个10元素的列表,给labels中的数值标签以有意义的名称。例如,label_names[0] == “airplane”, label_names[1] == “automobile”等。
都是一些二进制文件
# -*- coding:utf-8 -*-
import pickle as p
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as plimg
from PIL import Image
def load_CIFAR_batch(filename):
""" load single batch of cifar """
with open(filename, 'rb')as f:
datadict = p.load(f)
X = datadict['data']
Y = datadict['labels']
X = X.reshape(10000, 3, 32, 32)
Y = np.array(Y)
return X, Y
def load_CIFAR_Labels(filename):
with open(filename, 'rb') as f:
lines = [x for x in f.readlines()]
print(lines)
if __name__ == "__main__":
load_CIFAR_Labels("/data/cifar-10-batches-py/batches.meta")
imgX, imgY = load_CIFAR_batch("/data/cifar-10-batches-py/data_batch_1")
print imgX.shape
print "正在保存图片:"
for i in xrange(imgX.shape[0]):
imgs = imgX[i - 1]
if i < 100:#只循环100张图片,这句注释掉可以便利出所有的图片,图片较多,可能要一定的时间
img0 = imgs[0]
img1 = imgs[1]
img2 = imgs[2]
i0 = Image.fromarray(img0)
i1 = Image.fromarray(img1)
i2 = Image.fromarray(img2)
img = Image.merge("RGB",(i0,i1,i2))
name = "img" + str(i)
img.save("/data/images/"+name,"png")#文件夹下是RGB融合后的图像
for j in xrange(imgs.shape[0]):
img = imgs[j - 1]
name = "img" + str(i) + str(j) + ".png"
print "正在保存图片" + name
plimg.imsave("/data/image/" + name, img)#文件夹下是RGB分离的图像
print "保存完毕."
pickle.load():

pickle.load()如果不添加encoding参数,会默认将文件以解码为ASCII码的形式输出,所以需要添加encoding参数,初次之外,还需要强调的是encoding参数的值应该是一个字符串,而不是一个type,即例如’GBK’,'iso-8859-1’等形式。
用于序列化的两个模块
json:用于字符串和Python数据类型间进行转换
pickle: 用于python特有的类型和python的数据类型间进行转换
json提供四个功能:dumps,dump,loads,load
pickle提供四个功能:dumps,dump,loads,load
pickle.load(file,*,fix_imports=True, encoding=“ASCII”, errors=“strict”)
必填参数file必须以二进制可读模式打开,即“rb”,其他都为可选参数
python pickle 模块的使用
列表解析:
列表解析可以使我们通过一行代码就可以生成列表。列表解析是将 for 循环和创建新元素的代码合并成一行,并自动的附加新元素。
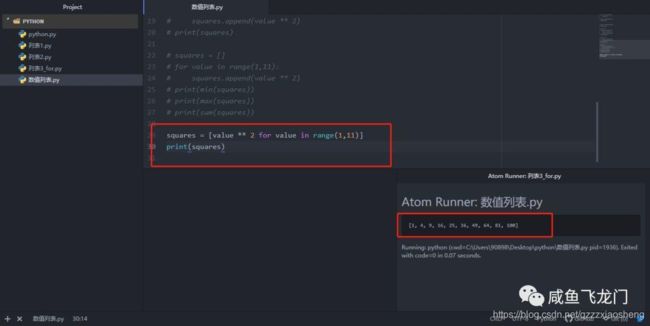 列表解析
列表解析
Python xrange() 函数:
1.range和xrange都是在循环中使用,输出结果一样。
2.range返回的是一个list对象,而xrange返回的是一个生成器对象(xrange object)。
3.xrange则不会直接生成一个list,而是每次调用返回其中的一个值,内存空间使用极少,因而性能非常好。
>>>xrange(8)
xrange(8)
>>> list(xrange(8))
[0, 1, 2, 3, 4, 5, 6, 7]
>>> range(8) # range 使用
[0, 1, 2, 3, 4, 5, 6, 7]
>>> xrange(3, 5)
xrange(3, 5)
>>> list(xrange(3,5))
[3, 4]
>>> range(3,5) # 使用 range
[3, 4]
>>> xrange(0,6,2)
xrange(0, 6, 2) # 步长为 2
>>> list(xrange(0,6,2))
[0, 2, 4]
>>>
python PIL
博客园介绍,在数据集处理貌似挺有用
python路径拼接os.path.join()函数的用法
博客参考
numpy中loadtxt 的用法
numpy中loadtxt 的用法
numpy.loadtxt(fname, dtype=, comments=’#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0)
更好的博客描述,主要针对.csv文件的读取,是一种特殊的.txt文件
tensorflow之从文件中读取数据(适用场景:大规模数据集,亲测有效~)
这个方法似乎有效,但是.csv制作有点问题,暂时还未掌握
Numpy函数学习–genfromtxt函数
烧脑啊
这个delimiter=" "参数似乎是文件中也就是矩阵中每一行元素中元素与元素之间的分割符,dtype参数可以将其转化为特定的格式。
想模仿一下这篇博客的导入数据集 Batch Generator:Tensorflow的大规模数据集导入
(现在思路基本已经明了,但是还是有很多基本的问题要处理,我们可以把所有图片的地址与对应的标签存储在一个文本文件中,或者是.csv .txt文件,然后将图片集转化成为tensorflow的标准数据形式,最后利用多线程与队列的形式进行数据的读取与训练,这种方法可以用来处理大规模的数据集,但是对python文件的处理要求比较高,不过相信最后可以解决,现在的主要任务是亲自动手实践,整理这几天看过数以万计的博客,哈哈哈哈!!!)
首先进行第一种方法的实验,将我的UcMerced数据集转化为.txt文本格式:
拟打算主要参考博客
##相关库函数导入
import os
from cv2 import cv2 as cv
import tensorflow as tf
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
def getTrainList():
root_dir ="/home/xiaozhen/UCMerced_LandUse/Images/airplane"
with open("/home/xiaozhen/Desktop/UCMerced.txt","w") as f:
for file in os.listdir(root_dir):
if len(file)==14:
f.write(root_dir+'/'+file+" "+"2"+"\n")
def load_file(example_list_file): #从清单中读取地址和类别编号,这里的输入是清单存储地址
lines = np.genfromtxt(example_list_file,delimiter=" ",dtype=[('col1', 'S120'), ('col2', 'i8')])
examples = []
labels = []
for example,label in lines:
examples.append(example)
labels.append(label)
return np.asarray(examples),np.asarray(labels),len(lines)
def trans2tfRecord(trainFile,output_dir): #生成tfrecords文件
_examples,_labels,examples_num = load_file(trainFile)
filename = output_dir + '.tfrecords'
writer = tf.python_io.TFRecordWriter(filename)
for i,[example,label] in enumerate(zip(_examples,_labels)):
example = example.decode("UTF-8")
image = cv.imread(example)
image = cv.resize(image,(256,256)) #这里的格式需要注意,一定要尽量保证图片的大小一致
image_raw = image.tostring() #将图片矩阵转化为字符串格式
example = tf.train.Example(features=tf.train.Features(feature={
'image_raw':tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_raw])),
'label':tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
}))
writer.write(example.SerializeToString())
writer.close() #写入完成,关闭指针
return filename #返回文件地址
def read_tfRecord(file_tfRecord): #输入是.tfrecords文件地址
queue = tf.train.string_input_producer([file_tfRecord])
reader = tf.TFRecordReader()
_,serialized_example = reader.read(queue)
features = tf.parse_single_example(
serialized_example,
features={
'image_raw':tf.FixedLenFeature([], tf.string),
'label':tf.FixedLenFeature([], tf.int64)
}
)
image = tf.decode_raw(features['image_raw'],tf.uint8)
image = tf.reshape(image,[256,256,3])
image = tf.cast(image, tf.float32)
image = tf.image.per_image_standardization(image)
label = tf.cast(features['label'], tf.int64) #这里设置了读取信息的格式
return image,label
if __name__ == '__main__':
getTrainList()
dataroad = "/home/xiaozhen/Desktop/UCMerced.txt"
outputdir = "/home/xiaozhen/Desktop/UCMerced"
trainroad = trans2tfRecord(dataroad,outputdir)
traindata,trainlabel = read_tfRecord(trainroad)
image_batch,label_batch = tf.train.shuffle_batch([traindata,trainlabel],
batch_size=100,capacity=2000,min_after_dequeue = 1000)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess,coord = coord)
train_steps = 10
try:
while not coord.should_stop(): # 如果线程应该停止则返回True
example,label = sess.run([image_batch,label_batch])
print(example.shape,label)
train_steps -= 1
print(train_steps)
if train_steps <= 0:
coord.request_stop() # 请求该线程停止
except tf.errors.OutOfRangeError:
print ('Done training -- epoch limit reached')
finally:
# When done, ask the threads to stop. 请求该线程停止
coord.request_stop()
# And wait for them to actually do it. 等待被指定的线程终止
coord.join(threads)
只导入了一个飞机的图片集,比较成功。突然发现其实格式都是固定的。在图片的大小上一定要改,否则会出现参数不匹配问题。另外在vscode中导入cv2时会提醒缺少模块,实际是正常运作的,不过为了减少警告,可以讲导入方法改为:from cv2 import cv2 as cv 嘿嘿,问题解决。
接下来需要解决的问题是如何将所有类别全部导入,是否可以用一个简单的for循环来完成。未完待续。
继续工作,现在我们将要实现如何将所有的类别均导入:

numpy中np.array()与np.asarray的区别以及.tolist
比较好的博客
##相关库函数导入
import os
from cv2 import cv2 as cv
import tensorflow as tf
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
'''def getTrainList():
root_dir ="/home/xiaozhen/UCMerced_LandUse/Images/airplane"
with open("/home/xiaozhen/Desktop/UCMerced.txt","w") as f:
for file in os.listdir(root_dir):
if len(file)==14:
f.write(root_dir+'/'+file+" "+"2"+"\n")
'''
def getTrainList():
open("/home/xiaozhen/Desktop/UCMerced.txt","w").close()
category="/home/xiaozhen/UCMerced_LandUse/Images"
for classes in os.listdir(category):
root_dir="/home/xiaozhen/UCMerced_LandUse/Images/"+classes
with open("/home/xiaozhen/Desktop/UCMerced.txt","a") as f:
for file in os.listdir(root_dir):
f.write(root_dir+'/'+file+" "+str(os.listdir(category).index(classes))+"\n")
def load_file(example_list_file): #从清单中读取地址和类别编号,这里的输入是清单存储地址
lines = np.genfromtxt(example_list_file,delimiter=" ",dtype=[('col1', 'S120'), ('col2', 'i8')])
examples = []
labels = []
for example,label in lines:
examples.append(example)
labels.append(label)
return np.asarray(examples),np.asarray(labels),len(lines)
def trans2tfRecord(trainFile,output_dir): #生成tfrecords文件
_examples,_labels,examples_num = load_file(trainFile)
filename = output_dir + '.tfrecords'
writer = tf.python_io.TFRecordWriter(filename)
for i,[example,label] in enumerate(zip(_examples,_labels)):
example = example.decode("UTF-8")
image = cv.imread(example)
image = cv.resize(image,(256,256)) #这里的格式需要注意,一定要尽量保证图片的大小一致
image_raw = image.tostring() #将图片矩阵转化为字符串格式
example = tf.train.Example(features=tf.train.Features(feature={
'image_raw':tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_raw])),
'label':tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
}))
writer.write(example.SerializeToString())
writer.close() #写入完成,关闭指针
return filename #返回文件地址
def read_tfRecord(file_tfRecord): #输入是.tfrecords文件地址
queue = tf.train.string_input_producer([file_tfRecord])
reader = tf.TFRecordReader()
_,serialized_example = reader.read(queue)
features = tf.parse_single_example(
serialized_example,
features={
'image_raw':tf.FixedLenFeature([], tf.string),
'label':tf.FixedLenFeature([], tf.int64)
}
)
image = tf.decode_raw(features['image_raw'],tf.uint8)
image = tf.reshape(image,[256,256,3])
image = tf.cast(image, tf.float32)
image = tf.image.per_image_standardization(image)
label = tf.cast(features['label'], tf.int64) #这里设置了读取信息的格式
return image,label
if __name__ == '__main__':
#getTrainList()
dataroad = "/home/xiaozhen/Desktop/UCMerced.txt"
outputdir = "/home/xiaozhen/Desktop/UCMerced"
#trainroad = trans2tfRecord(dataroad,outputdir)
traindata,trainlabel = read_tfRecord(outputdir+".tfrecords")
image_batch,label_batch = tf.train.shuffle_batch([traindata,trainlabel],
batch_size=100,capacity=2000,min_after_dequeue = 1000)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess,coord = coord)
train_steps = 10
try:
while not coord.should_stop(): # 如果线程应该停止则返回True
example,label = sess.run([image_batch,label_batch])
print(example.shape,label)
train_steps -= 1
print(train_steps)
if train_steps <= 0:
coord.request_stop() # 请求该线程停止
except tf.errors.OutOfRangeError:
print ('Done training -- epoch limit reached')
finally:
# When done, ask the threads to stop. 请求该线程停止
coord.request_stop()
# And wait for them to actually do it. 等待被指定的线程终止
coord.join(threads)
上为最终版代码,但是据说数据标签一定要使用one—hot编码,这里输出的都是整形,所以还需要改进。
接下来进行第二中方法的测试:生成.csv文件,不过本质原理都是一样的,利用文本文件找寻地址生成tfrecords标准数据集形式。
import os
category="/home/xiaozhen/UCMerced_LandUse/Images"
category_name=os.listdir(category)
str_text=""
for classes in category_name:
root_dir="/home/xiaozhen/UCMerced_LandUse/Images/"+classes
with open("/home/xiaozhen/Desktop/UCMerced.csv","a") as f:
for file in os.listdir(root_dir):
str_text=root_dir+os.sep+file+","+str(os.listdir(category).index(classes))+"\n"
f.write(str_text)
f.close()
导入模块挺成功,成功的生成了.csv文件,里面包含每个类别图片的绝对地址和类别标签(序号)
博客上要求要生成训练集和测试集两个.csv文档然后进行训练,现在暂时未掌握直接分开的方法,需要慢慢来测试,这里结合博客尝试一下简单的二分类问题。
import numpy as np
import pandas as pd
from cv2 import cv2
import csv
from os import path as osp
import os
import tensorflow as tf
'''category="/home/xiaozhen/UCMerced_LandUse/Images"
category_name=os.listdir(category)
str_text=""
for classes in category_name:
root_dir="/home/xiaozhen/UCMerced_LandUse/Images/"+classes
with open("/home/xiaozhen/Desktop/UCMerced.csv","a") as f:
for file in os.listdir(root_dir):
str_text=root_dir+os.sep+file+","+str(os.listdir(category).index(classes))+"\n"
f.write(str_text)
f.close()
'''
'''
path1="/home/xiaozhen/UCMerced_LandUse/Images/agricultural" #这段代码用来生成csv文件,将除此之外的代码注释掉即可得
path2="/home/xiaozhen/UCMerced_LandUse/Images/airplane"
f1=open("/home/xiaozhen/Desktop/UCMerced1.csv","a")
f2=open("/home/xiaozhen/Desktop/UCMerced2.csv","a")
name_list1=os.listdir(path1)
name_list2=os.listdir(path2)
for file in name_list1:
if name_list1.index(file)<80:
f1.write(path1+os.sep+file+","+"0"+"\n")
else:
f2.write(path1+os.sep+file+","+"0"+"\n")
for file2 in name_list2:
if name_list2.index(file2)<80:
f1.write(path2+os.sep+file2+","+"1"+"\n")
else:
f2.write(path2+os.sep+file2+","+"1"+"\n")
f1.close()
f2.close()
'''
def load_file(example_list_file):
lines = np.genfromtxt(example_list_file,delimiter=",",dtype=[('col1', 'S120'), ('col2', 'i8')])
examples = []
labels = []
for example,label in lines:
examples.append(example)
labels.append(label)
#convert to numpy array
return np.asarray(examples),np.asarray(labels),len(lines)
def extract_image(filename,height,width):
print(filename)
image = cv2.imread(filename)
image = cv2.resize(image,(height,width))
b,g,r = cv2.split(image)
rgb_image = cv2.merge([r,g,b])
return rgb_image
def trans2tfRecord(train_file,output_dir,height,width):
#if not os.path.exists(output_dir) or os.path.isfile(output_dir):
#os.makedirs(output_dir)
_examples,_labels,examples_num = load_file(train_file)
filename = output_dir + '.tfrecords'
writer = tf.python_io.TFRecordWriter(filename)
for i,[example,label] in enumerate(zip(_examples,_labels)):
# print("NO{}".format(i))
#need to convert the example(bytes) to utf-8
example = example.decode("UTF-8")
#image = extract_image(example,height,width)
image = cv2.imread(example)
image = cv2.resize(image,(256,256))
image_raw = image.tostring()
example = tf.train.Example(features=tf.train.Features(feature={
'image_raw':_bytes_feature(image_raw),
'height':_int64_feature(image.shape[0]),
'width': _int64_feature(32),
'depth': _int64_feature(32),
'label': _int64_feature(label)
}))
writer.write(example.SerializeToString())
writer.close()
return filename
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def read_tfRecord(file_tfRecord,shuffle=False):
# 这个函数需要传入一个文件名,系统会自动将它转为一个文件名队列,这个队列存的是训练或测试过程用到的数据
# tf.train.string_input_producer有两个重要的参数,一个是num_epochs,这个设成默认none就行,none表示无限次
# 它表示将全部样本入队次数,一般程序迭代几次就入队几次。程序运行开始,数据就开始出队,为了保证队列一直不空,
# 我们设为none,使全部样本入队无数次(无限循环)。
# 另外一个就是shuffle,shuffle是指在一个epoch内文件的顺序是否被打乱(但是我测试时发现无论是True还是False,其实都打乱了)。
queue = tf.train.string_input_producer([file_tfRecord], shuffle=shuffle)
reader = tf.TFRecordReader()
_,serialized_example = reader.read(queue)
features = tf.parse_single_example(
serialized_example,
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'height': tf.FixedLenFeature([], tf.int64),
'width':tf.FixedLenFeature([], tf.int64),
'depth': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64)
}
)
image = tf.decode_raw(features['image_raw'],tf.uint8)
#height = tf.cast(features['height'], tf.int64)
#width = tf.cast(features['width'], tf.int64)
image = tf.reshape(image,[256,256,3])
image = tf.cast(image, tf.float32)
image = tf.image.per_image_standardization(image)
label = tf.cast(features['label'], tf.int64)
print(image,label)
return image,label
def fit_ATDA(source_train, y_train, target_val, y_val, nb_epoch=30,
n = 86524, my_number = 25596, my_catelogy = 2, batch = 4):
for e in range(nb_epoch):
n_batch = 0
for my_batch_train in range(int(n/batch)):
Xu_batch, Yu_batch = self.sess.run([source_train, y_train])
Xu_batch = transform_batch_images(Xu_batch)
Yu_batch = np_utils.to_categorical(Yu_batch, 2)
# print('train label',Yu_batch)
feed_dict = { self.x: Xu_batch, self.y_: Yu_batch ,self.istrain:True}
cost, Ft_loss = self.sess.run([cost, Ft_loss], feed_dict=feed_dict)
n_batch += 1
#every 1000 minibatch print loss
if n_batch % 1000==0:
print("Epoch %d total_loss %f Ft_loss %f" % (e + 1, cost,Ft_loss))
with tf.Session() as sess:
# 训练过程
# base_path = os.path.join('images','images224')
data_train_path = "/home/xiaozhen/Desktop/UCMerced1.csv"
data_test_path = "/home/xiaozhen/Desktop/UCMerced1.csv"
output_dir_1="/home/xiaozhen/Desktop/UCMerced1"
output_dir_2="/home/xiaozhen/Desktop/UCMerced2"
# 首次执行程序需要运行一旦生成之后就可以注释掉了:利用csv生成y_train.tfrecords和y_test.tfrecords文件,这俩文件是训练集和测试集的样本与标签,
filename = trans2tfRecord(data_train_path,output_dir_1,256,256)
filename2 = trans2tfRecord(data_train_path,output_dir_2,256,256)
img_batch, path_batch = read_tfRecord(filename, shuffle=True)
img_batch2, path_batch2 = read_tfRecord(filename2, shuffle=False)
image_batches, label_batches = tf.train.batch([img_batch, path_batch], batch_size=batch, capacity=4096)
image_batches2, label_batches2 = tf.train.batch([img_batch2, path_batch2], batch_size=batch, capacity=4096)
tf.local_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
# 定义一个模型
model=ATDA(sess=sess)
model.create_model()
# 训练模型:(image_batches,label_batches)是训练集,(image_batches2,label_batches2)是测试集,
model.fit_ATDA(source_train=image_batches, y_train=label_batches,
target_val=image_batches2, y_val=label_batches2,
# n是训练集总数,my_number是测试集总数,my_catelogy是标签种类,batch是迭代次数
nb_epoch=epochs, n = 160, my_number = 40, my_catelogy = 2,batch = 16)
coord.request_stop() # 请求线程结束
coord.join() # 等待线程结束
这段代码已经实现了生成一个训练集和一个测试集的csv文件,并且将其转化为了tfrecords标准格式,不过由于对训练模块一些代码不清楚,所以在训练模块提示出现有些变量没能够定义,不过基本目标已经完成和实现。

接下来我将对数据集的处理做一个简要的总结:
tensorflow 读取数据在官网上主要介绍了3种方法,分别为:
1、供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据。
2、从文件读取数据: 在TensorFlow图的起始, 让一个输入管线从文件中读取数据。
3、预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)。
这篇博客讲的相当不错
主要总结一下第二种从文件中以管线形式读取数据:
一般包括:
文件名列表
可配置的 文件名乱序(shuffling)
可配置的 最大训练迭代数(epoch limit)
文件名队列
针对输入文件格式的阅读器
纪录解析器
可配置的预处理器
样本队列。
(这种方法适合读取大规模数据集,也是上面所用的方法)
这种方法主要用到了队列这种先进先出的数据结构,具体参考可以参考下面的博客:
多线程理解
按照博客所讲,从数据集中读取可以采用直接feeding形式,这种形式不确定是否适合大规模数据集。
之后是直接从文件中读取数据,这种文件可以是csv文件,其本质是一种文本文件,里面存储了图片的标签和图片的像素数据,比较适合小规模数据集的存储(由于文本文件比二进制文件更多占用内存),还可以使已经转化好的位二进制文件,比如mnist介绍,还可以是cifar10这种字典类型,也可以是tfrecords这种转化好的标准二进制形式,要读取这种数据集首先要首先要知道你要读取的文件的格式,选择对应的文件读取器,参考多线程理解,
然后再利用队列利用多线程进行训练,再一种方法就是对数据进行预加载,如可以讲mnist在各种小的数据集直接全部加载进内存进行训练,最后一种方法是直接从原图中读取数据
具体可以参考这篇博客
还有这个
最后介绍一下:利用Tensorflow构建自己的图片数据集TFrecords
参考一
参考二
参考三
到此over…